Selenium自动化
Selenium是一个用于Web应用程序的自动化测试工具。它直接运行在浏览器中,可以模拟用户在浏览器上面的行为操作。
chrome下载
https://www.google.com/chrome/
下载的结果是 "ChromeSetup.exe",双击该文件,安装程序会自动启动。

默认安装位置:C:\Program Files\Google\Chrome\Application\chrome.exe
结果我的在:C:\Users\91073\AppData\Local\Google\Chrome\Application\chrome.exe
。。。为啥?
下载驱动
最新版:Chrome for Testing availability
查看谷歌浏览器版本
谷歌浏览器输入网址的地方输入:chrome://version
下载与浏览器对应(或相近)版本的浏览器驱动:http://chromedriver.storage.googleapis.com/index.html备用地址:CNPM Binaries Mirror


解压后得到一个chromedriver.exe驱动文件
禁用自动升级
关闭自动升级方法:
1.右键单击【计算机】------【管理】------【计算机管理本地】------【系统工具】------【任务计划程序】------【任务计划程序库】------这里找到两个和Google自动更新相关的任务计划【GoogleUpdateTaskMachineCore】与【GoogleUpdateTaskMachineUA】,把这两个选项禁用。
2.在【服务和应用程序】------【服务】,这里找到了两个和Google更新相关的服务【Google更新服务(gupdate)】、【Google更新服务(gupdatem)】,右键------选择属性------启动类型禁用即可;

卸载谷歌浏览器
在卸载当前版本之前,建议备份你的书签、扩展、密码等资料。
- 通过Windows + R快捷键调出"运行"对话框。
- 键入APPWIZ.CPL和命中输入。

这将带您到所有已安装应用程序的列表。从列表中选择Google Chrome,然后点击卸载 命令。
降级版本
版本报错
Caused by: org.openqa.selenium.SessionNotCreatedException: session not created: This version of ChromeDriver only supports Chrome version 114
Current browser version is 116.0.5845.97 with binary path C:\Users\91073\AppData\Local\Google\Chrome\Application\chrome.exeGoogle浏览器历史版本下载地址
Download older versions of Google Chrome for Windows, Linux and Mac
按住alt键,双击桌面的谷歌浏览器桌面图标
拷贝目标路径:C:\Users\lenovo\AppData\Local\Google\Chrome\Application\chrome.exe
打开命令提示符,输入如下并回车键;
cd C:\Users\lenovo\AppData\Local\Google\Chrome\Application输入"chrome.exe--disable-remote-words-auto-upgrade--version=版本号",然后按回车键。在这里,请将"版本号"替换为所需的版本号。

Selenium入门
maven坐标
打开selenium的仓库地址 : https://mvnrepository.com/artifact/org.seleniumhq.selenium/selenium-java
直接拷贝到pom文件吧,,
XML
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-java</artifactId>
<version>3.141.5</version>
</dependency>
<!-- 测试工具testng-->
<dependency>
<groupId>org.testng</groupId>
<artifactId>testng</artifactId>
<version>6.14.3</version>
<scope>test</scope>
</dependency>入门案例
如果浏览器驱动未加入环境变量,那么创建浏览器驱动的时候,需要指定浏览器驱动的路径
java
public class Client {
public static void main(String[] args) throws InterruptedException {
//配置浏览器驱动地址
System.setProperty("webdriver.chrome.driver", "D:\\tools\\chrome\\driver113\\chromedriver.exe");
//打开Chrome浏览器
WebDriver webDriver = new ChromeDriver();
TimeUnit.SECONDS.sleep(5);
//打开百度网站
webDriver.get("https://www.baidu.com");
TimeUnit.SECONDS.sleep(2);
//输入框输入搜索关键词 selenium 中文官网
webDriver.findElement(By.id("kw")).sendKeys("selenium 中文官网");
TimeUnit.SECONDS.sleep(2);
//点击百度一下按钮
webDriver.findElement(By.id("su")).submit();
TimeUnit.SECONDS.sleep(2);
//查询所有搜索的结果
List<WebElement> resultElements = webDriver.findElements(By.className("result"));
if (!resultElements.isEmpty()) {
//找到第一条结果的第一个链接
List<WebElement> aTagElements = resultElements.get(0).findElements(By.tagName("a"));
if (!aTagElements.isEmpty()) {
//新开一个窗口打开此链接
String href = aTagElements.get(0).getAttribute("href");
System.out.println(href);
((JavascriptExecutor) webDriver).executeScript(String.format("window.open('%s')", href));
}
}
TimeUnit.SECONDS.sleep(10);
//关闭浏览器
webDriver.quit();
}
}结果,很神奇的哦
命令行打开浏览器
java
new ChromeDriver(options);如果希望Chrome 浏览器启动时附带启动参数,可通过addArguments 方式加载。
希望测试某个浏览器插件,可通过addExtensions方式提前加载以.crx 为扩展名的插件
感觉上和addArguments有点类似,不过setExperimentalOption是设置实验选项 (ChromeDriver选项尚未通过ChromeOptions API公开 ),这个方法我比较经常用来设置浏览器默认下载路径
对于一台机器上安装了多个版本的Chrome浏览器,可以使用setBinary 指定待测试Chrome。
让 selenium 连接我们手动打开的浏览器
打开浏览器有两种方式:图标点击和命令行运行。
图标点击不用多说,我们经常使用这种方式打开浏览器。命令行方式允许我啰嗦一句,找到浏览器的安装目录,在安装目录中输入 chrome.exe 就可以了。 比如我的 chrome 浏览器安装在
C:\Users\91073\AppData\Local\Google\Chrome\Application这个路径,则在这个目录下打开 cmd 命令行,输入 chrome.exe,就可以打开一个浏览器

