一、拓扑排序
拓扑排序的背景
拓扑排序是经典的图论问题。
拓扑排序的应用场景。
概括来说,给出一个 有向图,把这个有向图转成线性的排序 就叫拓扑排序。
当然拓扑排序也要检测这个有向图 是否有环,即存在循环依赖的情况,因为这种情况是不能做线性排序的。
所以拓扑排序也是图论中判断有向无环图的常用方法。
拓扑排序的思路
拓扑排序指的是一种 解决问题的大体思路, 而具体算法,可能是广搜也可能是深搜。
其实只要能在把 有向无环图 进行线性排序 的算法 都可以叫做 拓扑排序。
实现拓扑排序的算法有两种:卡恩算法(BFS)和DFS
卡恩1962年提出这种解决拓扑排序的思路
一般来说我们只需要掌握 BFS (广度优先搜索)就可以了,清晰易懂
接下来讲解BFS的实现思路。
以题目中示例为例如图:
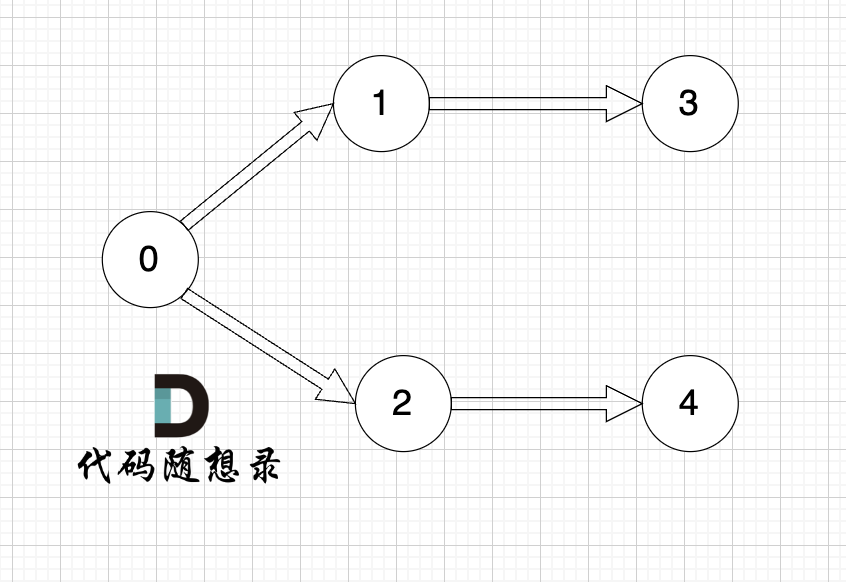
做拓扑排序的话,如果肉眼去找开头的节点,一定能找到 节点0 吧,都知道要从节点0 开始。
但为什么我们能找到 节点0呢,因为我们肉眼看着 这个图就是从 节点0出发的。
作为出发节点,它有什么特征?节点0 的入度 为0 出度为2, 也就是 没有边指向它,而它有两条边是指出去的。
节点的入度表示 有多少条边指向它,节点的出度表示有多少条边 从该节点出发。
做拓扑排序的时候,应该优先找 入度为 0 的节点,只有入度为0,它才是出发节点。
接下来我给出 拓扑排序的过程,其实就两步:
- 找到入度为0 的节点,加入结果集
- 将该节点从图中移除
循环以上两步,直到 所有节点都在图中被移除了。
结果集的顺序,就是我们想要的拓扑排序顺序 (结果集里顺序可能不唯一)
模拟过程
用本题的示例来模拟这一过程:
1、找到入度为0 的节点,加入结果集
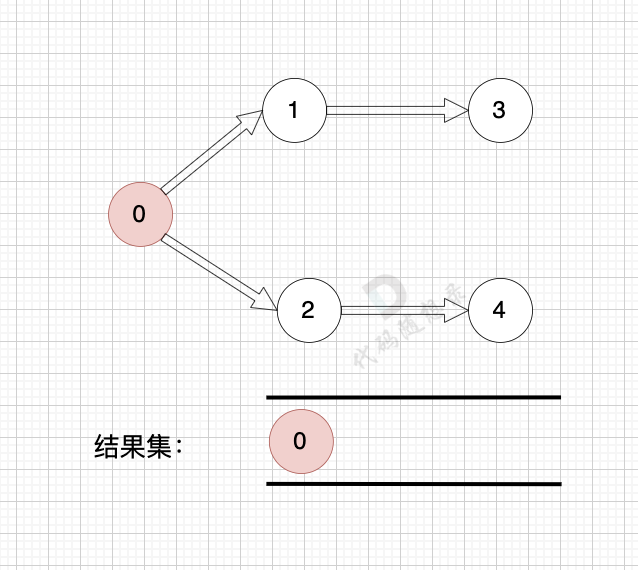
2、将该节点从图中移除
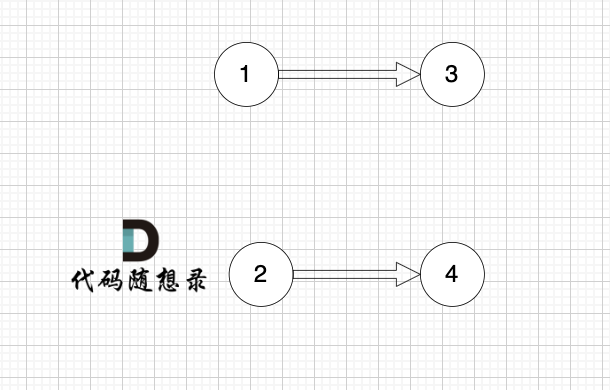
1、找到入度为0 的节点,加入结果集
节点1 和 节点2 入度都为0, 选哪个呢?
选哪个都行,所以这也是为什么拓扑排序的结果是不唯一的。
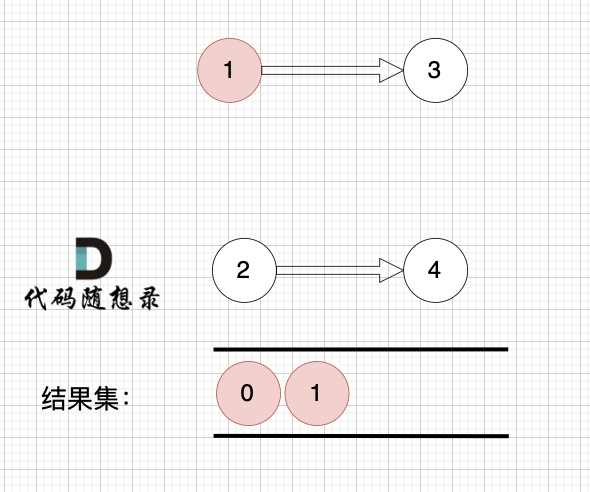
2、将该节点从图中移除
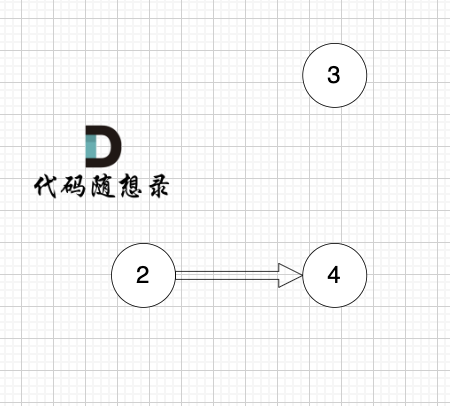
1、找到入度为0 的节点,加入结果集
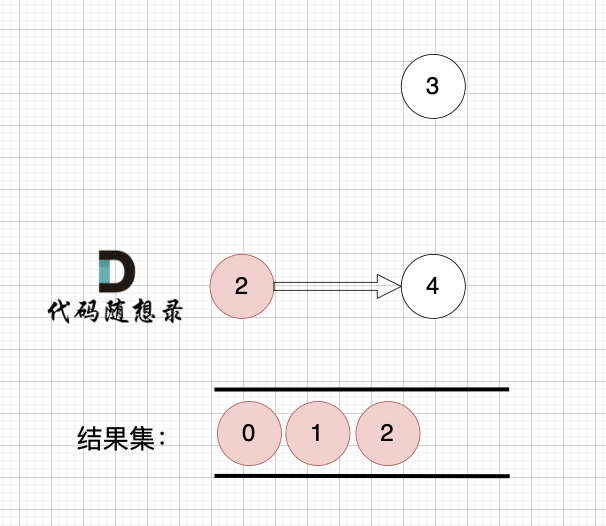
节点2 和 节点3 入度都为0,选哪个都行,这里选节点2
2、将该节点从图中移除
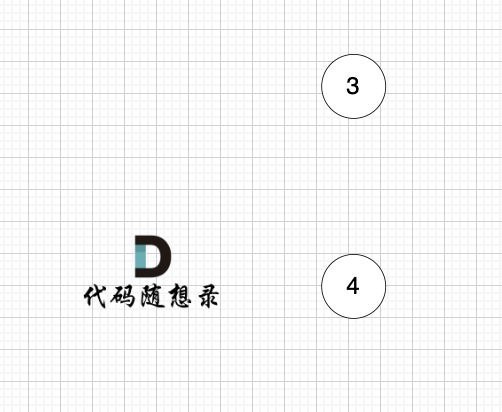
后面的过程一样的,节点3 和 节点4,入度都为0,选哪个都行。
最后结果集为: 0 1 2 3 4 。当然结果不唯一的。
判断有环
如果有 有向环怎么办呢?例如这个图:
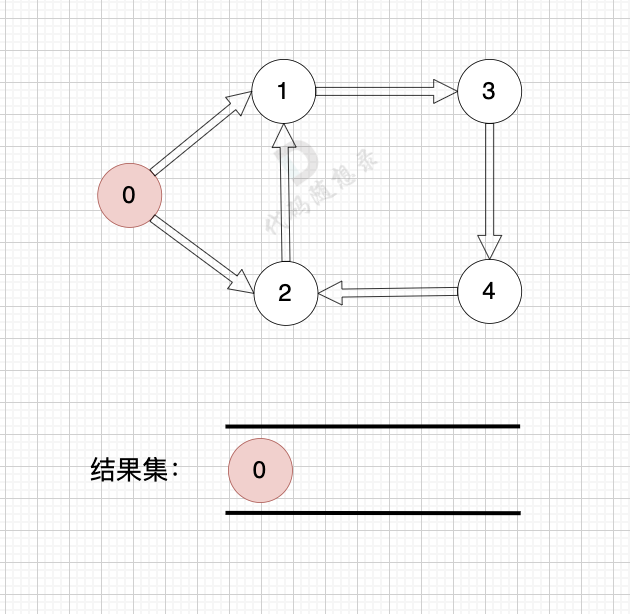
这个图只能将入度为0 的节点0 接入结果集。
之后,节点1、2、3、4 形成了环,找不到入度为0 的节点了,所以此时结果集里只有一个元素。
那么如果发现结果集元素个数 不等于 图中节点个数,我们就可以认定图中一定有 有向环
这也是拓扑排序判断有向环的方法。
写代码
理解思想后,确实不难,但代码写起来也不容易。
为了每次可以找到所有节点的入度信息,在初始化的时候,就把每个节点的入度 和 每个节点的依赖关系做统计。
代码如下:
cpp
cin >> n >> m;
vector<int> inDegree(n, 0); // 记录每个文件的入度
vector<int> result; // 记录结果
unordered_map<int, vector<int>> umap; // 记录文件依赖关系
while (m--) {
// s->t,先有s才能有t
cin >> s >> t;
inDegree[t]++; // t的入度加一
umap[s].push_back(t); // 记录s指向哪些文件
}找入度为0 的节点,需要用一个队列放存放。
因为每次寻找入度为0的节点,不一定只有一个节点,可能很多节点入度都为0,所以要将这些入度为0的节点放到队列里,依次去处理。
代码如下:
cpp
queue<int> que;
for (int i = 0; i < n; i++) {
// 入度为0的节点,可以作为开头,先加入队列
if (inDegree[i] == 0) que.push(i);
}开始从队列里遍历入度为0 的节点,将其放入结果集。
cpp
while (que.size()) {
int cur = que.front(); // 当前选中的节点
que.pop();
result.push_back(cur);
// 将该节点从图中移除
}这里面还有一个很重要的过程,如何把这个入度为0的节点从图中移除呢?
