传统JDBC连接存在的问题,每次获取连接都需要去验证driverClass,url,username,password
而应用与数据库DBMS之间的通信是进程间的通信而底层又使用的是Socket,相对耗时
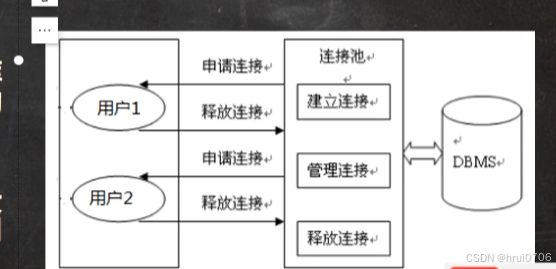
从而引入连接池的概念
连接池负责从DBMS提前获取连接,例如20个conn,一直放在连接池中
用户需要用了,去连接池中获取连接,连接用完还给连接池,但是连接池并没有真正去关闭该连接
而是等待其他线程的再次重用,这样,提高效率,当然很多连接池都配置了连接默认刷新时间,一般是30分钟,主要是网络问题去刷新下连接(就是真正意义上的重新获取连接,当连接还是使用,一般等连接空闲,再刷新)
SpringBoot+Mybatis默认用的是HikariCP 暂时查到的是HikariCP内当最大连接数用完,又没有空闲连接可以使用的时候,并没有提供接受队列,而是进入阻塞,等待有空闲连接可以使用
连接池就是一个技术方面的解决方案
连接池就是一个技术方面的解决方案
连接池就是一个技术方面的解决方案
使用数据库连接池,需要实现 javax.sql.DataSource
为什么使用数据库连接池:简单讲就是为了优化提高效率,减少每次去获取连接的耗时
传统JDBC实现类是:JDBC4Connection
C3P0从连接池获取的连接是:NewProxyConnection
Druid从连接池获取的连接是:DruidStatementConnection
HikariCP从连接池获取的连接时:HikariProxyConnection
使用连接池之后conn.closed方法并非正真意义上的关闭连接,而是将连接交还给数据库连接池
public class ConQuestion {
/**
* 传统通过DriverManager方式获取Connection,每次向数据库建立链接的时候
* 要验证url,用户名,密码,这样效率比较低
* 而且每次都是获取一个连接
* 传统获取连接的方式,不能控制创建的丽娜姐数量
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
long start = System.currentTimeMillis();
System.out.println("开始");
for(int i=0;i<500;i++){
//传统方式通过DriverManager获取Connection
Connection connection = JDBCUtils.getConnection();
//通过SQL执行对象操作数据库.....
JDBCUtils.closed(null,null,connection);
}
System.out.println("结束");
long end = System.currentTimeMillis();
System.out.println("耗时:"+(end-start));//这里连的阿里云RDS 50次 耗时:4s 一般连接本地的话 500次大概8秒 用的mysql8.0
}
}
package com.example;
import java.io.FileInputStream;
import java.io.IOException;
import java.sql.*;
import java.util.Properties;
/**
* JDBC工具类
* @author hrui
* @date 2024/8/29 16:45
*/
public class JDBCUtils {
private static String url;
private static String username;
private static String password;
private static Properties properties=new Properties();
static{
try {
properties.load(new FileInputStream("src\\jdbc.properties"));
url = properties.getProperty("url");
username = properties.getProperty("username");
password = properties.getProperty("password");
}catch (IOException e){
e.printStackTrace();
//throw new RuntimeException(e);
}
}
public static Connection getConnection() throws SQLException {
//如果这样写,虽然不需要定义url,username,password,但是每次都要从properties获取url,username,password,效率不高 所以还是定义url,username,password 静态块里赋值
//return DriverManager.getConnection(properties.getProperty("url"), properties.getProperty("username"), properties.getProperty("password"));
return DriverManager.getConnection(url, username, password);
}
public static void closed(ResultSet rs, Statement stmt, Connection conn){
try {
if(rs!=null){
rs.close();
}
if(stmt!=null){
stmt.close();
}
if(conn!=null){
conn.close();
}
}catch (SQLException e){
e.printStackTrace();
}
}
}src下的jdbc.properties
url=jdbc:mysql://localhost:3306/jdbc?rewriteBatchedStatements=true username=root password=123456

1.C3P0连接池的使用
依赖
<!-- https://mvnrepository.com/artifact/com.mchange/c3p0 --> <dependency> <groupId>com.mchange</groupId> <artifactId>c3p0</artifactId> <version>0.9.5.5</version> </dependency> <!-- https://mvnrepository.com/artifact/com.mchange/mchange-commons-java --> <dependency> <groupId>com.mchange</groupId> <artifactId>mchange-commons-java</artifactId> <version>0.2.20</version> </dependency>
注意:如果新版C3P0只导入C3P0会报错 因此导入mchange-commons-java
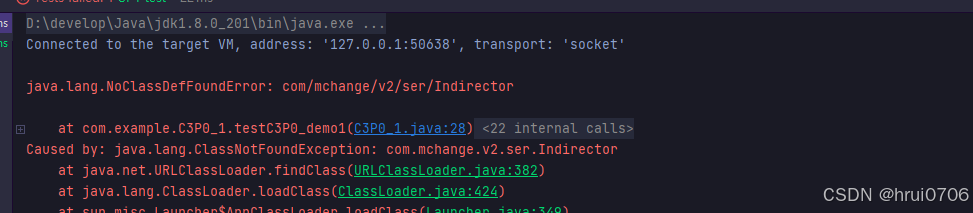
C3P0第一个示例demo
/**
* 测试C3P0连接池demo1
*/
@Test
public void testC3P0_demo1() throws IOException, PropertyVetoException, SQLException {
//该类最终实现java.sql.DataSource接口
//创建C3P0连接池
ComboPooledDataSource dataSource=new ComboPooledDataSource();
Properties properties=new Properties();
properties.load(new FileInputStream("src\\jdbc.properties"));
String url = properties.getProperty("url");
String username = properties.getProperty("username");
String password = properties.getProperty("password");
//连接池会去连接DBMS 告知连接池驱动类型,url,username,password
dataSource.setDriverClass("com.mysql.cj.jdbc.Driver");
dataSource.setJdbcUrl(url);
dataSource.setUser(username);
dataSource.setPassword(password);
//设置初始化连接数
dataSource.setInitialPoolSize(5);
//设置最大连接数
dataSource.setMaxPoolSize(10);
//从连接池中获取一个连接
for(int i=0;i<12;i++){
Connection conn = dataSource.getConnection();//从连接池获取连接
System.out.println(conn);
System.out.println("获取第"+i+"个连接");
if(i==9){
conn.close();//该conn是个代理对象,还回数据库连接池 并没有真正关闭
}
}
}第二种配置c3p0连接池的方式:用配置文件
在src下创建c3p0-config.xml
<?xml version="1.0" encoding="UTF-8"?>
<c3p0-config>
<!-- 配置文件 -->
<!-- 名称代表连接池 -->
<named-config name="myc3p0">
<!-- 驱动包 -->
<property name="driverClass">com.mysql.cj.jdbc.Driver</property>
<!-- 数据库的地址 -->
<property name="jdbcUrl">jdbc:mysql:///jdbc?serverTimezone=Asia/Shanghai</property>
<!-- 用户名 -->
<property name="user">root</property>
<!-- 密码 -->
<property name="password">123456</property>
<!-- 每次增长的连接数 -->
<property name="acquireIncrement">5</property>
<!-- 初始化连接对象的数量 -->
<property name="initialPoolSize">5</property>
<!-- 最小连接对象的数量 -->
<property name="minPoolSize">5</property>
<!-- 最大连接对象的数量 -->
<property name="maxPoolSize">10</property>
<!-- 可以缓存的sql语句模板数量,在整个连接池缓存 -->
<property name="maxStatements">50</property>
<!-- 每个连接可以缓存的sql语句模板数量 -->
<property name="maxStatementsPerConnection">20</property>
<!-- 超时时间 -->
<property name="checkoutTimeout">3000</property>
</named-config>
</c3p0-config>示例代码
/**
* 测试C3P0连接池demo2
* 使用配置文件模板
* src下配置c3p0-config.xml
*/
@Test
public void testC3P0_demo2() throws IOException, SQLException {
//创建C3P0连接池
ComboPooledDataSource dataSource=new ComboPooledDataSource("myc3p0");
Connection connection = dataSource.getConnection();
System.out.println("从连接池获取连接:"+connection);
System.out.println(connection.getAutoCommit());
}2.Druid(德鲁伊连接池)
<!-- https://mvnrepository.com/artifact/com.alibaba/druid -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.2.23</version>
</dependency>
直接点击下载
在src下创建druid.properties
# 键=值格式的配置 driverClassName=com.mysql.jdbc.Driver url=jdbc:mysql://localhost:3306/jdbc?rewriteBatchedStatements=true username=root password=root # 初始连接数 initialSize=10 # 最小空闲连接数 最小连接数 minIdle=5 # 最大活跃连接数 也是最大连接数 maxActive=20 # 最大等待时间(5000毫秒)等待的是连接池里的连接 maxWait=5000
package com.example;
import com.alibaba.druid.pool.DruidDataSource;
import com.alibaba.druid.pool.DruidPooledConnection;
import org.junit.Test;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.sql.Connection;
import java.sql.SQLException;
import java.util.Properties;
/**
*
* @author hrui
* @date 2024/8/30 15:43
*/
public class Druid_ {
/**
* 测试Druid连接池
*/
@Test
public void testDruid() throws IOException, SQLException {
Properties properties = new Properties();
properties.load(new FileInputStream("src\\druid.properties"));
//创建数据源
DruidDataSource druidDataSource = new DruidDataSource();
druidDataSource.setDriverClassName(properties.getProperty("driverClassName"));
druidDataSource.setUrl(properties.getProperty("url"));
druidDataSource.setUsername(properties.getProperty("username"));
druidDataSource.setPassword(properties.getProperty("password"));
druidDataSource.setInitialSize(Integer.parseInt(properties.getProperty("initialSize")));
druidDataSource.setMaxActive(Integer.parseInt(properties.getProperty("maxActive")));
druidDataSource.setMaxWait(Integer.parseInt(properties.getProperty("maxWait")));
Connection connection = druidDataSource.getConnection();
System.out.println(connection);
connection.close();//交还给连接池
long start = System.currentTimeMillis();
//复用连接池中的连接
for(int i=0;i<5000;i++){
Connection conn = druidDataSource.getConnection();//从连接池获取连接
//System.out.println(conn);
conn.close();//交还给连接池
}
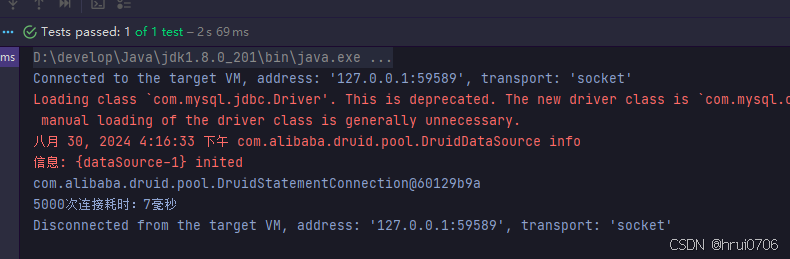
System.out.println("5000次耗时:"+(System.currentTimeMillis()-start));
}
}因连接已经在连接池中,因此获取连接的耗时问题基本解决了
Druid连接池工具类
package com.example;
import com.alibaba.druid.pool.DruidDataSourceFactory;
import javax.sql.DataSource;
import java.io.FileInputStream;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.Properties;
/**
* 基于Druid数据库连接池的工具类
* @author hrui
* @date 2024/8/30 16:18
*/
public class JDBCUtilsByDruid {
private static DataSource dataSource;
static {
Properties properties = new Properties();
try {
Properties prop = new Properties();
prop.load(new FileInputStream("src\\druid.properties"));
//给数据源(连接池赋值,并创建连接池)
dataSource = DruidDataSourceFactory.createDataSource(prop);
} catch (Exception e) {
e.printStackTrace();
}
}
public static Connection getConnection() throws SQLException {
return dataSource.getConnection();
}
//还回连接池
public static void close(ResultSet rs, Statement stmt, Connection conn) {
if (rs != null){
try {
rs.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (stmt != null){
try {
stmt.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (conn != null){
try {
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}获取连接demo
3.HikariCP(SpringBoot+Mybatis默认使用的数据库连接池)
<!-- https://mvnrepository.com/artifact/com.zaxxer/HikariCP -->
<dependency>
<groupId>com.zaxxer</groupId>
<artifactId>HikariCP</artifactId>
<version>5.1.0</version>
</dependency>
//HikariCP内部日志需要
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.36</version>
</dependency>
可以模仿Druid写个工具类
package com.example;
import com.zaxxer.hikari.HikariConfig;
import com.zaxxer.hikari.HikariDataSource;
import java.sql.Connection;
import java.sql.SQLException;
/**
* @author hrui
* @date 2024/8/30 16:56
*/
public class HikariCP_ {
public static void main(String[] args) throws SQLException {
// 1. 配置 HikariCP
HikariConfig config = new HikariConfig();
config.setJdbcUrl("jdbc:mysql://localhost:3306/jdbc");
config.setUsername("root");
config.setPassword("123456");
config.setDriverClassName("com.mysql.cj.jdbc.Driver");
// 2. 配置连接池属性
// 设置连接池中允许的最大连接数(10个连接),当所有连接都被占用时,新的连接请求将会被阻塞并进入等待状态,直到有连接被释放
config.setMaximumPoolSize(10);
// 设置最小空闲连接数(5个连接),连接池在空闲时最少会保持这些连接数不被关闭
config.setMinimumIdle(5);
// 设置获取连接的最大等待时间(30秒),如果在此时间内无法获取到连接,将抛出 SQLException
config.setConnectionTimeout(30000);
// 设置连接在连接池中空闲的最大时间(600秒),超过此时间的空闲连接将被释放(超过最小连接<最大连接时候的连接)
config.setIdleTimeout(600000);
// 默认就是这个值 30分钟 将连接真正关闭 重新获取新的连接 一个连接用久了可能网络问题等待时间会比较长,所以设置这个时间
config.setMaxLifetime(1800000);
// 3. 创建数据源
HikariDataSource dataSource = new HikariDataSource(config);
long start = System.currentTimeMillis();
for(int i=0;i<5000;i++){
Connection conn = dataSource.getConnection();
conn.close();
}
System.out.println("耗时:"+(System.currentTimeMillis()-start)+"毫秒");
}
}并没有Druid快
4.Apache Commons DbUtils:轻量级的 Java 库,用于简化 JDBC 操作,注意本身他没有集成连接池,是对JDBC操作的简化
<!-- https://mvnrepository.com/artifact/commons-dbutils/commons-dbutils -->
<dependency>
<groupId>commons-dbutils</groupId>
<artifactId>commons-dbutils</artifactId>
<version>1.8.1</version>
</dependency>
如果要集成连接池,需要引入对应连接池的jar包
那么有人会说:JDBC的操作很容易,为什么还要引入Apache Commons DbUtils?????
这是你写简单JDBC觉得容易的原因,然而随着项目复杂度的增加,JDBC的操作会变得繁琐且容易出错
例如:
1.资源管理,没有正确关闭,导致的资源耗尽问题
2.Apache Commons DbUtils简化了结果集的处理
3.Apache Commons DbUtils减少了样板代码,就是说它本身已经封装了获取连接,关闭资源等等
4.提高了可维护性
什么时候不需要使用Apache Commons DbUtils
1.简单应用,例如就几次JDBC操作
2.更加复杂的操作,如果使用的是Hibernate,JPA这样的ORM框架
3.也不适用于现在常用的SpringBoot+Mybatis
所以这个选择是否使用Apache Commons DbUtils 还是看你自己意愿
什么时候适合使用Apache Commons DbUtils
简单讲:我觉得如果大量使用JDBC代码,而你又对Apache Commons DbUtils非常了解的情况下,那么可以选择使用Apache Commons DbUtils+其他数据库连接池的方案 是否多余 看你咯
那么传统JDBC有哪些不好为什么要用Apache Commons DbUtils
1.传统JDBC的做法是,获取连接,用sql执行对象发送select/insert/update/delete等操作
2.select查询得到结果集之后,必须遍历完结果集才可以关闭连接conn,这样在多线程时候,还是浪费conn的,就是说并不是理想的结果,如果你提前关闭conn,ResultSet没有办法遍历,会报错,有没有办法,获取Result之后,随时可以关闭连接,其实****Apache Commons DbUtils就是这么做的,内部肯定是想ResultSet存起来了
3.Apache Commons DbUtils将ResultSet存起来,并且封装成了ArrayList<javaBean>,那么ResultSet也就没有用了,conn也随时可以关闭
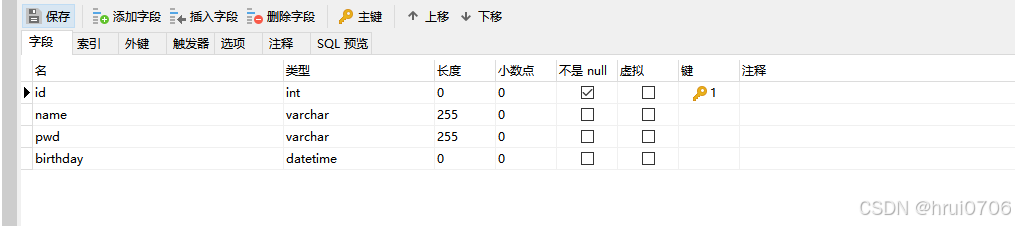
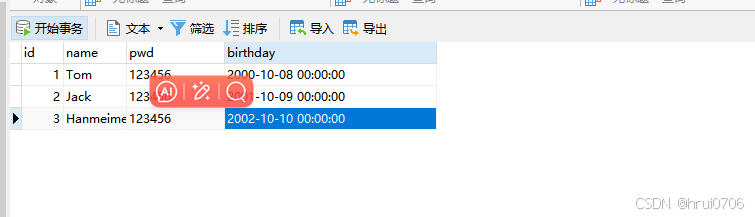
Apache Commons DbUtils对ResultSet做了封装
package com.example;
import java.sql.Connection;
import java.sql.Date;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.util.ArrayList;
import java.util.List;
/**
* @author hrui
* @date 2024/8/30 18:56
*/
public class ResultSetTest {
public static void main(String[] args) {
PreparedStatement ps = null;
ResultSet rs = null;
Connection conn=null;
try {
conn = JDBCUtils.getConnection();
String sql="select * from t_test";
PreparedStatement p = conn.prepareStatement(sql);
rs = p.executeQuery();
//Apache Commons DbUtils帮我们将ResultSet做了一个封装 并返回
List<Test> list=new ArrayList<>();
while (rs.next()){
int id = rs.getInt(1);
String name=rs.getString(2);
String pwd=rs.getString(3);
Date dirthday = rs.getDate(4);
System.out.println(id+":"+name+":"+pwd+":"+dirthday);
//编译器将java.sql.Date;和java.util.Date;做了转换
Test test=new Test(id,name,pwd,dirthday);
list.add(test);
}
System.out.println(list);
}catch (Exception e){
e.printStackTrace();
}finally {
JDBCUtils.closed(rs,ps,conn);
}
}
}
5.使用Apache Commons DbUtils+Druid连接池对表进行增删改查
<!-- https://mvnrepository.com/artifact/commons-dbutils/commons-dbutils -->
<dependency>
<groupId>commons-dbutils</groupId>
<artifactId>commons-dbutils</artifactId>
<version>1.8.1</version>
</dependency>
//德鲁伊连接池
<!-- https://mvnrepository.com/artifact/com.alibaba/druid -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.2.23</version>
</dependency>
可以直接下载jar包
Druid数据库连接池工具类
package com.example;
import com.alibaba.druid.pool.DruidDataSourceFactory;
import javax.sql.DataSource;
import java.io.FileInputStream;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.Properties;
/**
* 基于Druid数据库连接池的工具类
* @author hrui
* @date 2024/8/30 16:18
*/
public class JDBCUtilsByDruid {
private static DataSource dataSource;
static {
Properties properties = new Properties();
try {
Properties prop = new Properties();
prop.load(new FileInputStream("src\\druid.properties"));
//给数据源(连接池赋值,并创建连接池)
dataSource = DruidDataSourceFactory.createDataSource(prop);
} catch (Exception e) {
