
文章链接:https://arxiv.org/pdf/2408.14975
项目链接:https://megactor-ops.github.io/
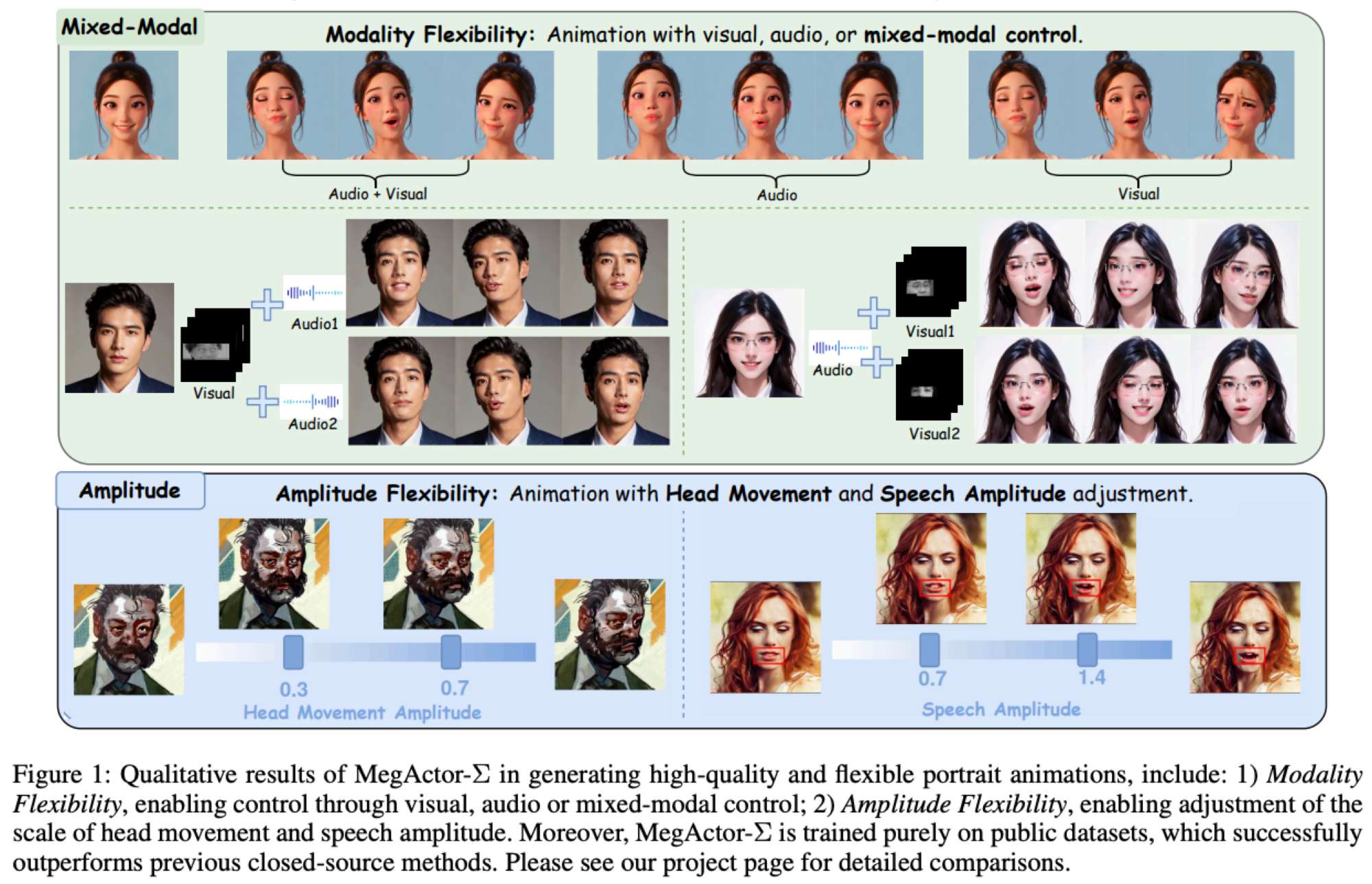
亮点直击
一种新颖的混合模态扩散Transformer(DiT),能够有效整合音频和视觉控制信号。相较于之前基于UNet的方法,这是首个基于DiT框架的人像动画方法。
一种新颖的"模态解耦控制"训练策略,能够解决视觉泄露问题,并有效平衡视觉和音频模态之间的控制强度。
一套用于筛选公共多模态人像动画数据集的质量评估指标,并提供了一个经过筛选的100小时高质量数据集以供开源研究使用。
大量实验表明,本文的方法在生成生动的人像动画方面表现出色,并在应用上提供了更优的灵活性。
扩散模型在人像动画领域表现出色。然而,当前的方法依赖视觉或音频模态来控制角色动作,未能充分利用混合模态控制的潜力。这一挑战源于平衡音频模态控制强度较弱与视觉模态控制强度较强的难度。
为了解决这个问题,本文提出了MegActor-Σ :一种混合模态条件扩散Transformer(DiT),可以灵活地将音频和视觉模态控制信号注入人像动画。具体来说,通过利用DiT的有前途的模型结构,并通过在DiT框架中集成音频和视觉条件的高级模块,在其前身MegActor的基础上做了实质性改进。为了进一步实现混合模态控制信号的灵活组合,本文提出了"模态解耦控制"训练策略,以平衡视觉和音频模态之间的控制强度,并提出了"幅度调整"推理策略,以自由调节每种模态的运动幅度。最后,为了促进该领域的广泛研究,研究者们设计了多个数据集评估指标来筛选公开数据集,并仅使用此筛选后的数据集来训练MegActor-Σ。大量实验表明,本文的方法在生成生动的人像动画方面优于以往使用私有数据集训练的方法。
前身回顾
MegActor : Harness the Power of Raw Video for Vivid Portrait Animation
链接 :https://arxiv.org/pdf/2405.20851
git地址:https://github.com/megvii-research/MegActor
MegActor-Σ方法
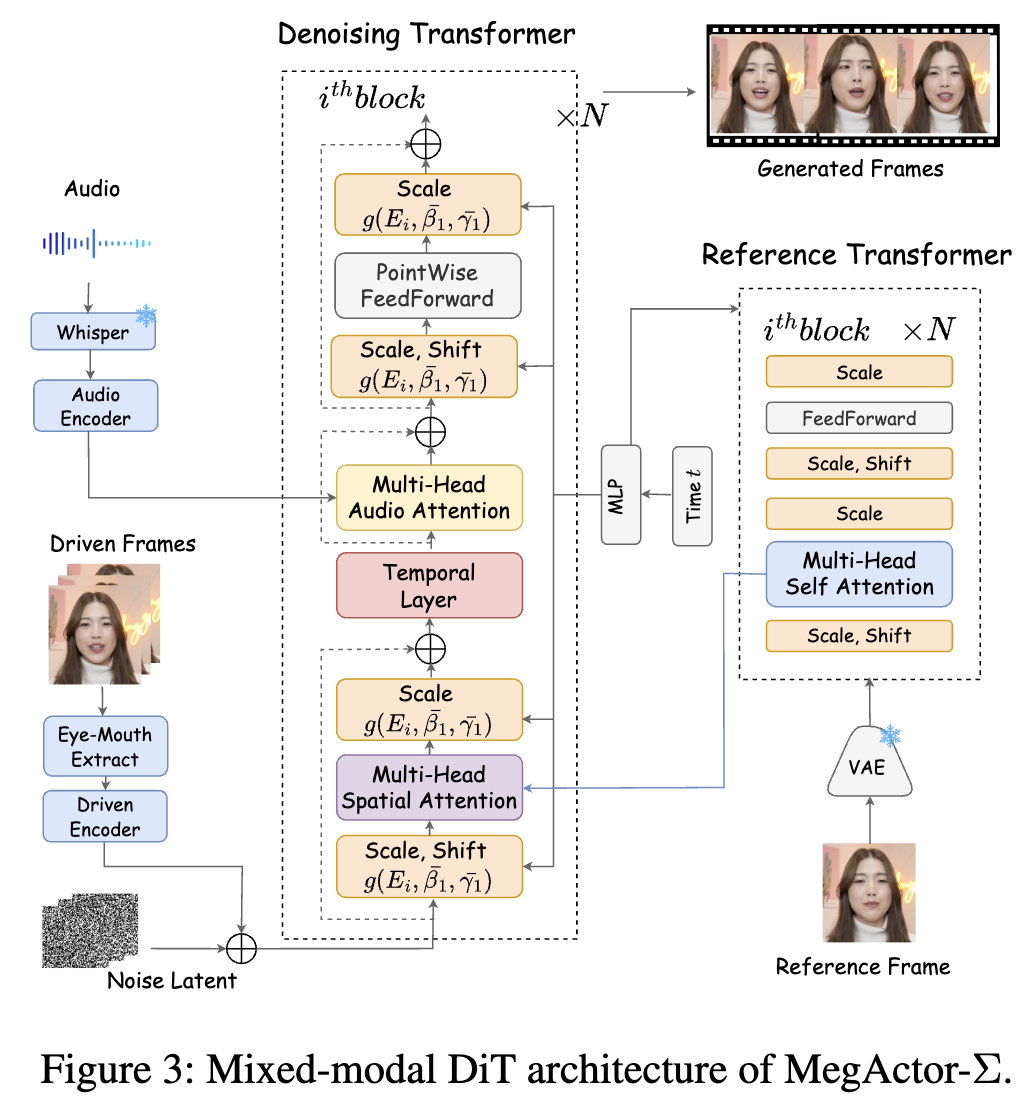
MegActor-Σ的整体框架下图3所示:
-
去噪Transformer:该组件基于PIXART-α架构,旨在灵活地将输入的音频信号与从参考Transformer中提取的视觉特征相结合。
-
参考Transformer:该组件在结构上与去噪Transformer相同,主要负责从参考图像中提取细粒度的身份和背景细节。
MegActor-Σ
Driven Encoder
受到AnimateAnyone的启发,该轻量级Driven Encoder由四个2D卷积层组成,用于从Driving视频中提取运动特征。这些运动特征随后被调整为与随机采样获得的噪声潜变量具有相同的分辨率。运动特征与噪声潜变量沿通道维度进行拼接。在训练过程中,去噪Transformer的卷积输入层(conv-in layer)的参数会被重新初始化,保留前四个通道的参数,将其余通道初始化为零。这一策略有助于在引入运动特征时,减少对最初从PIXART-α初始化的去噪Transformer空间结构的破坏。
-
Whisper 集成:采用Whisper来提取语音音频特征,这些特征通过交叉注意力机制注入到去噪Transformer中。
-
时间模块:为提高生成帧之间的时间一致性,将一个时间模块集成到去噪Transformer中并独立进行微调。
-
模态解耦控制:提出了一种新的训练策略,以平衡占主导地位的视觉模态信号与较弱的音频模态信号。
音频注意力层
