前言

来自中科院自动化所的paper
MoDS: Model-oriented Data Selection for Instruction Tuning
link:https://arxiv.org/pdf/2311.15653
github:https://github.com/CASIA-LM/MoDS
一、摘要
sft已经成为让LLM遵循用户指令的一种方式。通常,需要使用数十万个数据来微调基础LLM。最近,研究表明少量的高质量指令数据就足够。然而,如何在给定的数据中选择合适的指令数据?
为了解决这个问题,提出了一种面向模型的数据选择(MoDS)方法,该方法基于考虑三个方面的新标准来选择指令数据:质量、覆盖范围和必要性。
首先,利用质量评估模型从原始指令数据集中过滤出高质量子集,然后设计算法进一步从高质量子集中选择具有良好覆盖率的seed instruction dataset。应用seed数据集来微调基础LLM获得初始sft LLM。最后,用一个必要性评估模型来找出初始sft LLM效果较差的sft数据,将这些数据作为下一步改进LLM的必要指令。
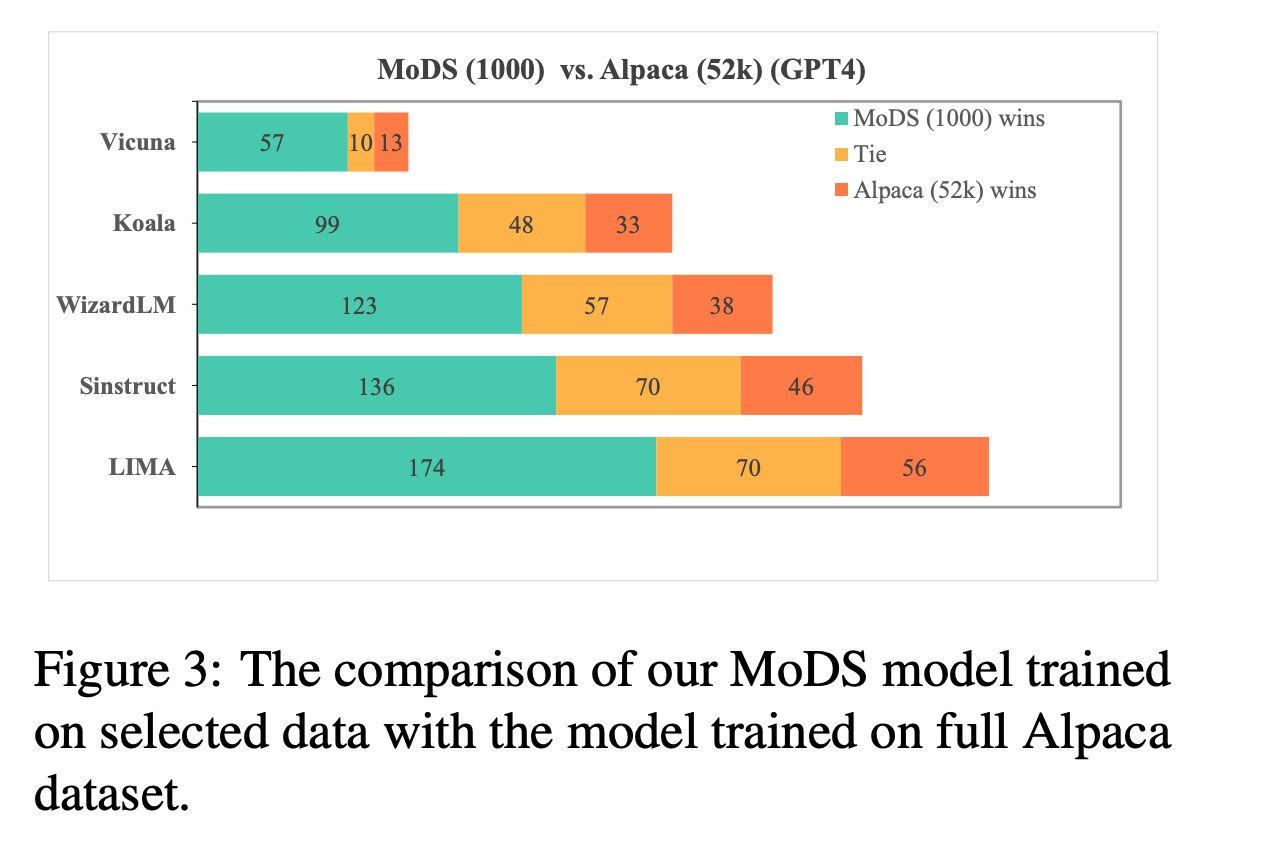
从原始指令数据集中得到一个小的高质量、覆盖面广、必要性高的子集。实验结果表明,使用MoDS方法选择的 4,000 个指令对进行微调的模型比使用包含 214k 指令数据的完整原始数据集进行微调的模型表现更好。
二、方法
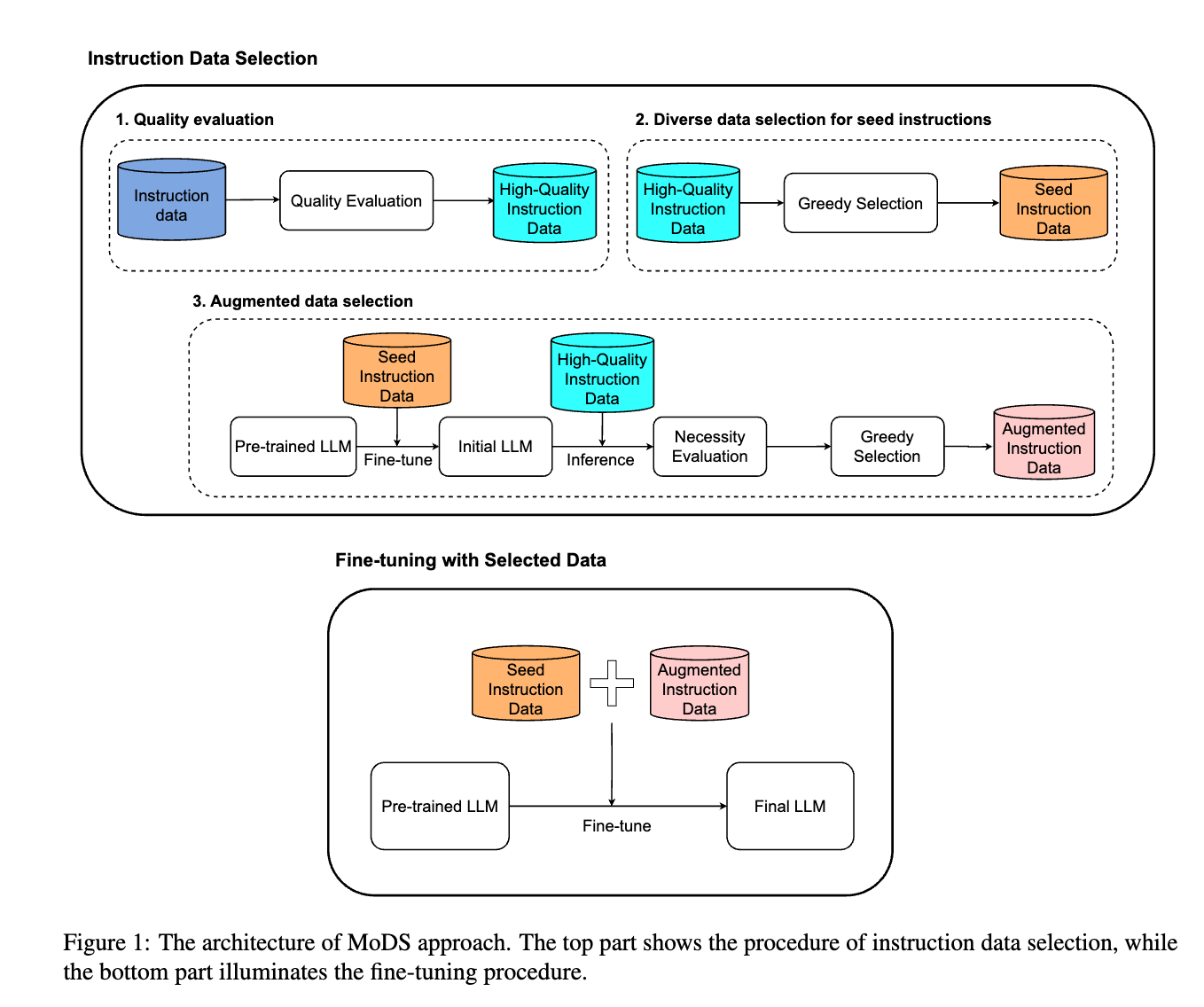
这个方法主要聚焦于三点:
- Quality: 数据样本的质量
- Coverage: 即多样性
- Necessity: 对模型sft重要且唯一,主要从,大模型能很好的回答,说明模型学习好了,如果不能生成好的回答,说明LLM缺乏这个能力,则这个样本是必要的去提升模型能力。
分为三步骤
- Quality Evaluation
- Diverse Data Selection for Seed Instructions
- Augmented Data Selection.
