OpenAI Chat Completion API 申请及使用
OpenAI ChatGPT 是一款非常强大的 AI 对话系统,只要输入提示词,就能在短短几秒内生成流畅自然的回复。ChatGPT 以其出色的语言理解和生成能力在业界独树一帜,如今,ChatGPT 早已在各个行业和领域广泛应用,其影响力愈发显著。无论是日常对话、创意写作,还是专业咨询、代码编程,ChatGPT 都能提供令人惊叹的智能协助,极大地提高了人类的工作效率和创造力。
本文档主要介绍 OpenAI Chat Completion API 操作的使用流程,利用它我们可以轻松使用官方 OpenAI ChatGPT 的对话功能。
申请流程
要使用 OpenAI Chat Completion API,首先可以到 OpenAI Chat Completion API 页面点击「Acquire」按钮,获取请求所需要的凭证:

如果你尚未登录或注册,会自动跳转到登录页面邀请您来注册和登录,登录注册之后会自动返回当前页面。
在首次申请时会有免费额度赠送,可以免费使用该 API。
基本使用
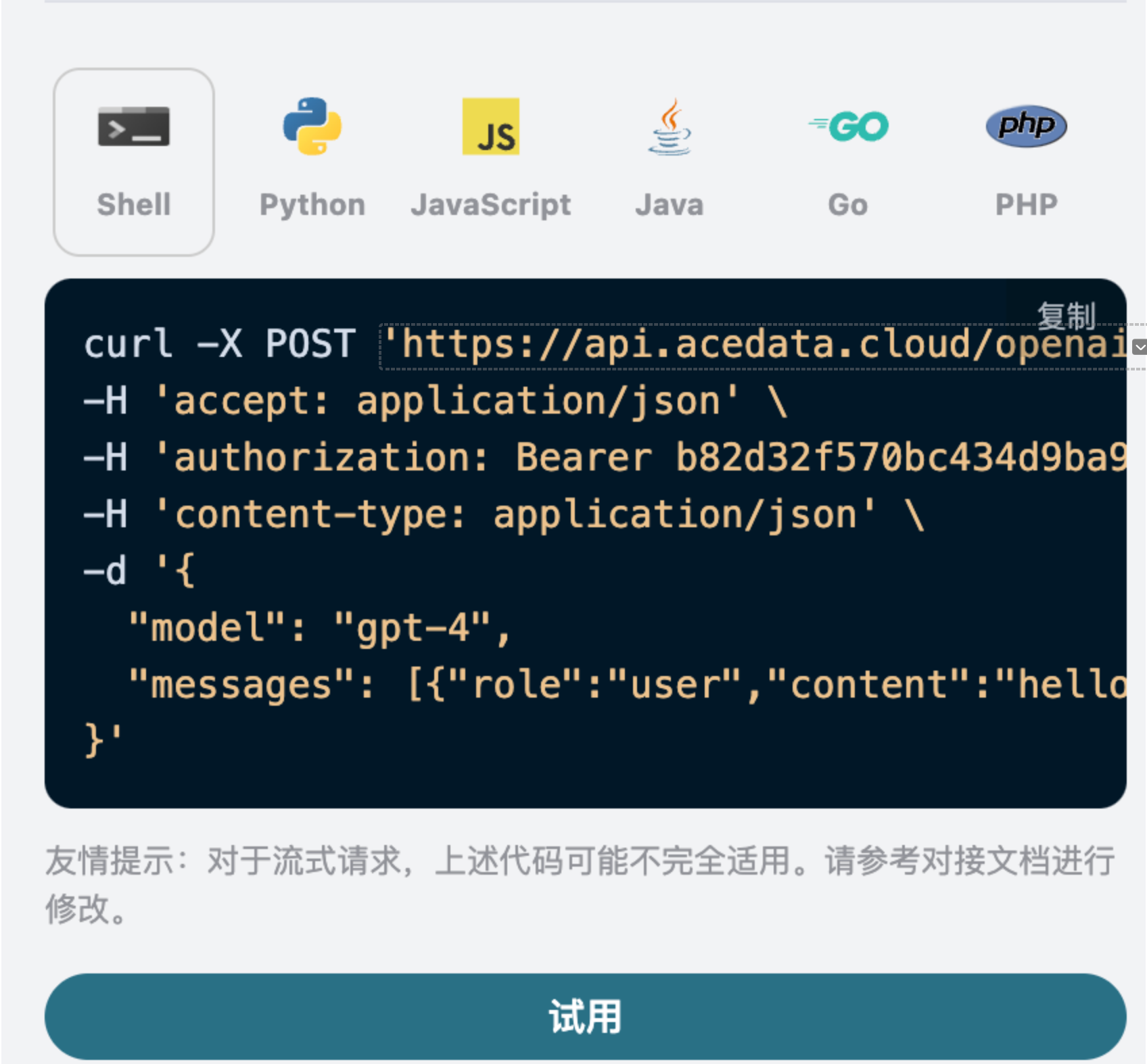
接下来就可以在界面上填写对应的内容,如图所示:

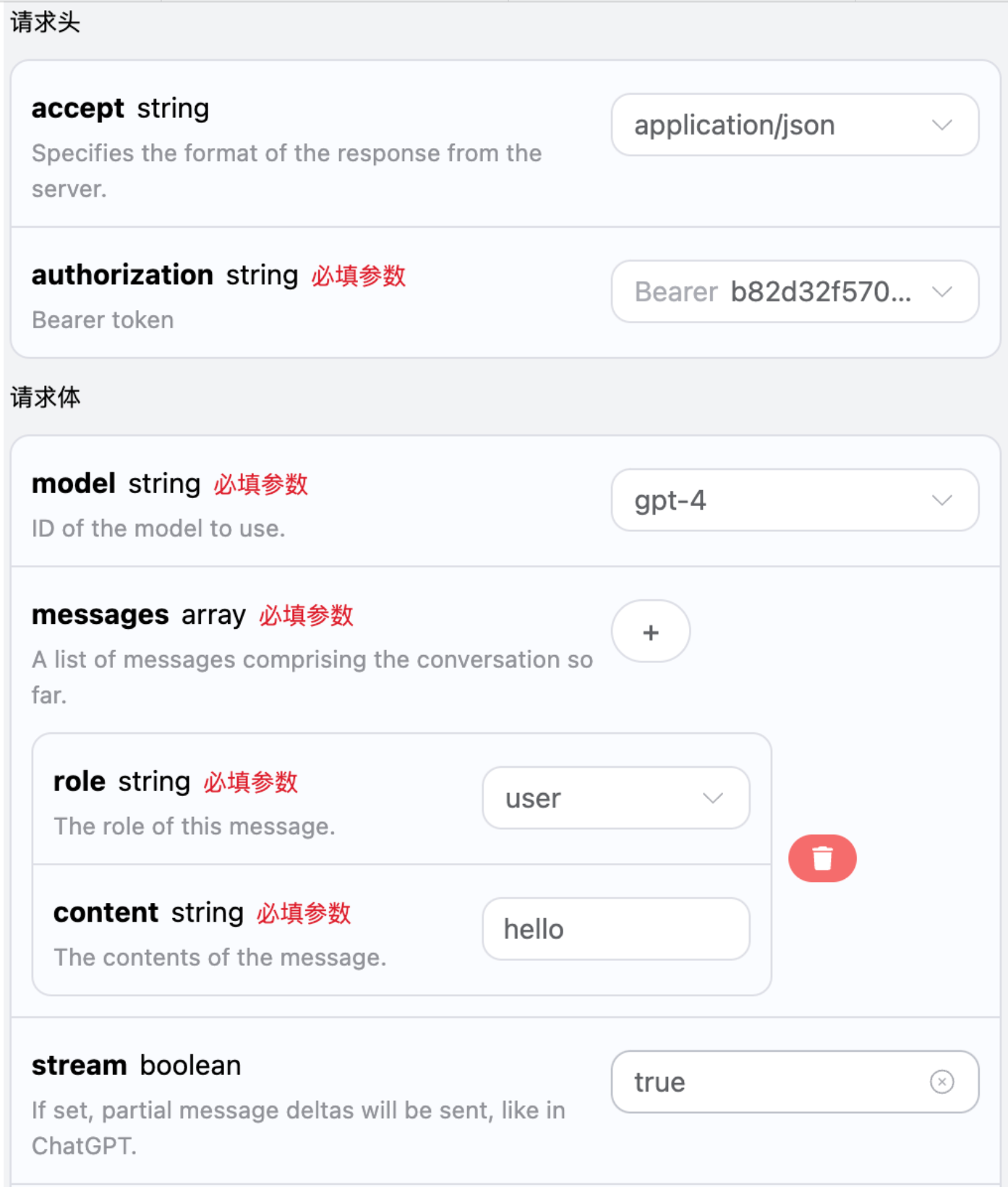
在第一次使用该接口时,我们至少需要填写三个内容,一个是 authorization,直接在下拉列表里面选择即可。另一个参数是 model, model 就是我们选择使用 OpenAI ChatGPT 官网模型类别,这里我们主要有 20 种模型,详情可以看我们提供的模型。最后一个参数是messages,messages是我们输入的提问词数组,它是一个数组,表示可以同时上传多个提问词,每个提问词包含了 role 和 content,其中 role 表示提问者的角色,我们提供了三种身份,分别为 user 、assistant、system 。另一个 content 就是我们提问的具体内容。
同时您可以注意到右侧有对应的调用代码生成,您可以复制代码直接运行,也可以直接点击「Try」按钮进行测试。
调用之后,我们发现返回结果如下:
json
{
"id": "chatcmpl-9k1idCCQuteN6Zu7Kv35TrG6DHKNt",
"object": "chat.completion.chunk",
"created": 1720756723,
"model": "gpt-4",
"system_fingerprint": "fp_abc28019ad",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "Hello! How can I assist you today?"
},
"finish_reason": "stop"
}
],
"recipient": "all",
"usage": {
"prompt_tokens": 8,
"completion_tokens": 9,
"total_tokens": 17
}
}返回结果一共有多个字段,介绍如下:
id,生成此次对话任务的 ID,用于唯一标识此次对话任务。model,选择的 OpenAI ChatGPT 官网模型。choices,ChatGPT 针对提问词给于的回答信息。usage:针对本次问答对 token 的统计信息。
其中 choices 是包含了 ChatGPT 的回答信息,它里面的 choices 是 ChatGPT,可以发现如图所示。
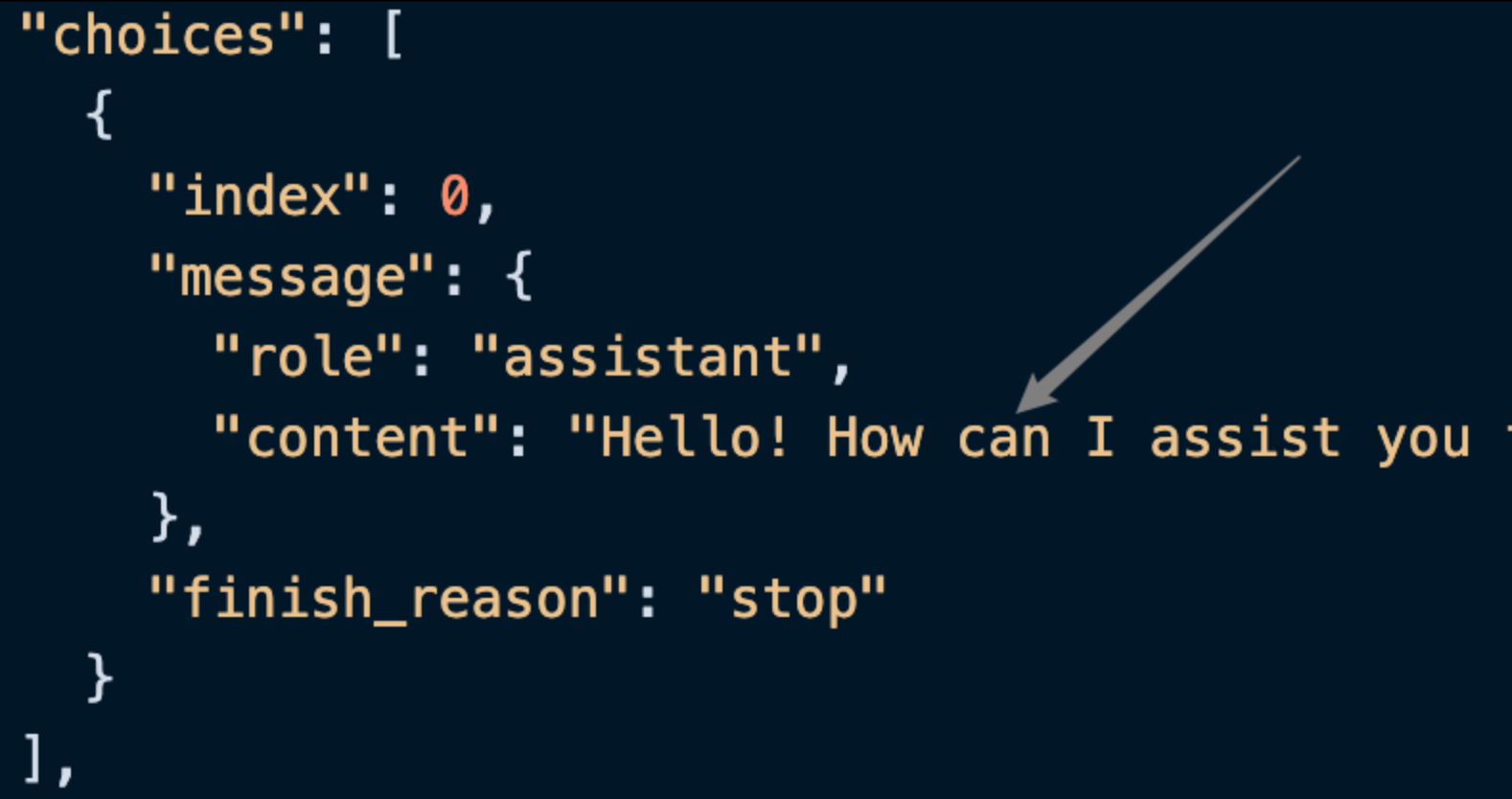
可以看到,choices 里面的 content 字段包含了 ChatGPT 回复的具体内容。
流式响应
该接口也支持流式响应,这对网页对接十分有用,可以让网页实现逐字显示效果。
如果想流式返回响应,可以更改请求头里面的 stream 参数,修改为 true。
修改如图所示,不过调用代码需要有对应的更改才能支持流式响应。
将 stream 修改为 true 之后,API 将逐行返回对应的 JSON 数据,在代码层面我们需要做相应的修改来获得逐行的结果。
Python 样例调用代码:
python
import requests
url = "https://api.acedata.cloud/openai/chat/completions"
headers = {
"accept": "application/json",
"authorization": "Bearer {token}",
"content-type": "application/json"
}
payload = {
"model": "gpt-4",
"messages": [{"role":"user","content":"hello"}],
"stream": True
}
response = requests.post(url, json=payload, headers=headers)
print(response.text)输出效果如下:
json
data: {"choices": [{"delta": {"role": "assistant"}, "index": 0}], "created": 1721007348, "id": "chatcmpl-YzczYjVhNjhjMzMwNDQ5MDkyNGYzOGZjZGE1ZGQ5OGU", "model": "gpt-4", "object": "chat.completion.chunk", "recipient": "all"}
data: {"choices": [{"delta": {"content": "Hi", "role": "assistant"}, "index": 0}], "created": 1721007348, "id": "chatcmpl-YzczYjVhNjhjMzMwNDQ5MDkyNGYzOGZjZGE1ZGQ5OGU", "model": "gpt-4", "object": "chat.completion.chunk", "recipient": "all"}
data: {"choices": [{"delta": {"content": " there", "role": "assistant"}, "index": 0}], "created": 1721007348, "id": "chatcmpl-YzczYjVhNjhjMzMwNDQ5MDkyNGYzOGZjZGE1ZGQ5OGU", "model": "gpt-4", "object": "chat.completion.chunk", "recipient": "all"}
data: {"choices": [{"delta": {"content": "!", "role": "assistant"}, "index": 0}], "created": 1721007348, "id": "chatcmpl-YzczYjVhNjhjMzMwNDQ5MDkyNGYzOGZjZGE1ZGQ5OGU", "model": "gpt-4", "object": "chat.completion.chunk", "recipient": "all"}
data: {"choices": [{"delta": {"content": " How", "role": "assistant"}, "index": 0}], "created": 1721007348, "id": "chatcmpl-YzczYjVhNjhjMzMwNDQ5MDkyNGYzOGZjZGE1ZGQ5OGU", "model": "gpt-4", "object": "chat.completion.chunk", "recipient": "all"}
data: {"choices": [{"delta": {"content": " can", "role": "assistant"}, "index": 0}], "created": 1721007348, "id": "chatcmpl-YzczYjVhNjhjMzMwNDQ5MDkyNGYzOGZjZGE1ZGQ5OGU", "model": "gpt-4", "object": "chat.completion.chunk", "recipient": "all"}
data: {"choices": [{"delta": {"content": " I", "role": "assistant"}, "index": 0}], "created": 1721007348, "id": "chatcmpl-YzczYjVhNjhjMzMwNDQ5MDkyNGYzOGZjZGE1ZGQ5OGU", "model": "gpt-4", "object": "chat.completion.chunk", "recipient": "all"}
data: {"choices": [{"delta": {"content": " assist", "role": "assistant"}, "index": 0}], "created": 1721007348, "id": "chatcmpl-YzczYjVhNjhjMzMwNDQ5MDkyNGYzOGZjZGE1ZGQ5OGU", "model": "gpt-4", "object": "chat.completion.chunk", "recipient": "all"}
data: {"choices": [{"delta": {"content": " you", "role": "assistant"}, "index": 0}], "created": 1721007348, "id": "chatcmpl-YzczYjVhNjhjMzMwNDQ5MDkyNGYzOGZjZGE1ZGQ5OGU", "model": "gpt-4", "object": "chat.completion.chunk", "recipient": "all"}
data: {"choices": [{"delta": {"content": " today", "role": "assistant"}, "index": 0}], "created": 1721007348, "id": "chatcmpl-YzczYjVhNjhjMzMwNDQ5MDkyNGYzOGZjZGE1ZGQ5OGU", "model": "gpt-4", "object": "chat.completion.chunk", "recipient": "all"}
data: {"choices": [{"delta": {"content": "?", "role": "assistant"}, "index": 0}], "created": 1721007348, "id": "chatcmpl-YzczYjVhNjhjMzMwNDQ5MDkyNGYzOGZjZGE1ZGQ5OGU", "model": "gpt-4", "object": "chat.completion.chunk", "recipient": "all"}
data: {"choices": [{"delta": {"role": "assistant"}, "index": 0}], "created": 1721007348, "id": "chatcmpl-YzczYjVhNjhjMzMwNDQ5MDkyNGYzOGZjZGE1ZGQ5OGU", "model": "gpt-4", "object": "chat.completion.chunk", "recipient": "all"}
data: {"choices": [{"delta": {"role": "assistant"}, "finish_reason": "stop", "index": 0}], "created": 1721007349, "id": "chatcmpl-YzczYjVhNjhjMzMwNDQ5MDkyNGYzOGZjZGE1ZGQ5OGU", "model": "gpt-4", "object": "chat.completion.chunk", "recipient": "all"}
data: [DONE]可以看到,响应里面有许多 data ,data 里面的 choices 即为最新的回答内容,与上文介绍的内容一致。choices 是新增的回答内容,您可以根据结果来对接到您的系统中。同时流式响应的结束是根据 data 的内容来判断的,如果内容为 [DONE],则表示流式响应回答已经全部结束。返回的 data 结果一共有多个字段,介绍如下:
id,生成此次对话任务的 ID,用于唯一标识此次对话任务。model,选择的 OpenAI ChatGPT 官网模型。choices,ChatGPT 针对提问词给于的回答信息。
JavaScript 也是支持的,比如 Node.js 的流式调用代码如下:
javascript
const options = {
method: "post",
headers: {
accept: "application/json",
authorization: "Bearer {token}",
"content-type": "application/json",
},
body: JSON.stringify({
model: "gpt-4",
messages: [{ role: "user", content: "hello" }],
stream: true,
}),
};
fetch("https://api.acedata.cloud/openai/chat/completions", options)
.then((response) => response.json())
.then((response) => console.log(response))
.catch((err) => console.error(err));Java 样例代码:
java
JSONObject jsonObject = new JSONObject();
jsonObject.put("model", "gpt-4");
jsonObject.put("messages", [{"role":"user","content":"hello"}]);
jsonObject.put("stream", true);
MediaType mediaType = "application/json; charset=utf-8".toMediaType();
RequestBody body = jsonObject.toString().toRequestBody(mediaType);
Request request = new Request.Builder()
.url("https://api.acedata.cloud/openai/chat/completions")
.post(body)
.addHeader("accept", "application/json")
.addHeader("authorization", "Bearer {token}")
.addHeader("content-type", "application/json")
.build();
OkHttpClient client = new OkHttpClient();
Response response = client.newCall(request).execute();
System.out.print(response.body!!.string())其他语言可以另外自行改写,原理都是一样的。
多轮对话
如果您想要对接多轮对话功能,需要对 messages 字段上传多个提问词,多个提问词的具体示例如下图所示:
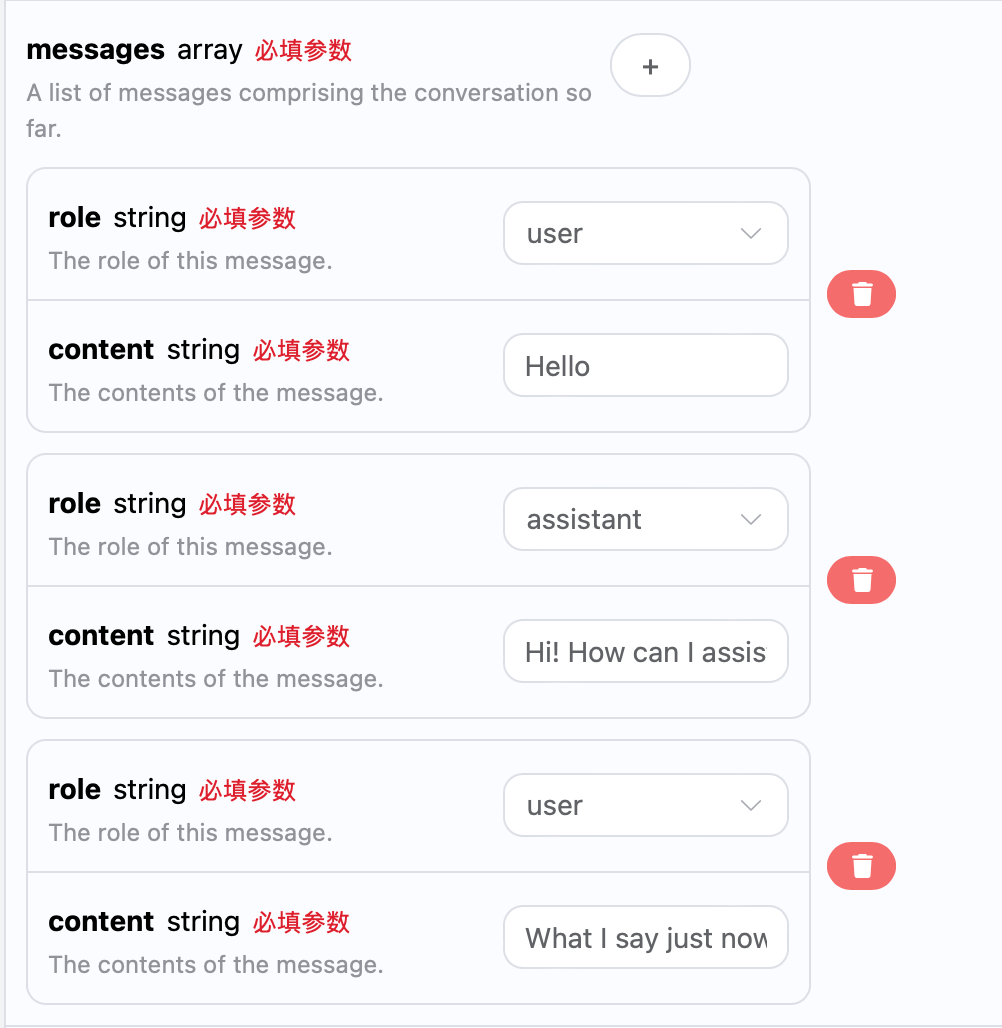
Python 样例调用代码:
python
import requests
url = "https://api.acedata.cloud/openai/chat/completions"
headers = {
"accept": "application/json",
"authorization": "Bearer {token}",
"content-type": "application/json"
}
payload = {
"model": "gpt-4",
"messages": [{"role":"user","content":"Hello"},{"role":"assistant","content":"Hi! How can I assist you today?"},{"role":"user","content":"What I say just now?"}]
}
response = requests.post(url, json=payload, headers=headers)
print(response.text)通过上传多个提问词,就可以轻松实现多轮对话,可以得到如下回答:
json
{
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "You said, \"Hello.\""
},
"finish_reason": "stop"
}
],
"created": 1721323012,
"id": "chatcmpl-NWZmOTA5MDlkZjBjNDRjNGEwMzRjYzA5NmM1MzQwMWY",
"model": "gpt-4",
"object": "chat.completion.chunk",
"recipient": "all",
"usage": {
"prompt_tokens": 31,
"completion_tokens": 6,
"total_tokens": 37
}
}可以看到,choices 包含的信息与基本使用的内容是一致的,这个包含了 ChatGPT 针对多个对话进行回复的具体内容,这样就可以根据多个对话内容来回答对应的问题了。
对接 OpenAI-Python
OpenAI Chat Completion API 服务的上游是官方的 OpenAI 服务,具体可查看官方 OpenAI-Python,本文将简要介绍如何使用官方提供的服务。
- 首先需要搭建本地
Python环境,此过程可谷歌搜索一下。 - 下载安装开发环境,比如安装 VSCode 编辑器。
- 配置
OpenAI环境变量。
- 在项目文件夹里,创建一个名为
.env的文件,并保存 .env文件内容:
json
OPENAI_API_KEY="sk-xxx"
OPENAI_BASE_URL="https://api.acedata.cloud/openai" # 再次提醒:如果你使用官网OpenAI的key,不要用这个地址。sk-xxx 使用自己的 key 替换。OPENAI_BASE_URL 是访问 OpenAI 的代理接口。
- 安装项目依赖的包
shell
pip install openaiMac OS 中命令为:
shell
pip3 install openai- 创建示例源代码文件
假设我们创建了一个示例代码 index.py ,具体内容如下:
python
import os
from openai import OpenAI
client = OpenAI(api_key=os.environ.get("OPENAI_API_KEY"))
response = client.chat.completions.create(
messages=[
{
"role": "user",
"content": "hello",
}
],
model="gpt-4",
)
print(response.text)联网模型
gpt-3.5-browsing 和 gpt-4-browsing 模型与其它模型不同,它可以根据提问词来进行联网搜索,并且将联网搜索的结果进行适当的调整返回给你,本文将通过一个具体示例来演示联网功能,接下来就可以在 OpenAI Chat Completion API 界面上填写对应的内容,如图所示:
同时您可以注意到右侧有对应的调用代码生成,您可以复制代码直接运行,也可以直接点击「Try」按钮进行测试。
调用之后,我们发现返回结果如下:
json
{
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "For the latest news in China today, you can check major news websites such as:\n\n- [BBC News China](https://www.bbc.com/news/world/asia/china)\n- [CNN China News](https://edition.cnn.com/china)\n- [Reuters China](https://www.reuters.com/news/archive/china-news)\n\nThese sources will have up-to-date information on current events in China."