去噪Transformer基于PIXART-α设计,其中每个块最初包含一个自注意力层和一个交叉注意力层。将原始的交叉注意力层替换为一个修改版,称为音频注意力层,其特征是隐藏维度不同。音频注意力层处理由 Whisper 编码的音频特征。
时间层
研究表明,在视频生成的文本到图像(T2I)模型中加入额外的时间模块,可以有效捕捉帧之间的时间依赖性,并增强其连续性。这种设计允许将预训练的图像生成能力从基础的T2I模型中转移过来。受到这些研究(Xu et al., 2024a)的启发,在去噪Transformer的每个自注意力层之后集成了一个时间模块,以促进帧之间的时间融合。
训练策略
如下图2所示,在使用混合模态控制信号进行训练时,当应用视觉控制时,通常会忽略音频线索。将此问题归因于视觉泄露,这种现象是由于视觉控制信号的连贯性引起的,在这种情况下,面部每个区域的运动可以根据其他区域进行预测。结果,即使视觉模态中没有与口部控制信号冲突的情况,音频信号也会被掩盖。因此,有效的混合模态控制的关键在于将眼睛控制信号与口部控制信号进行空间解耦。

为了实现MegActor-Σ的混合模态控制信号的灵活组合,提出了"模态解耦控制"训练策略,可分为三个阶段:"空间解耦视觉训练"、"模态解耦混合训练"和"运动先验训练"。
在"空间解耦视觉训练"阶段,使用面部丢弃策略生成空间mask ,随机选择独立的控制信号,例如来自眼睛、嘴巴或两者的信号。然后,将这些空间 mask 应用于控制注意力和损失函数的区域,确保眼睛信号不会影响嘴巴区域。在"模态解耦混合训练"阶段,进一步集成音频模态和混合模态以实现组合控制。具体来说,音频模态排除了视觉控制信号,而混合模态包含音频信号(如音频模态)和仅专注于眼睛区域的视觉信号,确保它不会掩盖由音频控制的嘴巴动作。这种方法使嘴巴的位置与音频模态对齐,简化了嘴型建模的挑战。在"运动先验训练"阶段,冻结视觉和音频模态的注意力参数,仅训练运动模块以实现平滑的时间预测。使用与PIXART-α相同的损失函数训练模型,包括KL损失和MSE损失。有关训练过程的详细信息,请参见下图4。
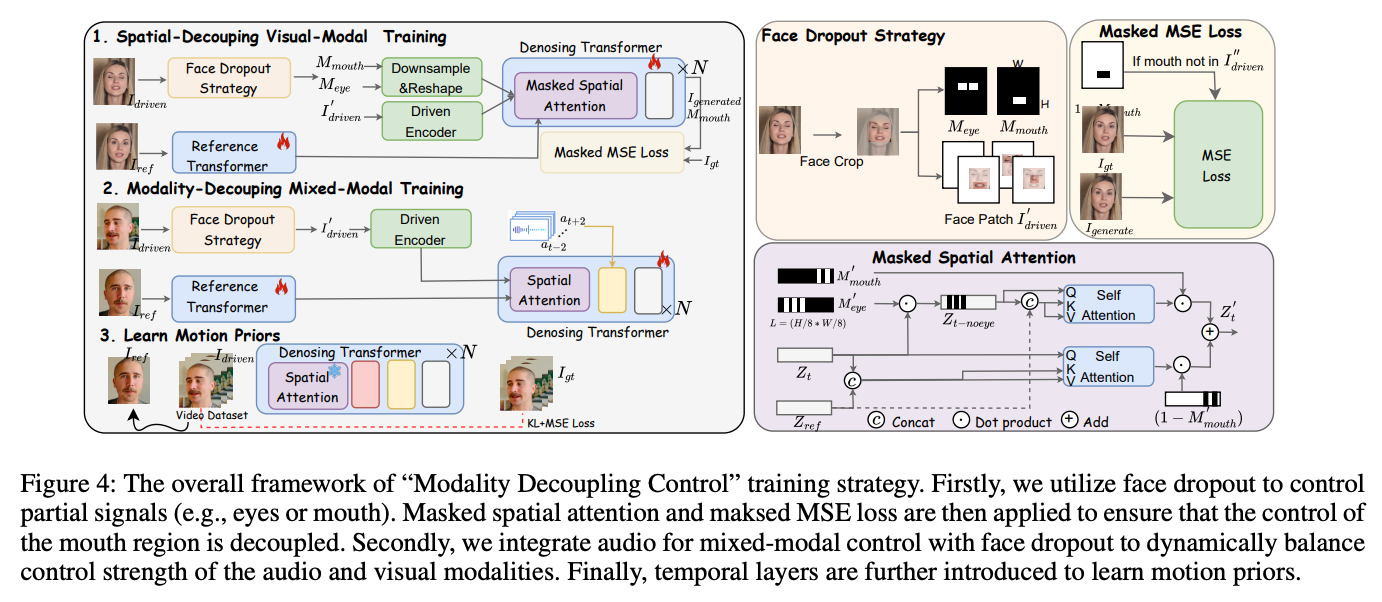
空间解耦视觉训练:对于包含面部运动的视频,随机选择两帧:一帧作为参考图像 ,具有静态人像,另一帧作为预测结果,称为。利用DWPose计算的面部标志。在训练过程中,随机选择用于驱动的区域mask ,这些mask 可以是眼睛和嘴巴区域的任何组合 , 。驱动帧将通过以下公式计算:

在训练的这一阶段,模型从PIXART-α初始化,并且不包括音频注意力层,因此未引入任何音频信息。训练目标是基于驱动图像()和参考图像()重建预测图像()。在训练过程中,在空间注意力机制中引入了一个注意力mask ,该mask 仅在驱动图像中没有嘴部区域时激活。在这种情况下,嘴部区域的embedding不会通过注意力与驱动区域进行交互,而其余区域则与原始注意力机制保持一致。嘴部区域的注意力公式如下:
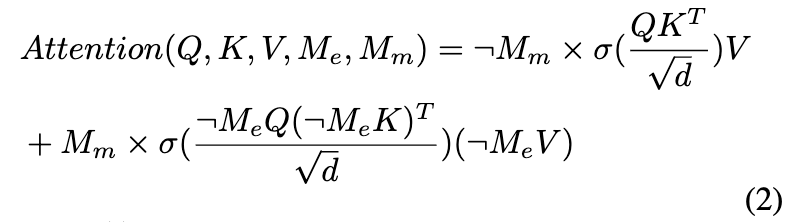
其中,σ(·) 表示 Softmax 函数,¬M 表示mask M 的补集,选择未被原始mask 覆盖的反向区域。我们还引入了一个用于均方误差(MSE)损失的空间mask ,仅计算感兴趣区域的损失。例如,当驱动图像是眼睛区域时,空间注意力中的嘴部令牌的注意力mask 排除了眼睛区域,MSE损失仅计算嘴部之外的区域,如上图4所示。这确保了嘴部区域的生成不会受到眼睛区域的控制。
为了进一步减轻因和之间特定区域内容重叠导致的信息泄露,对应用了人脸交换和风格化。此外,对驱动图像进行数据增强,包括分辨率调整、大小修改和颜色转换。在训练过程中,我们优化了去噪Transformer、参考Transformer和驱动编码器的所有参数。
模态解耦混合训练
在第一阶段训练参数的基础上初始化模型,并在每个Transformer块中加入音频注意力层。使用的音频信号作为音频控制条件,训练目标是基于和音频条件重建。我们训练去噪Transformer、参考Transformer和驱动编码器的所有参数,同时保持Whisper的编码器参数不变。在训练过程中,我们使用10%的视觉模态数据(包括面部丢弃),20%的音频模态数据和70%的混合模态数据。
运动先验训练
我们采用EasyAnimate-V1方法将帧间注意力模块集成到模型中。训练策略与第二阶段相同,唯一的区别在于仅训练新插入的运动模块。
推理策略
视觉控制
对于视觉模态控制,首先根据所有帧的面部标志派生参考图像与驱动视频每一帧之间的变换矩阵。给定第一帧的面部标志和第i帧的,是将投影到的相应变换矩阵。
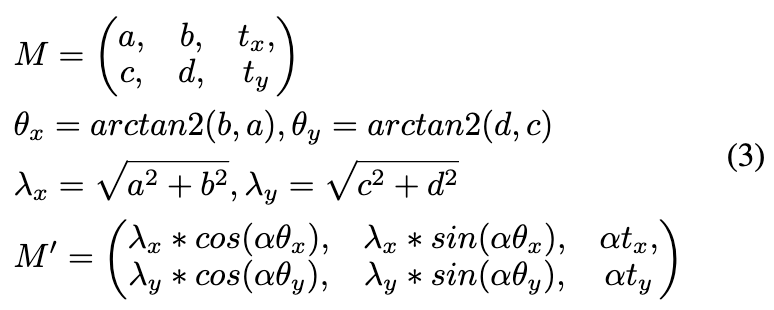
如公式3所示,首先从变换矩阵中提取旋转,然后将旋转和缩放与运动控制因子α一起应用,得到修改后的矩阵。然后使用的逆矩阵将第i帧图像变形回原始图像,得到。加入这个额外步骤,以最佳地保留原始帧的外观。最后,将应用于,得到用于推理的运动缩放帧。这种策略允许对图像模态在不同强度级别下进行精确控制。
音频控制
对于音频模态,音频缩放被用作每个多头音频注意力(MHAA)输出的残差求和中的加权因子,从而调整音频控制的影响。
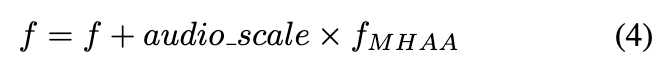
如公式4所述, 是MHAA模块的输入和跳跃特征, 是MHAA模块的输出特征。
公共数据处理
对于扩散模型,数据的质量显著影响模型的效果。然而,当前最先进的人像动画方法依赖于其私有数据集,这限制了社区的可复现性和进一步的研究。我们认为公共数据仍具有很大潜力,因此设计了一系列数据集质量评估指标,并用它们对大规模多模态人像动画数据集进行了广泛筛选。最终,基于我们筛选后的高质量公共数据集训练的模型优于那些在私有数据上训练的模型。
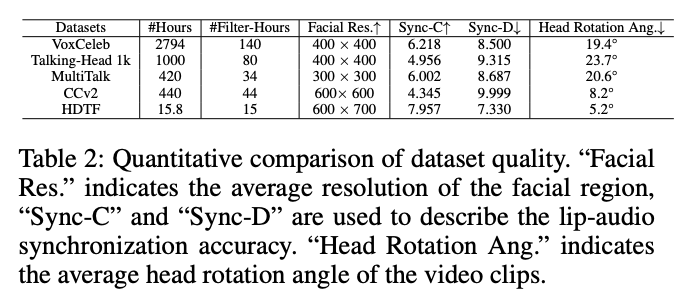
具体来说,我们利用了五个大规模的多模态公共数据集,这些数据集总共包含4670小时的原始视频素材。经过数据筛选,我们保留了313小时的素材。评估指标包括有效面部分辨率、唇音同步和头部旋转角度,具体设计如下:
-
有效面部分辨率:生成数据集的质量高度依赖于高分辨率的面部视频数据集。如果面部在高分辨率视频中的帧中仅占小部分,则裁剪后的面部图像分辨率仍然较低。因此,我们使用DW-Pose计算面部边界框及其大小,要求检测到的面部分辨率必须大于600 × 600。
-
唇音同步准确性:对于音频控制,音频与唇部运动之间的精确对齐直接影响音频对嘴部区域运动的控制。因此,我们使用SyncNet计算Sync-C和Sync-D,这些是音频唇部同步准确性的度量指标。较高的Sync-C值和较低的Sync-D值表示更好的同步效果。我们要求视频的Sync-C值大于6,Sync-D值小于8.5。
-
头部旋转角度:头部旋转角度的比例直接影响训练人像动画方法的难度。虽然较大的头部旋转角度有助于数据集的多样化,但较高比例的数据会显著增加训练复杂性。因此,我们根据地标计算视频片段的头部旋转角度,如果平均角度超过30度,则排除该视频。
我们计算了数据集在这些指标上的平均性能,突出了不同数据集之间的关注点和质量差异。最终,我们保留了6.7%的公共数据用于训练,如下表2所示。
实验结果
实施细节
实验在8个NVIDIA V100 GPU上进行,包括训练和推理阶段。每个训练阶段包括30,000步,视频分辨率设为512 × 512,学习率为1e-5。去噪Transformer由28个基本Transformer块组成。为了降低计算复杂性和参数数量,我们仅在最后16个块中将参考Transformer的空间特征注入到去噪Transformer中。在编号为0至27的基本Transformer块中,我们仅在那些奇数索引的块中插入了时间模块。
