目录
1、grep命令------查找文件
基本格式
grep 选项... 查找条件 目标文件
常用选项
|----|------------------------------------------------|
| 选项 | 说明 |
| -m | 匹配n次后停 |
| -v | 显示不被pattern匹配到的行,即取反 |
| -i | 忽略字符大小写 #可有可无 |
| -n | 显示匹配的行号 |
| -c | 统计匹配的行数 |
| -o | 仅显示匹配到的字符串 |
| -q | 静默模式,不输出任何信息 |
| -A | after, 后n行 |
| -B | before, 前n行 |
| -C | context, 前后各n行 |
| -e | 实现多个选项间的逻辑or关系,如:grep --e 'cat ' -e 'dog' file |
| -W | 匹配整个单词 |
| -E | 使用ERE,相当于egrep,使用扩展正则 |
| -F | 不支持正则表达式 |
| -f | file 根据模式文件,处理两个文件相同内容 把第一个文件作为匹配条件 |
| -r | 递归目录,但不处理软链接 |
| -R | 递归目录,但处理软链接 |
示列
-m
grep -m 1 root /etc/passwd #多个匹配只取第一个
-v
grep -Ev '^\[:space:]*#|^$' /etc/fstab
-c
grep -c root /etc/passwd #统计匹配到的行数
-A
grep -A3 root /etc/passwd #匹配到的行的后3行也显示出来
-e
grep -e root -e bash /etc/passwd #包含root或者包含bash 的行
-w
grep -w root /etc/passwd
-f
root@localhost opt# grep -f 123.txt 456.txt #匹配两个文件中内容相同的部分
a
b
c
ee
-r
root@localhost opt# grep -r a /opt #递归过滤目录中的文件
匹配到二进制文件 /opt/.yonghu.sh.swp
/opt/123.txt:a
/opt/456.txt:a
-R
root@localhost opt# ln -s 123.txt b
root@localhost opt# grep -R a /opt
匹配到二进制文件 /opt/.yonghu.sh.swp
/opt/123.txt:a
/opt/456.txt:a
/opt/b:a
root@test1 opt# cat 123.txt |grep -v '^$' >test.txt //将非空行写入到test.txt文件
root@test1 opt# grep "^b" 123.txt //过滤已b开头
root@test1 opt#grep '/$' 123.txt //过滤已/结尾
2、sort命令-------排序
以行位单位对文件内容进行排序,也可以根据不同的数据类型进行排序