e.printStackTrace();
}
}
public static Connection getConnection() throws SQLException {
return dataSource.getConnection();
}
//还回连接池
public static void close(ResultSet rs, Statement stmt, Connection conn) {
if (rs != null){
try {
rs.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (stmt != null){
try {
stmt.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (conn != null){
try {
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}Druid数据库连接池配置文件
druid.properties
# 键=值格式的配置 driverClassName=com.mysql.jdbc.Driver url=jdbc:mysql://localhost:3306/jdbc?rewriteBatchedStatements=true username=root password=123456 # 初始连接数 initialSize=10 # 最小空闲连接数 minIdle=5 # 最大活跃连接数 也是最大连接数 maxActive=20 # 最大等待时间(5000毫秒) maxWait=5000
报这个错暂时两种方式
1.将实体类java.util.Date去掉改成String
2.mysql驱动换成5.1.6不要使用8版本
3.将实体类Date类型改成LocalDateTime(推荐做法) 或者LocalDate

java.sql.Date是java.util.Date的子类
第三种解决方式,咱不改自己代码,改Apache Commons DbUtils代码,重写下
Apache Commons DbUtils 默认情况下使用 PreparedStatement 来执行 SQL 语句
所以有参数都以PreparedStatement ? ? ?的方式
改成LocalDateTime就好了 最好不要一直这样 我当时实体类还是用的Date
1.查询多条数据
package com.example;
import org.apache.commons.dbutils.QueryRunner;
import org.apache.commons.dbutils.ResultSetHandler;
import org.apache.commons.dbutils.handlers.BeanListHandler;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
/**
* @author hrui
* @date 2024/8/30 19:47
*/
public class CommonDBUtils {
//使用Apache Commons DbUtils工具类+druid连接池完成表的增删改查
@org.junit.Test
public void testQueryMany(){
Connection conn =null;
try {
//从druid数据库连接池得到连接
conn = JDBCUtilsByDruid.getConnection();
//获取Commons DbUtils数据库操作对象 进行增删改查都用它好了
QueryRunner qr = new QueryRunner();
//List<Test> query = qr.query(conn, "select * from t_test", new BeanListHandler<>(Test.class));
//mysql8报错 1.将实体类Date类型改成String 2.将mysql驱动改成5.X 3.那就高级了
//List<Test> query = qr.query(conn, "select * from t_test where id=?", new BeanListHandler<>(Test.class),1);//如果有参数
//解决mysql驱动8无法将LocalDateTime转换为java.util.Date 原因是mysql8的驱动版本问题 ResultSet 的某些方法返回 java.time.LocalDateTime 而不是 java.util.Date
List<Test> results = qr.query(conn,"select * from t_test where id>=?", new ResultSetHandler<List<Test>>() {
@Override
public List<Test> handle(ResultSet rs) throws SQLException {
List<Test> list = new ArrayList<>();
while (rs.next()) {
int id = rs.getInt("id");
String name = rs.getString("name");
String pwd = rs.getString("pwd");
Date birthday = rs.getDate("birthday"); // 获取 java.sql.Date
Test test = new Test(id, name, pwd,birthday); //java.sql.Date是java.util.Date子类 隐式转
list.add(test);
}
return list;
}
},1);
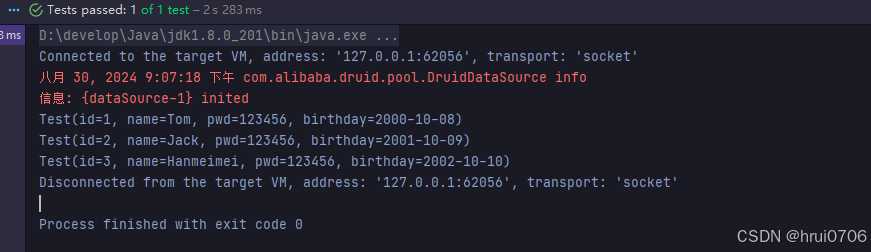
for (Test test : results) {
System.out.println(test);
}
} catch (SQLException e) {
e.printStackTrace();
}finally {
//在query方法里会自动关闭rs stmt
JDBCUtilsByDruid.close(null,null,conn);
}
}
}
2.返回单个对象
卧槽 拉倒吧 这样每次都重写 后面将实体类Date字段改成LocalDateTime 也是推荐的日期类型
//查询返回一条
@org.junit.Test
public void testQueryOne(){
Connection conn =null;
try {
//从druid数据库连接池得到连接
conn = JDBCUtilsByDruid.getConnection();
QueryRunner qr = new QueryRunner();
//使用BeanHandler处理器, 返回结果为单个对象 例如登录
//Test query =qr.query(conn, "select * from t_test where id=?", new BeanHandler<>(Test.class),1);
Test query = qr.query(conn, "select * from t_test where id=?", new ResultSetHandler<Test>() {
@Override
public Test handle(ResultSet resultSet) throws SQLException {
Test test = null;
while (resultSet.next()) {
int id = resultSet.getInt("id");
String name = resultSet.getString("name");
String pwd = resultSet.getString("pwd");
Date birthday = resultSet.getDate("birthday"); // 获取 java.sql.Date
test = new Test(id, name, pwd,birthday); //java.sql.Date是java.util.Date子类 隐式转
}
return test;
}
}, 1);
if(query!=null){
System.out.println(query);
}
} catch (SQLException e) {
e.printStackTrace();
}finally {
//在query方法里会自动关闭rs stmt
JDBCUtilsByDruid.close(null,null,conn);
}
}将实体类Date类型转成LocalDateTime
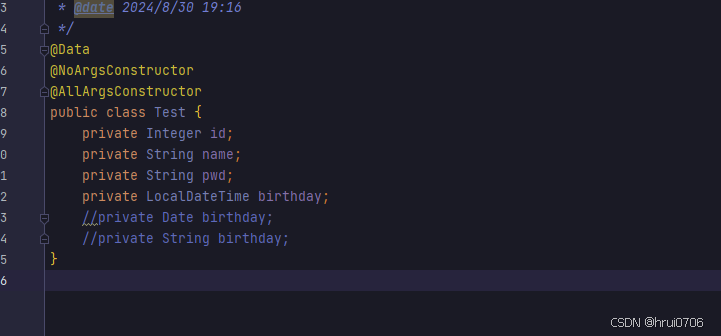
@org.junit.Test
public void testQueryOne(){
Connection conn =null;
try {
//从druid数据库连接池得到连接
conn = JDBCUtilsByDruid.getConnection();
QueryRunner qr = new QueryRunner();
//使用BeanHandler处理器, 返回结果为单个对象 例如登录
Test query =qr.query(conn, "select * from t_test where id=?", new BeanHandler<>(Test.class),1);
if(query!=null){
System.out.println(query);
}
} catch (SQLException e) {
e.printStackTrace();
}finally {
//在query方法里会自动关闭rs stmt
JDBCUtilsByDruid.close(null,null,conn);
}
}
3.查询返回单行单列
//查询返回单行单列
@org.junit.Test
public void testScalar(){
Connection conn =null;
try {
//从druid数据库连接池得到连接
conn = JDBCUtilsByDruid.getConnection();
QueryRunner qr = new QueryRunner();
//使用ScalarHandler处理器
Object query = qr.query(conn, "select name from t_test where id=?", new ScalarHandler<>(), 1);
if(query!=null){
System.out.println("name="+query);
}
} catch (SQLException e) {
e.printStackTrace();
}finally {
//在query方法里会自动关闭rs stmt
JDBCUtilsByDruid.close(null,null,conn);
}
}4.增删改DML操作
//DML操作
@org.junit.Test
public void testDML(){
Connection conn =null;
try {
//从druid数据库连接池得到连接
conn = JDBCUtilsByDruid.getConnection();
QueryRunner qr = new QueryRunner();
//使用ScalarHandler处理器
int insert = qr.update(conn, "insert into t_test value(null,?,?,?)", "hrui", "123456",LocalDateTime.now());
System.out.println("insert="+insert);
} catch (SQLException e) {
e.printStackTrace();
}finally {
//在query方法里会自动关闭rs stmt
JDBCUtilsByDruid.close(null,null,conn);
}
}5.演示批量
Connection conn = null;
try {
// 获取数据库连接
conn = JDBCUtilsByDruid.getConnection();
QueryRunner qr = new QueryRunner();
// SQL 语句
String sql = "INSERT INTO test (name, pwd, birthday) VALUES (?, ?, ?)";
// 批量参数:每个 Object[] 表示一行数据
Object[][] params = new Object[][]{
{"user1", "password1", LocalDateTime.now()},
{"user2", "password2", LocalDateTime.now()},
{"user3", "password3", LocalDateTime.now()}
};
// 执行批量插入操作
int[] results = qr.batch(conn, sql, params);
// 输出结果
System.out.println("Inserted rows: " + results.length);
} catch (SQLException e) {
e.printStackTrace();
} finally {
// 关闭连接
JDBCUtilsByDruid.close(null, null, conn);
}
Connection conn = null;
try {
// 获取数据库连接
conn = JDBCUtilsByDruid.getConnection();
QueryRunner qr = new QueryRunner();
// SQL 语句
String sql = "INSERT INTO test (name, pwd, birthday) VALUES (?, ?, ?)";
// 定义批次大小
int batchSize = 1000;
Object[][] params = new Object[batchSize][3];
// 循环生成数据并执行批量插入
for (int i = 0; i < 1000000; i++) {
params[i % batchSize] = new Object[]{"user" + i, "password" + i, LocalDateTime.now()};
// 当达到批次大小时执行批量插入
if ((i + 1) % batchSize == 0) {
qr.batch(conn, sql, params);
System.out.println("Inserted batch " + (i + 1) / batchSize);
}
}
// 处理剩余未满批次的数据
if (1000000 % batchSize != 0) {
qr.batch(conn, sql, params);
System.out.println("Inserted final batch");
}
} catch (SQLException e) {
e.printStackTrace();
} finally {
// 关闭连接
JDBCUtilsByDruid.close(null, null, conn);
}事实上对于JDBC操作
Apache Commons DbUtils+druid数据库连接操作就已经满足了大部分需求
一个conn不关闭就好了,其实也用不到什么连接池
因 Apache Commons DbUtils目的是简化JDBC操作
因此没有提供获取连接的方式
QueryRunner有几个好几个构造方法

6.事务操作
还是和原来一样 通过conn去设置事务
@org.junit.Test
public void testDML() {
Connection conn = null;
try {
// 从 Druid 数据库连接池获取连接
conn = JDBCUtilsByDruid.getConnection();
// 关闭自动提交,手动管理事务
conn.setAutoCommit(false);
QueryRunner qr = new QueryRunner();
// 第一个 DML 操作
int insert1 = qr.update(conn, "insert into t_test value(null,?,?,?)", "hrui", "123456", LocalDateTime.now());
System.out.println("insert1=" + insert1);
// 第二个 DML 操作
int insert2 = qr.update(conn, "insert into t_test value(null,?,?,?)", "john", "654321", LocalDateTime.now());
System.out.println("insert2=" + insert2);
// 如果所有操作成功,提交事务
conn.commit();
} catch (SQLException e) {
e.printStackTrace();
try {
if (conn != null) {
// 发生异常时回滚事务
conn.rollback();
System.out.println("事务已回滚");
}
} catch (SQLException ex) {
ex.printStackTrace();
}
} finally {
// 关闭连接,释放资源
JDBCUtilsByDruid.close(null, null, conn);
}
}6.Apache Commons DbUtils不使用连接池
6.关于BasicDao的概念
package com.example.dao;
import com.example.JDBCUtilsByDruid;
import org.apache.commons.dbutils.QueryRunner;
import org.apache.commons.dbutils.handlers.BeanHandler;
import org.apache.commons.dbutils.handlers.BeanListHandler;
import org.apache.commons.dbutils.handlers.ScalarHandler;
import java.sql.Connection;
import java.util.List;
/**
* 基类: 所有 Dao 的父类
* @author hrui
* @date 2024/8/30 22:55
*/
public class BasicDao<T> {
private QueryRunner qr = new QueryRunner();
// 通用 DML 操作(无事务)
public int update(String sql, Object... params) {
Connection conn = null;
try {
conn = JDBCUtilsByDruid.getConnection();
return qr.update(conn, sql, params);
} catch (Exception e) {
e.printStackTrace();
throw new RuntimeException(e);
} finally {
JDBCUtilsByDruid.close(null, null, conn);
}
}
// 返回多行(无事务)
public List<T> query(String sql, Class<T> cls, Object... params) {
Connection conn = null;
try {
conn = JDBCUtilsByDruid.getConnection();
return qr.query(conn, sql, new BeanListHandler<>(cls), params);
} catch (Exception e) {
e.printStackTrace();
throw new RuntimeException(e);
} finally {