实验设置
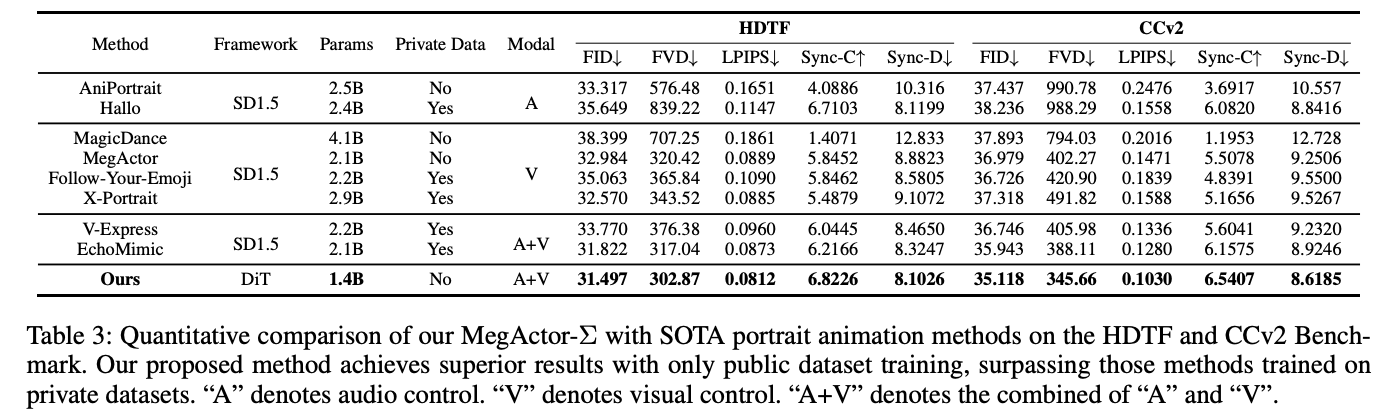
评估指标:人像动画方法的评估指标包括Fréchet Inception Distance (FID)、Fréchet Video Distance (FVD)、Learned Perceptual Image Patch Similarity (LPIPS)、Synchronization-C (Sync-C)和Synchronization-D (Sync-D)。FID、FVD和LPIPS衡量生成图像与真实数据之间的相似性,值越低表示性能越优越,输出越真实。Sync-C和Sync-D评估生成视频中的唇部同步,从内容和动态角度进行评估。
基线方法:在定量实验中,将本文的方法与公开实现的音频驱动方法、AniPortrait、SadTalker 、图像驱动方法、Follow Your Emoji 、MagicDance以及多模态驱动方法、EchoMimic进行比较。评估在HDTF数据集和CCv2数据集上进行。为了确保评估的严格性,身份数据按照标准9:1的比例进行划分,90%用于训练阶段。
评估与比较
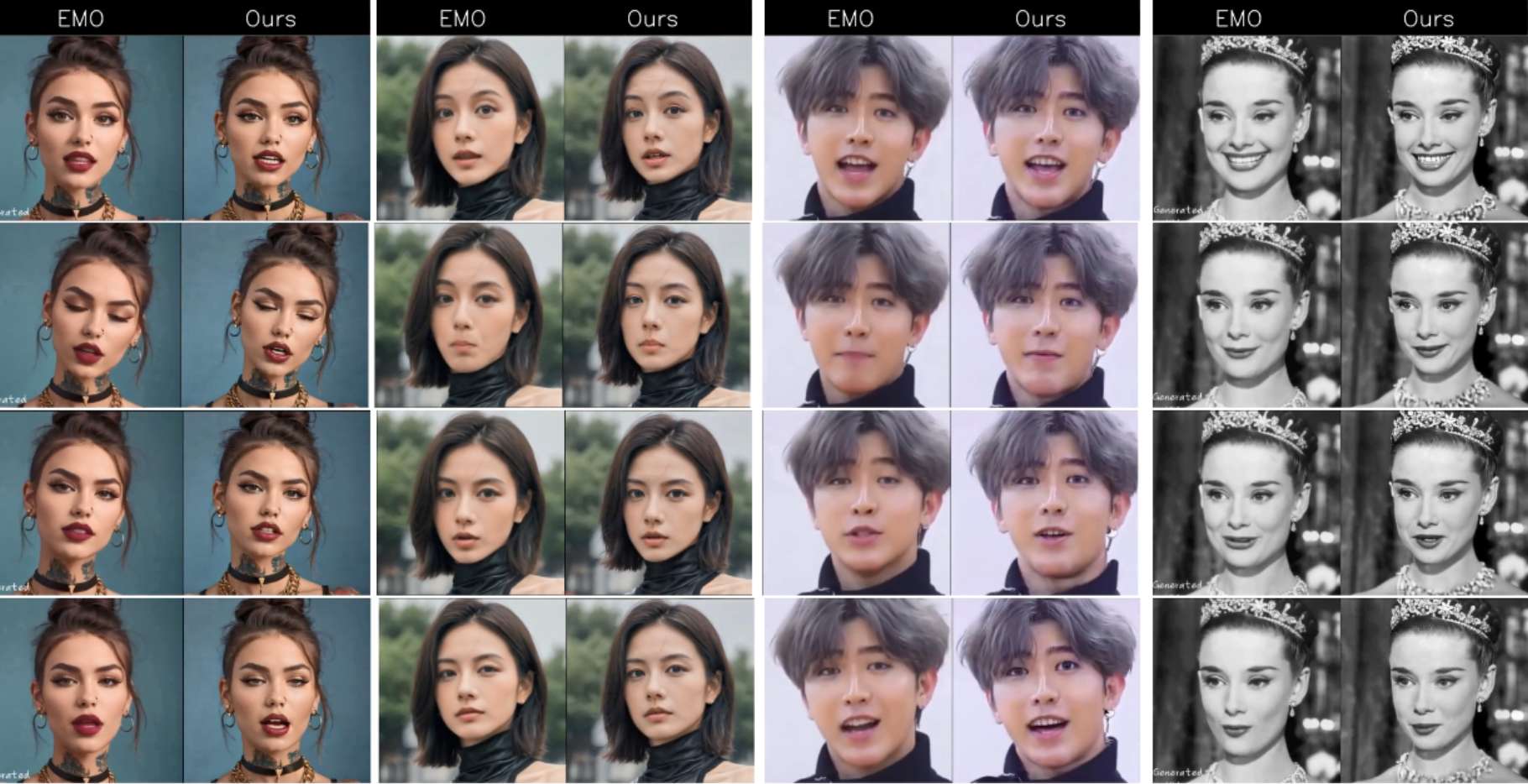
下表3展示了在HDTF和CCv2基准测试中对各种人像动画方法的全面定量评估。我们提出的方法在多个指标上表现出色,使用公共数据集进行训练,优于那些在私有数据上训练的方法。下图5展示了音频驱动的方法在头部运动、眼睛凝视等方面难以保持一致。图像模态和多模态方法(如MagicDance、Follow Your Emoji、V-Express和EchoMimic)在身份相似性上遇到问题,如最后一列蒙娜丽莎生成结果所示。提出的MegActor-Σ将原始图像控制的准确性和保真度与音频模态的自然平滑性相结合,取得了最优的结果。

消融研究
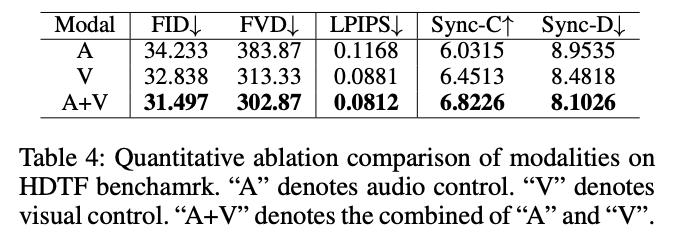
多模态控制信号:下表4展示了在HDTF数据集上测试的单模态和多模态控制结果。研究发现,音频控制方法(A)施加的约束最弱,导致与原始视频存在较大差异,但它仍然实现了较高的唇部同步。使用音频和图像帧(A+V)的方法受到原始图像帧和音频的约束,生成的视频与原始视频最为相似,并且唇部同步性最高,因此取得了最佳结果。
结论
MegActor-Σ:一种混合模态条件扩散Transformer(DiT),旨在充分发挥多样化混合模态控制在人像动画中的潜力。通过解决音频和视觉模态控制强度平衡的问题,本文的方法引入了"模态解耦控制"训练策略和"幅度调整"推理策略,实现了更加灵活和细致的控制。为了进一步促进该领域的广泛研究,我们设计了多个数据集评估指标来筛选公共数据集,并仅使用这些筛选后的数据集来训练MegActor-Σ。广泛的实验结果表明,本文的方法在生成生动的人像动画方面优于以往的闭源方法。希望这项工作能激发开源社区的兴趣。
参考文献
1 MegActor-Σ: Unlocking Flexible Mixed-Modal Control in Portrait Animation with Diffusion Transformer
实习生tips:If you're seeking an internship and are interested in our work, please send your resume to wujuhao@megvii.com or lihuadong@megvii.com.
更多精彩内容,请关注公众号:AI生成未来
