MySQL中的索引模型
Mysql中的索引使用的数据结构一般为搜索树,这里的搜索树,一般使用B树,这里补一下数据结构中的B树结构;说B树之前,先顺一个前置的知识点,平衡二叉树;
平衡二叉树
二叉树应该都不陌生,大学数据结构的基本入门,二叉排序树是基于二叉树上多了个"有序 "的概念,简单来说,即**左 < 右或 右<左**,反正就是,树是按着顺序建立的 。
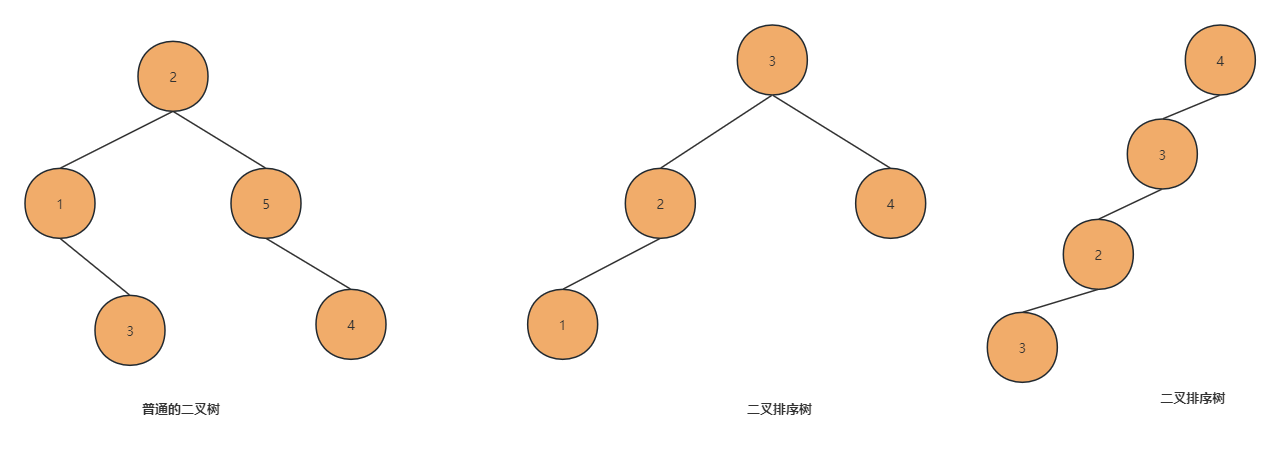
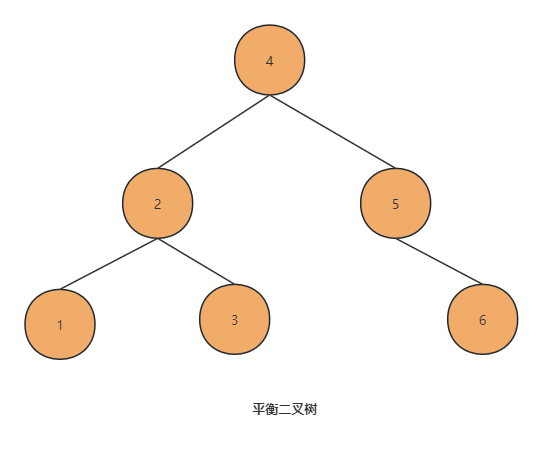
相比较普通的二叉树,二叉排序树具有"顺序"的特点,但是当极端情况下,即单边顺序排列下去,二叉排序树就成了单链表了,失去了树的意义,于是在二叉排序树的基础上进一步加强,即:**满足二叉排序树特点同时又左右子树高度差小于等于1,就有了平衡二叉树。**平衡二叉树的特点如下:
-
二叉排序树
-
任何一个节点的左子树或者右子树都是「平衡二叉树」(左右高度差小于等于 1)
B树
平衡二叉树已经很好了,其因为顺序、且限制了树的饱和,于是使得平衡二叉树在检索时,具有很高的性能,复杂度才O(logN),此时影响查询性能的瓶颈就演变到节点数量N了;根据树的特点,进行比对计算的次数取决于树的高度,如果节点的数量固定,我们可以通过控制每层的节点数来控制树的高度,不拘泥于"二叉"这一特性,变成多叉的平衡树(B-树)。
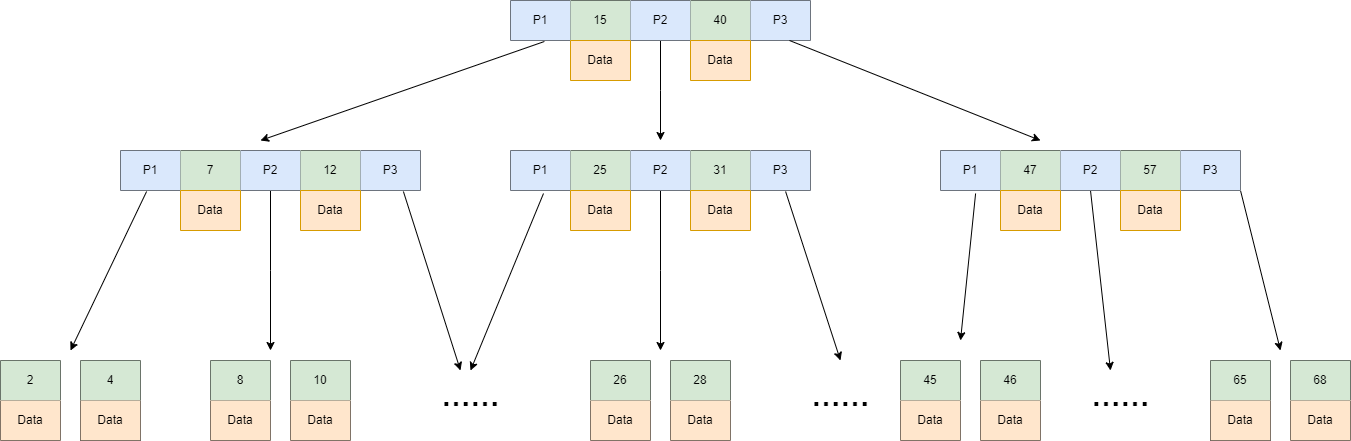
B树是一个绝对平衡树,所有的叶子节点在同一高度。在每个节点存储多个元素,在每个节点除了指针节点外,还存储相应的数据;相比二叉平衡查找树,在整个查找过程中,虽然数据的比较次数并没有明显减少,但是磁盘IO次数会大大减少;B树的高度一般2至3层就能满足大部分的应用场景,所以使用B树构建索引可以很好的提升查询的效率。
B树特点
- 每个节点至多可以拥有m棵子树(m阶)。
- 根节点,至少有2个节点。
- 非根非叶的节点至少有的Ceil(m/2)个子树(Ceil表示向上取整,图中5阶B树,每个节点至少有3个子树,也就是至少有3个叉)。
- 非叶节点中的信息包括n,A0,K1,A1,K2,A2,...,Kn,An,,其中n表示该节点中保存的关键字个数,K为关键字且Ki<Ki+1,A为指向子树根节点的指针。
- 从根到叶子的每一条路径都有相同的长度,也就是说,叶子节在相同的层,并且这些节点不带信息,实际上这些节点就表示找不到指定的值,也就是指向这些节点的指针为空。
B+树
尽管B树能较为明显的提升效率,但是它节点携带数据这一特征,随着存储数据的增长,必然导致空间的占用,如果使用到数据库索引时,意味着会树相应就会变高,一个页中可存储的数据量就会变少,磁盘IO次数就会变大。
所以引入了B树的另一增强B+树,相比于B树,B+树的特点在于:
-
内部节点只存储键值,不存储数据。数据只存储在叶子节点中,并且叶子节点包含了全部的键值和指向数据的指针。
-
叶子节点之间有双向链表链接,这使得范围查询更加高效,因为可以通过链表顺序访问叶子节点。
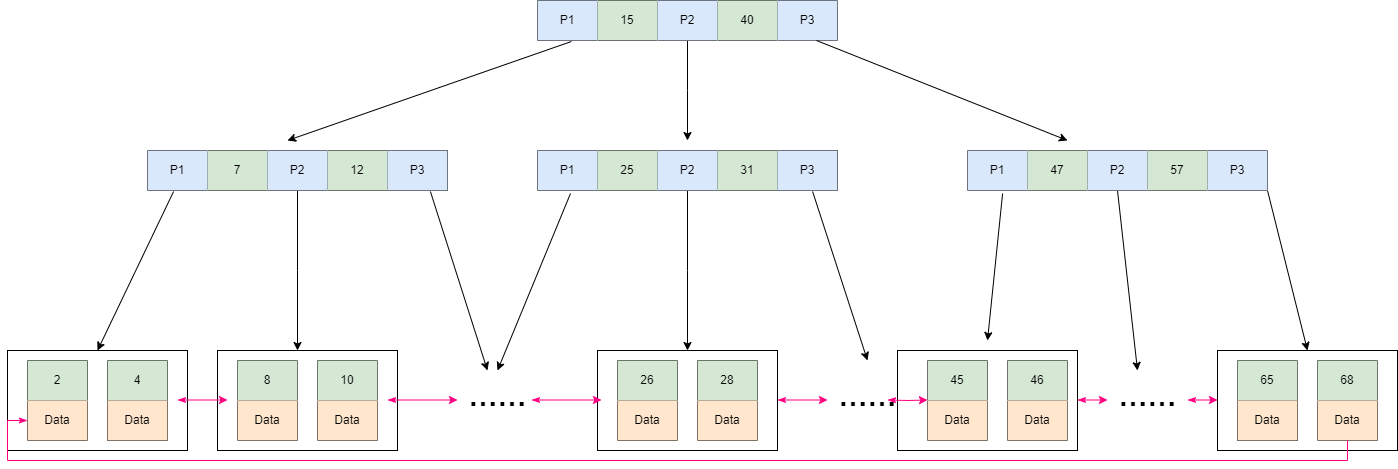
B+树的最底层叶子节点包含了所有的索引项。从图上可以看到,B+树在查找数据的时候,由于数据都存放在最底层的叶子节点上,所以每次查找都需要检索到叶子节点才能查询到数据。所以在需要查询数据的情况下每次的磁盘的IO跟树高有直接的关系,但是从另一方面来说,由于数据都被放到了叶子节点,所以放索引的磁盘块锁存放的索引数量是会跟这增加的,所以相对于B树来说,B+树的树高理论上情况下是比B树要矮的。也存在索引覆盖查询的情况,在索引中数据满足了当前查询语句所需要的全部数据,此时只需要找到索引即可立刻返回,不需要检索到最底层的叶子节点。
索引分类
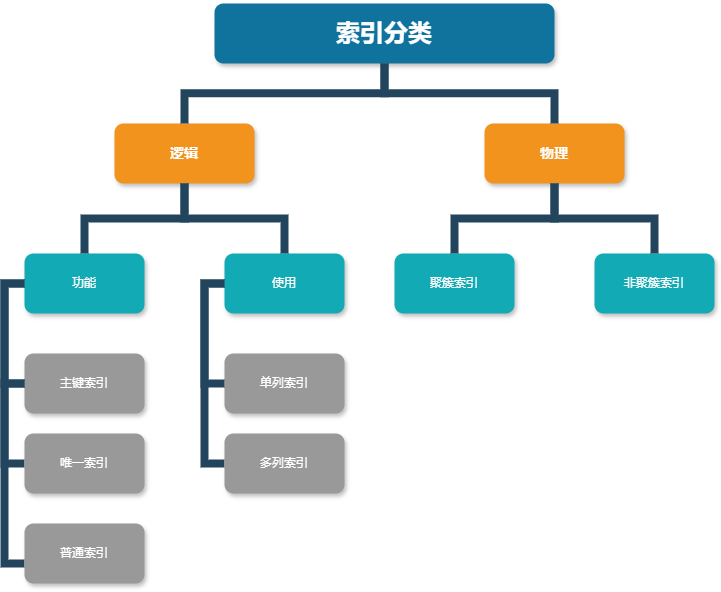
逻辑划分
按功能分
主键索引
一张表只能有一个主键索引,不允许重复、不允许为 NULL,使用关键字PRIMARY KEY 定义;PRIMARY KEY的通常基于B树(B-Tree)实现,本质上是特殊的唯一索引。
ALTER TABLE TableName ADD PRIMARY KEY(column_list);唯一索引