首先为什么要把节点从图中移除?为的是将 该节点作为出发点所连接的边删掉。
删掉的目的是要把 该节点作为出发点所连接的节点的 入度 减一。
如果这里不理解,看上面的模拟过程第一步:
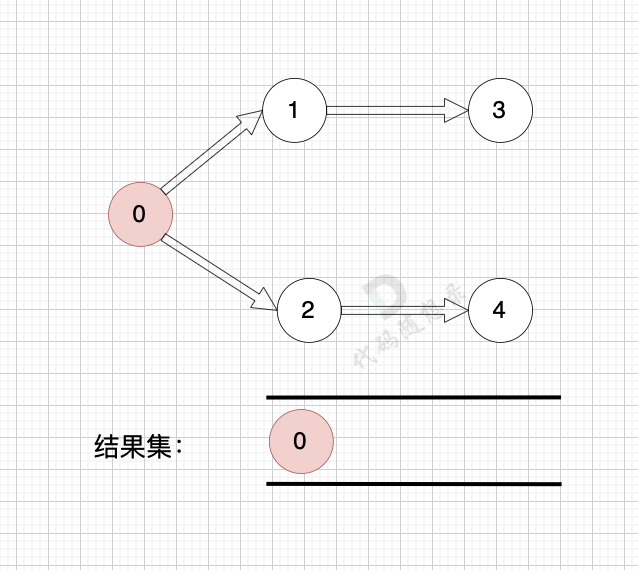
这事节点1 和 节点2 的入度为 1。
将节点0删除后,图为这样:
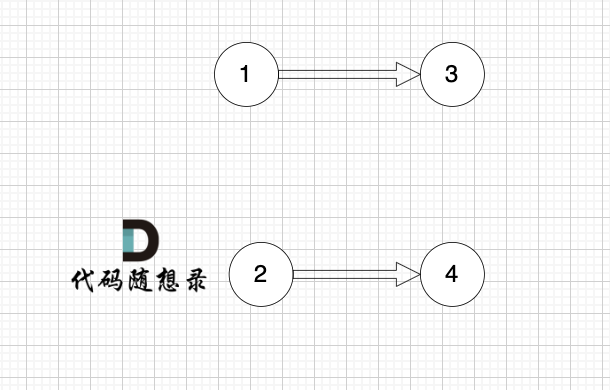
那么 节点0 作为出发点 所连接的节点的入度 就都做了 减一 的操作。
此时 节点1 和 节点 2 的入度都为0, 这样才能作为下一轮选取的节点。
所以,我们在代码实现的过程中,本质是要将 该节点作为出发点所连接的节点的 入度 减一 就可以了,这样好能根据入度找下一个节点,不用真在图里把这个节点删掉。
该过程代码如下:
cpp
while (que.size()) {
int cur = que.front(); // 当前选中的节点
que.pop();
result.push_back(cur);
// 将该节点从图中移除
vector<int> files = umap[cur]; //获取cur指向的节点
if (files.size()) { // 如果cur有指向的节点
for (int i = 0; i < files.size(); i++) { // 遍历cur指向的节点
inDegree[files[i]] --; // cur指向的节点入度都做减一操作
// 如果指向的节点减一之后,入度为0,说明是我们要选取的下一个节点,放入队列。
if(inDegree[files[i]] == 0) que.push(files[i]);
}
}
}最后代码如下:
cpp
#include <iostream>
#include <vector>
#include <queue>
#include <unordered_map>
using namespace std;
int main() {
int m, n, s, t;
cin >> n >> m;
vector<int> inDegree(n, 0); // 记录每个文件的入度
unordered_map<int, vector<int>> umap;// 记录文件依赖关系
vector<int> result; // 记录结果
while (m--) {
// s->t,先有s才能有t
cin >> s >> t;
inDegree[t]++; // t的入度加一
umap[s].push_back(t); // 记录s指向哪些文件
}
queue<int> que;
for (int i = 0; i < n; i++) {
// 入度为0的文件,可以作为开头,先加入队列
if (inDegree[i] == 0) que.push(i);
//cout << inDegree[i] << endl;
}
// int count = 0;
while (que.size()) {
int cur = que.front(); // 当前选中的文件
que.pop();
//count++;
result.push_back(cur);
vector<int> files = umap[cur]; //获取该文件指向的文件
if (files.size()) { // cur有后续文件
for (int i = 0; i < files.size(); i++) {
inDegree[files[i]] --; // cur的指向的文件入度-1
if(inDegree[files[i]] == 0) que.push(files[i]);
}
}
}
if (result.size() == n) {
for (int i = 0; i < n - 1; i++) cout << result[i] << " ";
cout << result[n - 1];
} else cout << -1 << endl;
}二、dijkstra
本题就是求最短路,最短路是图论中的经典问题即:给出一个有向图,一个起点,一个终点,问起点到终点的最短路径。
dijkstra算法:在有权图(权值非负数)中求从起点到其他节点的最短路径算法。
需要注意两点:
- dijkstra 算法可以同时求 起点到所有节点的最短路径
- 权值不能为负数
(这两点后面我们会讲到)
如本题示例中的图:
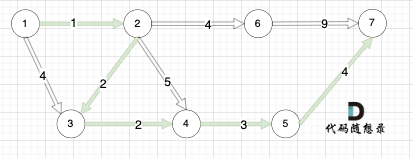
起点(节点1)到终点(节点7) 的最短路径是 图中 标记绿线的部分。
最短路径的权值为12。
其实 dijkstra 算法 和 我们之前讲解的prim算法思路非常接近。dijkstra 算法 同样是贪心的思路,不断寻找距离 源点最近的没有访问过的节点。
dijkstra三部曲:
- 第一步,选源点到哪个节点近且该节点未被访问过
- 第二步,该最近节点被标记访问过
- 第三步,更新非访问节点到源点的距离(即更新minDist数组)
在dijkstra算法中,同样有一个数组很重要,起名为:minDist。minDist数组 用来记录 每一个节点距离源点的最小距离。
朴素版dijkstra
模拟过程
0、初始化
minDist数组数值初始化为int最大值。
minDist数组的含义:记录所有节点到源点的最短路径,那么初始化的时候就应该初始为最大值,这样才能在后续出现最短路径的时候及时更新。
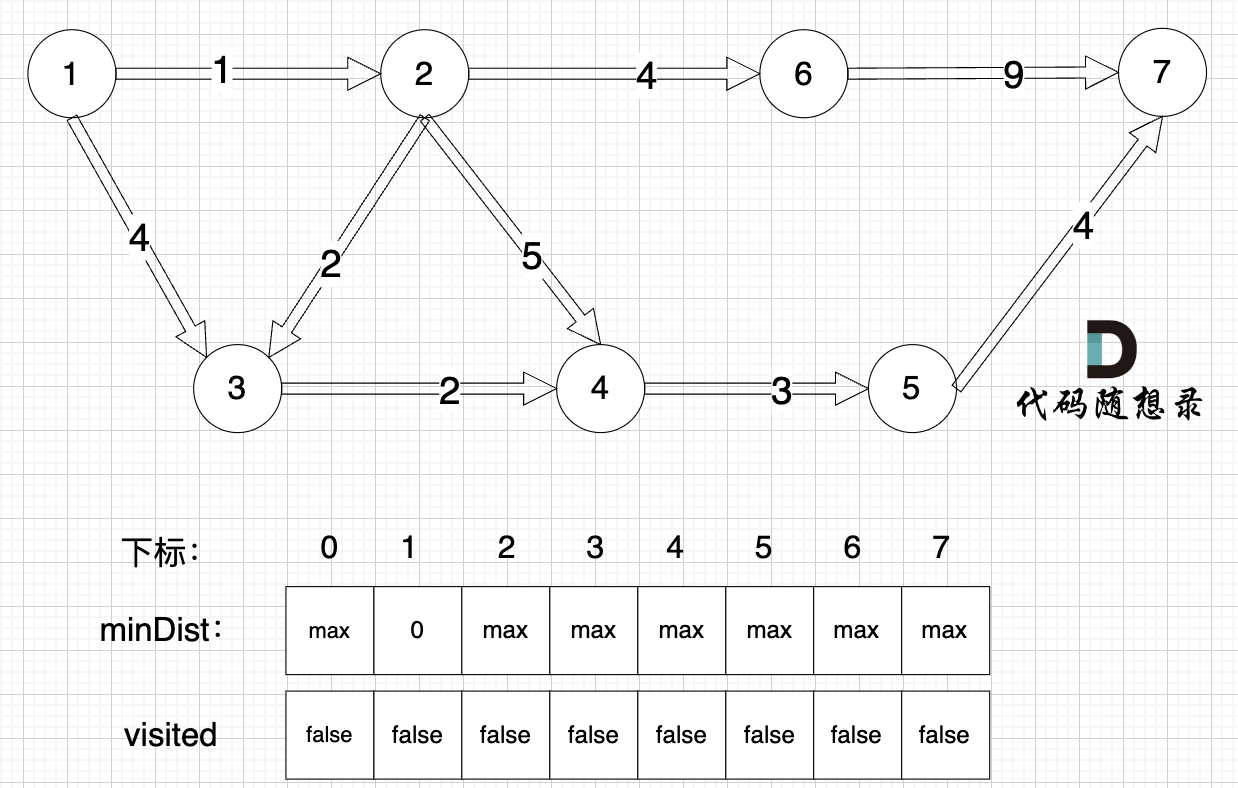
(图中,max 表示默认值,节点0 不做处理,统一从下标1 开始计算,这样下标和节点数值统一, 方便理解)
源点(节点1) 到自己的距离为0,所以 minDist1 = 0
此时所有节点都没有被访问过,所以 visited数组都为0
以下为dijkstra 三部曲
1、选源点到哪个节点近且该节点未被访问过
源点距离源点最近,距离为0,且未被访问。
2、该最近节点被标记访问过
标记源点访问过
3、更新非访问节点到源点的距离(即更新minDist数组) ,如图:
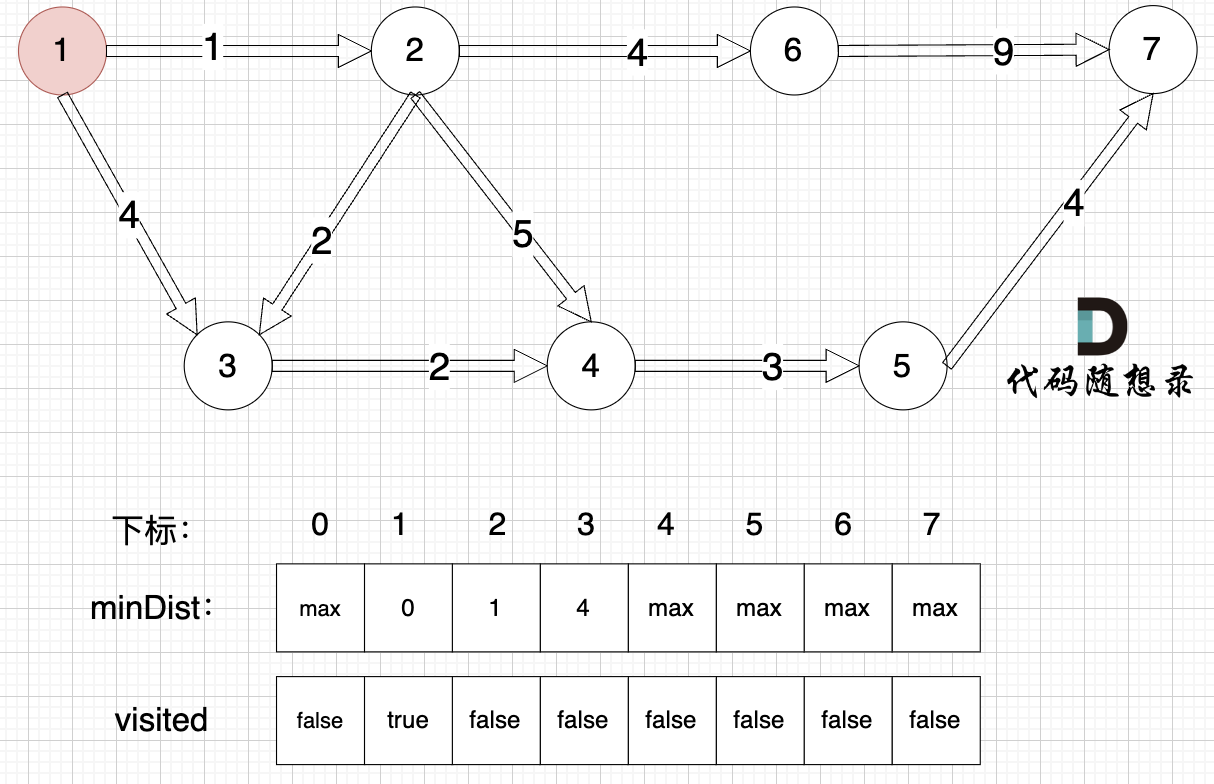
更新 minDist数组,即:源点(节点1) 到 节点2 和 节点3的距离。
- 源点到节点2的最短距离为1,小于原minDist2的数值max,更新minDist2 = 1
- 源点到节点3的最短距离为4,小于原minDist3的数值max,更新minDist3 = 4
1、选源点到哪个节点近且该节点未被访问过
未访问过的节点中,源点到节点2距离最近,选节点2
2、该最近节点被标记访问过
节点2被标记访问过
3、更新非访问节点到源点的距离(即更新minDist数组) ,如图:
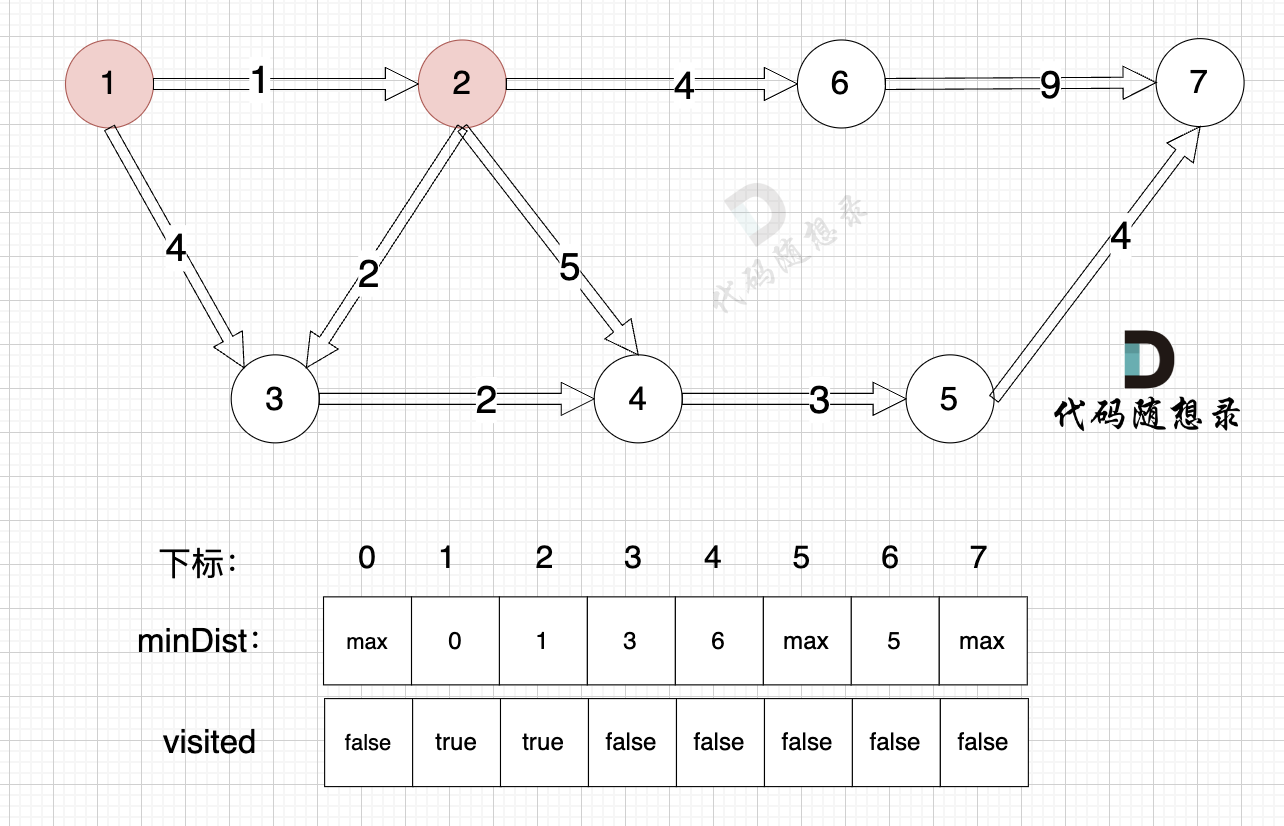
更新 minDist数组,即:源点(节点1) 到 节点6 、 节点3 和 节点4的距离。
为什么更新这些节点呢? 怎么不更新其他节点呢?
因为 源点(节点1)通过 已经计算过的节点(节点2) 可以链接到的节点 有 节点3,节点4和节点6.
更新 minDist数组:
- 源点到节点6的最短距离为5,小于原minDist6的数值max,更新minDist6 = 5
- 源点到节点3的最短距离为3,小于原minDist3的数值4,更新minDist3 = 3
- 源点到节点4的最短距离为6,小于原minDist4的数值max,更新minDist4 = 6
1、选源点到哪个节点近且该节点未被访问过
未访问过的节点中,源点距离哪些节点最近,怎么算的?其实就是看 minDist数组里的数值,minDist 记录了 源点到所有节点的最近距离,结合visited数组筛选出未访问的节点就好。
从 上面的图,或者 从minDist数组中,我们都能看出 未访问过的节点中,源点(节点1)到节点3距离最近。
2、该最近节点被标记访问过
节点3被标记访问过
3、更新非访问节点到源点的距离(即更新minDist数组) ,如图:
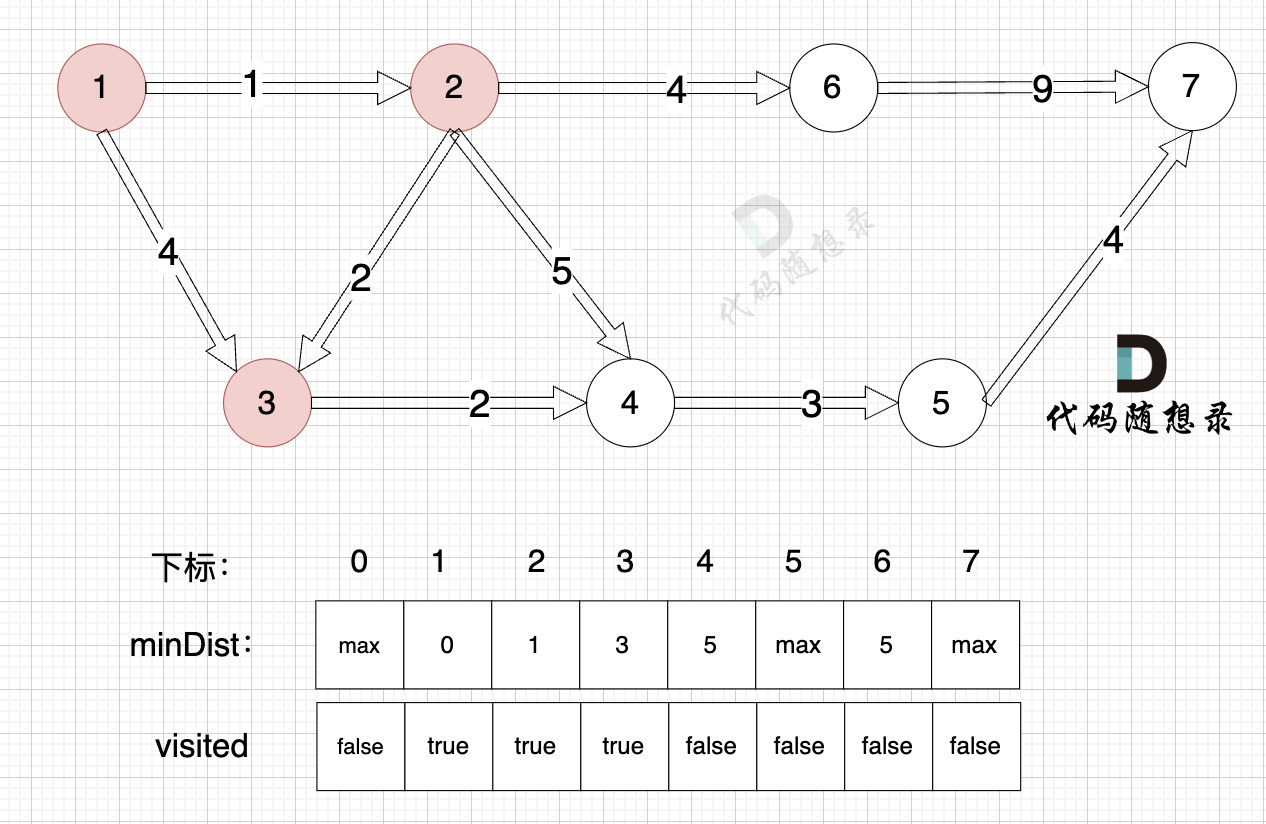
由于节点3的加入,那么源点可以有新的路径链接到节点4 所以更新minDist数组:
更新 minDist数组:
- 源点到节点4的最短距离为5,小于原minDist4的数值6,更新minDist4 = 5
1、选源点到哪个节点近且该节点未被访问过
距离源点最近且没有被访问过的节点,有节点4 和 节点6,距离源点距离都是 5 (minDist4 = 5,minDist6 = 5) ,选哪个节点都可以。
2、该最近节点被标记访问过
节点4被标记访问过
3、更新非访问节点到源点的距离(即更新minDist数组) ,如图:
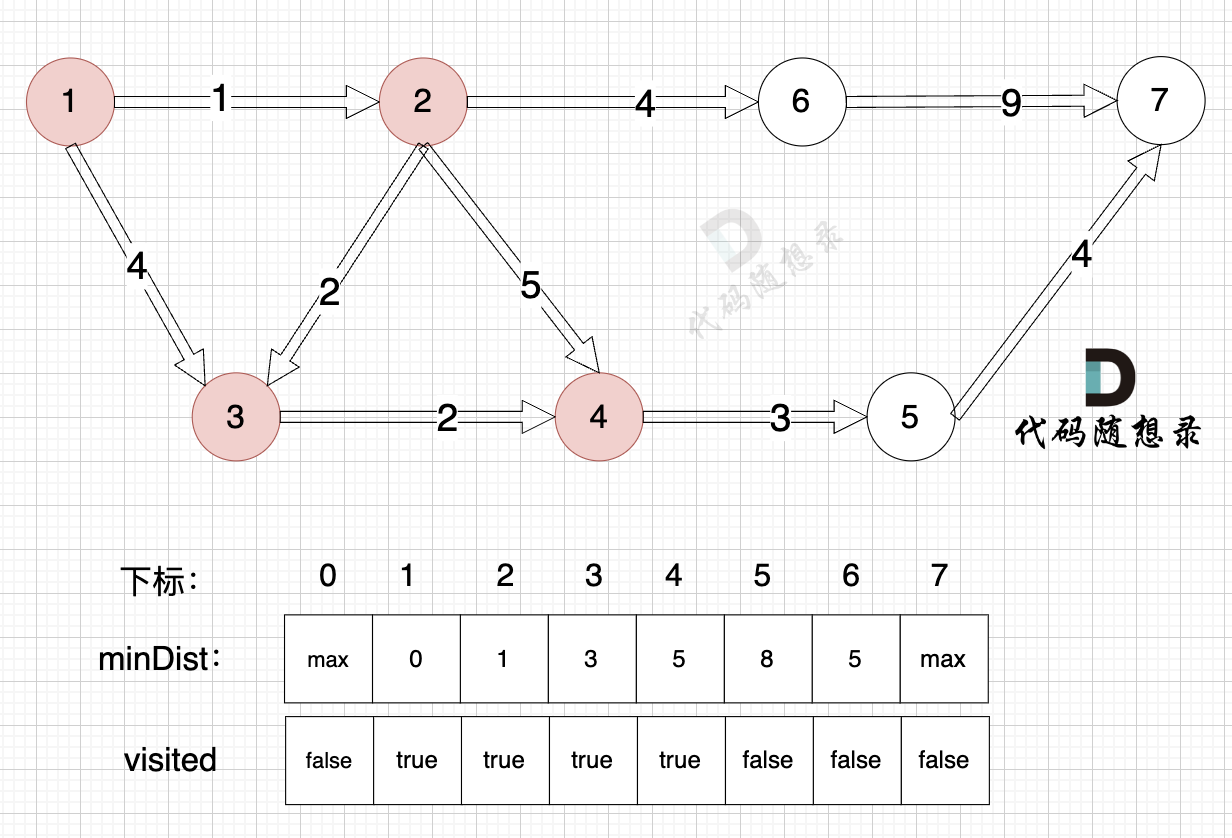
由于节点4的加入,那么源点可以链接到节点5 所以更新minDist数组:
- 源点到节点5的最短距离为8,小于原minDist5的数值max,更新minDist5 = 8
1、选源点到哪个节点近且该节点未被访问过
距离源点最近且没有被访问过的节点,是节点6,距离源点距离是 5 (minDist6 = 5)
2、该最近节点被标记访问过
节点6 被标记访问过
3、更新非访问节点到源点的距离(即更新minDist数组) ,如图:
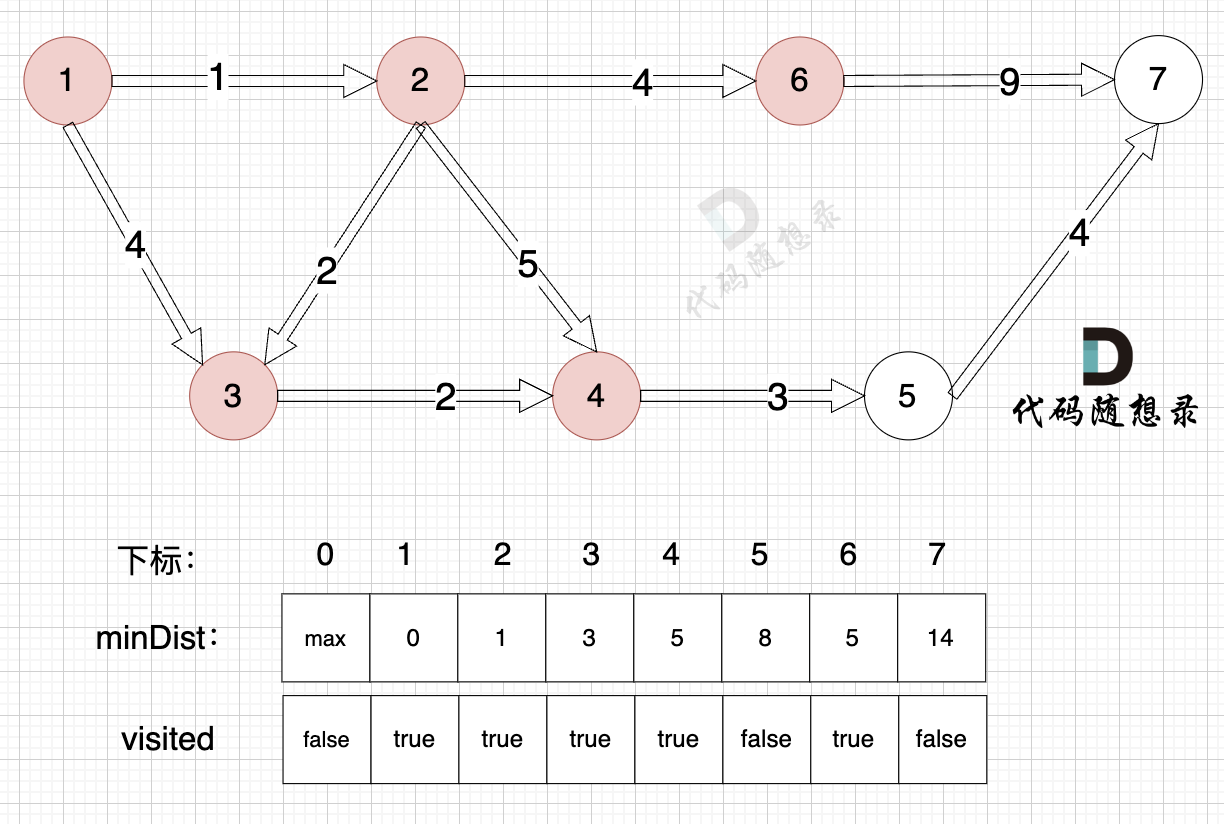
由于节点6的加入,那么源点可以链接到节点7 所以 更新minDist数组:
- 源点到节点7的最短距离为14,小于原minDist7的数值max,更新minDist7 = 14
1、选源点到哪个节点近且该节点未被访问过
距离源点最近且没有被访问过的节点,是节点5,距离源点距离是 8 (minDist5 = 8)
2、该最近节点被标记访问过
节点5 被标记访问过
3、更新非访问节点到源点的距离(即更新minDist数组) ,如图:
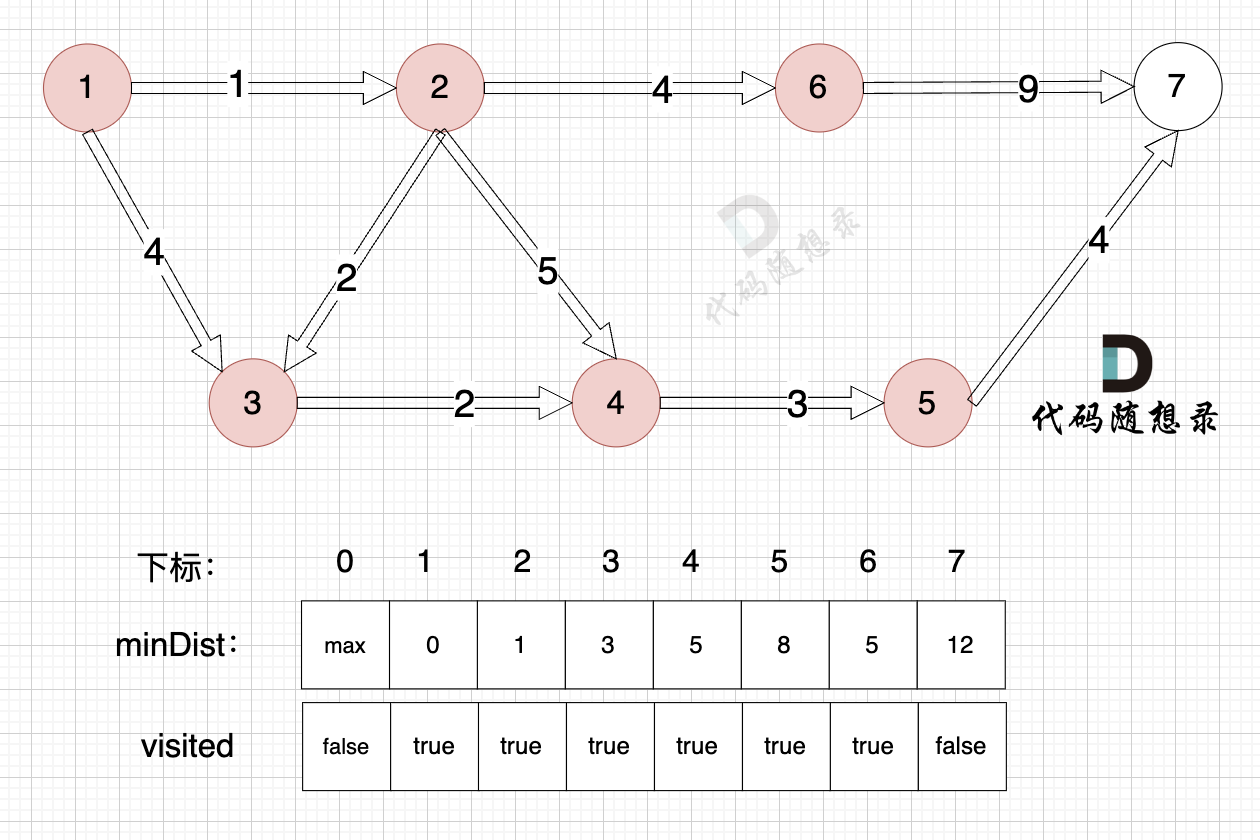
由于节点5的加入,那么源点有新的路径可以链接到节点7 所以 更新minDist数组:
- 源点到节点7的最短距离为12,小于原minDist7的数值14,更新minDist7 = 12
1、选源点到哪个节点近且该节点未被访问过
距离源点最近且没有被访问过的节点,是节点7(终点),距离源点距离是 12 (minDist7 = 12)
2、该最近节点被标记访问过
节点7 被标记访问过
3、更新非访问节点到源点的距离(即更新minDist数组) ,如图:
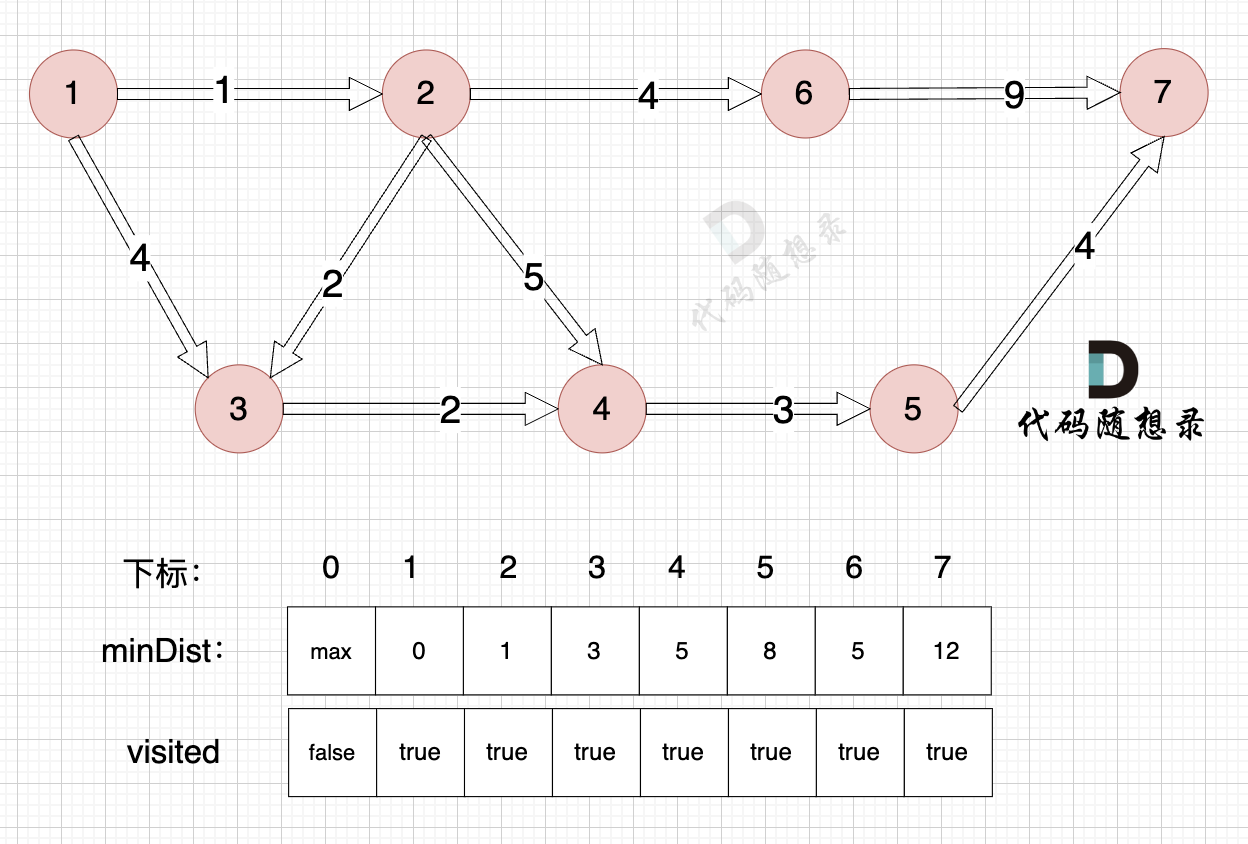
节点7加入,但节点7到节点7的距离为0,所以 不用更新minDist数组
最后我们要求起点(节点1) 到终点 (节点7)的距离。
再来回顾一下minDist数组的含义:记录 每一个节点距离源点的最小距离。
那么起到(节点1)到终点(节点7)的最短距离就是 minDist7 ,按上面举例讲解来说,minDist7 = 12,节点1 到节点7的最短路径为 12。
路径如图:
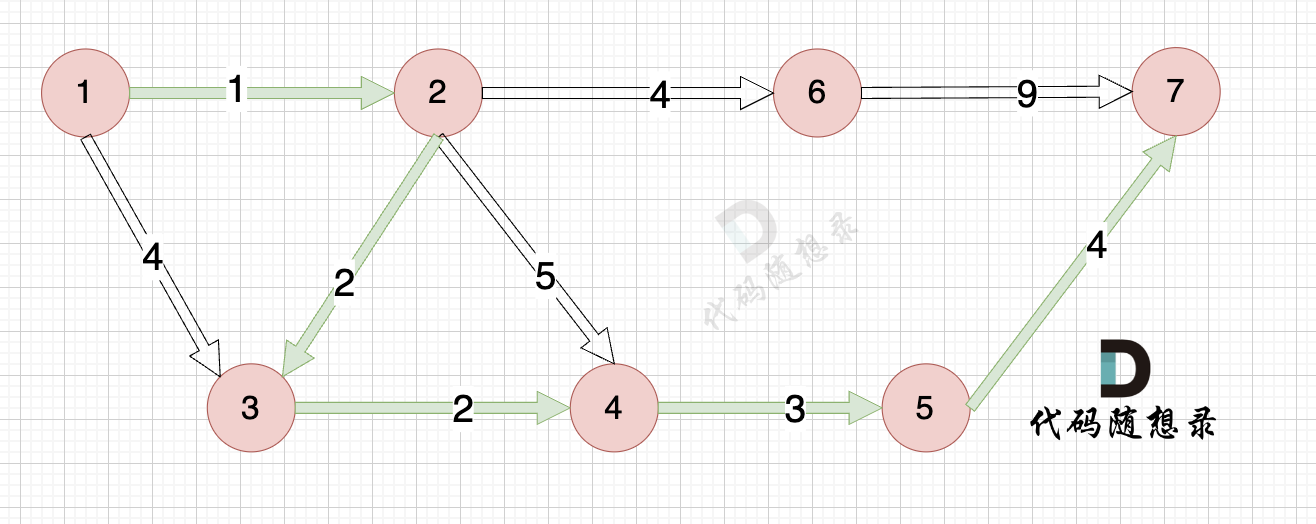
在上面的讲解中,每一步 我都是按照 dijkstra 三部曲来讲解的,理解了这三部曲,代码也就好懂的。
