相关文档:
https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Guide/Regular_expressions
文档里面已经写的很详细了,这篇主要是根据用法做一些代码练习
创建正则表达式
字面量创建正则表达式:
通过/ / 关键字创建正则表达式, /与/之间的部分即为正则表达式的字面量,对于字面量来说,表达式本身即为正则表达式,一般不需要额外的转义。
javascript
let e = /abc/构造函数创建正则表达式:
调用RegExp对象构造函数创建正则表达式,需要注意,这时候传入的参数 是字符串形式,而非正则表达式字面量。为了构造函数接收字符串之后,能将其正确处理为字面量含义,需要进行字符串和字面量之间的转义。
javascript
let e = new RegExp('c:\\\\')转义:转义通过 \ 来进行,
一般来说,对于正则表达式中具有特殊含义的字符,如果我们不想使用它的特殊含义,而是单纯需要一个字符,都需要进行转义,
特殊含义是指,比如,如果\后面跟了某个字母,这通常是表示固定的特殊字符,比如\n表示换行。而()在正则式中通常表示一个捕获组。+在正则表达式中表示字符可以匹配一个或者多个。但是,如果我想在正则表达式中匹配字符"\",字符"(",字符"+",而不是用其表示某种特殊的含义,如何区分匹配的是字符还是特殊含义呢?答案就是使用'\'进行转义。
在特殊字符之前加'\',表示匹配的是单纯的字符串,而不是将其视为特殊字符。
比如上面的'c:\\\\'字符串,其与字面量'c:\\'相同
特殊字符表:
正则表达式匹配(应用场景)
定义了正则表达式之后,如何将其应用在某个具体的字符串之上?
通过RegExp(正则表达式)的exec和test方法、
通过String(字符串)的match、matchAll、replace、search、split进行正则表达式调用。
具体的匹配练习之后会单开一个博客练习。
RegExp的test方法:
使用正则表达式.test(匹配字符串)来进行匹配验证,如果匹配成功,则返回true,否则返回false。
javascript
console.log(/abc/.test('ab'))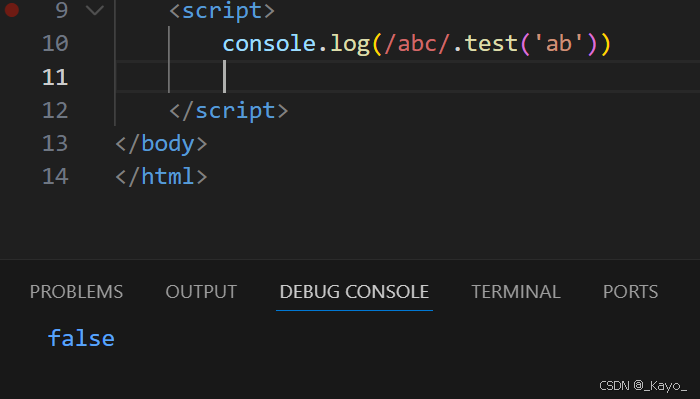
javascript
let e = new RegExp('c:\\\\')
console.log( e.test('c:\\') )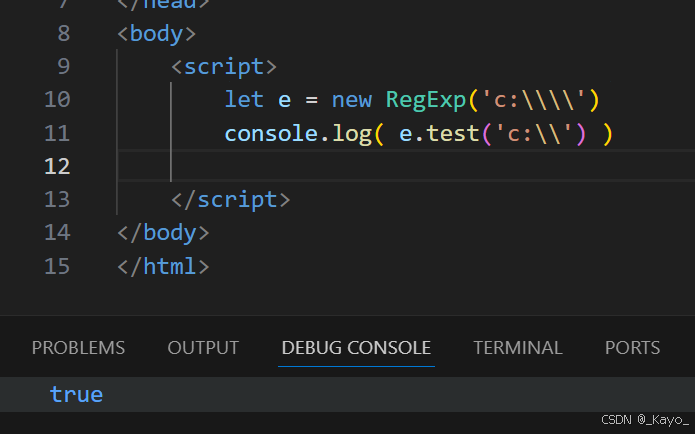
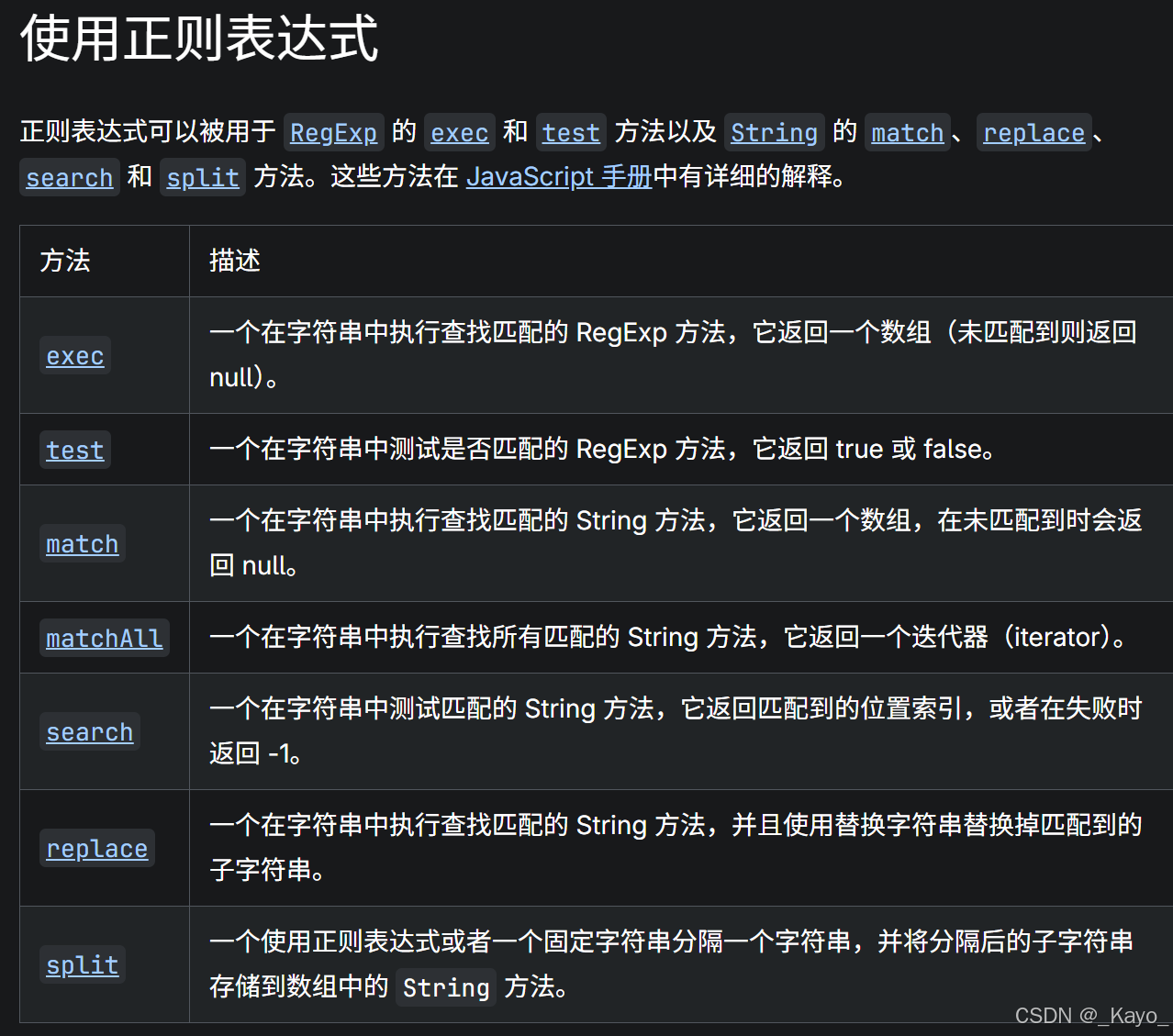
匹配规则
这部分主要是学习正则表达式的规则。
一般特殊字符
\
\ 一般\后面接字母,表示某种特殊含义。
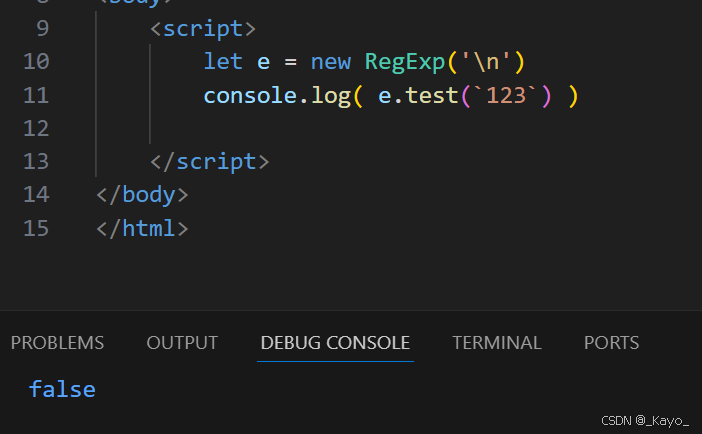
javascript
let e = new RegExp('\n')
console.log( e.test(`
`) )表示匹配换行符
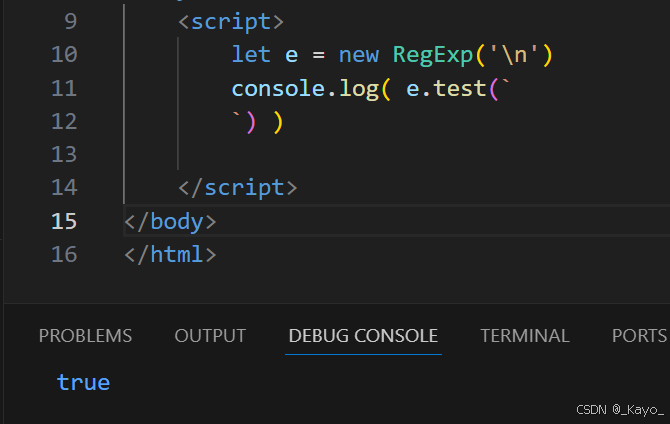
\x 特殊字符规则:
^
^ 表示以匹配内容开头
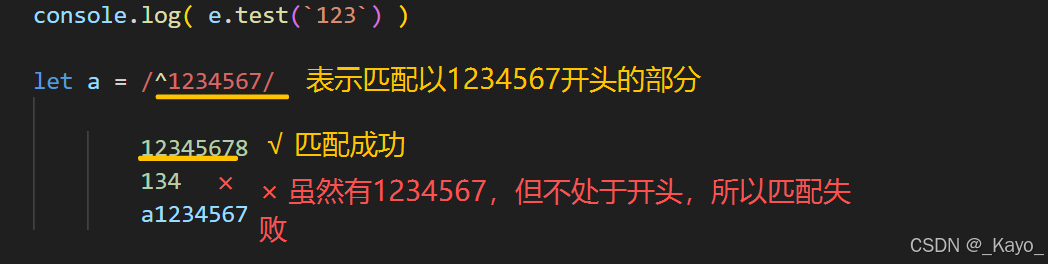
javascript
let a = /^123/
console.log( a.test('12346')) //true
console.log( a.test(' 12346')) //false
console.log( a.test('123467')) //true
console.log( a.test('abc12346')) //false
console.log( a.test('12')) //false
console.log( a.test('abcd')) //false$
$ 表示以匹配内容结束

javascript
let a = /123$/
console.log( a.test('1234')) //false
console.log( a.test(' 123')) //true
console.log( a.test('12')) //false
console.log( a.test('abc')) //false
console.log( a.test('12341234')) //false{n,m}及衍生格式
其实n和m都是整数
{n}
表示{n}前面的字符刚好出现了n次。
{n,}
表示{n,}前面的字符至少出现了n次。
{n,m}
表示{n,m}前面的字符出现次数至少为n,至多为m。
*
* 相当于{0,} 表示匹配内容出现0次或多次,*和{0,}是对前面的单个字符或者捕获组进行限制

javascript
let a = /123*/
let b = /123{0,}/
console.log( a.test('1234')) //true
console.log( a.test(' 123333333')) //true
console.log( a.test('12')) //true
console.log( a.test('abc')) //false
console.log( a.test('123341234')) //true+
- 相当于{1,},表示匹配内容出现1次或者多次

?