2.1 Quality Evaluation
直接用一个reward model进行样本质量评分
reward model:reward-model-deberta-
v3-large-v22 (基于DeBERTa架构)
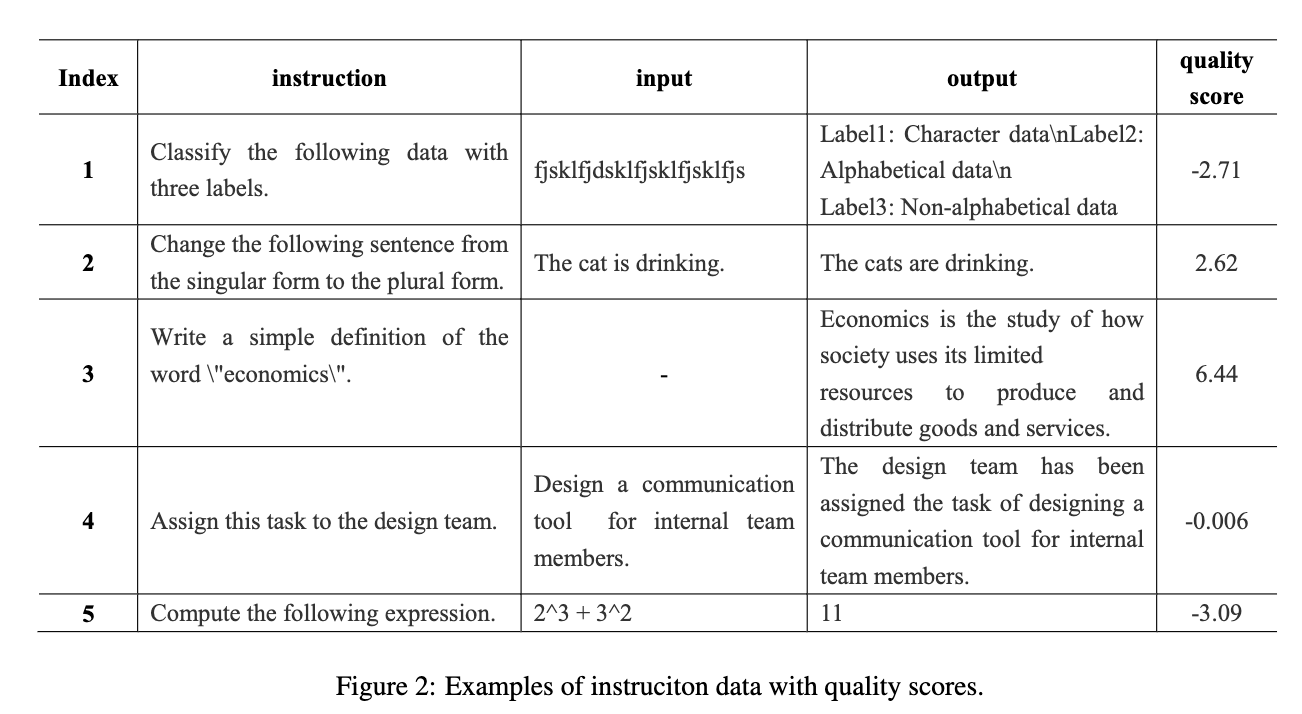
超过某个阈值的数据样本挑出来,当作 high-quality in struction dataset
2.2 Diverse Data Selection for Seed
依然采用k-center-greedy聚类来得到subset

讲解和代码:https://zhuanlan.zhihu.com/p/711917766
最终得到的样本集称为:seed instruction dataset
2.3 Augmented Data Selection
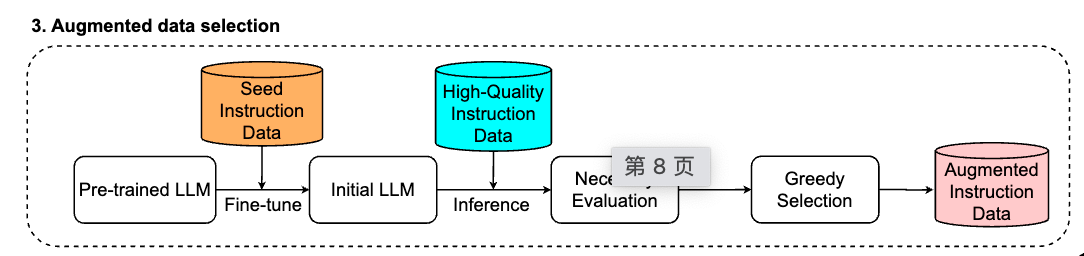
利用seed instruction dataset训练一个sft model.
用这个sft model对high-quality in struction dataset进行推理,之后用一个review model对生成的response和instruction计算一个review score,采用的模型依然是reward-model-deberta-v3-large-v22 (基于DeBERTa架构)
如果review score低于某个分数,则代表模型生成的response不是那么好,收集全部的低review score的样本,之后再用一次K-center greedy选取一个子集,作为加强数据集。
相当于做了一个high-quality in struction dataset选多样性subset,之后再通过预测不好的样本集,再补充一部分增强模型能力。
最终用这两个subset组成最终的数据集进行训练
三、实验
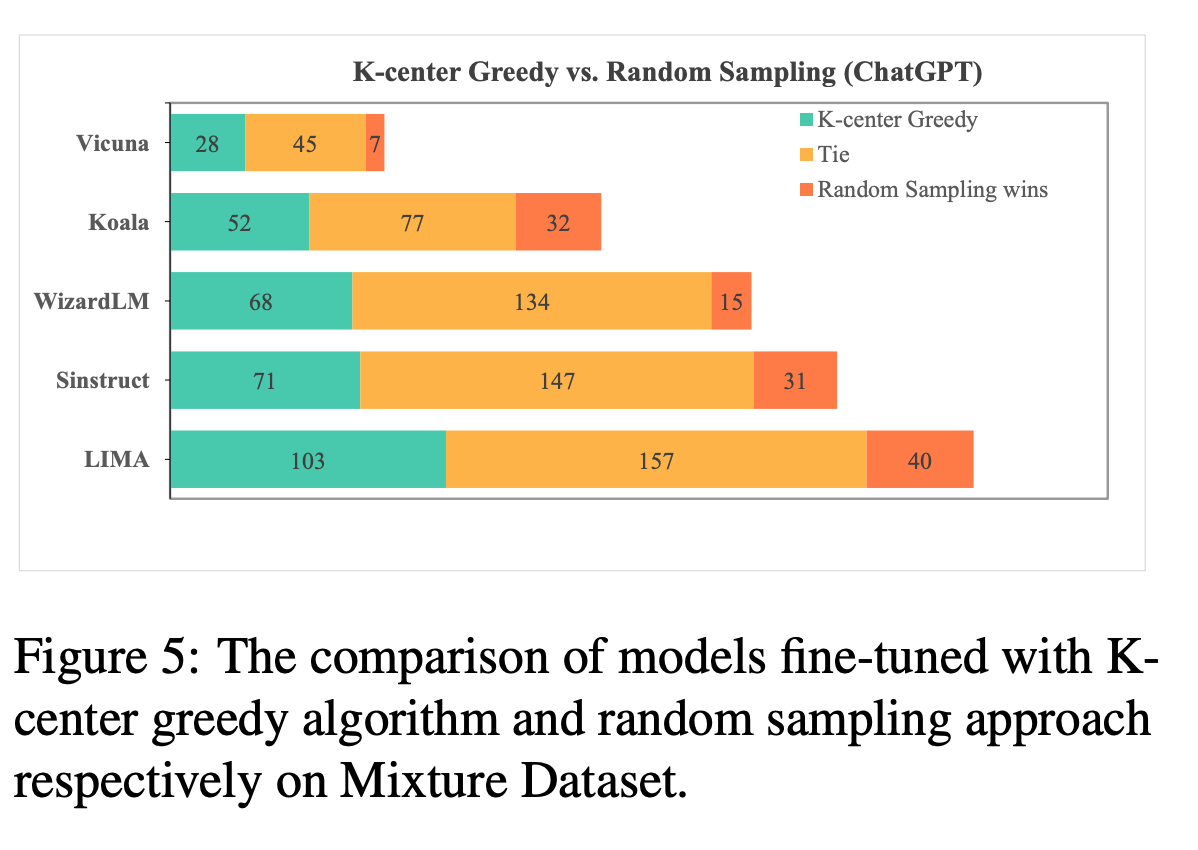
还做了一个 k-center和random采样的对比实验,这种实验基本上在用k-center的情况下都会对比一下: