Python爬虫(基本篇)
一:静态页面爬取
Requests库的使用
1)基本概念+安装+基本代码格式
-
应用领域 :适合处理**
静态页面数据和简单的 HTTP 请求响应**。 -
Requests库的讲解
含义 :
requests库是 Python 中一个非常简单且强大的库,相当于urllib的升级版(此处不对urllib进行讲解),在Cookie,登录验证,代理设置等操作更加的便利。 -
请求头(UA)
UA介绍 :UA全名是User Agent,中文名为用户代理。它是一个特殊字符串头,使得服务器能够识别客户使用的操作系统及版本、CPU 类型、浏览器及版本。浏览器内核、浏览器渲染引擎、浏览器语言、浏览器插件等。
UA反爬虫是一种很常见的反爬手段,通过识别发送的请求中是否有需要的参数信息来判断这次访问是否由用户通过浏览器发起。
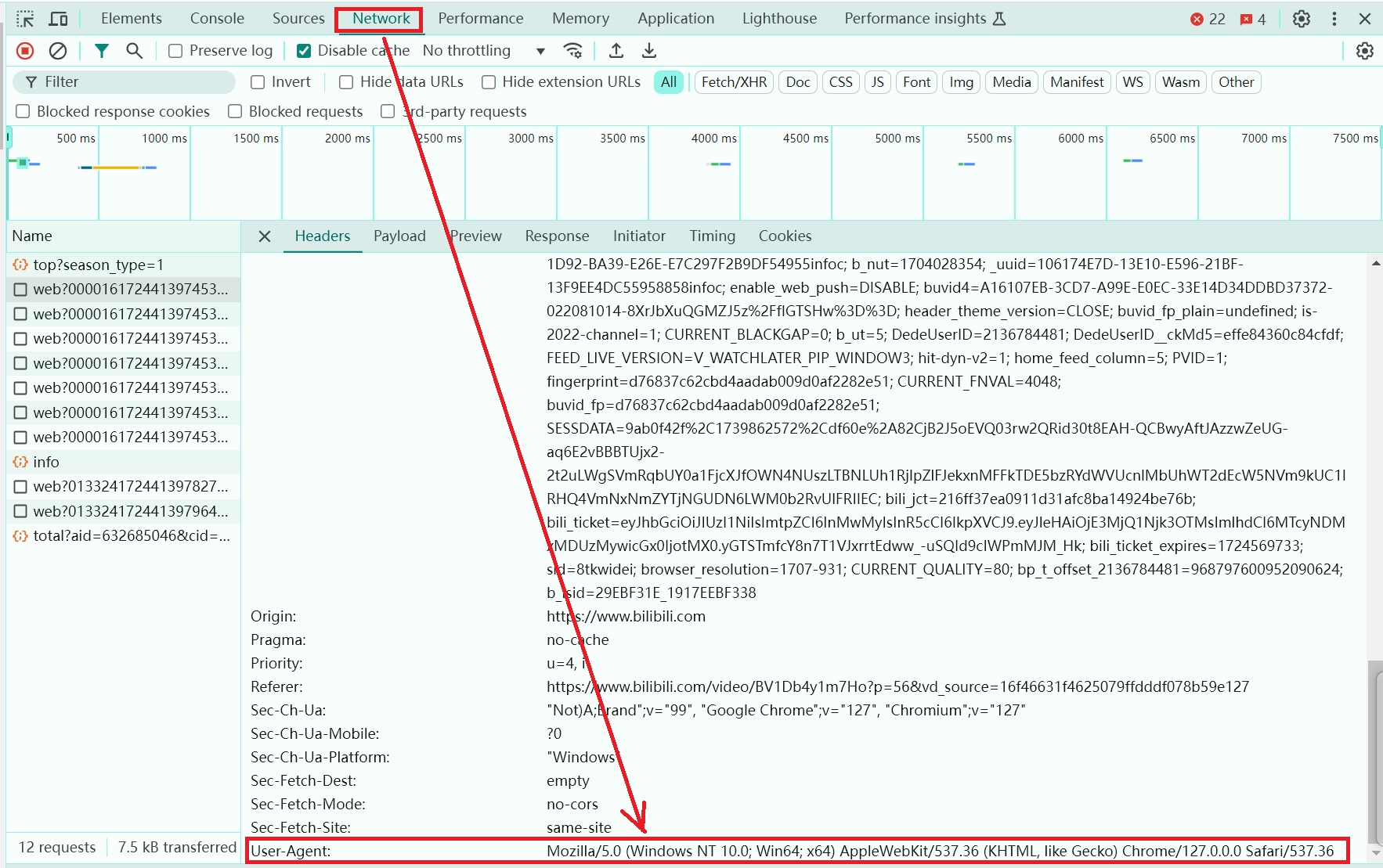
-
安装Requests基本步骤:在pycharm的控制台中需要手动安装requests库来进行操作即可。
shellpip install requests -
基本代码格式:不带参数的GET请求
pythonimport requests # 指定访问页面的地址 url = 'https://www.bilibili.com/' # 设置请求头 👈 headers = { 'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36', } # 模拟浏览器向服务器请求(response响应) 👈 response = requests.get(url=url,headers=headers) # 设置相应的编码格式为utf-8 response.encoding = 'utf-8' # 获取响应中的页面源码 content = response.text # 打印数据 print(content)
2)一个类型和六个属性
python
import requests
url = 'http://www.baidu.com'
response = requests.get(url=url)| 代码 | 讲解 | |
|---|---|---|
| 类型 | type(response) | requests.models.Response |
| 属性1 | response.encoding = 'utf-8' | 设置相应的编码格式:utf-8 |
| 属性2 | response.text | 以字符串形式返回网站源码 |
| 属性3 | response.url | 返回一个url地址 |
| 属性4 | response.content | 以二进制形式返回网站源码 |
| 属性5 | response.status_code | 返回响应状态码,正常为200 |
| 属性6 | response.headers | 返回响应头 |
3)GET请求实例
我们运用requests库中的GET请求来爬取如下的网页:
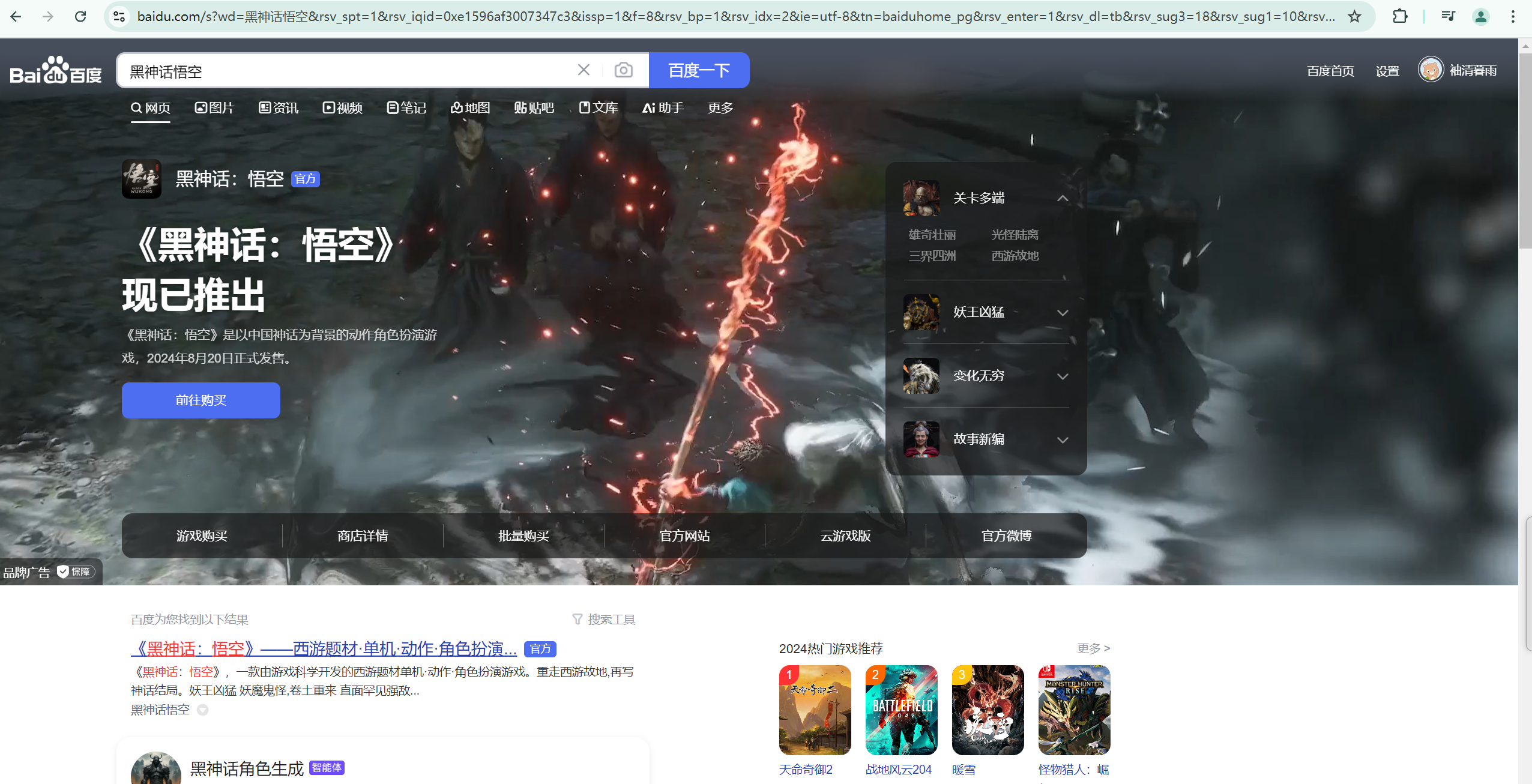
具体代码如下:发送带有请求参数的GET请求
python
import requests
# 要查询的完整路径:https://www.baidu.com/s?wd=黑神话悟空
# 此处为基本路径
url = 'https://www.baidu.com/s?'
# 设置请求头
headers = {
'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36',
}
# 查询参数:附加在url上 👈
# 这些查询参数通常以?符号开始,后面跟着一系列的键值对,键值对之间用&符号分隔
data = {
'wd': '黑神话悟空'
}
# 模拟浏览器向服务器请求(response响应) 👈
response = requests.get(url=url, params=data, headers=headers)
# 设置相应的编码格式:utf-8
response.encoding = 'utf-8'
# 获取响应中的页面源码
content = response.text
# 打印数据
print(content)4)POST请求实例
此处以百度翻译为例讲述POST请求。首先,在Network中寻找完整的POST发送信息(eye)的文件,如下图所示:
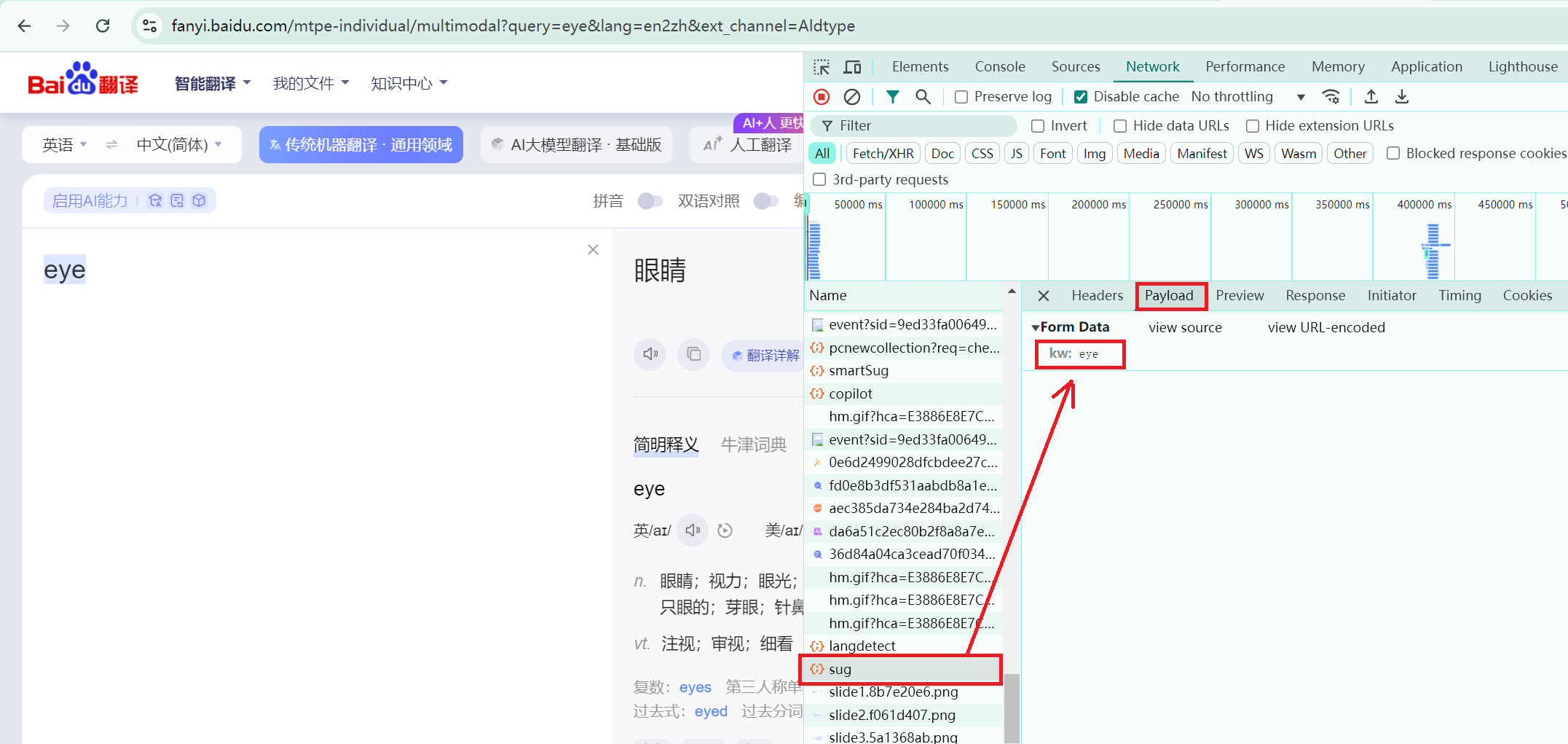
然后,对Headers中的url路径进行爬取操作:
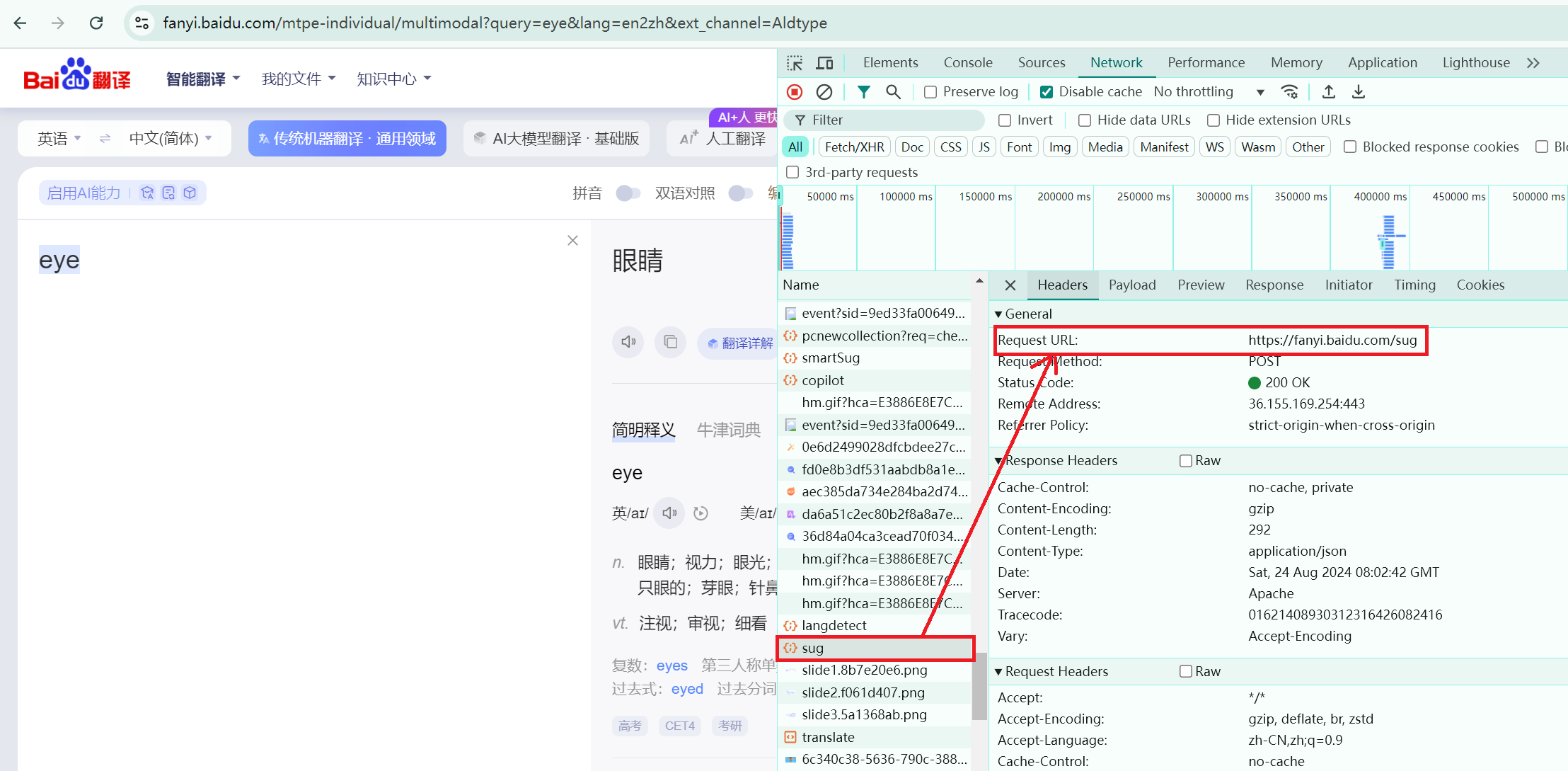
具体代码如下:发送带有请求参数的POST请求
python
import requests
import json
# 爬取的路径
url = 'https://fanyi.baidu.com/sug'
# 设置请求头
headers = {
'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36'
}
# POST发送信息:eye
data = {
'kw': 'eye'
}
# 模拟浏览器向服务器请求(response响应) 👈
response = requests.post(url=url,data=data,headers=headers)
# 设置相应的编码格式:utf-8
response.encoding = 'utf-8'
# 获取响应中的页面源码
content = response.text
# 将json类型转化为python类型
obj = json.loads(content)
print(obj)5)补充点:urllib下载功能
urllib是本身就有的,无需安装。
-
下载网页(http)
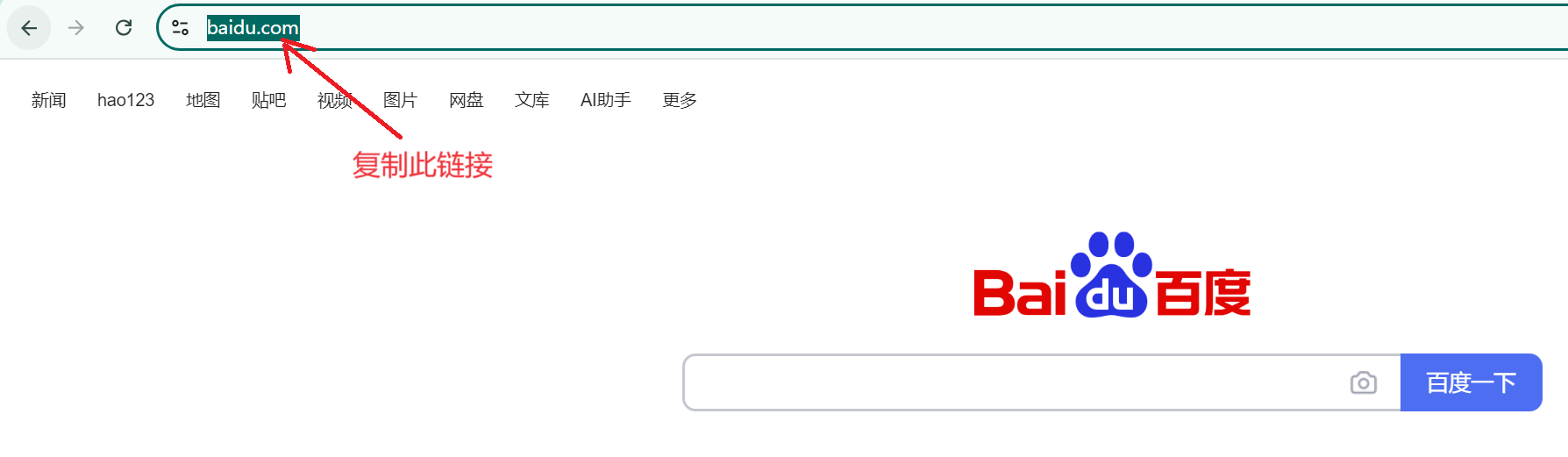 python
pythonimport urllib.request # 下载网页 url_page = 'http://www.baidu.com/' urllib.request.urlretrieve(url=url_page,filename='百度.html') -
下载图片
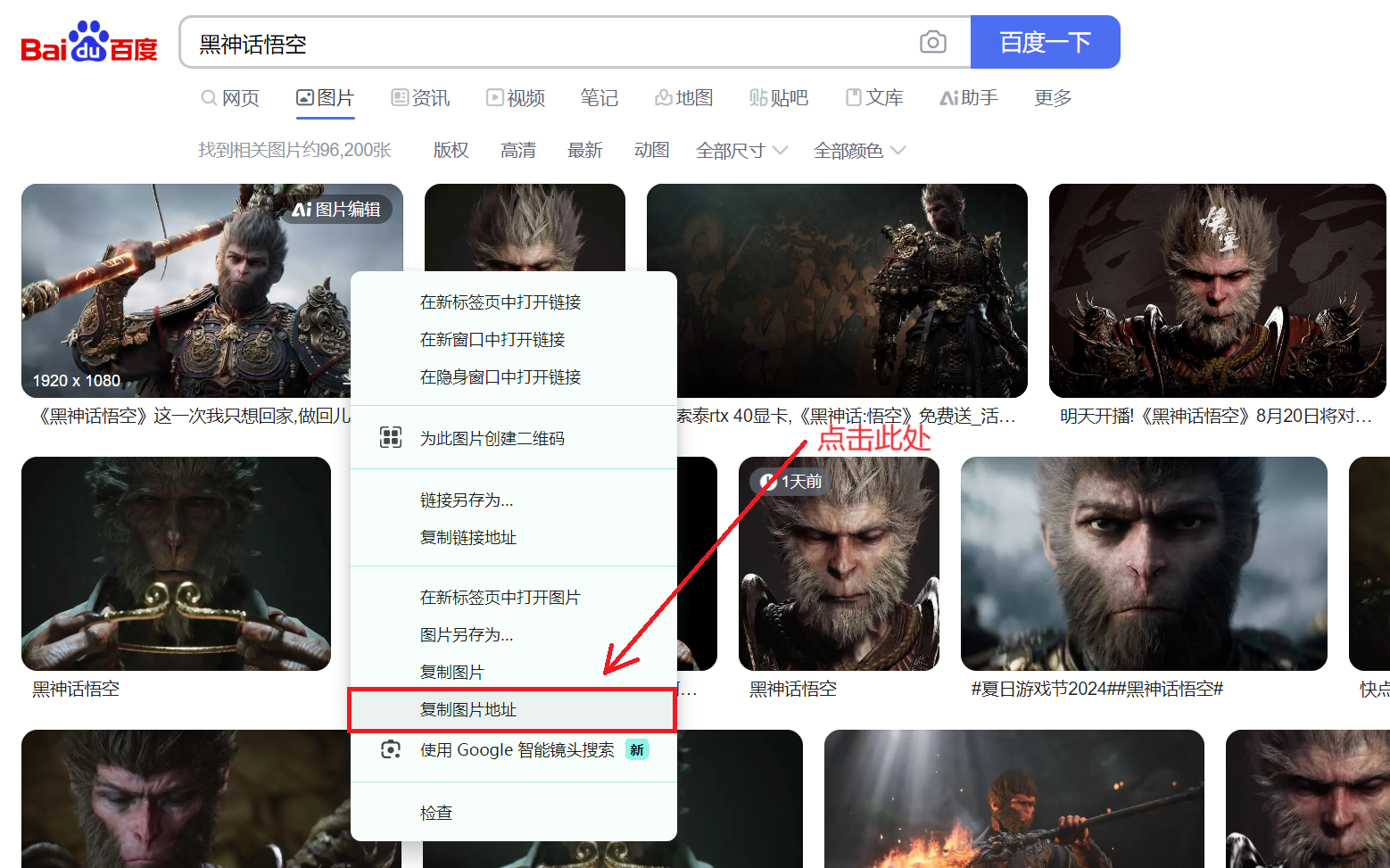 python
pythonimport urllib.request # 下载图片 url_img = 'https://img2.baidu.com/it/u=2239806468,3590288621&fm=253&fmt=auto&app=120&f=JPEG?w=889&h=500' urllib.request.urlretrieve(url=url_img,filename='wukong.png') -
下载视频
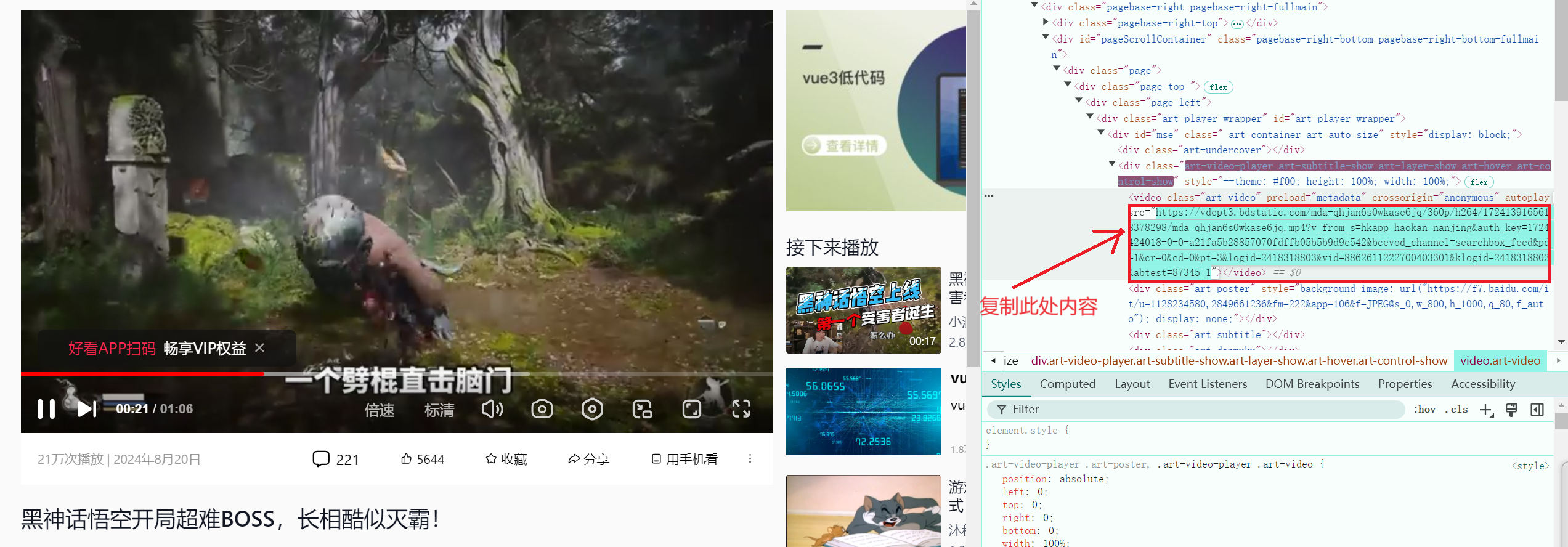 python
pythonimport urllib.request # 下载视频 url_video = 'https://vdept3.bdstatic.com/mda-qhjan6s0wkase6jq/360p/h264/1724139165618378298/mda-qhjan6s0wkase6jq.mp4?v_from_s=hkapp-haokan-nanjing&auth_key=1724424018-0-0-a21fa5b28857070fdffb05b5b9d9e542&bcevod_channel=searchbox_feed&pd=1&cr=0&cd=0&pt=3&logid=2418318803&vid=8862611222700403301&klogid=2418318803&abtest=87345_1' urllib.request.urlretrieve(url=url_video,filename='wukong.mp4')
二:JavaScript动态渲染页面爬取
Selenium库的使用
1)基本概念+安装+基本代码格式
-
应用领域 :适合处理需要
模拟用户操作的场景,如动态页面和复杂的用户交互。 -
Selenium库的讲解
含义 :
Selenium库是一个用于Web应用程序测试的工具,可以实现如同真正的用户操作一般。Selenium支持各种Driver驱动真实浏览器(火狐浏览器,Chrome浏览器等)完成测试,同时也支持无界面浏览器的操作。功能:模拟浏览器功能,自动执行网页中的js代码,实现动态加载。
-
安装Selenium基本步骤:
步骤一:查看谷歌浏览器的版本:设置-->帮助-->关于Chrome
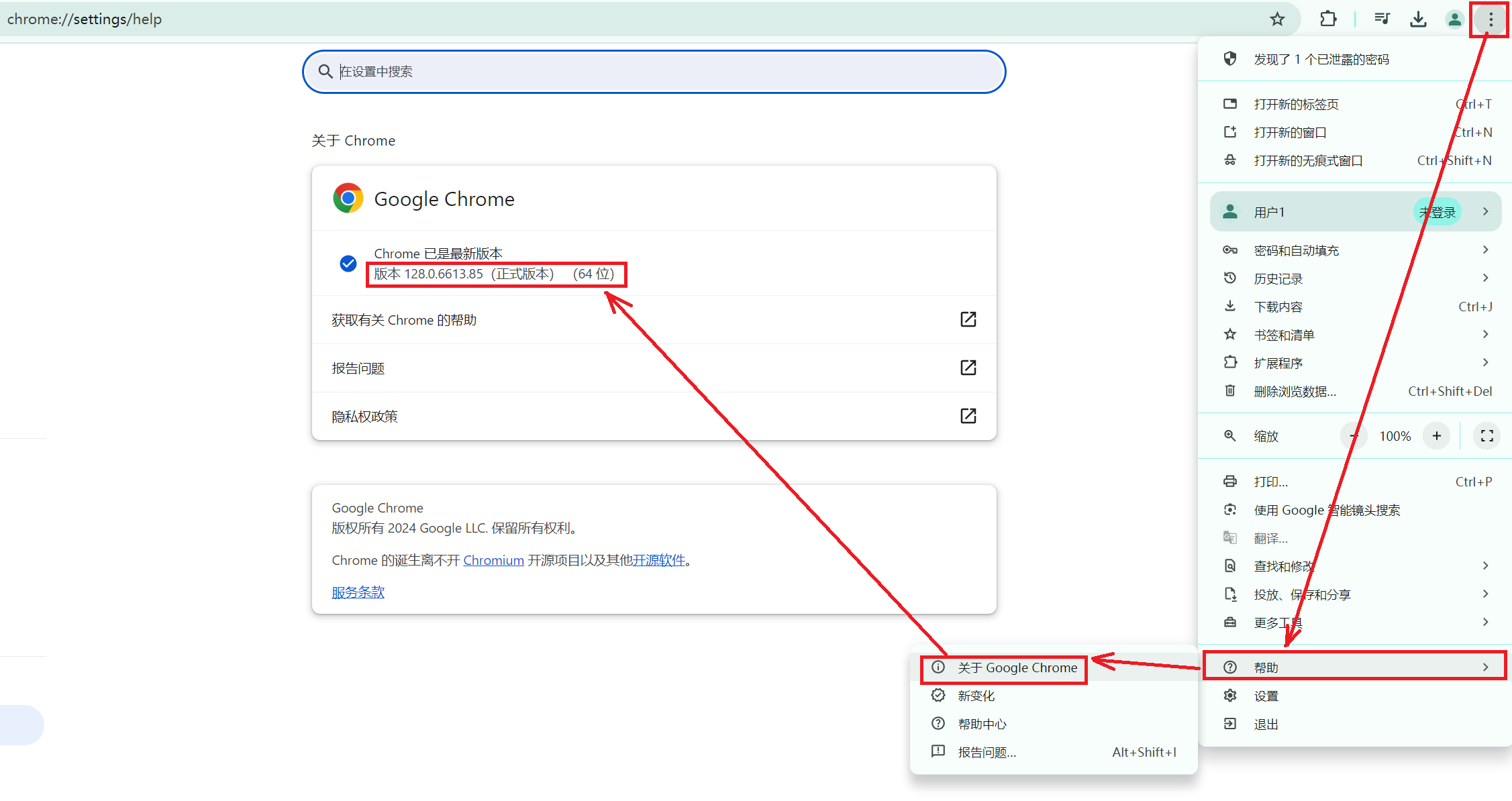
步骤二:下载对应版本的谷歌浏览器驱动
【注意事项】
-
Chrome版本在113之前对应下载的driver:CNPM Binaries Mirror (npmmirror.com)
-
Chrome版本在113-120对应下载的driver:CNPM Binaries Mirror或https://googlechromelabs.github.io/chrome-for-testing/
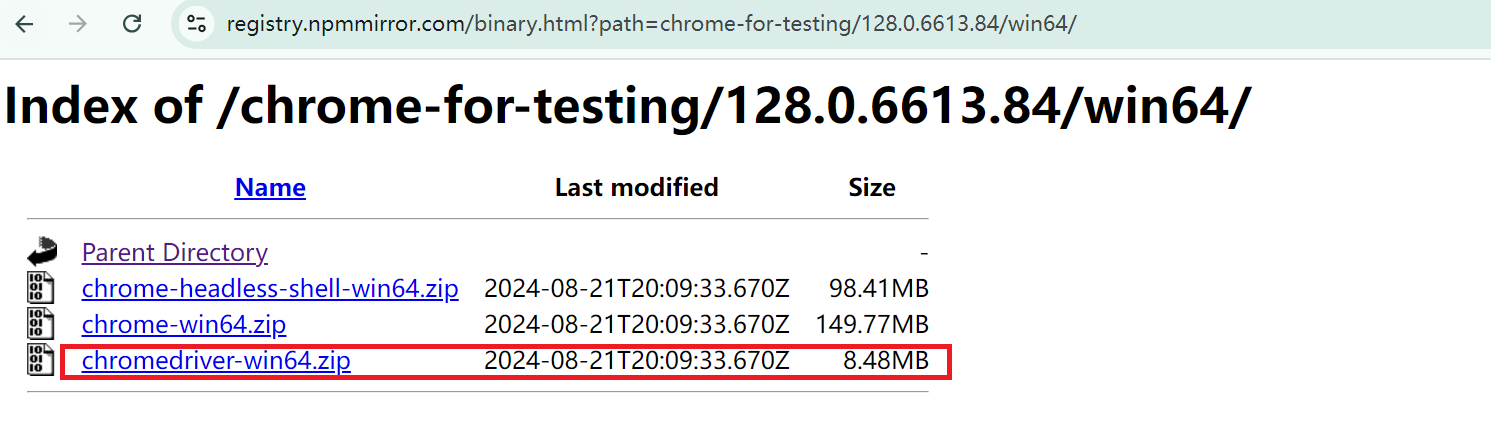
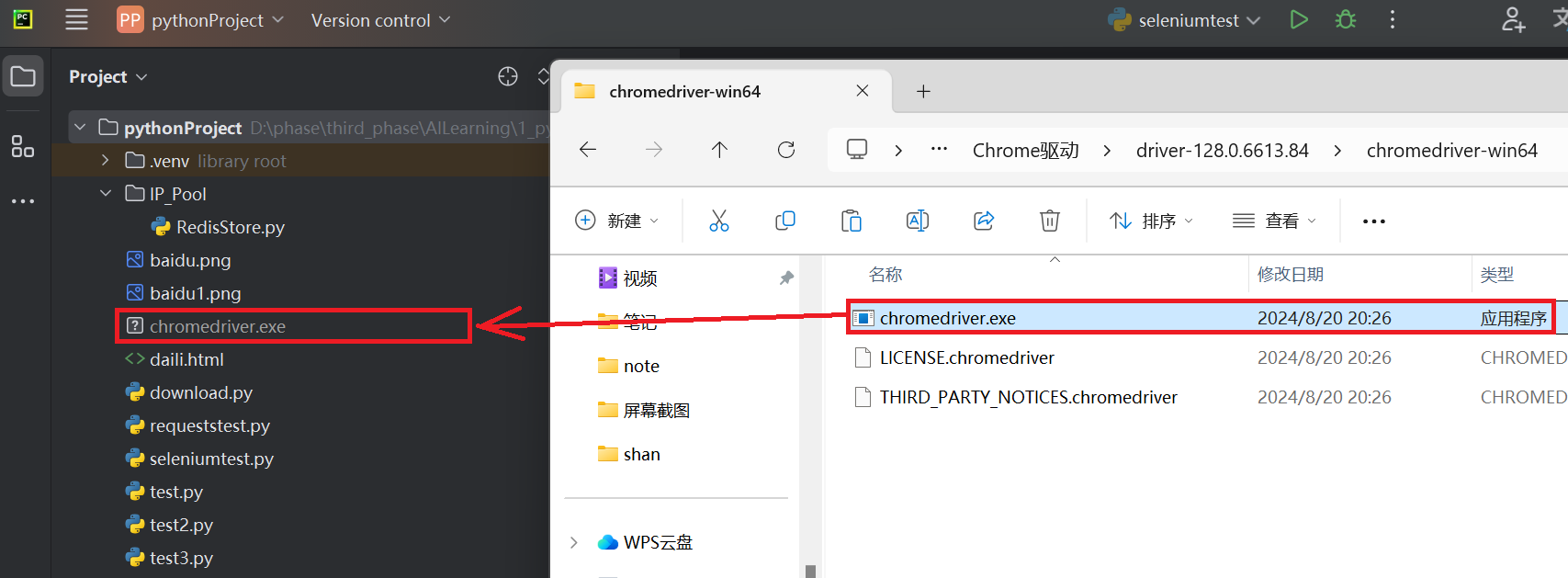
步骤三:将下载好的谷歌浏览器驱动解压,并将exe文件放置Pycharm目录下【无需安装exe文件】
步骤四:在Pycharm的控制台中下载Selenium
pythonpip install selenium -
-
基本代码格式:完成操作后会自动关闭,需要定义time.sleep来休眠一段时间。
pythonimport time from selenium import webdriver # 创建浏览器操作对象(自动将exe文件配置进来) => 整个浏览器窗口 driver = webdriver.Chrome() # 访问网站[必须添加] url = "https://www.jd.com" driver.get(url) # 打开网址 time.sleep(10)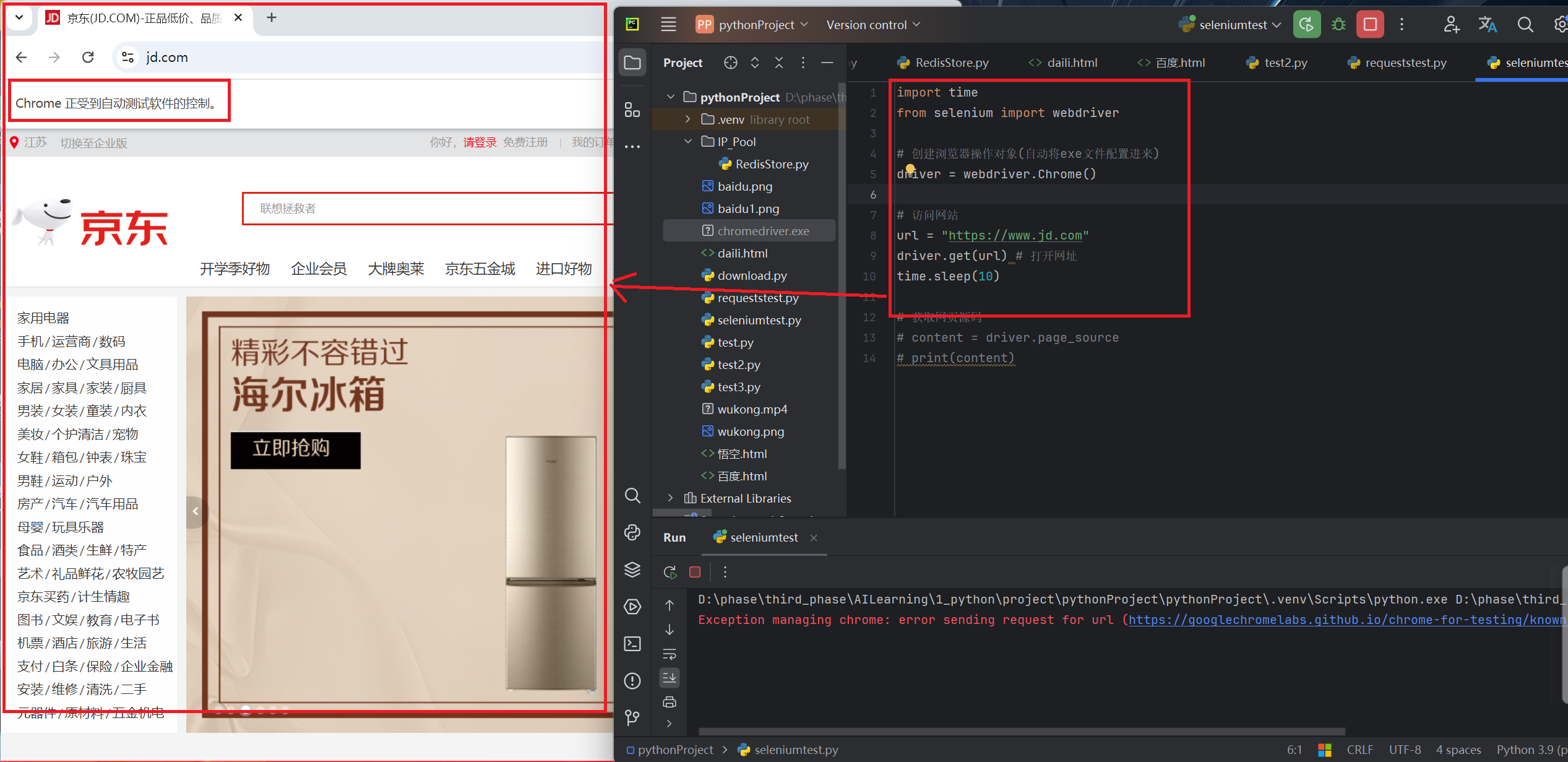
2)常规操作
2.1:浏览器窗口操作
用途:通过driver.get(url)操作打开浏览器窗口,可以对其窗口进行如下操作:
python
driver.maximize_window() # 浏览器窗口最大化 => 模拟浏览器最大化按钮
driver.set_window_size(100,100) # 设置浏览器窗口大小 => 设置浏览器宽,高(像素)
driver.set_window_position(300,200) # 设置浏览器窗口位置 => 设置浏览器位置
driver.back() # 后退 => 模拟浏览器后退按钮
driver.forward() # 前进 => 模拟浏览器前进按钮
driver.refresh() # 刷新 => 模拟浏览器F5刷新
driver.close() # 关闭 => 关闭单个浏览器窗口
driver.quit() # 关闭 => 关闭整个浏览器(所有窗口)2.2:元素定位
用途 :元素定位主要用于找到浏览器窗口中所需的对应元素,从而帮助我们进行点击,输入等操作。
获取单个元素:首个匹配到的元素对象 ✔
python
element=driver.find_element(By.ID,"kw") # 根据ID来获取对象 ✔
element=driver.find_element(By.CSS_SELECTOR,"#su") # 使用bs4语法来获取对象 ✔
element=driver.find_element(By.TAG_NAME,"div") # 根据标签名来获取对象
element=driver.find_element(By.NAME,"rsv_enter") # 根据标签属性的属性值name来获取对象
element=driver.find_element(By.LINK_TEXT,"视频") # 获取超链接的文本格式对象(a标签)CSS_SELECTOR使用方式讲解:
ID选择器 :使用
#符号后跟元素的ID来定位元素。如果有一个元素的ID是myElement,则CSS选择器为#myElement,如:driver.find_element(By.CSS_SELECTOR, "#myElement")类选择器 :使用
.符号后跟元素的类名(class)来定位元素。如果元素有一个类名为myClass,则CSS选择器为.myClass,如:driver.find_element(By.CSS_SELECTOR, ".myClass")属性选择器 :使用
[attribute=value]来选择具有特定属性及值的元素。例如,选择所有type="text"的<input>元素,如:driver.find_element(By.CSS_SELECTOR, "inputtype='text'")组合选择器 :你可以通过空格来组合选择器,以选择特定元素的后代元素。例如,选择所有在类名为
container的元素内部的<p>元素,如:driver.find_element(By.CSS_SELECTOR, ".container p")元素选择器 :直接使用元素的标签名来选择元素。例如,选择第一个
<div>元素,CSS选择器就是div,如:driver.find_element(By.CSS_SELECTOR, "div")
获取多个元素:所有匹配到的元素对象
python
elements=driver.find_elements(By.ID,"kw") # 根据ID来获取对象 ✔
elements=driver.find_elements(By.CSS_SELECTOR,"#su") # 使用bs4语法来获取对象 ✔
elements=driver.find_elements(By.TAG_NAME,"div") # 根据标签名来获取对象
elements=driver.find_elements(By.NAME,"rsv_enter") # 根据标签属性的属性值name来获取对象
elements=driver.find_elements(By.LINK_TEXT,"视频") # 获取超链接的文本格式对象(a标签)2.3:内容获取
用途 :在获取带所需的元素后,我们会对元素中的内容进行操作,如下所述:
python
整体浏览器窗口操作:
driver.title # 获取页面的标题
driver.current_url # 获取当前页面的URL
浏览器内特定元素操作:
element.size # 返回元素大小
element.text # 返回元素文本内容 ✔ => 如:在<div>百度</div>中,获取到的是"百度"
get_attribute("href") # 获取属性值 ✔ => 如:获取<a href="www.baidu.com">百度</a>中的"www.baidu.com"
is_display() # 判断元素是否可见 => 是否可见
is_enabled() # 判断元素是否可用 => 是否被创建3)页面操作【动态链】
3.1:鼠标操作
python
move_to_element(to_element) # 悬停 => 模拟鼠标悬停效果(与"元素定位"配合使用) ✔
click() # 点击(右击) ✔
context_click() # 右击 => 模拟鼠标右击效果
double_click() # 双击 => 模拟鼠标双击效果
drag_and_drop() # 滚动 => 模拟鼠标滚动页面效果
perform() # 执行操作 => 执行以上所有操作的启动器,无这个则无法执行以上操作 ✔小型案例:在百度中搜索"黑神话悟空"操作。
python
import time
from selenium import webdriver
from selenium.webdriver import ActionChains, Keys
from selenium.webdriver.common.by import By
import csv
# 创建浏览器操作对象(自动将exe文件配置进来) => 整个浏览器窗口
driver = webdriver.Chrome()
# 打开网页
url = 'https://www.baidu.com/'
driver.get(url)
# 找到输入框(元素定位)
kw = driver.find_element(By.ID,"kw")
# 向输入框中输入内容(键盘操作)
kw.send_keys("黑神话悟空")
# 点击按钮,进行搜查
button = driver.find_element(By.ID,"su")
# 鼠标悬停+点击操作(动作链,鼠标操作) 等同于 button.click(),效果一致
ActionChains(driver).move_to_element(button).click().perform()
# button.click() # 点击按钮
time.sleep(2) # 等待2s3.2:键盘操作
python
element.send_keys("内容") # 输入内容 ✔
element.send_keys(Keys.BACK_SPACE) # 删除键(BackSpace)
element.send_keys(Keys.SPACE) # 空格键(Space)
element.send_keys(Keys.ENTER) # 回车键(Enter)
element.send_keys(Keys.ESCAPE) # 回退键(Esc)
element.send_keys(Keys.CONTROL,'c') # 复制(Ctrl+C)
element.send_keys(Keys.CONTROL,'x') # 剪切(Ctrl+X)
element.send_keys(Keys.CONTROL,'v') # 粘贴(Ctrl+v)
element.send_keys(Keys.CONTROL,'a') # 全选(Ctrl+A)3.3:滚动条
在HTML页面中,由于前端技术框架原因,页面元素为动态显示,元素会根据滚动条的下拉而被加载。
python
# 1、设置JavaScript脚本控制滚动条
# window.scrollTo(x-coord, y-coord) => x-coord: 横向滚动距离,y-coord: 纵向滚动距离
js = "window.scrollTo(0,1000)"
# 2、WebDriver调用js脚本方法
driver.execute_script(js)3.4:窗口截图
如果在执行出错时候可以对当前窗口进行截图保存,从而通过截取到的图片来看到出错的原因。
python
# 截取当前窗口
driver.get_screenshot_as_file("./error.png") # error.png 当前窗口不可存在4)Selenium三种等待方式
显示等待
显式等待指定某个条件,然后设置最长等待时间。如果在这个时间还没有找到元素,那么便会抛出异常 了。 显示等待使用WebDriverWait完成【不常用】
WebDriverWait(driver, timeout, poll_frequency=POLL_FREQUENCY, ignored_exceptions=None)-
driver 所创建的浏览器
-
driver timeout 最长时间长度(默认单位:秒)
-
poll_frequency 间隔检测时长(每)默认0.5秒
-
ignored_exceptions 方法调用中忽略的异常,默认只抛出:找不到元素的异常
基础格式(webDriverWait+until+(判断条件))
until
直到调用的方法返回值为True
method:expected_conditions库中定义的方法
message :自定义报错信息
判断条件
python判断当前页面标题是否为title title_is(title) 判断当前页面标题是否包含title title_contains(title) 判断此定位的元素是否存在,presence_of_element_located(locator) 判断页面网址中是否包含url url_contains(url) 判断此定位的元素是否可见 EC.visibility_of_element_located(locator) ✔ 判断此元素是否可见 visibility_of(element) element:所获得的元素 判断此定位的一组元素是否至少存在一个 presence_of_all_elements_located(locator) 判断此定位的一组元素至少有一个可见,visibility_of_any_elements_located(locator) 判断此定位的一组元素全部可见visibility_of_all_elements_located(locator) 判断此定位中是否包含text_的内容,text_to_be_present_in_element(locator, text_) locator:元素的定位信息 text_:期望的文本信息 判断此定位中的value属性中是否包含text_的内容 text_to_be_present_in_element_value(locator, text_) locator:元素的定位信息 text_:期望的文本信息 判断定位的元素是否为frame,并直接切换到这个frame中 frame_to_be_available_and_switch_to_it(locator) locator:元素的定位信息 判断定位的元素是否不可见 invisibility_of_element_located(locator) locator:元素的定位信息 判断此元素是否不可见 invisibility_of_element(element) element:所获得的元素 判断所定位的元素是否可见且可点击 element_to_be_clickable(locator) locator:元素的定位信息 判断此元素是否不可用 staleness_of(element) element:所获得的元素 判断该元素是否被选中 element_to_be_selected(element) element:所获得的元素 判断定位的元素是否被选中 element_located_to_be_selected(locator) locator:元素的定位信息
简单案例:
python
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# 程序每0.5秒检查,是否满足:标题包含"百度一下"这个条件,检查是否满足条件的最长时间为:15秒,超过15秒仍未满足条件则抛出异常
WebDriverWait(driver, 15).until(EC.title_contains("百度一下"))
# 程序每0.5秒检查,是否满足:某定位的元素出现,检查是否满足条件的最长时间为:15秒,超过15秒仍未满足条件则抛出异常
WebDriverWait(driver, 15).until(EC.visibility_of_element_located(By.CSS_SELECTOR,"XX"))隐式等待
定义:通过设定的时长等待页面元素加载完成,再执行下面的代码,如果超过设定时间还未加载完成,则继续执行下面的代码(注意:在设定时间内加载完成则立即执行下面的代码)
python
# 隐性等待,最长等5秒
driver.implicitly_wait(5)强制等待
定义:强制让代码等待xxx时间【推荐】
python
# 强制让代码等待5s时间
time.sleep(5)5)小型案例
需求:进入当当页面,进行搜索"悬疑推理小说",并获取前5页中的小说信息。
python
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
# 创建浏览器操作对象(自动将exe文件配置进来) => 整个浏览器窗口
driver = webdriver.Chrome()
# 1、打开当当网页(必要步骤)
url = 'https://www.dangdang.com/'
driver.get(url)
# 2、获取输入框
searchBox = driver.find_element(By.ID,"key_S") # 锁定输入框
searchBox.send_keys("悬疑推理小说") # 输入内容
# 3、获取搜索框,点击搜索
search = driver.find_element(By.CSS_SELECTOR,".search .button") # 锁定搜索框
search.click() # 点击搜索
# 4、获取数据
# 循环5次(5页)
for i in range(5):
shopList = driver.find_elements(By.CSS_SELECTOR,".bigimg li")
# 从获取到的商品列表中寻找所需的内容并打印出来
for shop in shopList:
print(shop.find_element(By.CSS_SELECTOR, "a").get_attribute("title"))
print(shop.find_element(By.CSS_SELECTOR, ".price .search_now_price").text)
# 等待5s
time.sleep(5)
# 点击下一页
next = driver.find_element(By.LINK_TEXT,"下一页")
next.click()
time.sleep(5)三:网络数据的解析提取
1)XPath解析
1.1. 基本概念
XPath,全称为XML Path Language(可扩展标记语言路径语言),用来在XML文档中查找信息。它基于XML的树状结构,提供在数据结构树中找寻节点的能力。XPath不仅适用于XML文档,也常被用于HTML文档的搜索。
在实际应用中,将获取到的网页内容进行解析,从而得到所需的内容。
1.2. xpath安装
-
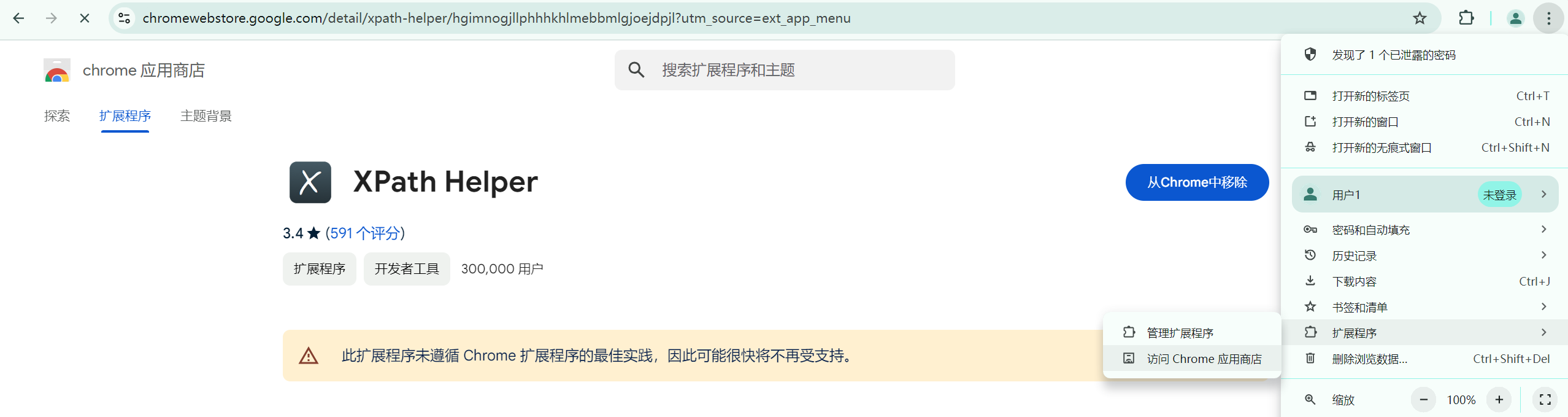
xpath浏览器插件:
打开Chrome浏览器,点击右上角小圆圈,然后选择"扩展程序"中的"Chrome应用商店"。在搜索栏中进行搜索"XPath Helper",进行安装即可【ctrl+shift+x】。
-
xpath在PyCharm中的安装:
shpip install lxml
1.3. xpath基本语法
-
路径查询:
python// :查找所有子孙节点,不考虑层级关系(所有后代节点)。 / :找直接子节点。 -
谓词查询:
python# 查找所有有id属性的li标签【关键部分://div[@id]】 list2 = tree.xpath("//ul/li[@id]") # 查找id为l1的li标签【关键部分://div[@id="maincontent"]】 list4 = tree.xpath('//ul/li[@id="l1"]/text()') -
属性查询:
python@class # 获取class属性值 @value # 获取value属性值 @alt # 获取alt属性值 ... -
内容查询:
python# 查看li标签所有内容(内容查询)【关键部分:text()】 list3 = tree.xpath("//ul/li/text()") -
模糊查询:
python# 查找id中包含l的li标签【关键部分:contains】 list6 = tree.xpath('//ul/li[contains(@id,"l")]/text()') # 查找id中以c开头的li标签【关键部分:starts-with】 list7 = tree.xpath('//ul/li[starts-with(@id,"c")]/text()')补充知识点 :
在pycharm编译器中无法编译含有空格的class,如以下的形式:
python//div[@class="flash-list-box loginItemList masonry-list clearfix masonry"]//img/@alt以上的写法是无法编译的。因此,我们需要将其写出如下形式:
python//div[contains(@class, 'flash-list-box') and contains(@class, 'loginItemList') and contains(@class, 'masonry-list') and contains(@class, 'clearfix') and contains(@class, 'masonry')]//img/@alt -
逻辑运算:
python# 查询id为l1和class为c1的li标签【关键部分:and】 tree.xpath('//ul/li[@id="l1" and @class="c1"]/text()') # 查询id为l1或l2的li标签【关键部分:|】 tree.xpath('//ul/li[@id="l1"]/text() | //ul/li[@id="l2"]/text()')
1.4. Xpath实际操作
本地文件解析:etree.parse
基本格式:tree.xpath("xpath路径")
注意 :
xpath路径采取的是"xpath基本语法"文本内容:
html<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"/> <meta name="viewport" content="width=device-width, initial-scale=1.0"/> <title>Document</title> </head> <body> <ul> <li id="l1" class="c1">上海</li> <li id="l2">苏州</li> <li id="c3">南京</li> <li id="c4">连云港</li> </ul> </body> </html>具体代码:
pythonfrom lxml import etree # xpath解析本地文件(完整路径) tree = etree.parse("D:/phase/third_phase/AILearning/1_python/project/pythonProject/pythonProject/test.html") # 属性查询 # 查找到id为l1的li标签的class属性值 list = tree.xpath('//ul/li[@id="l1"]/@class') print(list) print(len(list)) --------------------------- ['c1'] 1 ---------------------------服务器响应数据解析:etree.HTML()
案例:爬取"站长素材"网站中的前2页的图片内容,并进行下载至loveImgs目录下。
pythonimport urllib.request import time import requests from lxml import etree # 请求对象的定制 def create_response(page): if(page==1): url = 'https://sc.chinaz.com/donghua/index.html' else: url = 'https://sc.chinaz.com/donghua/index_' + str(page) +'.html' headers = { 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36', } response = requests.get(url=url,headers=headers) return response # 获取网页源码: def get_content(response): response.encoding = 'utf-8' return response.text # 下载图片 def down_load(content): tree = etree.HTML(content) name_list = tree.xpath('//div[@class="left-div"]//div//img/@alt') # 一般涉及到图片网站都会涉及到懒加载,因此需要进行处理 img_urls = [] for img in tree.xpath('//div[@class="left-div"]//div/img'): data_original = img.get('data-original') if data_original: img_urls.append(data_original) else: src = img.get('src') img_urls.append(src) # 最终处理 for i in range(len(img_urls)): src = img_urls[i] name = name_list[i] url = 'https:' + src # 图片的下载至指定的文件(loveImgs)中 urllib.request.urlretrieve(url=url,filename='./loveImgs/' + name + ".png") # main函数 if __name__ == '__main__' : start_page = int(input("请输入起始页码:")) end_page = int(input("请输入结束页码:")) for page in range(start_page,end_page+1): # (1)请求对象的定制 response = create_response(page) # (2)获取网页源码 content = get_content(response) # (3)下载图片 down_load(content)
2)Beautiful Soup解析(bs4)
2.1. 基本概念
Beautiful Soup简称bs4,和lxml一样,是一个html解析器,主要功能是解析和提取数据。
2.2. bs4安装
在pycharm的控制台中需要手动安装bs4库来进行操作即可。
shell
pip install bs42.3. bs4基本语法
文本内容:
html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8"/>
<meta name="viewport" content="width=device-width, initial-scale=1.0"/>
<title>Document</title>
</head>
<body>
<ul>
<li id="l1">上海</li>
<li id="l2">苏州</li>
<li>南京</li>
</ul>
<span>hahaha</span>
<a href="https://www.baidu.com" id="baidu" class="a1">百度</a>
<a href="https//www.bilibili.com" id="bilibili" title="a2">哔哩哔哩</a>
<div>
<ul>
<li id="l11">上海1</li>
<li id="l22">苏州1</li>
<li>南京1</li>
<a href="https://www.baidu.com" class="a1">百度1</a>
</ul>
</div>
<div id="h1">
<span>
哈基米
</span>
</div>
<p id="p1" class="p1">锦木千束</p>
</body>
</html>-
创建对象:
python#服务器响应的文件生成对象: 基本形式:soup = BeautifulSoup(文件内容,解析器) 案例: response = requests.get(url=url,headers=headers) response.encoding = 'utf-8' content = response.text soup = BeautifulSoup(content,'lxml') #本地文件生成对象: 基本形式:soup = BeautifulSoup(open(文档路径, encoding=编码格式),解析器) 案例:soup = BeautifulSoup(open('./bs4.html',encoding='utf-8'),'lxml') 注意:默认打开文件的编码格式gbk,所以需指定打开的编码格式为utf-8 -
节点定位:
(1)根据标签名来查找节点【解析本地文件】
pythonfrom bs4 import BeautifulSoup # 通过解析本地文件 来对bs4基本语法进行讲解 soup = BeautifulSoup(open('./bs4.html',encoding='utf-8'),'lxml') print(soup.a) # 只找到【第一个符合条件的数据】 => 只找到第一个a print(soup.a.attrs) # 获取标签的【属性】和【属性值】 => 获取第一个a中的属性和属性值 -------------------------------------------------------------------- <a class="a1" href="https://www.baidu.com" id="baidu">百度</a> {'href': 'https://www.baidu.com', 'id': 'baidu', 'class': ['a1']} --------------------------------------------------------------------(2)bs4函数
-
.find(返回第一个符合条件的数据)
小型总结:
pythonfind('a'): 只找到第一个a标签 find('a',title='名字') find('a',class_='名字')具体案例:
pythonfrom bs4 import BeautifulSoup # 通过解析本地文件 来对bs4基本语法进行讲解 soup = BeautifulSoup(open('./bs4.html',encoding='utf-8'),'lxml') # 返回第一个a标签的数据 print(soup.find('a')) # 根据title值找到对应的标签对象 print(soup.find('a',title="a2")) # 根据class值找到对应的标签对象,注意:class需要添加下划线 print(soup.find('a',class_="a1")) ---------------------------------------------------------------------- <a class="a1" href="https://www.baidu.com" id="baidu">百度</a> <a href="https//www.bilibili.com" id="bilibili" title="a2">哔哩哔哩</a> <a class="a1" href="https://www.baidu.com" id="baidu">百度</a> ---------------------------------------------------------------------- -
.find_all(返回一个列表)
小型总结:
pythonfind_all('a'): 找到所有的a标签 find_all(['a','p']): 返回所有的a标签和p标签 find_all('li',limit=2): 只找前2个li标签具体案例:
pythonfrom bs4 import BeautifulSoup # 通过解析本地文件 来对bs4基本语法进行讲解 soup = BeautifulSoup(open('./bs4.html',encoding='utf-8'),'lxml') # 返回的是一个列表,并且返回所有的a标签 print(soup.find_all('a')) print("=============================================") # 获取多个标签的数据,需要在find_all参数中添加的是列表的数据 print(soup.find_all(['a','p'])) print("=============================================") # limit作用是查找前几个数据 print(soup.find_all('li')) print(soup.find_all('li',limit=2)) ---------------------------------------------------------------------------- [<a class="a1" href="https://www.baidu.com" id="baidu">百度</a>, <a href="https//www.bilibili.com" id="bilibili" title="a2">哔哩哔哩</a>, <a class="a1" href="https://www.baidu.com">百度1</a>] ============================================= [<a class="a1" href="https://www.baidu.com" id="baidu">百度</a>, <a href="https//www.bilibili.com" id="bilibili" title="a2">哔哩哔哩</a>, <a class="a1" href="https://www.baidu.com">百度1</a>, <p class="p1" id="p1">锦木千束</p>] ============================================= [<li id="l1">上海</li>, <li id="l2">苏州</li>, <li>南京</li>, <li id="l11">上海1</li>, <li id="l22">苏州1</li>, <li>南京1</li>] [<li id="l1">上海</li>, <li id="l2">苏州</li>] ---------------------------------------------------------------------------- -
.select(根据选择器得到节点对象)【推荐】
注意:select 方法返回的是一个列表,并且会返回多个数据
小型总结:
python(1) element 如:soup.select('a') # 找到所有a标签 (2) .class 如:soup.select('.a1') # 根据class来获取数据【获取class为a1的数据】 (3) #id 如:soup.select('#bilibili') # 根据id来获取数据【获取id为bilibili的数据】 (4) 属性选择器 结构:[属性] 如:li = soup.select('li[id]') # 查找所有含有id属性的li标签 结构:[属性=值] 如:li = soup.select('li[id="l2"]') # 查找所有含有id为l2的li标签 (5) 层级选择器 结构:element element【后代选择器】 如:soup.select('div li') # 找到所有div标签内的li标签的数据 结构:element > element【子代选择器】 如:soup.select('div > ul > li') # 找到所有div标签中ul标签内的li标签数据 结构:element,element 如:soup.select('a,li') # 找到所有a标签和li标签的数据具体案例:
pythonfrom bs4 import BeautifulSoup # 通过解析本地文件 来对bs4基本语法进行讲解 soup = BeautifulSoup(open('./bs4.html',encoding='utf-8'),'lxml') # 找到所有a标签 print(soup.select('a')) print("=============================================") # 根据class来获取数据 print(soup.select('.a1')) # 获取class为a1的数据 print("=============================================") # 根据id来获取数据 print(soup.select('#bilibili')) # 获取id为bilibili的数据 print("=============================================") # 查找所有含有id属性的li标签 print(soup.select('li[id]')) print("=============================================") # 查找所有含有id为l2的li标签 print(soup.select('li[id="l2"]')) print("=============================================") # 后代选择器:找到所有div标签内的li标签的数据 print(soup.select('div li')) print("=============================================") # 子代选择器:某标签的第一个子标签 print(soup.select('div > ul > li')) # 找到所有div标签中ul标签内的li标签数据 print("=============================================") # 找到所有a标签和li标签的数据 print(soup.select('a,li')) ---------------------------------------------------------------------- [<a class="a1" href="https://www.baidu.com" id="baidu">百度</a>, <a href="https//www.bilibili.com" id="bilibili" title="a2">哔哩哔哩</a>, <a class="a1" href="https://www.baidu.com">百度1</a>] ============================================= [<a class="a1" href="https://www.baidu.com" id="baidu">百度</a>, <a class="a1" href="https://www.baidu.com">百度1</a>] ============================================= [<a href="https//www.bilibili.com" id="bilibili" title="a2">哔哩哔哩</a>] ============================================= [<li id="l1">上海</li>, <li id="l2">苏州</li>, <li id="l11">上海1</li>, <li id="l22">苏州1</li>] ============================================= [<li id="l2">苏州</li>] ============================================= [<li id="l11">上海1</li>, <li id="l22">苏州1</li>, <li>南京1</li>] ============================================= [<li id="l11">上海1</li>, <li id="l22">苏州1</li>, <li>南京1</li>] ============================================= [<li id="l1">上海</li>, <li id="l2">苏州</li>, <li>南京</li>, <a class="a1" href="https://www.baidu.com" id="baidu">百度</a>, <a href="https//www.bilibili.com" id="bilibili" title="a2">哔哩哔哩</a>, <li id="l11">上海1</li>, <li id="l22">苏州1</li>, <li>南京1</li>, <a class="a1" href="https://www.baidu.com">百度1</a>] ----------------------------------------------------------------------
-
-
节点信息:
用途 :通常与节点
定位配合使用,在获取到对象后,就可以获取节点的相关信息,如:内容,输出等小型总结:
python(1) 获取节点内容:适用于标签中嵌套标签的结构 obj.string obj.get_text() 【推荐】 注意: 如果标签对象中 只有内容(如:<div>哈基米</div>),则string和get_text()都可以使用,获取"哈基米"。 如果标签对象中 除了内容还有标签(如:<div><span>哈基米</span></div>),则string就无法获取数据,而get_text()可以获取数据"哈基米"。 (2) 节点的属性 obj.name: 获取标签名(如:li,span等) obj.attrs: 属性值作为一个字典返回(如:{'id': 'p1', 'class': ['p1']}) (3) 获取节点属性 obj.attrs.get('class') 【推荐】 obj.get('class') obj['class'] 注意:三个方法效果一致(如:<p id="p1" class="p1">锦木千束</p>),其中返回的都是['p1']具体案例:
pythonfrom bs4 import BeautifulSoup # 通过解析本地文件 来对bs4基本语法进行讲解 soup = BeautifulSoup(open('./bs4.html',encoding='utf-8'),'lxml') # 获取节点内容 obj1 = soup.select('#h1')[0] # 获取对象 print(obj1.string) print(obj1.get_text()) # 【推荐】 print("===============================") # 节点属性 obj2 = soup.select('#p1')[0] # 获取对象 print(obj2.name) # 标签名:p print(obj2.attrs) # 将属性值作为一个字典返回:{'id': 'p1', 'class': ['p1']} print("===============================") # 获取节点属性 print(obj2.attrs.get('class')) # 【推荐】 print(obj2.get('class')) print(obj2['class']) --------------------------------------------------------- None 哈基米 =============================== p {'id': 'p1', 'class': ['p1']} =============================== ['p1'] ['p1'] ['p1'] ---------------------------------------------------------
2.4. bs4实际操作
案例:爬取麦当劳网页中的汉堡菜单(图片+文字)
python
import requests
from bs4 import BeautifulSoup
# 获取网页源码
url = 'https://www.mcdonalds.com.cn/index/Food/menu/burger'
headers = {
'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36'
}
response = requests.get(url=url,headers=headers)
response.encoding = 'utf-8'
context = response.text
# bs4解析
soup = BeautifulSoup(context,'lxml')
# 节点定位
imgs = soup.select('div[class="row"] div[class="pic"] img')
names = soup.select('div[class="row"] span[class="name"]')
# 节点信息获取
for i in range(len(imgs)):
img = imgs[i].attrs.get('src')
name = names[i].get_text()
print(name,img)四:数据的存储
1)TXT文本文件存储
| 打开方式 | 解释 |
|---|---|
| r | 以只读方式打开文件 |
| rb | 以二进制只读方式打开一个文件 |
| r+ | 以读写方式打开一个文件 |
| rb+ | 以二进制读写方式打开一个文件 |
| w | 以写入方式打开文件 |
| wb | 以二进制写入方式打开一个文件 |
| w+ | 以读写方式打开一个文件 |
| wb+ | 以二进制读写方式打开一个文件 |
| a | 以追加方式打开一个文件 |
| ab | 以二进制追加方式打开一个文件 |
| a+ | 以读写方式打开一个文件 |
| ab+ | 以二进制追加方式打开一个文件 |
-
【写入】数据操作:
python# 数据 data = "你好,天命人" # 写入操作 with open('test.txt', 'a', encoding='utf-8') as f: f.write(data) -
【读取】数据操作:
pythonf = open('test.txt', 'r', encoding='utf-8') context = f.read() print(context)
2)CSV文本文件存储
-
【写入】数据操作:
pythonimport csv # 以写入方式打开文件,如果文件不存在则自动创建 f = open("./test.csv",'w') # 获取csv的writer对象,用于写入csv格式数据 writer = csv.writer(f) # 写入数据 writer.writerow(["张三","男","1.6"]) # 关闭文件 f.close()简化写法:
pythonimport csv with open('./data.csv','w',encoding='utf-8') as csvfile: fieldnames = ['id','name','age'] writer = csv.DictWriter(csvfile,fieldnames=fieldnames) writer.writerow({'id':'1','name':'王莽','age':'29'}) # 写入数据 -
【读取】数据操作:
pythonwith open('./data.csv','r',encoding='utf-8') as csvfile: reader = csv.reader(csvfile) for row in reader: print(row)
【推荐】使用pandas库来进行csv文件存储。
安装pandas库:
sh
pip install pandas具体写法:
python
import pandas
# 写入数据操作
data = [
{'id':'1','name':'Mike','age':18},
{'id':'2','name':'Rose','age':24},
{'id':'3','name':'Jack','age':26},
]
df = pandas.DataFrame(data)
df.to_csv('data.csv',index=False)
# 读取数据操作
content = pandas.read_csv('data.csv')
print(content)
-------------------------------
id name age
0 1 Mike 18
1 2 Rose 24
2 3 Jack 26
-------------------------------3)MySQL存储
安装pymysql:
shell
pip install pymysql具体写法:
python
import pymysql
# 创建连接
conn = pymysql.connect(host='IP地址', port=端口号, user='用户名', passwd='密码', db='数据库名', charset='utf8')
# 创建游标
cursor = conn.cursor()
# 创建表(需提前建好spider库)
sql1 = "create table if not exists spider.book(id int, name varchar(255))"
cursor.execute(sql1) # 执行sql语句
# 插入数据
books = {("1","三国演义"),("2","西游记"),("3","红楼梦"),("4","水浒传")}
sql2 = "insert into spider.book(id,name) values (%s,%s)"
for item in books:
cursor.execute(sql2, (item[0], item[1])) # 执行sql语句
# 提交,不然无法保存新建或者修改的数据
conn.commit()
# 关闭游标
cursor.close()
# 关闭连接
conn.close()五:代理的使用
代理的基本知识点:
IP代理的概念: 代理(Proxy)是指一种充当中间人的服务器或服务,用户通过代理与目标服务器通信,从而隐藏其真实的网络身份。代理服务器可以拦截、修改、转发用户和目标服务器之间的通信数据。
IP代理作用:
(1)突破自身IP访问限制,访问国外站点。如:运用国外IP来访问外国网站。
(2)访问一些单位或团体内部资源。如:访问校园网中才能访问的资源,校外无法访问的资源。
(3)提高访问速度。原理:通常代理服务器都设置了一个较大的硬盘缓冲区,当有外界的信息通过时,同时也将其保存到缓冲区内,当其他用户再次访问相同的信息时,则还会直接由缓冲区去除信息,传给用户,以提高访问速度。
(4)隐藏真实IP,免受攻击。
动态IP切换: IP代理池通常会周期性地更新,添加新的代理IP,同时淘汰失效或被封禁的IP。这使用户能够实现动态IP切换,减少被检测到的风险,提高匿名性和稳定性。
代理池:可以构建代理池来从中获取代理IP
IP代理的免费网站:https://www.kuaidaili.com/free/fps/
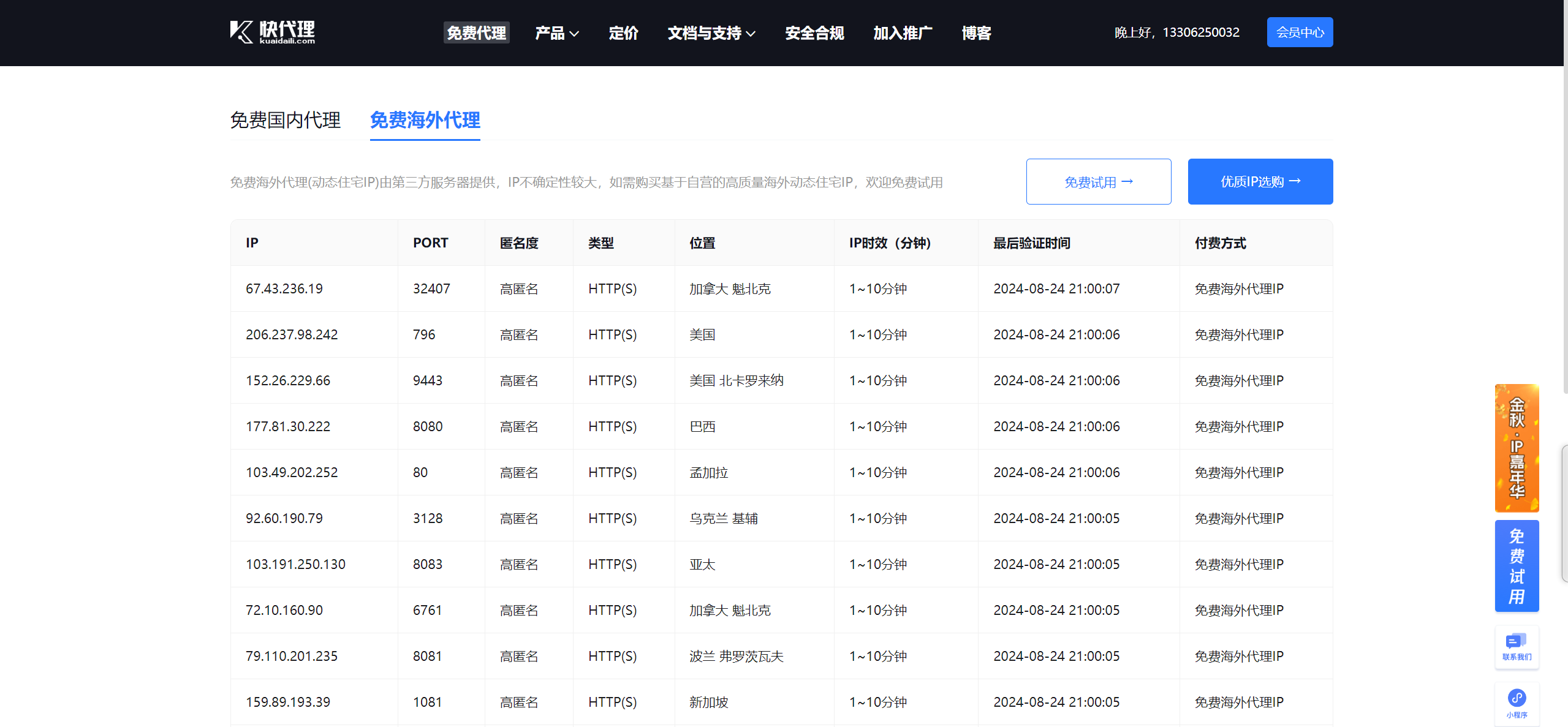
实际应用:
python
import requests
# 要查询的完整路径:https://www.baidu.com/s?wd=黑神话悟空
# 此处为基本路径
url = 'https://www.baidu.com/s?'
# 设置请求头
headers = {
'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36'
}
# 参数
data = {
'wd': '黑神话悟空'
}
# 设置IP代理 👈
proxy = {
'https':'67.43.236.19:32407'
}
# 模拟浏览器向服务器请求(response响应) 👈
response = requests.get(url=url,params=data,headers=headers,proxies=proxy)
# 设置相应的编码格式:utf-8
response.encoding = 'utf-8'
# 获取响应中的页面源码
content = response.text
# 将获取信息写入html文件中
with open('悟空.html','w',encoding='utf-8') as fp:
fp.write(content)六:模拟登录(Cookie和Session)
核心要求:维护好Cookie的信息。
1)实现的方式
方式一 :
手动进行登录过程,这是最省时省力的方式。直接在浏览器中登录自己的账号,直接将Cookie赋值给爬虫,然后即可爬取个人页面中的信息。方式二【✔】 :
使用爬虫来模拟登录过程,完全自动化操作。登录过程是一个POST请求,爬虫将"用户名"和"密码"等信息提交给服务器,服务器返回一个Set-Cookie字段,将其内容存储下来,即可获取Cookie来进行爬虫操作。方式三【✔】 :
登录过程的自动化化。使用Selenium驱动浏览器模拟执行一些操作(如填写用户名,密码。提交表单等)。登录成功后,通过Selenium获取浏览器的Cookie并保存,从而进行爬虫操作。
2)Requests模拟登陆
这里用到的案例网站是 https://login2.scrape.center/,访问这个网站,会打开一个登录页面,如图所示。
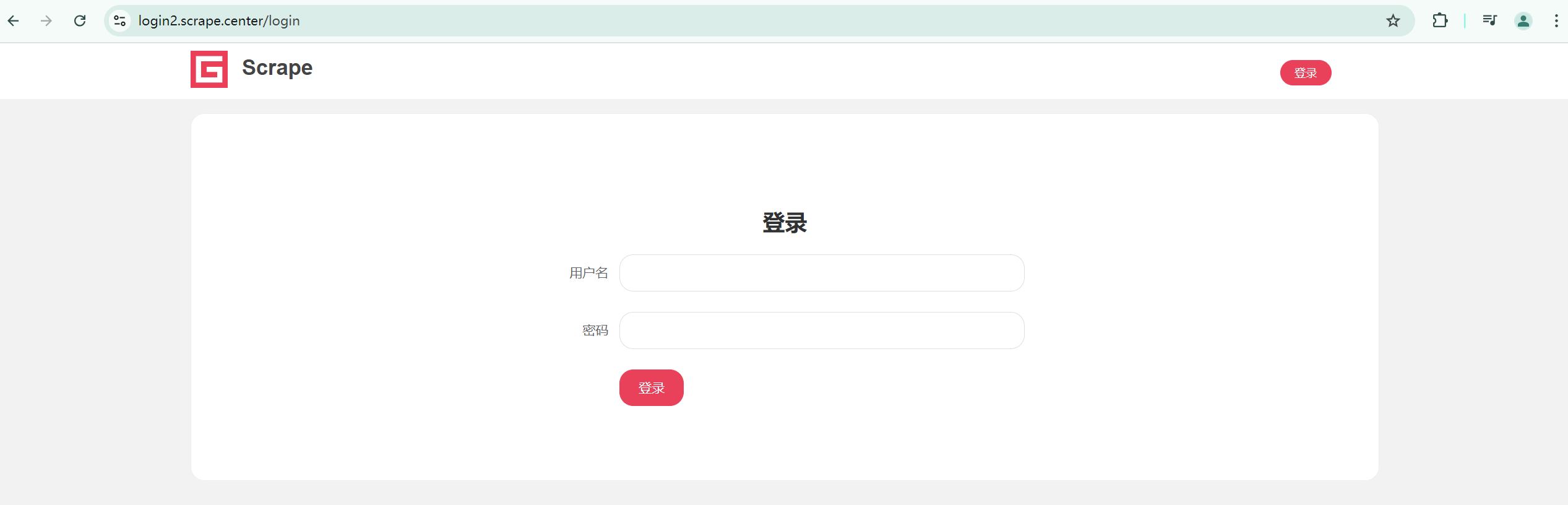
输入用户名和密码(都是 admin),然后点击登录按钮,登陆成功后,我们便可以看到一个熟悉的页面,如图所示。
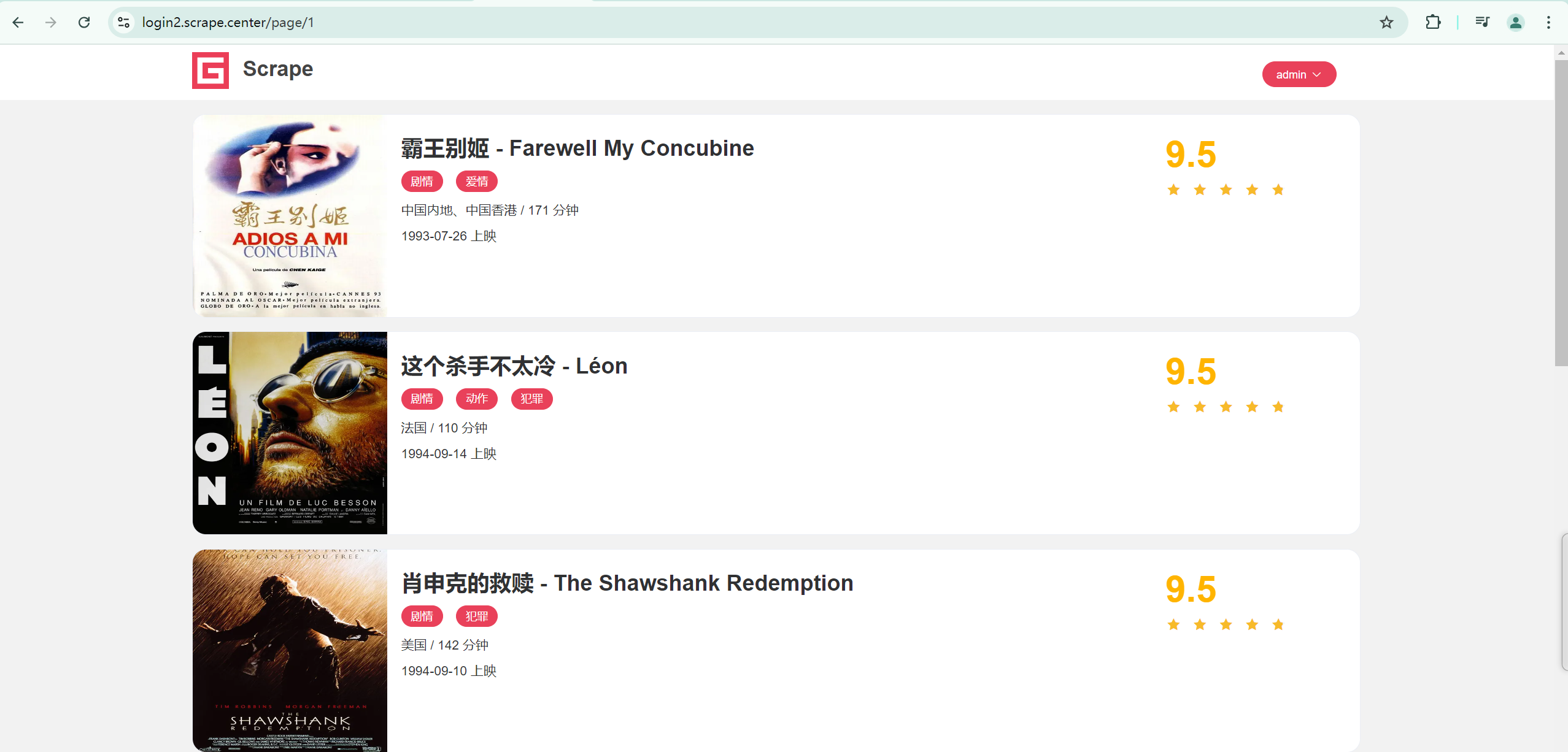
这个网站是基于传统的 MVC 模式开发的,因此也比较适合 Session + Cookies 的认证【方式二】。
python
import requests
from urllib.parse import urljoin
BASE_URL = 'https://login2.scrape.center/'
# urljoin()方法将两个链接参数拼接为完整URL,用于拼接url
LOGIN_RUL = urljoin(BASE_URL,'login')
INDEX_URL = urljoin(BASE_URL,'page/2')
# 提供登录密码,用户名
data = {
'username' : 'admin',
'password' : 'admin'
}
# Session对象:自动处理Cookie,通过Session来获取信息
session = requests.session()
# 模拟登录
response_login = session.post(url=LOGIN_RUL,data=data)
# 1、通过Session获取Cookie
cookies = session.cookies
print(cookies)
# 2、通过Session获取内容信息(二进制,需转utf-8)
page = session.get(INDEX_URL)
content = page.content.decode('utf-8')
print(content)3)Selenium模拟登陆
若带有验证码,带有加密参数的网站,无法直接用requests来进行模拟登陆,则要使用Selenium模拟浏览器的方式来实现模拟登录,获取模拟登录成功后的 Cookies,再把获取的 Cookies 交由 requests 等来爬取【方式三】。
python
import time
from urllib.parse import urljoin
import requests
from selenium import webdriver
from selenium.webdriver.common.by import By
BASE_URL = 'https://login2.scrape.center/'
LOGIN_URL = urljoin(BASE_URL,'/login')
INDEX_URL = urljoin(BASE_URL,'/page/1')
username = 'admin'
password = 'admin'
driver = webdriver.Chrome()
# 1、进行登录操作
driver.get(LOGIN_URL)
# 用户名框
box1 = driver.find_element(By.CSS_SELECTOR,"input[name='username']")
# 密码框
box2 = driver.find_element(By.CSS_SELECTOR,"input[name='password']")
# 输入用户名和账号
box1.send_keys(username)
box2.send_keys(password)
# 点击登录
submit = driver.find_element(By.CSS_SELECTOR,"input[type='submit']")
submit.click()
time.sleep(5)
# 2、从浏览器对象中获取Cookie信息
cookies = driver.get_cookies()
print(cookies)
driver.close()
# Session对象:自动处理Cookie,通过Session来获取信息
session = requests.Session()
# 3、通过Session获取Cookie
for cookie in cookies:
session.cookies.set(cookie['name'],cookie['value'])
# 4、通过Session获取内容信息(二进制,需转utf-8)
page = session.get(INDEX_URL)
content = page.content.decode('utf-8')
print(content)
cookies = session.cookies
print(cookies)
# 2、通过Session获取内容信息(二进制,需转utf-8)
page = session.get(INDEX_URL)
content = page.content.decode('utf-8')
print(content)