?相当于{0,1},表示匹配内容出现0次或者1次

.
. 匹配除了换行符之外的任何单个字符
javascript
let a = /123.4/
console.log( a.test('1234')) //flase
console.log( a.test(' 12334')) //true
console.log( a.test('123\\n5')) //false
console.log( a.test('123\\n4')) //false
console.log( a.test('123\n4')) //false
console.log( a.test('123\n5')) //false|
用 | 表示或。
|之间包裹的部分自动成为一组,x|y,表示x或y
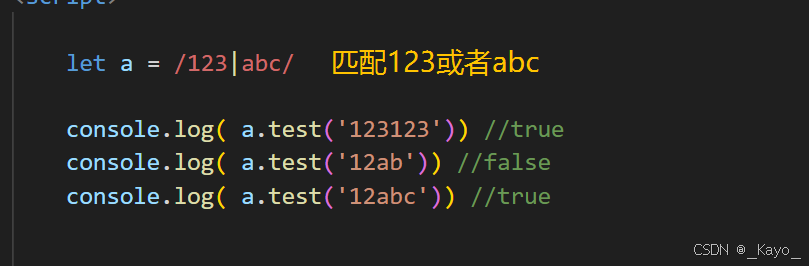
javascript
let a = /123|abc/
console.log( a.test('123123')) //true
console.log( a.test('12ab')) //false
console.log( a.test('12abc')) //true-
表示范围。对于数字、字母等可以用0-9表示0到9之间,用a-z表示a到z之间。
这种形式需要和下面的\[\]配套使用,单独的0-9会被视为普通字符串匹配,没有特殊含义。
javascript
let a = /0-9/
console.log( a.test('0')) //false
console.log( a.test('0-9')) //true\[\]及其衍生格式
...
表示匹配\[\]字符集合中的任意一个字符即算匹配成功
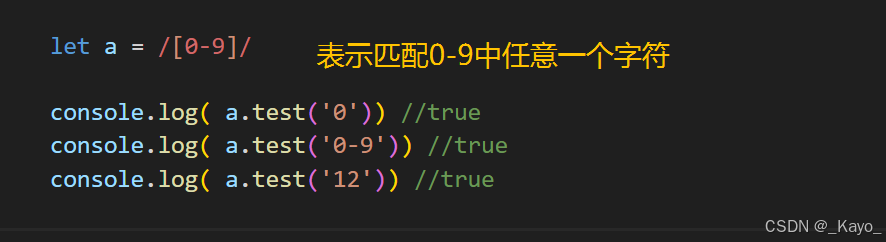
javascript
let a = /[0-9]/
console.log( a.test('0')) //true
console.log( a.test('0-9')) //true
console.log( a.test('12')) //true\^...