代码实现
本题代码如下:
cpp
#include <iostream>
#include <vector>
#include <climits>
using namespace std;
int main() {
int n, m, p1, p2, val;
cin >> n >> m;
vector<vector<int>> grid(n + 1, vector<int>(n + 1, INT_MAX));
for(int i = 0; i < m; i++){
cin >> p1 >> p2 >> val;
grid[p1][p2] = val;
}
int start = 1;
int end = n;
// 存储从源点到每个节点的最短距离
std::vector<int> minDist(n + 1, INT_MAX);
// 记录顶点是否被访问过
std::vector<bool> visited(n + 1, false);
minDist[start] = 0; // 起始点到自身的距离为0
for (int i = 1; i <= n; i++) { // 遍历所有节点
int minVal = INT_MAX;
int cur = 1;
// 1、选距离源点最近且未访问过的节点
for (int v = 1; v <= n; ++v) {
if (!visited[v] && minDist[v] < minVal) {
minVal = minDist[v];
cur = v;
}
}
visited[cur] = true; // 2、标记该节点已被访问
// 3、第三步,更新非访问节点到源点的距离(即更新minDist数组)
for (int v = 1; v <= n; v++) {
if (!visited[v] && grid[cur][v] != INT_MAX && minDist[cur] + grid[cur][v] < minDist[v]) {
minDist[v] = minDist[cur] + grid[cur][v];
}
}
}
if (minDist[end] == INT_MAX) cout << -1 << endl; // 不能到达终点
else cout << minDist[end] << endl; // 到达终点最短路径
}- 时间复杂度:O(n^2)
- 空间复杂度:O(n^2)
debug方法
写这种题目难免会有各种各样的问题,我们如何发现自己的代码是否有问题呢?
最好的方式就是打日志,本题的话,就是将 minDist 数组打印出来,就可以很明显发现 哪里出问题了。
每次选择节点后,minDist数组的变化是否符合预期 ,是否和我上面讲的逻辑是对应的。
例如本题,如果想debug的话,打印日志可以这样写:
cpp
#include <iostream>
#include <vector>
#include <climits>
using namespace std;
int main() {
int n, m, p1, p2, val;
cin >> n >> m;
vector<vector<int>> grid(n + 1, vector<int>(n + 1, INT_MAX));
for(int i = 0; i < m; i++){
cin >> p1 >> p2 >> val;
grid[p1][p2] = val;
}
int start = 1;
int end = n;
std::vector<int> minDist(n + 1, INT_MAX);
std::vector<bool> visited(n + 1, false);
minDist[start] = 0;
for (int i = 1; i <= n; i++) {
int minVal = INT_MAX;
int cur = 1;
for (int v = 1; v <= n; ++v) {
if (!visited[v] && minDist[v] < minVal) {
minVal = minDist[v];
cur = v;
}
}
visited[cur] = true;
for (int v = 1; v <= n; v++) {
if (!visited[v] && grid[cur][v] != INT_MAX && minDist[cur] + grid[cur][v] < minDist[v]) {
minDist[v] = minDist[cur] + grid[cur][v];
}
}
// 打印日志:
cout << "select:" << cur << endl;
for (int v = 1; v <= n; v++) cout << v << ":" << minDist[v] << " ";
cout << endl << endl;;
}
if (minDist[end] == INT_MAX) cout << -1 << endl;
else cout << minDist[end] << endl;
}打印后的结果:
select:1
1:0 2:1 3:4 4:2147483647 5:2147483647 6:2147483647 7:2147483647
select:2
1:0 2:1 3:3 4:6 5:2147483647 6:5 7:2147483647
select:3
1:0 2:1 3:3 4:5 5:2147483647 6:5 7:2147483647
select:4
1:0 2:1 3:3 4:5 5:8 6:5 7:2147483647
select:6
1:0 2:1 3:3 4:5 5:8 6:5 7:14
select:5
1:0 2:1 3:3 4:5 5:8 6:5 7:12
select:7
1:0 2:1 3:3 4:5 5:8 6:5 7:12打印日志可以和上面我讲解的过程进行对比,每一步的结果是完全对应的。
所以如果大家如果代码有问题,打日志来debug是最好的方法
如何求路径
如果题目要求把最短路的路径打印出来,应该怎么办呢?
打印路径只需要添加 几行代码, 打印路径的代码我都加上的日志,如下:
cpp
#include <iostream>
#include <vector>
#include <climits>
using namespace std;
int main() {
int n, m, p1, p2, val;
cin >> n >> m;
vector<vector<int>> grid(n + 1, vector<int>(n + 1, INT_MAX));
for(int i = 0; i < m; i++){
cin >> p1 >> p2 >> val;
grid[p1][p2] = val;
}
int start = 1;
int end = n;
std::vector<int> minDist(n + 1, INT_MAX);
std::vector<bool> visited(n + 1, false);
minDist[start] = 0;
//加上初始化
vector<int> parent(n + 1, -1);
for (int i = 1; i <= n; i++) {
int minVal = INT_MAX;
int cur = 1;
for (int v = 1; v <= n; ++v) {
if (!visited[v] && minDist[v] < minVal) {
minVal = minDist[v];
cur = v;
}
}
visited[cur] = true;
for (int v = 1; v <= n; v++) {
if (!visited[v] && grid[cur][v] != INT_MAX && minDist[cur] + grid[cur][v] < minDist[v]) {
minDist[v] = minDist[cur] + grid[cur][v];
parent[v] = cur; // 记录边
}
}
}
// 输出最短情况
for (int i = 1; i <= n; i++) {
cout << parent[i] << "->" << i << endl;
}
}打印结果:
-1->1
1->2
2->3
3->4
4->5
2->6
5->7对应如图:
出现负数
如果图中边的权值为负数,dijkstra 还合适吗?
看一下这个图: (有负权值)
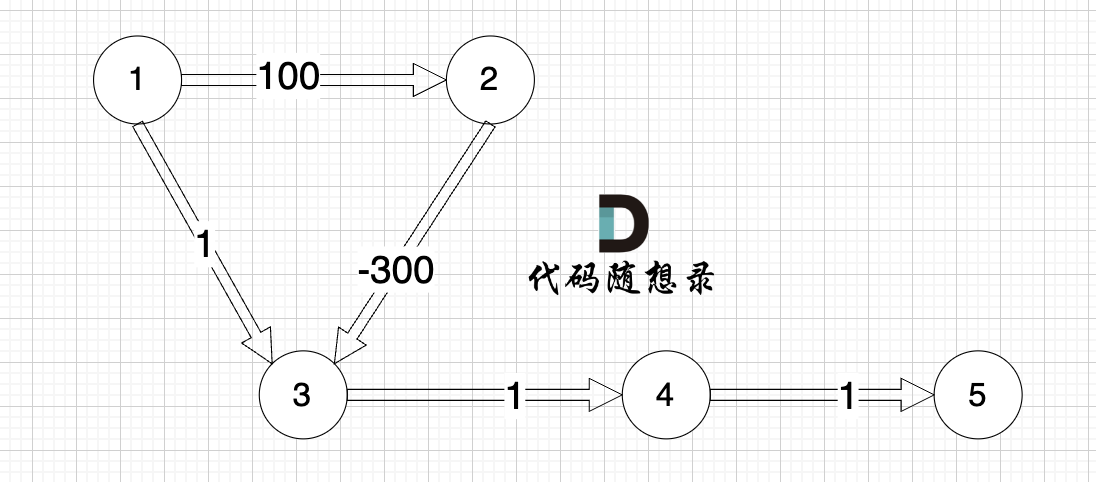
节点1 到 节点5 的最短路径 应该是 节点1 -> 节点2 -> 节点3 -> 节点4 -> 节点5
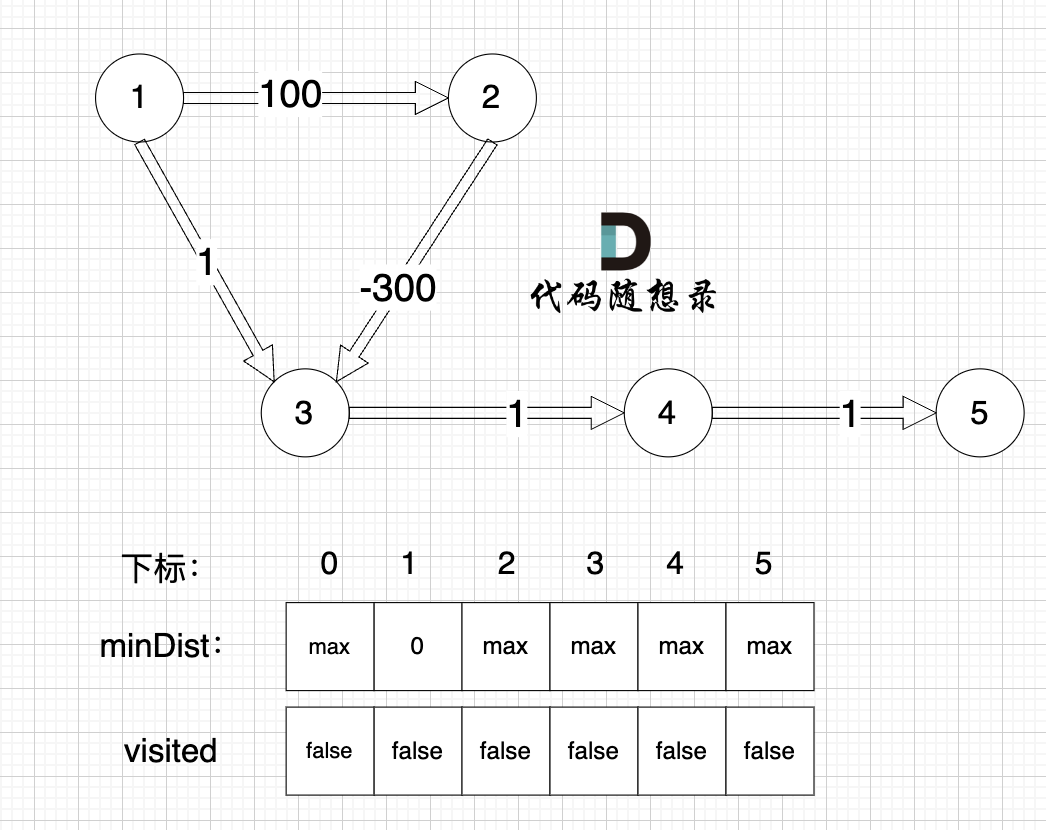
那我们来看dijkstra 求解的路径是什么样的,继续dijkstra 三部曲来模拟 :(dijkstra模拟过程上面已经详细讲过,以下只模拟重要过程,例如如何初始化就省略讲解了)
初始化:
1、选源点到哪个节点近且该节点未被访问过
源点距离源点最近,距离为0,且未被访问。
2、该最近节点被标记访问过
标记源点访问过
3、更新非访问节点到源点的距离(即更新minDist数组) ,如图:
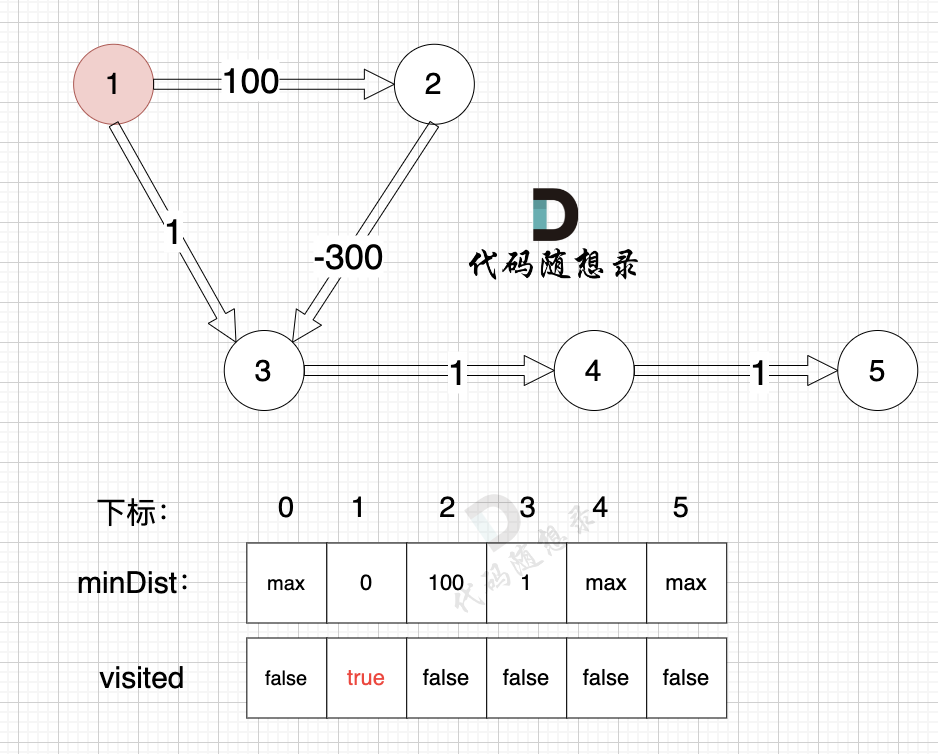
更新 minDist数组,即:源点(节点1) 到 节点2 和 节点3的距离。
- 源点到节点2的最短距离为100,小于原minDist2的数值max,更新minDist2 = 100
- 源点到节点3的最短距离为1,小于原minDist3的数值max,更新minDist4 = 1
1、选源点到哪个节点近且该节点未被访问过
源点距离节点3最近,距离为1,且未被访问。
2、该最近节点被标记访问过
标记节点3访问过
3、更新非访问节点到源点的距离(即更新minDist数组) ,如图:
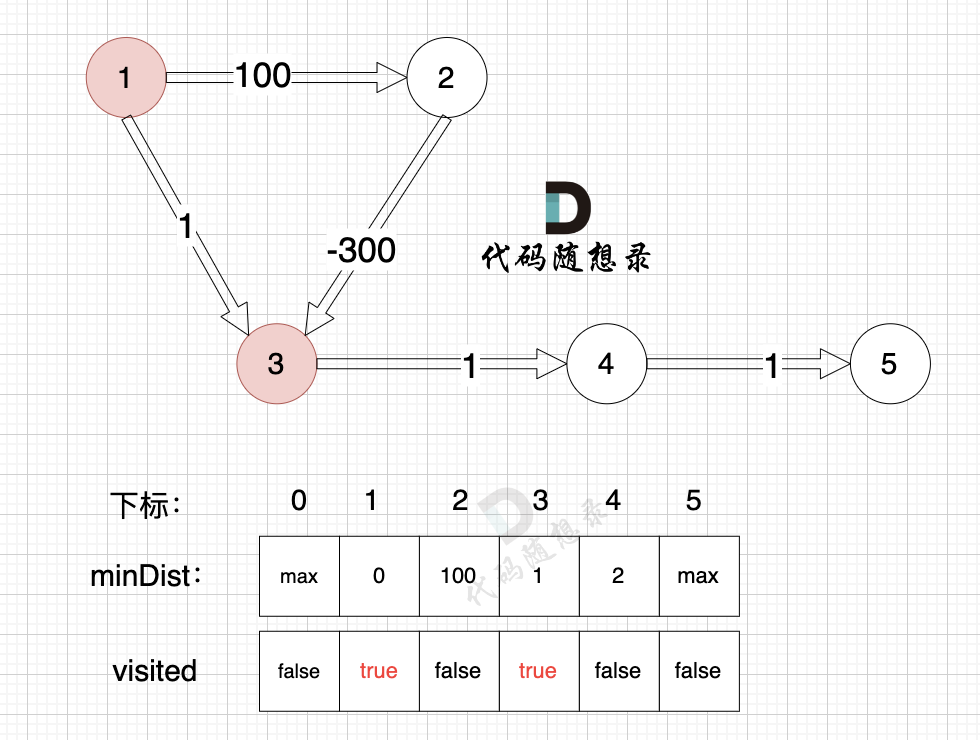
由于节点3的加入,那么源点可以有新的路径链接到节点4 所以更新minDist数组:
- 源点到节点4的最短距离为2,小于原minDist4的数值max,更新minDist4 = 2
1、选源点到哪个节点近且该节点未被访问过
源点距离节点4最近,距离为2,且未被访问。
2、该最近节点被标记访问过
标记节点4访问过
3、更新非访问节点到源点的距离(即更新minDist数组) ,如图:
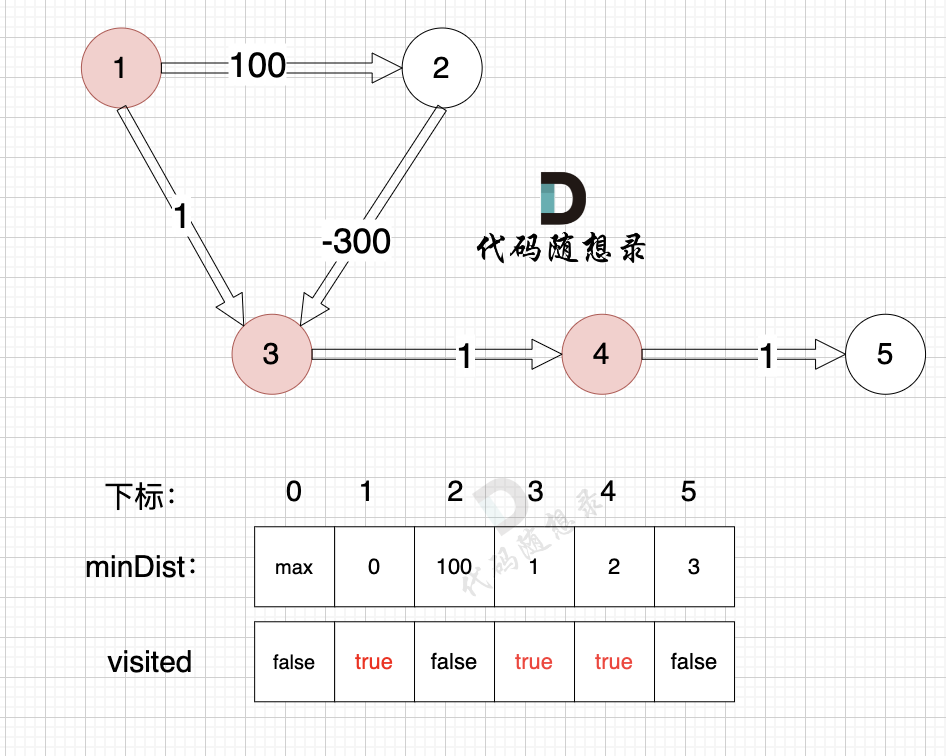
由于节点4的加入,那么源点可以有新的路径链接到节点5 所以更新minDist数组:
- 源点到节点5的最短距离为3,小于原minDist5的数值max,更新minDist5 = 5
1、选源点到哪个节点近且该节点未被访问过
源点距离节点5最近,距离为3,且未被访问。
2、该最近节点被标记访问过
标记节点5访问过
3、更新非访问节点到源点的距离(即更新minDist数组) ,如图:
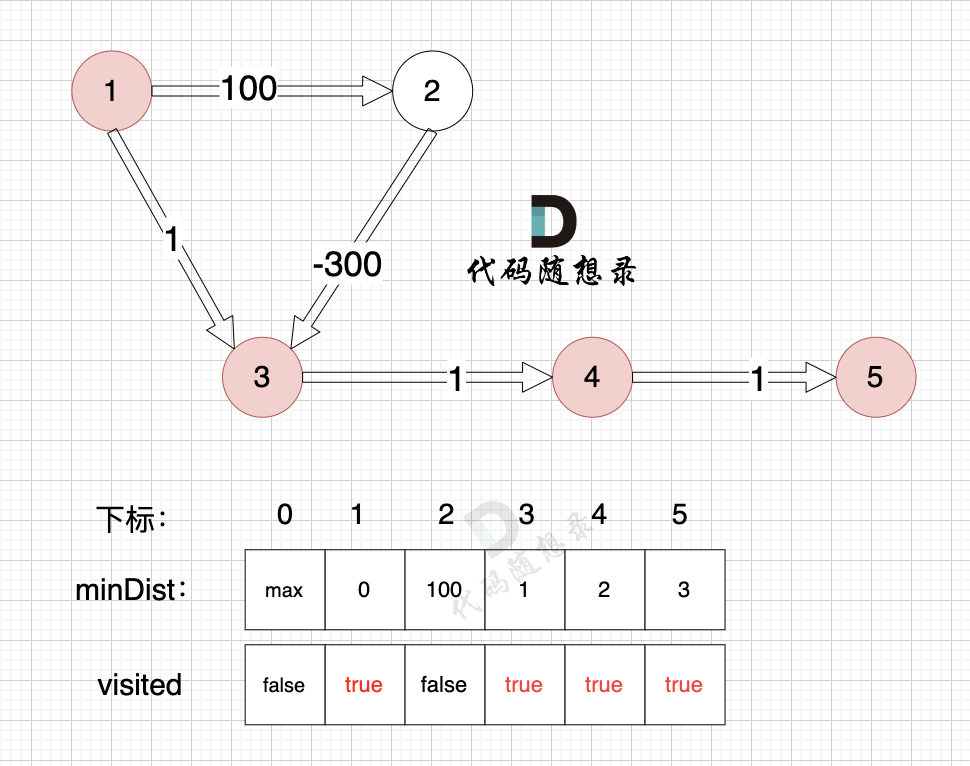
节点5的加入,而节点5 没有链接其他节点, 所以不用更新minDist数组,仅标记节点5被访问过了
1、选源点到哪个节点近且该节点未被访问过
源点距离节点2最近,距离为100,且未被访问。
2、该最近节点被标记访问过
标记节点2访问过
3、更新非访问节点到源点的距离(即更新minDist数组) ,如图:
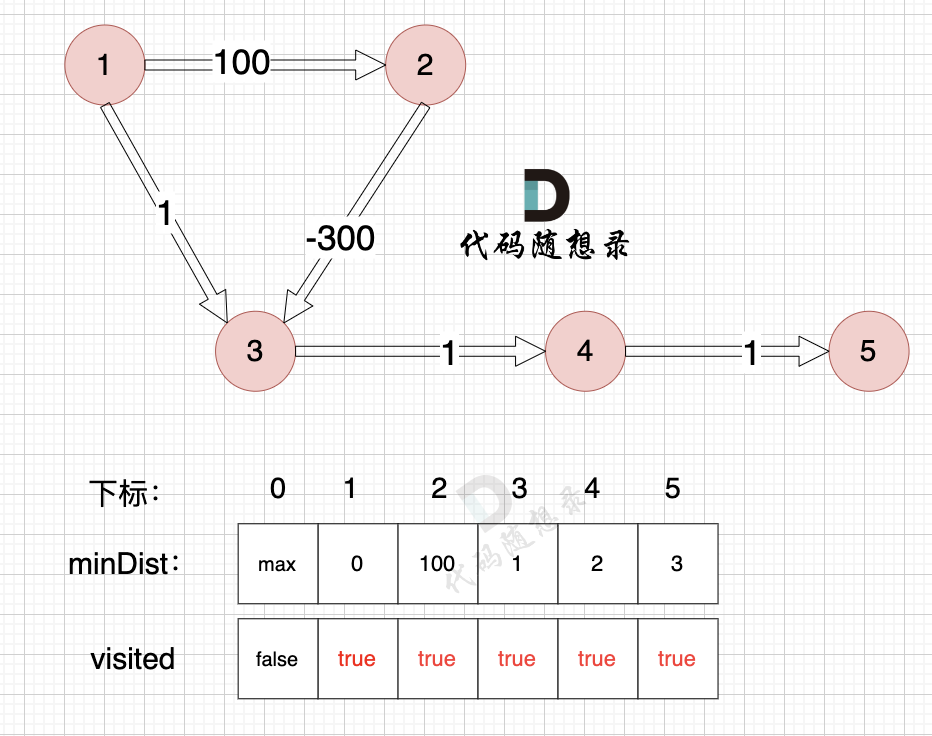
至此dijkstra的模拟过程就结束了,根据最后的minDist数组,我们求 节点1 到 节点5 的最短路径的权值总和为 3,路径: 节点1 -> 节点3 -> 节点4 -> 节点5
通过以上的过程模拟,我们可以发现 之所以 没有走有负权值的最短路径 是因为 在 访问 节点 2 的时候,节点 3 已经访问过了,就不会再更新了。
dijkstra与prim算法的区别
其实代码大体不差,唯一区别在 三部曲中的 第三步: 更新minDist数组
因为prim是求 非访问节点到最小生成树的最小距离,而 dijkstra是求 非访问节点到源点的最小距离。
prim 更新 minDist数组的写法:
cpp
for (int j = 1; j <= v; j++) {
if (!isInTree[j] && grid[cur][j] < minDist[j]) {
minDist[j] = grid[cur][j];
}
}因为 minDist表示 节点到最小生成树的最小距离,所以 新节点cur的加入,只需要 使用 gridcurj ,gridcurj 就表示 cur 加入生成树后,生成树到 节点j 的距离。
dijkstra 更新 minDist数组的写法:
cpp
for (int v = 1; v <= n; v++) {
if (!visited[v] && grid[cur][v] != INT_MAX && minDist[cur] + grid[cur][v] < minDist[v]) {
minDist[v] = minDist[cur] + grid[cur][v];
}
}因为 minDist表示 节点到源点的最小距离,所以 新节点 cur 的加入,需要使用 源点到cur的距离 (minDistcur) + cur 到 节点 v 的距离 (gridcurv),才是 源点到节点v的距离。