数据列不允许重复,允许为 NULL 值;一张表可有多个唯一索引,索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一;一般使用UNIQUE INDEX定义
CREATE UNIQUE INDEX IndexName ON `TableName`(`字段名`(length));
# 或者
ALTER TABLE TableName ADD UNIQUE (column_list); 普通索引
一张表可以创建多个普通索引,一个普通索引可以包含多个字段,允许数据重复,允许 NULL 值插入;
CREATE INDEX IndexName ON `TableName`(`字段名`(length));
# 或者
ALTER TABLE TableName ADD INDEX IndexName(`字段名`(length));按使用分
按使用划分其实就是单个列进行索引还是多个列组合索引。
- 单例索引:一个索引只包含一个列,一个表可以有多个单例索引。
- 组合索引:一个组合索引包含两个或两个以上 的列。查询的时候遵循 mysql 组合索引的 "最左前缀"原则,即使用 where 时条件要按照建立索引的时候字段的排列方式放置索引才会生效。MySQL中可以使用唯一索引 和普通索引进行组合索引
-- 多列组合(普通索引)
CREATE INDEX <index_name> ON <table_name > (column1, column2, column3);
或
ALTER TABLE <table_name> ADD INDEX <index_name> (column1, column2,column3);
-- 多列组合(唯一索引)
CREATE UNIQUE INDEX <index_name> ON <table_name> (column1, column2,column3);
或
ALTER TABLE <table_name> ADD UNIQUE INDEX <index_name> (column1, column2,column3));关于组合索引使用中的性能及使用原则,可直接跳至组合索引的使用原则
物理划分
之所以说根据物理划分是索引在物理存储原理上的特点。而且主要是针对B+树索引结构来讲
**簇的含义:**为了提高某个属性(或属性组)的查询速度,把这个或这些属性(称为聚簇码)上具有相同值的元组集中存放在连续的物理块。
聚簇索引
聚簇索引(clustered index)不是单独的一种索引类型,而是一种数据存储方式。这种存储方式根据表的主键构造一棵B+树,且B+树叶子节点存放的都是表的行记录数据时,该主键索引为聚簇索引。
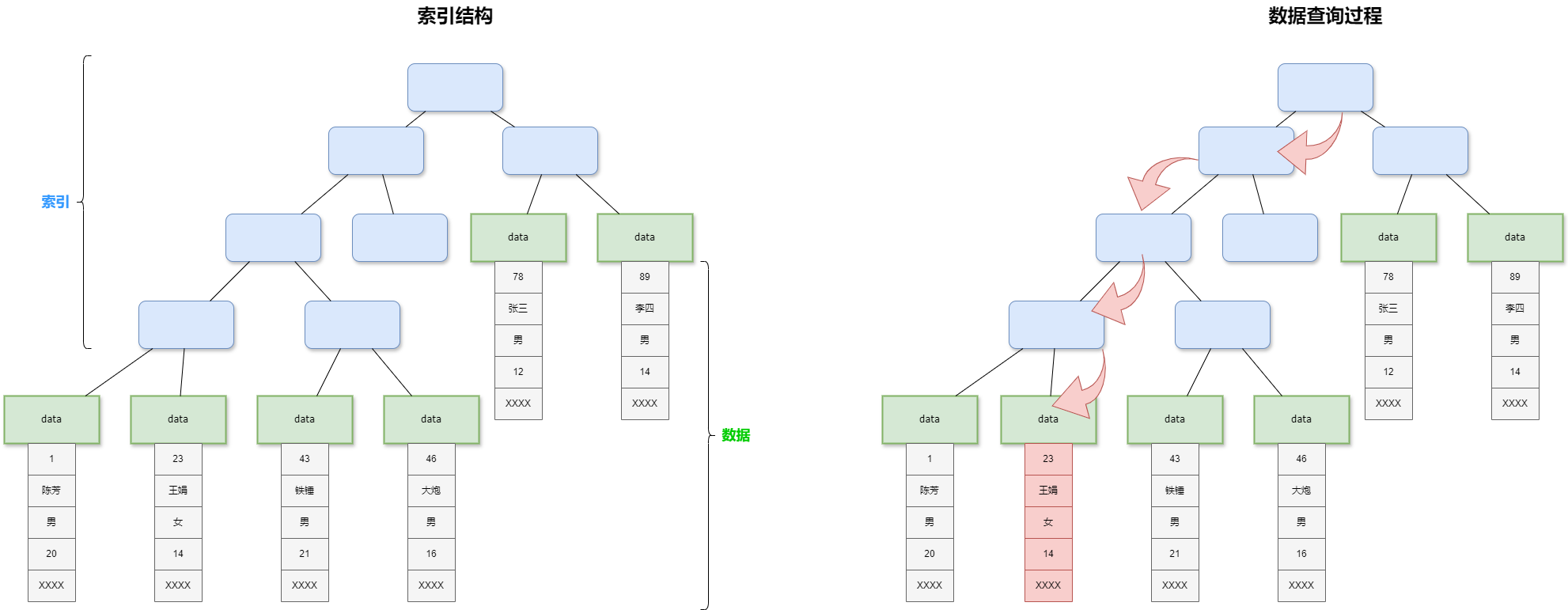
在聚簇索引中,其数据文件本身就是索引文件。 树的叶节点 data 域保存了完整的数据记录。这个索引的 key 是数据表的主键,进行查询时,根据搜索算法,在树上找到叶子节点后,数据也一并找到。这种情况也就是常说的覆盖索引。
注:每张表最多只能拥有一个聚簇索引
非聚簇索引
非聚簇索引又叫辅助索引或二级索引(在Mysql中primary key之外的均为辅助索引),与簇索引相反,数据和索引是分开的,B+Tree 叶节点的 data 域存放的是主键和该字段的值。在索引检索的时候,首先按照 B+Tree 搜索算法搜索索引,如果指定的内容 存在,则取出其 data 域中的主键,然后再在聚簇索引(Primary Key 索引树上再次搜索)。
假设我们针对user表查询
SELECT sex,age FROM user WHERE name = '陈芳';此时user表存在基于主键ID创建的聚簇索引,和基于name创建的非聚簇索引,那么查询过程则是这样的:
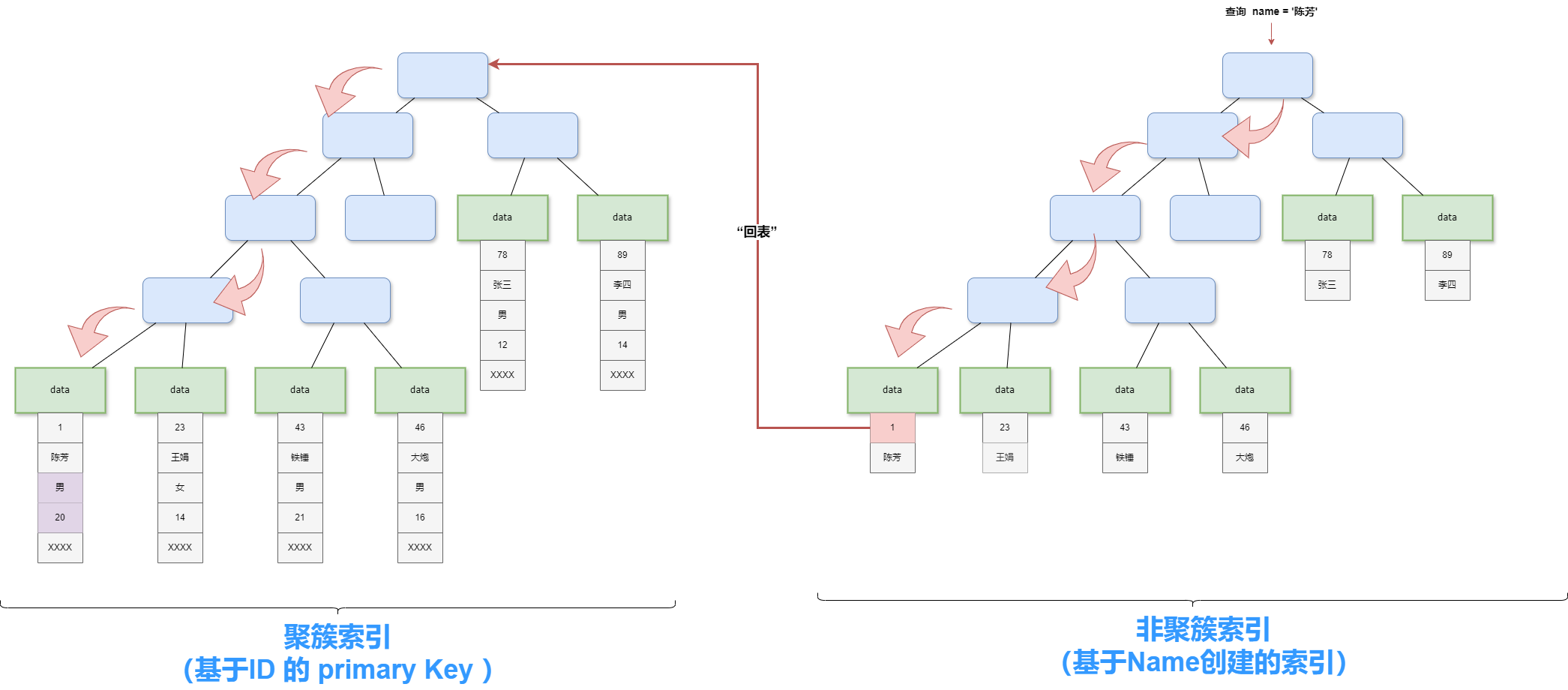
首先因为使用了name列进行等值查询,此时会先使用Name索引的B+树,进行搜索,当找到name为陈芳的叶子节点时,会拿到其ID,再回到基于ID的聚簇索引B+树上进行基于ID=1的搜索,最终找到其叶子节点,拿到上面的性别和年龄,其中这种需要两段使用索引的过程就是常说的回表查询。
虽然InnoDB 和MyISAM 存储引擎都默认使用B+树结构存储索引,但是只有InnoDB的主键索引才是聚簇索引,InnoDB中的辅助索引以及MyISAM使用的都是非聚簇索引。
索引的使用
创建索引的原则
- 在经常需要搜索的列上,可以加快搜索的速度
- 在作为主键的列上,强制该列的唯一性和组织表中数据的排列结构
- 在经常用在连接(JOIN)的列上,这些列主要是一外键,可以加快连接的速度
- 在经常需要根据范围(<,<=,=,>,>=,BETWEEN,IN)进行搜索的列上创建索引,因为索引已经排序,其指定的范围是连续的
- 在经常需要排序(order by)的列上创建索引,因为索引已经排序,这样查询可以利用索引的排序,加快排序查询时间;
- 在经常使用在WHERE子句中的列上面创建索引,加快条件的判断速度。
数据类型对于索引的不同表现
VARCHAR类型
VARCHAR类型用于存储可变长度的字符串。
- 前缀索引 :由于
VARCHAR类型的列可能很长,为了节省空间和提高效率,可以只为每个值的前几个字符创建索引,称为前缀索引。但是,前缀索引会降低索引的选择性,可能需要扫描更多的行来找到匹配的记录。 - 区分度:在选择前缀长度时,应该考虑列的区分度。如果大多数行的前缀都相同,那么前缀索引的效果可能不佳。
- 索引效率 :等值查询、
IN子句查询 等效率较高,VARCHAR类型的列在排序和比较时是按字典顺序进行的,这可能会影响范围查询 的性能。VARCHAR类型的索引在没有使用函数或表达式的情况下性能较好,但如果在查询中对字符串列使用了函数(如CONCAT、SUBSTRING等),索引可能失效,导致全表扫描。
数字类型
数字类型泛指数字相关类型,例如INT、FLOAT、Double等。
- 选择性:整数类型的列通常具有很高的选择性,这意味着索引中的值分布均匀,可以有效地减少查询中需要检查的行数。
- 索引效率 :**等值查询、范围查询(
>、<、BETWEEN等)**效率较高,数字类型的索引在进行范围查询时查询性能上通常优于字符串类型。
日期类型
DATETIME类型用于存储日期和时间。
- 时区影响:在处理跨时区的数据时,需要注意时区转换可能对索引的使用和查询结果产生影响。
- 函数影响 :如果查询中使用了日期函数(如
DATE_FORMAT),可能会导致索引失效 - 索引效率 :
DATETIME类型的列在进行等值查询 和范围查询时效率较高,因为日期和时间的比较操作非常快速。
其他
- 列的NULL值 :如果列中包含NULL值,索引的行为可能会受到影响。例如,
VARCHAR类型的列如果允许NULL值,可能会在索引中占用额外的空间。 - 列的默认值 :默认值可能会影响索引的选择性。例如,如果一个
INT类型的列有一个默认值,那么很多行可能会有相同的默认值,这会降低索引的选择性。 - 列的更新频率:频繁更新的列可能会使索引变得碎片化,从而影响索引的性能。因此,对于经常更新的列,可能需要定期重建索引。
组合索引的使用原则
在MySQL中使用组合索引时,"最左前缀 "原则决定了索引的使用方式和查询优化的效果。这个原则指的是,MySQL会按照组合索引中列的顺序,从左到右使用索引中的列。只有当索引的最左列被包含在查询条件中时,索引才会被有效地使用。如果查询条件中跳过了索引中的某个列,那么该列及其右边的所有列都不会被用于索引查询。
例如:将tb_flow_visit表的 源ip、目的ip、访问时间 三个字段设置为组合索引(注意设置的顺序)
ALTER TABLE tb_flow_visit ADD INDEX commIndies (sip, dip,visit_time);顺序优先
在组合索引中,MySQL会按照(源ip、目的ip、访问时间 )这个顺序来匹配条件。如果WHERE子句中首先出现的是sip字段匹配相关的条件,那么索引才会被使用。
-- 有效索引查询(全部匹配)
SELECT * FROM tb_flow_visit WHERE sip = '192.168.1.1' AND dip = '192.168.1.2' AND visit_time = '2023-08-01';
-- 有效索引查询(部分匹配)
SELECT * FROM tb_flow_visit WHERE sip = '192.168.1.1' AND dip = '192.168.1.2';不能跳过
如果你的查询条件首先使用了**dip(或者visit_time)** 而没有包含**sip**,那么这个组合索引将不会被使用,因为违反了最左前缀原则。