表示一个反向字符集,也就是说,匹配\[\]中不包含的任意一个字符。
比如,匹配非数字:
javascript
let a = /[^0-9]/
console.log( a.test('0')) //false
console.log( a.test('0-9')) //true
console.log( a.test('12')) //false\\b
表示匹配退格
\b 字符边界
对于\x组成的特殊含义,这里只记录\b和\B,其他用法可以看文档了解。
\b表示匹配一个词的边界,\b可以用在字符前面,也可以用在字符后面,\b用在字符最前面时,表示匹配以\b后面接的内容开头的内容;\b在字符最后面时,表示匹配以\b前面接的内容结尾的字符。
javascript
let a = /\babc/
console.log( a.test('abcde')) //true
console.log( a.test('123abc')) //false
console.log( a.test('12a')) //false对于\\babc的模式,它表示匹配a或b或c或单词边界,在这个例子中,\[\]可以解析\b为转义字符,但是由于\b包裹在\[\]中,它会被理解为或者的情况的其中之一,实际上,这个\b并没有生效,最终的含义还是匹配a或者b或者c:
javascript
let a = /[\babc]/
console.log( a.test('abcde')) //true
console.log( a.test('123abc')) //true
console.log( a.test('12a')) //true
console.log( a.test('1')) //false注意,\b不能用在一个匹配模式的中间,如果出现在中间,这种规则无法匹配任何字符串。
javascript
let a = /a\babc/
console.log( a.test('abcde')) //false
console.log( a.test('123abc')) //false
console.log( a.test('12a')) //false
console.log( a.test('1a1')) //false但是这种说法也不绝对,在\[\]中\b在中间的情况是无效的:
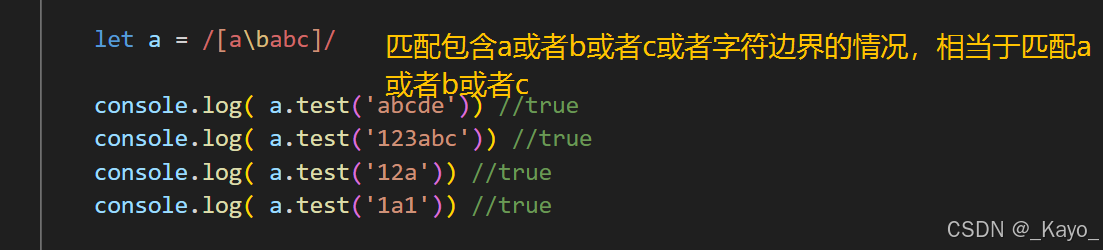
javascript
let a = /a\babc/
console.log( a.test('abcde')) //true
console.log( a.test('123abc')) //true
console.log( a.test('12a')) //true
console.log( a.test('1a1')) //true\B 非字符边界
\B匹配非字符边界
组
(x)
用()包裹住的内容是一个捕获组,()也成为捕获括号。
()可以表示前面的匹配内容是一个整体,也可以表示对捕获内容进行记忆。
使用()创建捕获组
思考这样一个场景,如果我想在匹配时,匹配前面某一个子串,并且在后续,我需要这个匹配内容反复出现,使用捕获组和\n语法即可实现这种匹配。
\n \n用于表示匹配和前面第n个捕获括号一样的内容。
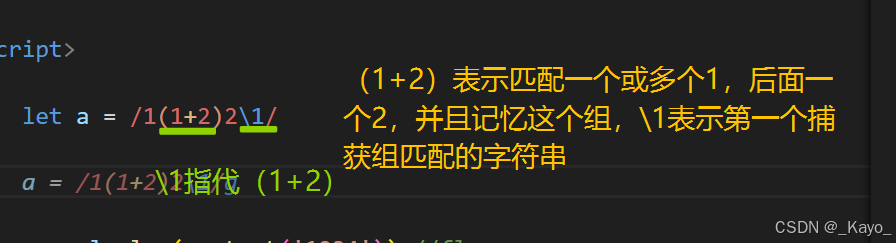
javascript
let a = /1(1+2)2(9+)\1\2/
console.log( a.test('11229129')) //true
console.log( a.test(' 1111229129')) //true
console.log( a.test(' 1229129')) //false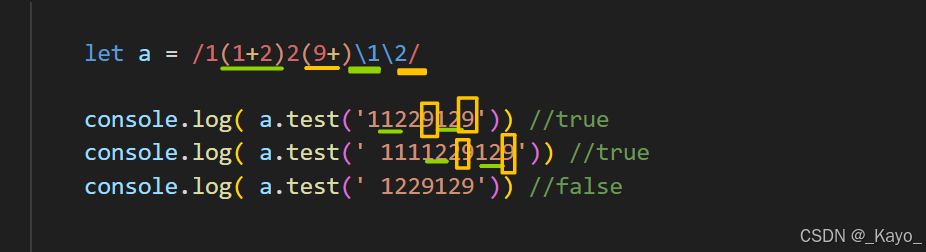
关于第一个捕获组,\1匹配的内容需要和第一个()匹配的内容完全一致,而不是满足一样的匹配规则:
javascript
let a = /2(1+2)2(9+)\1\2/
console.log( a.test(' 2111229129')) //false使用()表示特殊匹配对一个整体生效
()也可以用于表示将()内的内容看成一组,如果我想匹配一个或多个123,可以通过把123用()包裹起来实现:
javascript
let a = /(123)+/
console.log( a.test(' 112')) //false
console.log( a.test(' 1123123')) //true使用(?:x)的格式,可以达到一样的匹配效果,但不同的是(?:x)表示不对捕获的内容进行记忆,这种模式下,()叫做非捕获括号:
javascript
let a = /(?:123)+/
console.log( a.test(' 112')) //false
console.log( a.test(' 1123123')) //true如果不使用(),/123+/则表示匹配一个或多个3
断言
先行断言 x(?=y)
用于表示匹配的字符串x后面必须跟着的y。或者说,用于表示匹配的字符串x必须在y的前面,其中(?=y)的部分只用于验证,最终的匹配内容中不会包含它:

javascript
let a = /123(?=abc)/
console.log( a.test(' 123456')) //false
console.log( a.test(' 123abcd')) //true后行断言 (?<=y)x
用于表示匹配字符串x前面必须跟着y,或者说,x必须在y的后面。同样,y只用于匹配校验,不会存在于匹配结果中。
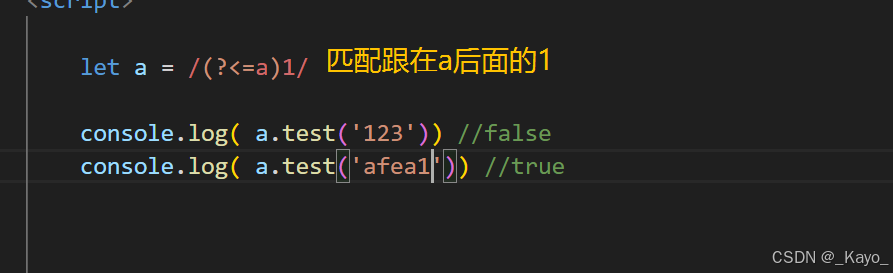
javascript
let a = /(?<=a)1/
console.log( a.test('123')) //false
console.log( a.test('afea1')) //true正向否定查找 x(?!y)
表示当x后面不跟着y时,才能匹配成功x。
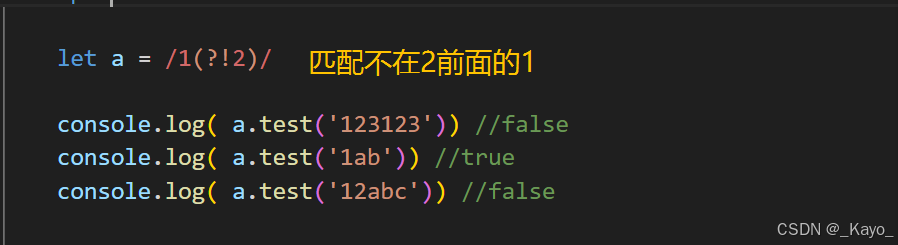
javascript
let a = /1(?!2)/
console.log( a.test('123123')) //false
console.log( a.test('1ab')) //true
console.log( a.test('12abc')) //false反向否定查找 (?<!y)x
表示当x前面不是y时,才匹配x
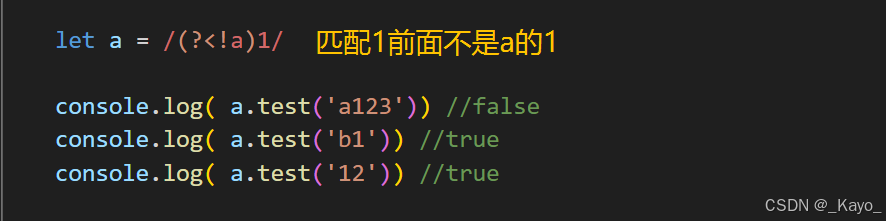
javascript
let a = /(?<!a)1/
console.log( a.test('a123')) //false
console.log( a.test('b1')) //true
console.log( a.test('12')) //true