在浏览器打开的时候设置额外的参数,为它提供不同的功能。 通过 selenium 连接浏览器,需要用到两个参数 --remote-debugging-port 和 --user-data-dir
-
--remote-debugging-port这个参数允许我们通过远程的方式连接,selenium 当然也可以。 -
--user-data-dir这个参数指定一个独立的目录存放产生的用户数据,在连接时也要设置,否则会失效。chrome.exe --remote-debugging-port=9222 --user-data-dir="F:\selenium\ChromeProfile"
有了远程调试地址,selenium 连接浏览器就变的很简单,只需要加 2 行代码。 创建一个选项,绑定debuggerAddress 远程调试地址。 此时就可以用 selenium 控制之前手工打开的浏览器了。
java
//配置浏览器驱动地址
System.setProperty("webdriver.chrome.driver", "F:\\webrpaTest\\RPA\\RoboticProcessAutomation\\browser\\driver\\chrome\\121\\chromedriver.exe");
ChromeOptions options = new ChromeOptions();
options.setBinary("C:\\Users\\91073\\AppData\\Local\\Google\\Chrome\\Application\\chrome.exe");
//设置 Chrome 的远程调试端口地址
options.setExperimentalOption("debuggerAddress", "127.0.0.1:9222");
// WebDriver driver = new ChromeDriver(ChromeDriverService.createDefaultService(), options);
WebDriver driver = new ChromeDriver(options);
System.out.println(driver.getTitle());WebDriver 实例化参数
Chome浏览器部分
executable_path:浏览器驱动程序路径,如果没有制定,则默认使用环境变量PATH中设置的路径
options:启动选项 (Options对象通常位于各浏览器的 WebDriver 模块下,列如:from selenium.webdriver.浏览器名称.options import Options),建议优先使用options 参数来设置浏览器(options 基于 capabilities,在实例化某个浏览器的Options对象时会自动写入该浏览器预设的 capabilities)
service_log_path:驱动程序存放日志文件的位置
keep_alive:表示在与
ChromeDriver进行链接时,是否带上 HTTP 请求头Connection: keep-alive,既是否使用长链接,布尔类型参数,默认值为Trueservice_args:浏览器驱动程序的参数,根据所使用的浏览器驱动不同,参数也有可能不同。
Edge浏览器部分
- executable_path:浏览器驱动程序路径,如果没有制定,则默认使用环境变量PATH中设置的路径
- capabilities:非浏览器特定的字典对象,传入浏览器启动参数时需要使用到
port:驱动程序启用的端口号,如果不填写,则自动使用任意闲置的端口号,默认参数为0
verbose:是否在服务中设置详细日志记录
service_log_path:驱动程序存放日志文件的位置
log_path:不推荐使用的 service_log_path 参数
keep_alive:表示在与 EdgeDriver 进行链接时,是否带上 HTTP 请求头Connection: keep-alive,既是否使用长链接,布尔类型参数,默认值为True
元素定位
web自动化的难点和重点之一,就是如何 选择 我们想要操作的web页面元素。
id定位
id 定位 driver.findElement(By.id("id的值"));如果元素有id属性 ,这个id 必须是当前html中唯一的。所以如果元素有id, 根据id选择元素是最简单高效的方式。
- 使用WebDriver对象的findElement函数定义一个Web页面元素
- 使用findElements函数可以定位页面的多个元素
使用
find_elements选择的是符合条件的所有元素, 如果没有符合条件的元素,返回空列表
List<WebElement> listOfElements = driver.findElements(By.xpath("//div")); webElement.findElements(By.tagName("tr"));
- 如果没有匹配条件的元素,Find Elements命令将返回一个空列表
使用
find_element选择的是符合条件的第一个元素, 如果没有符合条件的元素,抛出 NoSuchElementException 异常
定位的页面元素需要使用WebElement对象来存储,以便后续使用
class定位
class 定位 driver.findElement(By.className("class属性"));
java
//企查查
webDriver.get("https://www.qcc.com/");
TimeUnit.SECONDS.sleep(2);
//查企业 查老板 查风险 查招标 找关系
List<WebElement> elements = webDriver.findElements(By.className("search-type"));class 属性通常用于指向样式表的类
在html中,class规定元素的类名,语法格式为"<元素名称 class="value">"。class属性大多数时候用于指向样式表中的类(class)。

html标签是允许定义多个class类名的。比如:
html
<div class = "exp1 exp2"></div>上边这个div就用到了exp1、exp2这两个class类,对于个数是没有限制,只需每个类名之间用空格隔开就好。
tag 名 定位
TagName 标签名称定位 driver.findElement(By.tagName("标签名称"));选择所有的tag名为 div的元素,如下所示
name定位
name定位 driver.findElement(By.name("name的值"));css定位
CSS定位为的优势在于定位速度比Xpath定位快,且比Xpath定位更加稳定
css 方式定位 driver.findElement(By.cssSelector("css表达式"));Xpath定位
xpath定位方式
xpath 是XML Path的简称, 用于在XML文档中选择文档中的节点。基于XML树状文档结构,Xpath语言可以在整棵树中寻找指定的节点。
javaxpath 方式定位 driver.findElement(By.xpath("xpath表达式"));xpath 有两种表示方法,绝对路径和相对路径,
绝对路径是指从根开始,以/开始,如/html/body/div,
相对路径是指在一个路径下,另外的路径以这个路径作为参照,以//开始。从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。
- XPath表达式中的//表示在HTML文档的全部层级位置进行查找
举例如下:
java
//百度一下
webDriver.get("https://www.baidu.com");
WebElement element = webDriver.findElement(By.xpath("//*[@id='su']"));这里 为啥是**//*@** 呢?
- //表示从任意位置去查找
- *是标签名
- @是属性定位
强烈建议使用相对路径和属性值结合的定位方式来编写xpath定位表达式。如
javaBy.xpath("//*[@id='su']")
xpath获取
xpath获取技巧:网页的html是一种特殊的XML文档。使用浏览器调试工具,可以直接获取xpath语句
右键-检查(或者F12),然后点击这个箭头,就可以在浏览器上选择元素了
使用Chrome 来直接获取元素的XPath.
通过层级关系和索引定位(索引从1开始):
XML//*[@id="content"]/div/div[2]/div[4]/div[2]/h2/div[2]/form/div

标签+属性定位
XPath通过id,name,class属性定位。语法如下:
//标签名[@属性名='属性值']
java
//用XPath通过id属性定位
element1 = driver.find_element_by_xpath("//input[@id='kw']")
//用XPath通过name属性定位
element2 = driver.find_element_by_xpath("//input[@name='wd']")
//用XPath通过class属性定位
element3 = driver.find_element_by_xpath("//*[@class='s_ipt']")总结
- 如果不想制定标签名称,可以用*号表示任意标签。
- 有时候同一个属性,同名的比较多,这时候可以通过标签筛选下,定位更准一点。
- 如果想制定具体某个标签,就可以直接写标签名称
List pageUl = ar.driver.findElements(By.xpath("//ul@class='bfe-pager'"));//获取页数
层级定位
通过层级关系定位,注意:最终定位的是子标签....语法如下:
//父标签名[@父标签属性名='属性值']/子标签在页面中,定位下面代码片段中的<input>标签
html
<p id="p1">
<label for="userA">账号A</label>
<input required="" value="">
</p>答案如下:
java
driver.find_element_by_xpath("//p[@id='p1']/input")索引定位
索引定位元素,语法如下:
bash
//父标签名[@父标签属性名='属性值']/子标签[索引值] 索引从1开始比如我要定位如下图片的"京东家电连接"
答案是:
bash//*[@id=\"navitems-group1\"]/li[2]/a用id="navitems-group1"定位到如下图片这里,这些是一些li标签



//*[@id="navitems-group1"]/li[1]/a
//*[@id="navitems-group1"]/li/a注意:如果是第一个元素,索引值可以不加。因为不加索引值会选取ul下的全部li标签
而我们用的是单数定位形式,默认选择第一个。
文本定位
bash
//标签名[text()='文本']xpath定位时,定位某一元素不好定时,可以定位其子级元素,然后通过 /... 定位到它的父级元素。
bash
HTML实例:<button type="button" class="ant-btn ant-btn-primary"><span>新 建</span></button>
xpath定位://span[text()='搜 索']/..逻辑定位
XPath逻辑定位说明:
- xpath还有一个比较强的功能,可以支持与(and)、或(or)、非(not)。
- 一般用的比较多的是and运算,同时满足两个属性。
比如一个日期输入框无法输入
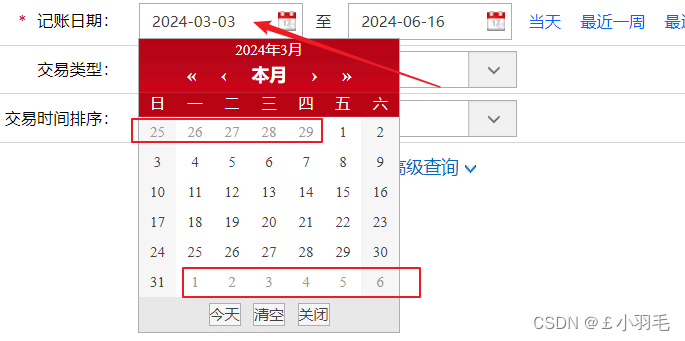
1
//获取当前页所有的数据
List datasaaa = ar.driver.findElements(By.xpath("/html/body/div[11]/table/tbody/tr/td[not(contains(@class, \"outMonthDay\"))]"));
System.out.println("datasaaa.size():"+datasaaa.size());
for(int i=0;i<datasaaa.size();i++){
String text=datasaaa.get(i).getText().trim();
System.out.println("text:" + text);
if(Integer.parseInt(text)==day1){
datasaaa.get(i).click();
break;
}
}判断元素是否存在
场景:比如银行某些账号的对账提醒,但是不是所有的账号都有。所以要先判断元素是否存在
捕获异常方式
捕获异常是使用f**indElement()**方法无法获取元素则会抛出异常,如果找到元素则会返回True
java//通过异常判断 public static boolean isElementExist(WebDriver driver, String xpath) { try { WebElement element = driver.findElement(By.xpath(xpath)); return true; } catch (Exception e) { e.printStackTrace(); return false; } }弊端:只要页面上有元素,不几个,都返回True
比如:在打开百度贴吧的时候,会有登录提醒。做一个判断,如果存在则关闭该弹窗
java
driver.get("https://tieba.baidu.com/");
//只需要设置一次,所有的元素都可有最多 10s 的等待加载的时间(默认0)
driver.manage().timeouts().implicitlyWait(10, TimeUnit.SECONDS);
//判断xpath是否存在,存在则点击关闭弹窗
boolean exist = isElementExist(driver, "//*[@id=\"tiebaCustomPassLogin\"]/div[2]/span");
父子、兄弟、相邻节点定位方式
相邻节点定位
比如,我要获取表格的总记录数。此时因为一个变化的值,
如果查询条数少,只有一页。则获取页数可以用xpath :/ul/li5/b
如果查询条数过多,则xpath发生变化:/ul/li6/b


此时,是否可以用兄弟节点定位。通过">"来定位。">"是可以用属性定位的//a@class=\\"next\\"
获取文本
//h5[text()='可用余额'//spantext() = '全部'/parent::label/span1
子节点定位父节点
result = html.xpath('//a[@id="parentSpan"]/text()')获取 href 属性
# 8、获取 href 属性
result = html.xpath('//a[@id="parentSpan"]/@href')