},
"finish_reason": "stop"
}
],
"created": 1721009347,
"id": "chatcmpl-YzA0M2RjZDVkYThlNDkxNTkzOThmZWQ4OGMzNzdhNzA",
"model": "gpt-4-browsing",
"object": "chat.completion.chunk",
"recipient": "all",
"usage": {
"prompt_tokens": 325,
"completion_tokens": 82,
"total_tokens": 407
}
}可以看到,choices 里面的回答信息是根据联网查询后得到的,并且也给出了相关的链接,choices 里面的回答信息是要通过 markdown 语法进行渲染,这样才能获得最佳的体验,最后这也体现出我们模型的联网功能的强大优势。
视觉模型
gpt-4o 是 OpenAI 开发的多模态大型语言模型,它在 GPT-4 的基础上增加了视觉理解能力。这个模型可以同时处理文本和图像输入,实现了跨模态的理解和生成。
使用 gpt-4o 模型的文本处理是与上文的基本使用内容一致的,下面将简要介绍一下如果使用模型的图像处理能力。
使用 gpt-4o 模型的图像处理能力主要是通过在原有的 content 内容基础上添加一个 type 字段,通过该字段可以知道上传的是文本还是图片,从而使用 gpt-4o 模型的图像处理能力,下面主要讲述采用 Curl 和 Python 俩种方式来调用该功能。
-
Curl 脚本方式
curl -X POST 'https://api.acedata.cloud/openai/chat/completions'
-H 'accept: application/json'
-H 'authorization: Bearer {token}'
-H 'content-type: application/json'
-d '{
"model": "gpt-4o",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "What'''s in this image?"
},
{
"type": "image_url",
"image_url": {
"url": "https://upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Gfp-wisconsin-madison-the-nature-boardwalk.jpg/2560px-Gfp-wisconsin-madison-the-nature-boardwalk.jpg"
}
}
]
}
]
}' -
Python 脚本方式
python
import requests
url = "https://api.acedata.cloud/openai/chat/completions"
headers = {
"accept": "application/json",
"authorization": "Bearer {token}",
"content-type": "application/json"
}
payload = {
"model": "gpt-4o",
"messages": [
{
"role": "user",
"content": [
{
"type": "text", "text": "What's in this image?"
},
{
"type": "image_url",
"image_url": {
"url": "https://upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Gfp-wisconsin-madison-the-nature-boardwalk.jpg/2560px-Gfp-wisconsin-madison-the-nature-boardwalk.jpg"
}
},
],
}
]
}
response = requests.post(url, json=payload, headers=headers)
print(response.text)然后可以得到下面的结果,结果里面的字段信息是与上文一致的,具体的如下:
json
{
"id": "chatcmpl-123",
"object": "chat.completion",
"created": 1677652288,
"model": "gpt-4-vision-preview",
"system_fingerprint": "fp_44709d6fcb",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "\n\nThis image shows a wooden boardwalk extending through a lush green marshland."
},
"logprobs": null,
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 9,
"completion_tokens": 12,
"total_tokens": 21
}
}可以看到回答的内容是基于图片进行回答的,因此通过上述俩种方式可以轻松使用 gpt-4-vision 模型的文本和图像处理能力。
除了,gpt-4o,还有一个更低成本的模型,叫做 gpt-4o-mini。gpt-4o-mini 是 OpenAI 开发的最新一代大型语言模型,它不仅响应速度快,同时价格也更便宜,也支持多模态。vision 功能的使用可参考上文 gpt-4o 模型的使用的内容。
错误处理
在调用 API 时,如果遇到错误,API 会返回相应的错误代码和信息。例如:
400 token_mismatched:Bad request, possibly due to missing or invalid parameters.400 api_not_implemented:Bad request, possibly due to missing or invalid parameters.401 invalid_token:Unauthorized, invalid or missing authorization token.429 too_many_requests:Too many requests, you have exceeded the rate limit.500 api_error:Internal server error, something went wrong on the server.
错误响应示例
{
"success": false,
"error": {
"code": "api_error",
"message": "fetch failed"
},
"trace_id": "2cf86e86-22a4-46e1-ac2f-032c0f2a4e89"
}结论
通过本文档,您已经了解了如何使用 OpenAI Chat Completion API 轻松实现官方 OpenAI ChatGPT 的对话功能。希望本文档能帮助您更好地对接和使用该 API。如有任何问题,请随时联系我们的技术支持团队。