JDBCUtilsByDruid.close(null, null, conn);
}
}
// 查询单行结果(无事务)
public T queryOne(String sql, Class<T> cls, Object... params) {
Connection conn = null;
try {
conn = JDBCUtilsByDruid.getConnection();
return qr.query(conn, sql, new BeanHandler<>(cls), params);
} catch (Exception e) {
e.printStackTrace();
throw new RuntimeException(e);
} finally {
JDBCUtilsByDruid.close(null, null, conn);
}
}
// 返回单行单列(无事务)
public Object queryScalar(String sql, Object... params) {
Connection conn = null;
try {
conn = JDBCUtilsByDruid.getConnection();
return qr.query(conn, sql, new ScalarHandler<>(), params);
} catch (Exception e) {
e.printStackTrace();
throw new RuntimeException(e);
} finally {
JDBCUtilsByDruid.close(null, null, conn);
}
}
// 通用 DML 操作(带事务)
public int update(Connection conn, String sql, Object... params) {
try {
return qr.update(conn, sql, params);
} catch (Exception e) {
e.printStackTrace();
throw new RuntimeException(e);
}
}
// 返回多行(带事务)
public List<T> query(Connection conn, String sql, Class<T> cls, Object... params) {
try {
return qr.query(conn, sql, new BeanListHandler<>(cls), params);
} catch (Exception e) {
e.printStackTrace();
throw new RuntimeException(e);
}
}
// 查询单行结果(带事务)
public T queryOne(Connection conn, String sql, Class<T> cls, Object... params) {
try {
return qr.query(conn, sql, new BeanHandler<>(cls), params);
} catch (Exception e) {
e.printStackTrace();
throw new RuntimeException(e);
}
}
// 返回单行单列(带事务)
public Object queryScalar(Connection conn, String sql, Object... params) {
try {
return qr.query(conn, sql, new ScalarHandler<>(), params);
} catch (Exception e) {
e.printStackTrace();
throw new RuntimeException(e);
}
}
}使用 BasicDao 进行无事务操作的示例
public class UserDao extends BasicDao<User> {
public int addUser(User user) {
String sql = "INSERT INTO user (name, password) VALUES (?, ?)";
return update(sql, user.getName(), user.getPassword());
}
public User getUserById(int id) {
String sql = "SELECT * FROM user WHERE id = ?";
return queryOne(sql, User.class, id);
}
}不带事务的操作示例
public class UserService {
public static void main(String[] args) {
UserDao userDao = new UserDao();
User newUser = new User();
newUser.setName("hrui");
newUser.setPassword("123456");
int result = userDao.addUser(newUser);
System.out.println(result > 0 ? "User added successfully" : "Failed to add user");
}
}使用 BasicDao 进行带事务操作的示例
public class UserService {
private UserDao userDao = new UserDao();
public void performUserOperations() {
Connection conn = null;
try {
conn = JDBCUtilsByDruid.getConnection();
conn.setAutoCommit(false); // 开启事务
// 在同一个事务中执行多个操作
userDao.update(conn, "UPDATE user SET name = ? WHERE id = ?", "newName", 1);
userDao.update(conn, "UPDATE user SET password = ? WHERE id = ?", "newPassword", 1);
conn.commit(); // 提交事务
} catch (Exception e) {
if (conn != null) {
try {
conn.rollback(); // 事务回滚
} catch (SQLException ex) {
ex.printStackTrace();
}
}
throw new RuntimeException(e);
} finally {
JDBCUtilsByDruid.close(null, null, conn); // 关闭连接
}
}
}