语法格式
sort 选项 参数
cat file | sort 选项
常用选项
|------------|------------------------|
| 选项 | 说明 |
| -f | 忽略大小写,默认会大写字母排在前面 |
| -b | 忽略每行前面的空格 |
| -n | 按照数字进行排序 |
| -r | 反向排序 |
| -u | 等同uniq,表示相同的数据仅显示一行,去重 |
| -t | 指定字段分隔符,默认使用tab键分隔 |
| -k | 指定排序字段 |
| -o<输出文件> | 将排序后的结果转存至指定文件 |
示列
-f

-n
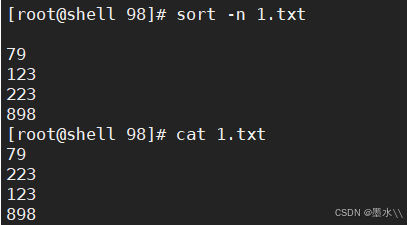
-nr
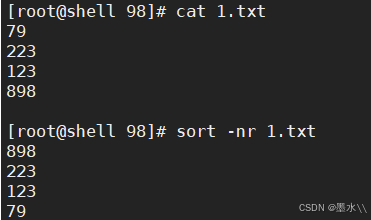
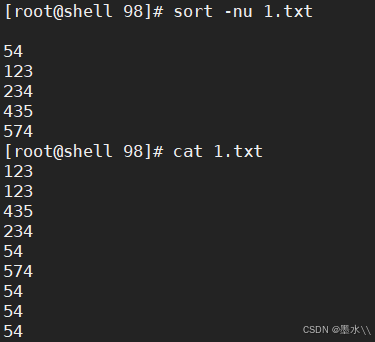
-nu
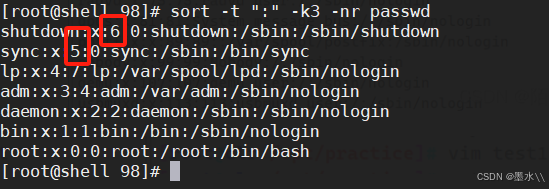
-t -k
-o

3、uniq命令------快捷去重
uniq命令用于报告或者忽略文件中连续的重复行,常与sort命令结合使用。
基本格式
uniq 选项 参数
常用选项
|----|----------------------|
| 选项 | 说明 |
| -c | 统计连续重复的行的次数,并且合并重复的行 |
| -u | 显示仅出现一次的行(包括不连续的重复行) |
| -d | 仅显示重复出现的行(必须是连续的重复行) |
-c
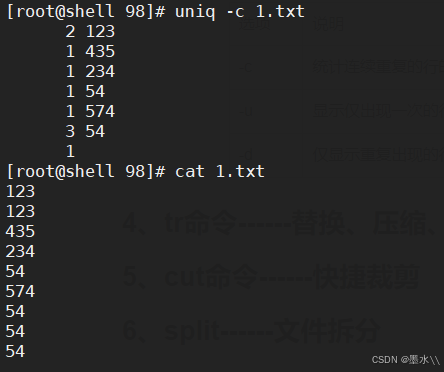
-u
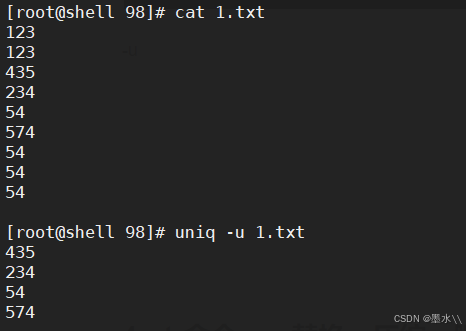
-d
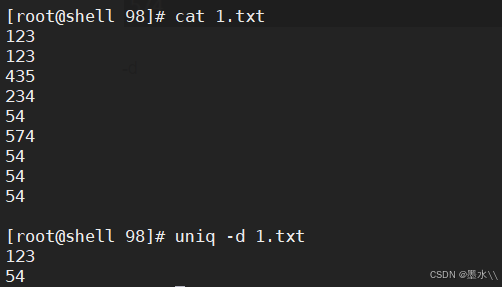
4、tr命令------替换、压缩、删除
常用于对来自标准输入的字符进行替换、压缩和删除
语法格式
tr 选项 参数
常用选项
|----|----------------------------------|
| 选项 | 说明 |
| -c | 保留字符集1的字符,其他的字符(包括换行符\n)用字符集2替换 |
| -d | 删除所有属于字符集1的字符 |
| -s | 将重复出现的字符串压缩为一个字符串,用字符集2 替换 字符集1 |
| -t | 字符集2 替换 字符集1,不加也行 |
字符集1:
指定要转换或删除的原字符集。
必须使用参数"字符集2"指定转换操作时,必须使用参数"字符集2"指定转换的目标字符集。
但执行删除操作时,不需要参数"字符集2"
字符集2:
指定要转换成的目标字符集
示列
-c -d

-t

-s
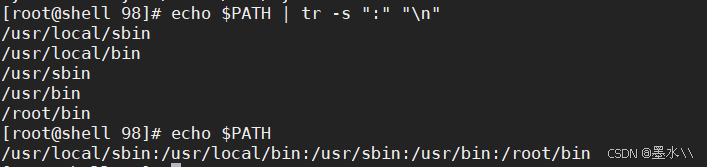
5、cut命令------快捷裁剪
格式
格式一:cut 选项 参数
格式二:cat file | cut 选项
常用选项
|--------------------|------------------|
| 选项 | 说明 |
| -f | 指定分隔符(默认分隔符为Tab) |
| -b | 按字段进行截取。指定第n个字段; |
| -c | 以字节为单位进行截取 |
| -d | 以字符为单位进行截取 |
| -complement | 排除所指定的字段 |
| --output-delimiter | 更改输出内容的分隔符 |
示列
cut -d ':' -f 1-3 passwd #已":"作为分隔符,指定第一个到第三个字段进行输出
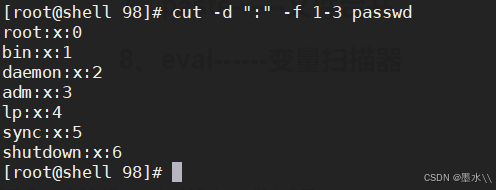
cut -d ':' --complement -f 2 passwd #指定已":"作为分隔符,但是删除了第二个字段进行输出
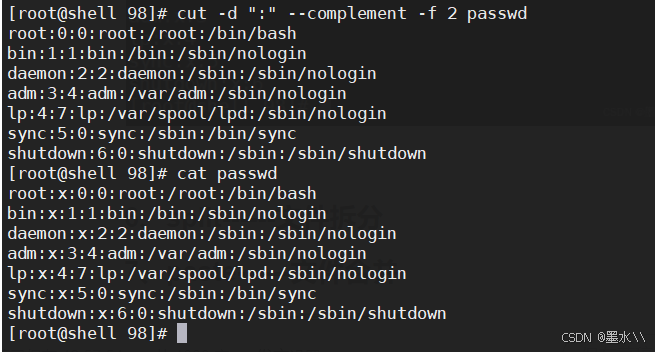
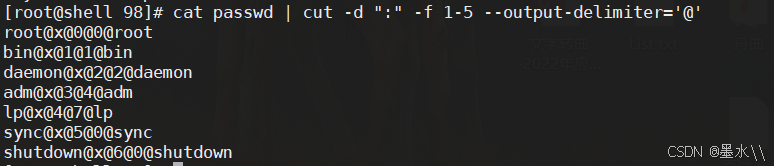
cat passwd | cut -d ':' -f 1-5 --output-delimiter='@' passwd #将分隔符转换为@,进行输出
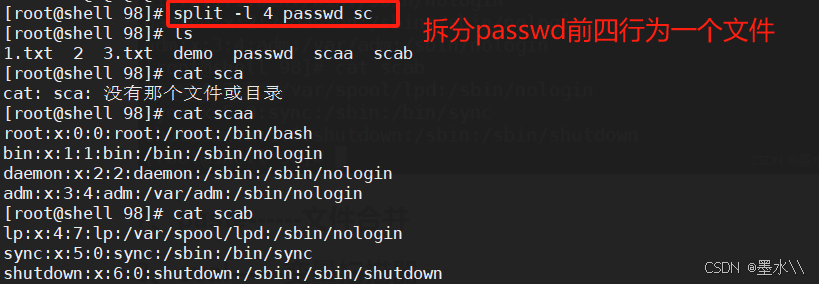
6、split------文件拆分
split命令用于在Linux下将大文件拆分为若干小文件。
格式
split 选项 参数 原始文件 拆分后文件名前缀
常用选项
|----|---------|
| 选项 | 说明 |
| -l | 指定行数 |
| -b | 指定文件的大小 |
示列
-l
7、paste------文件合并
按照字段来进行文件的合并
格式
paste 选项 文件1 文件2
常用选项
|----|----------------------------|
| 选项 | 说明 |
| -d | 用于指定文件的分隔符(默认情况下为制表符"\n") |
| -s | 将列和行的内容进行互相交换 |
8、eval------变量扫描器
命令字前加上eval,shell会在执行命令之前扫描它两次,
eval命令首先会先扫描命令行进行所有的置换,然后再执行命令,
该命令适用于那些一次扫描无法实现功能的变量,该命令会对变量进行两次扫描。
脚本示列
#!/bin/bash
#这是一个验证eval扫描的脚本
a=100
b=a
echo "普通echo输出的变量b的值为:" $$b
eval echo "经过eval扫描输出变量b的值为:" $$b综合示列:
统计当前主机的连接状态
[root@localhost ~]# ss -nta | grep -v '^State' |cut -d " " -f 1| sort | uniq -c
3 ESTAB #表示建立的 TCP 连接处于活动状态
17 LISTEN统计当前连接主机数
[root@localhost opt]# ss -nt | tr -s " "|cut -d " " -f 5 | sort -n | uniq -c
1 Local
2 192.168.233.21:22