-- 无效索引,不能跳过sip
SELECT * FROM tb_flow_visit WHERE dip = '192.168.1.2' AND visit_time = '2024-08-01';
-- 无效索引,组合索引中,如过不按照索引顺序,即便单独使用其中任何一列也无效
SELECT * FROM tb_flow_visit WHERE dip = '192.168.1.2';
或
SELECT * FROM tb_flow_visit WHERE visit_time > '2024-08-01';;部分匹配
如果WHERE子句中包含了从索引最左列开始的连续列,那么索引可以被部分使用。例如:使用了最左列sip的字段和visit_time字段,因此会有效使用**sip列的索引,但不会使用dip和visit_time列的索引**。
SELECT * FROM tb_flow_visit WHERE sip = '192.168.1.1' AND visit_time > '2024-08-01';范围查询限制
在MySQL中,最左原则的范围查询限制是指在使用组合索引时,如果查询条件中包含了范围查询(如>、<、BETWEEN、LIKE等),那么这个范围查询必须应用于组合索引的最左列或者紧挨着最左列的列(如果最左列是常量条件)。如果范围查询跳过了最左列或者在非最左列上使用,那么索引将不会被有效使用; 例如在最左列(sip)上使用了范围查询(如sip > '192.168.1.2'),那么后续的列仍然可以被索引使用,但最左列之后的列必须是等值查询,不能是范围查询。
-- 无效索引
SELECT * FROM tb_flow_visit WHERE sip > '192.168.1.2' AND dip > '192.168.2.1';
AND visit_time = '2024-08-01';
-- 有效索引
SELECT * FROM tb_flow_visit WHERE sip > '192.168.1.2' AND dip = '192.168.2.1' AND visit_time = '2024-08-01';