基于正则表达式的爬虫
一、爬虫简介
1、搜索引擎:百度,谷歌,企业内部的知识库,某些项目专项数据爬取,专业的数据爬取
2、互联网:公网(不需要授权的情况就可以浏览的内容,搜索引擎的重点),深网(需要授权才能使用的内容),暗网(非正式渠道,无法使用常规手段访问)
3、爬取互联网的公开信息,但是正常情况下,也需要遵守一个规则:robots协议。

二、基本原理
1、所有和网页,均是HTML,HTML首先是一个大的字符串,可以按照字符串处理的方式对响应进行解析处理。其次,HTML本身也是一门标记语言,与XML是同宗同源,所以可以使用DOM对其文本进行处理。
2、所有的爬虫,核心基于超链接,进而实现网站和网页的跳转。给我一个网站,爬遍全世界。
3、如果要实现一个整站爬取程序,首先需要收集到站内所有网址,并且将重复网址去除,开始爬取内容并保存在本地或数据库,进行实现后续目标。
三、正则表达式的实现
python
import re,requests,time
resp = requests.get('http://192.168.102.136/')
# print(resp.text)
#解析网页中的所有超链接
# links = re.findall('<a href="(.+?)">',resp.text) # 输出的是列表
# for link in links:
# print(link)
保存网站完整链接和图片的代码如下所示:
python
import re,requests,time
resp = requests.get('http://192.168.102.136/')
# print(resp.text)
#解析网页中的所有超链接
# links = re.findall('<a href="(.+?)">',resp.text) # 输出的是列表
# for link in links:
# print(link)
# 基于一些错误的源内容,对其进行优化,并下载和保存网页
def download_page():
resp = requests.get('http://192.168.102.136/')
links = re.findall('<a href="(.+?)"', resp.text) # 输出的是列表
for link in links:
# 根据页面特性,将一些无用的信息排除
if 'articleid' in link:
continue
if link.startswith('#'):
continue
# 对超链接进行处理,拼接出完整的URL地址
if link.startswith('/'):
link = 'http://192.168.102.136' + link
# print(link)
# 将页面文件保存与本地
resp = requests.get(link)
resp.encoding = 'utf-8'
filename = link.split('/')[-1] + time.strftime("_%Y%m%d_%H%M%S") + '.html'
with open(f'./woniunote/page/{filename}',mode='w',encoding='utf-8') as file:
file.write(resp.text)
# 爬虫首页图片
def download_image():
resp = requests.get('http://192.168.102.136/')
images = re.findall('<img src="(.+?)"',resp.text)
for image in images:
# print(image)
# 处理URL地址
if image.startswith('/'):
image = 'http://192.168.102.136' + image
# 下载图片
resp = requests.get(image)
# suffix = image.split('.')[-1]
filename = time.strftime("%Y%m%d_%H%M%S") + image.split('/')[-1]
with open('./woniunote/image/' + filename,mode='wb') as file:
file.write(resp.content)
if __name__ == '__main__':
# download_page()
download_image()基于BeautifulSoup的爬虫
一、Beautifulsoup简介
Beautiful Soup提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能。它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序。
Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码。你不需要考虑编码方式,除非文档没有指定一个编码方式,这时,BeautifulSoup就不能自动识别编码方式了。然后,你仅仅需要说明一下原始编码方式就可以了。
Beautiful Soup已成为和lxml、html6lib一样出色的python解释器,为用户灵活地提供不同的解析策略或强劲的速度。
BS基于DOM结构进行页面内容解析,当开始解析时,会将整个页面的DOM树保存于内存中,进而实现查找。
解析器:
(1)Python标准库BeautifulSoup(markup,"html.parser")Python的内置标准库、执行速度适中、文档容错能力强
(2)Ixml HTML解析器BeautifulSoup(markup,'Ixml')速度快、文档容错能力强需要安装C语言库
(3) Ixml XML解析器BeautifulSoup(markup, "xml")速度快、唯一支持XML的解析器需要安装C语言库
(4)html5lib BeautifulSoup(markup,"html5lib")最好的容错性、以浏览器的方式解析文档、生成HTML5格式的文档速度慢、不依赖外部扩展
二、具体代码使用
python
from bs4 import BeautifulSoup
import requests
resp = requests.get('http://192.168.102.136/')
# 初始化解释器
BS = BeautifulSoup(resp.text,'lxml')
# 查找页面元素(根据标签层次进行查找)
# print(BS.head.title)
# print(BS.head.title.string)
# 查找页面元素的通用方法
# 1、find_all:根据标签,属性,XPath等进行查找
# 2、select:css选择器,div,#id,.class
# 查找页面所有超链接
links = BS.find_all('a')
# for link in links:
# print(link['href'])
# 查找页面所有的图片
images = BS.find_all('img')
# for image in images:
# print(image['src'])
# 根据id或class等属性查找
'''
keyword = BS.find(id='keyword')
print(keyword)
# 结果:<input class="form-control" id="keyword" onkeyup="doSearch(event)" placeholder="请输入关键字" type="text"/>
print(keyword['placeholder'])
# 结果:请输入关键字
'''
'''
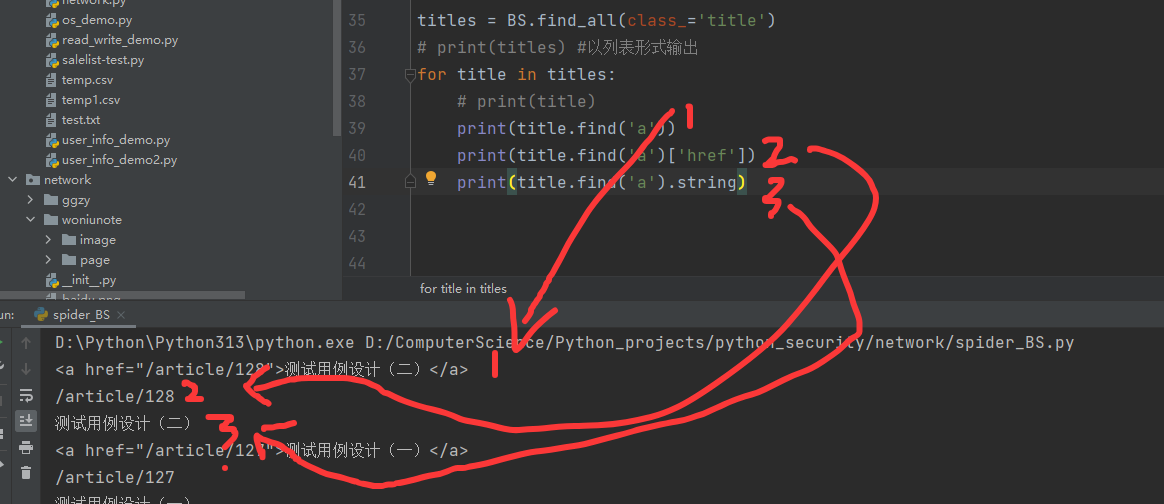
titles = BS.find_all(class_='title')
# print(titles) #以列表形式输出
for title in titles:
# print(title)
print(title.find('a'))
print(title.find('a')['href'])
print(title.find('a').string)
'''
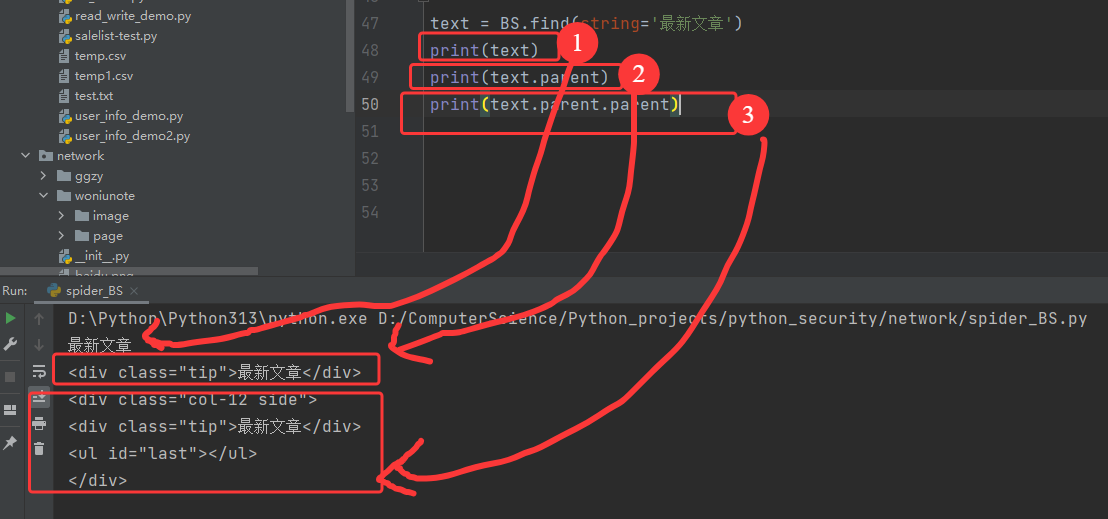
'''
text = BS.find(string='最新文章')
print(text)
print(text.parent)
print(text.parent.parent)
'''
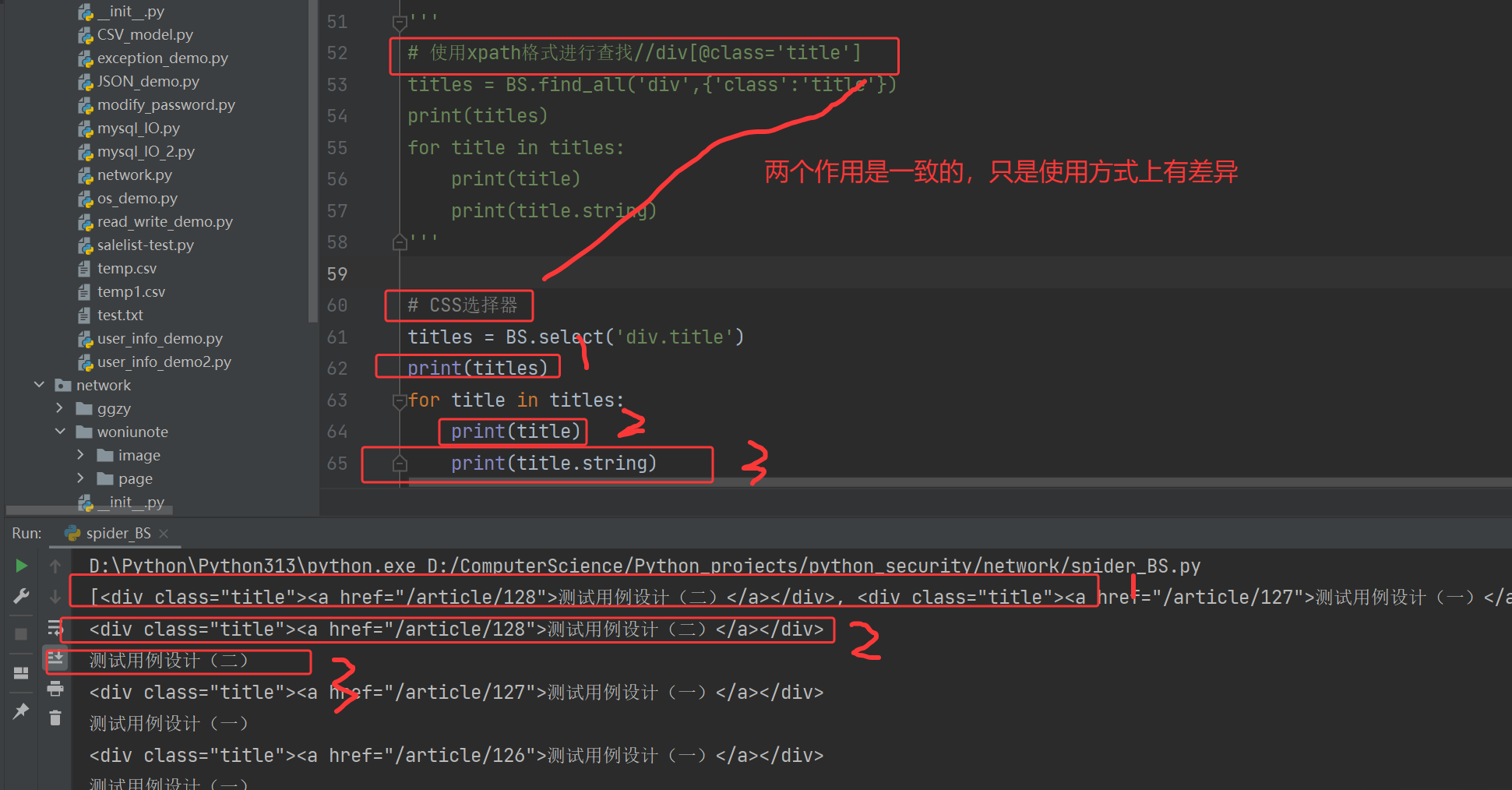
'''
# 使用xpath格式进行查找//div[@class='title']
titles = BS.find_all('div',{'class':'title'})
print(titles)
for title in titles:
print(title)
print(title.string)
'''
# CSS选择器
titles = BS.select('div.title')
print(titles)
for title in titles:
print(title)
print(title.string)
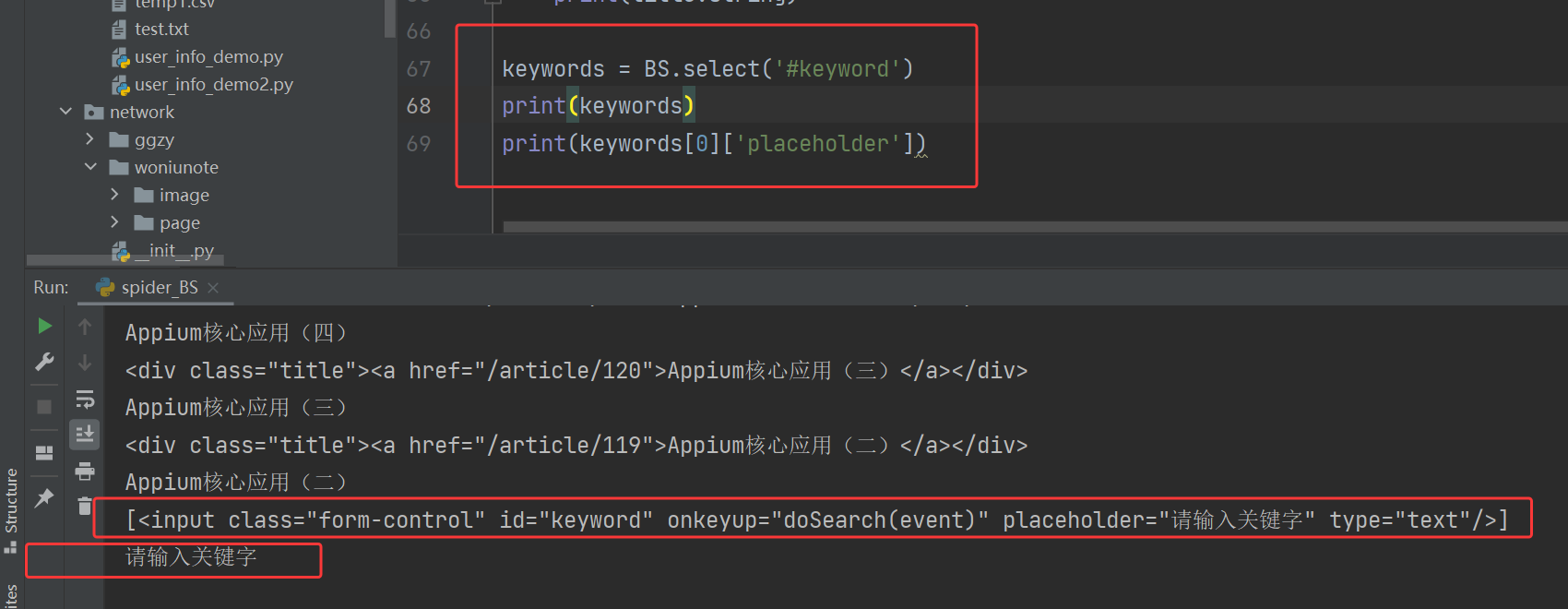
keywords = BS.select('#keyword')
print(keywords)
print(keywords[0]['placeholder'])代码对应输出的结果: