今天我们介绍可解释机器学习算法的最后一部分,基于XGBoost算法的SHAP值可视化。关于SHAP值其实我们之前的很多个推文中都介绍到,不论是R版本的还是Python版本的,亦不论是普通的分类问题还是生存数据模型的。在此推文中我们将基于XGBoost模型理解SHAP值的计算过程。此外,我们之前的SHAP可视化是基于别人封装好的函数。在今天的推文中,我们将学习如何使用ggplot2实现更加美观的SHAP值可视化。
R与机器学习系列|shapviz------机器学习"黑箱模型"SHAP值可视化
机器学习|SHAP value的另一种R可视化方式以及Python实现SHAP value可视化
机器学习|分享一篇25分临床预测模型文章,再次体现SHAP 值在机器学习中的重要性!
R学习|R复现机器学习算法XGBoost特征重要性解释------SHAP value
SHAP值在机器学习算法中的重要性主要体现在以下几个方面:
解释模型预测结果:SHAP值能够解释单个样本预测结果的贡献。它告诉我们每个特征对于某个特定预测结果的影响程度,从而帮助我们理解模型是如何基于输入特征做出预测的。
特征重要性评估:SHAP值可以用来评估特征的重要性。通过分析多个样本的SHAP值,我们可以得出哪些特征对于整体模型的性能影响最大,从而在特征选择、降维等任务中提供指导。
模型调试与验证:通过检查每个样本的SHAP值,可以帮助我们识别模型在某些特定预测上可能出现的问题。如果某个样本的预测与真实值相差较大,SHAP值可以揭示哪些特征导致了这种预测差异。
透明性和可信度:SHAP值的计算基于合理的博弈论原理,它们为模型的预测结果提供了一种可解释的解释。这可以增加模型的可信度,特别是在需要对模型决策做出解释的场景中。
特征交互分析:SHAP值不仅仅告诉我们单个特征的影响,还可以揭示不同特征之间的交互作用对预测结果的影响。这对于理解特征之间的复杂关系以及模型如何从这些关系中学习非常有帮助。
我们也可以看到SHAP值对模型的解释在高分的机器学习文献中出现的还是很频繁,如下面的两篇分别发表在EClinicalMedicine和 JAMA surgery上的文章。
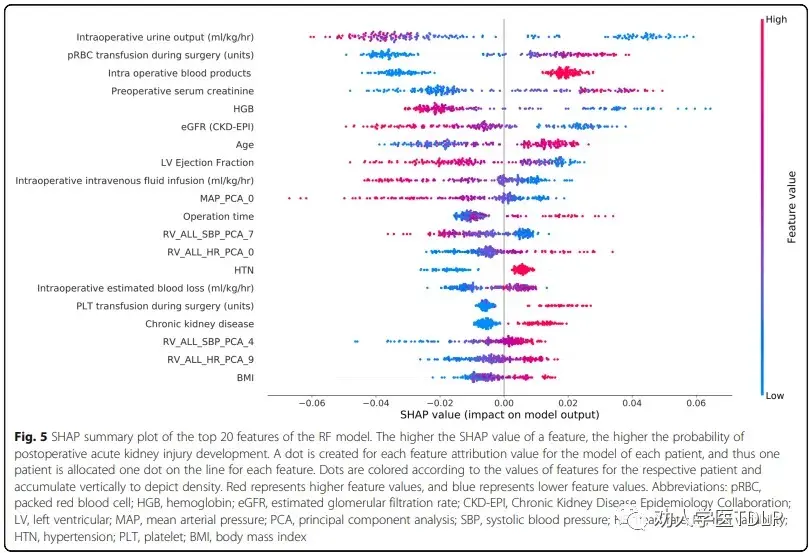
Tsai, Shang-Feng et al. "Development and validation of an insulin resistance model for a population without diabetes mellitus and its clinical implication: a prospective cohort study." EClinicalMedicine vol. 58 101934. 4 Apr. 2023, doi:10.1016/j.eclinm.2023.101934
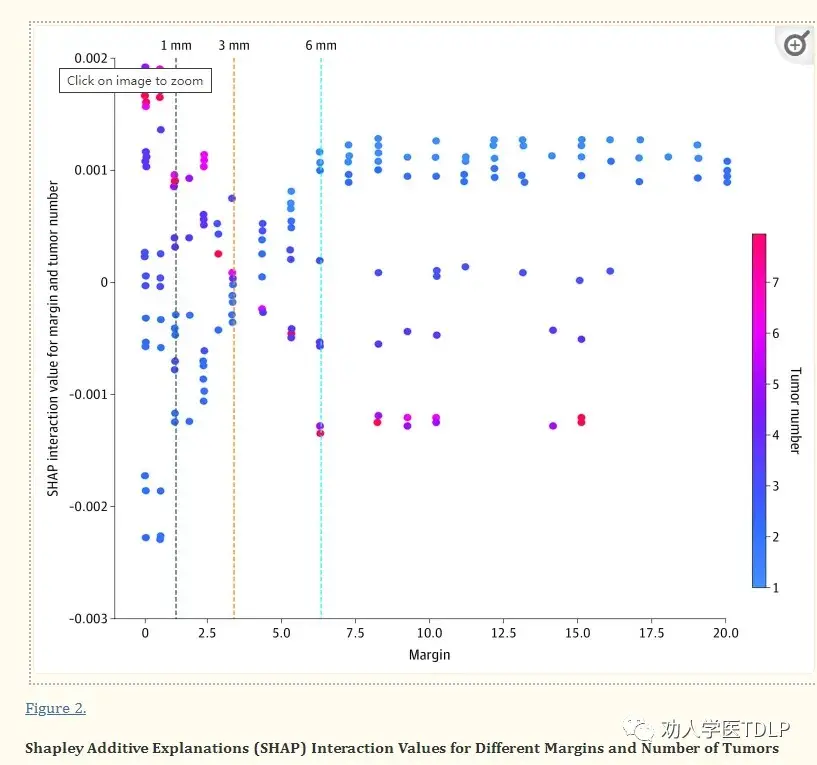
Bertsimas, Dimitris et al. "Using Artificial Intelligence to Find the Optimal Margin Width in Hepatectomy for Colorectal Cancer Liver Metastases." JAMA surgery vol. 157,8 (2022): e221819. doi:10.1001/jamasurg.2022.1819
1.1介绍
真实的 Shapley 值在理论上被认为是最优的;然而,真实SHAP值的计算会花费大量的时间。因此,iml包提供了近似 的Shapley 值计算方法。此外,Lundberg 和 Lee也开发了其他SHAP值的近似计算方法,虽然不是纯粹的模型无关方法,但也适用于基于树的模型,并且在大多数 XGBoost 算法实现中(包括 xgboost 包)完全可行。与 iml 的近似方法类似,这种基于树的 Shapley 值估计方法也是一种近似估计的方法,但其运行的时间远远要比iml包的计算时间短。为了演示,我们将使用第 12.5.2 节中使用的特征和最终创建的 XGBoost 模型。
1.2 SHAP计算
为了说明我们上面提到的问题,我们利用之前的数据再xgboost中拟合一个模型。xgboost算法的执行、参数调整及特征重要性解释在之前的章节中也有介绍。这里不过多介绍。首先,我们加载相关依赖包。
# Helper packages
library(tidyverse) # for general data wrangling needs
# Modeling packages
library(gbm) # for original implementation of regular and stochastic GBMs
library(h2o) # for a java-based implementation of GBM variants
library(xgboost) # for fitting extreme gradient boosting
library(rsample)# for data split
library(caret)# dummy funtion for categorical variables然后我们加载需要用到的数据。需要注意的是,我们将一个变量处理为多分类变量,已说明独热编码在xgboost模型数据预处理中的应用。此外,如果这里直接将多分类变量处理为数值型变量,那么最后的SHAP图里面也不会看到该变量其他哑变量的信息。
此外,因为xgboost的输入特征文件格式为矩阵,如果这个时候不对多分类变量进行虚拟编码,那么直接转换为矩阵后数据维度便会出错。
data<-read.csv("diabetes.csv",header = T)
data%>%
mutate(Pregnancies=case_when(
Pregnancies<3~"A",
Pregnancies>=3 &Pregnancies<=6~"B",
Pregnancies>6~"C"
))->data
data$Pregnancies<-as.factor(data$Pregnancies)
# Stratified sampling with the rsample package
set.seed(123)
split <- initial_split(data, prop = 0.7,
strata = "Outcome")
data_train <- training(split)
data_test <- testing(split)
data_train2=select(data_train, -Outcome)独热编码
dmytr = dummyVars(" ~ .", data =data_train2, fullRank=T)
data_train3 = predict(dmytr, newdata =data_train2)
X <-data_train3
Y<- data_train[,ncol(data_train)]此时的X为经过独热编码之后的特征矩阵。下面我们利用之前的超参数直接建立xgboost模型
# optimal parameter list
params <- list(
eta = 0.01,
max_depth = 3,
min_child_weight = 3,
subsample = 0.5,
colsample_bytree = 0.5
)
# train final model
xgb.fit.final <- xgboost(
params = params,
data = X,
label = Y,
nrounds = 602,
objective = "binary:logistic",
verbose = 0
)然后我们将特征重新由低到高进行标准化
feature_values <- X %>%
as.data.frame() %>%
mutate_all(scale) %>%
gather(feature, feature_value) %>%
pull(feature_value)然后我们计算特征的SHAP值以及SHAP重要性等参数
shap_df <- xgb.fit.final %>%
predict(newdata = X, predcontrib = TRUE) %>%
as.data.frame() %>%
select(-BIAS) %>%
gather(feature, shap_value) %>%
mutate(feature_value = feature_values) %>%
group_by(feature) %>%
mutate(shap_importance = mean(abs(shap_value)))1.3 SHAP可视化
现在,我们已经计算得到了这些特征的SHAP值,下面我们进行可视化。首先我们使用ggplot2进行可视化,严格的来说是基于ggplot2的蜂群图可视化。看过SHAP图后可以看到其实就是一个散点图,横坐标是SHAP值,纵坐标是每个特征,每个点代表一个观测值。此外,纵坐标按照SHAP值的重要性进行排序。
library(ggbeeswarm)
p1 <- ggplot(shap_df, aes(x = shap_value, y = reorder(feature, shap_importance))) +
geom_quasirandom(groupOnX = FALSE, varwidth = TRUE, size =1, alpha = 0.8, aes(color = shap_value)) +
scale_color_gradient(low = "#ffcd30", high = "#6600cd") +
labs(x="SHAP value",y="")+
theme_bw()+
theme(axis.text = element_text(color = "black"),
panel.border = element_rect(linewidth = 1))+
geom_vline(xintercept = 0,linetype="dashed",color="grey",linewidth=1)
p1 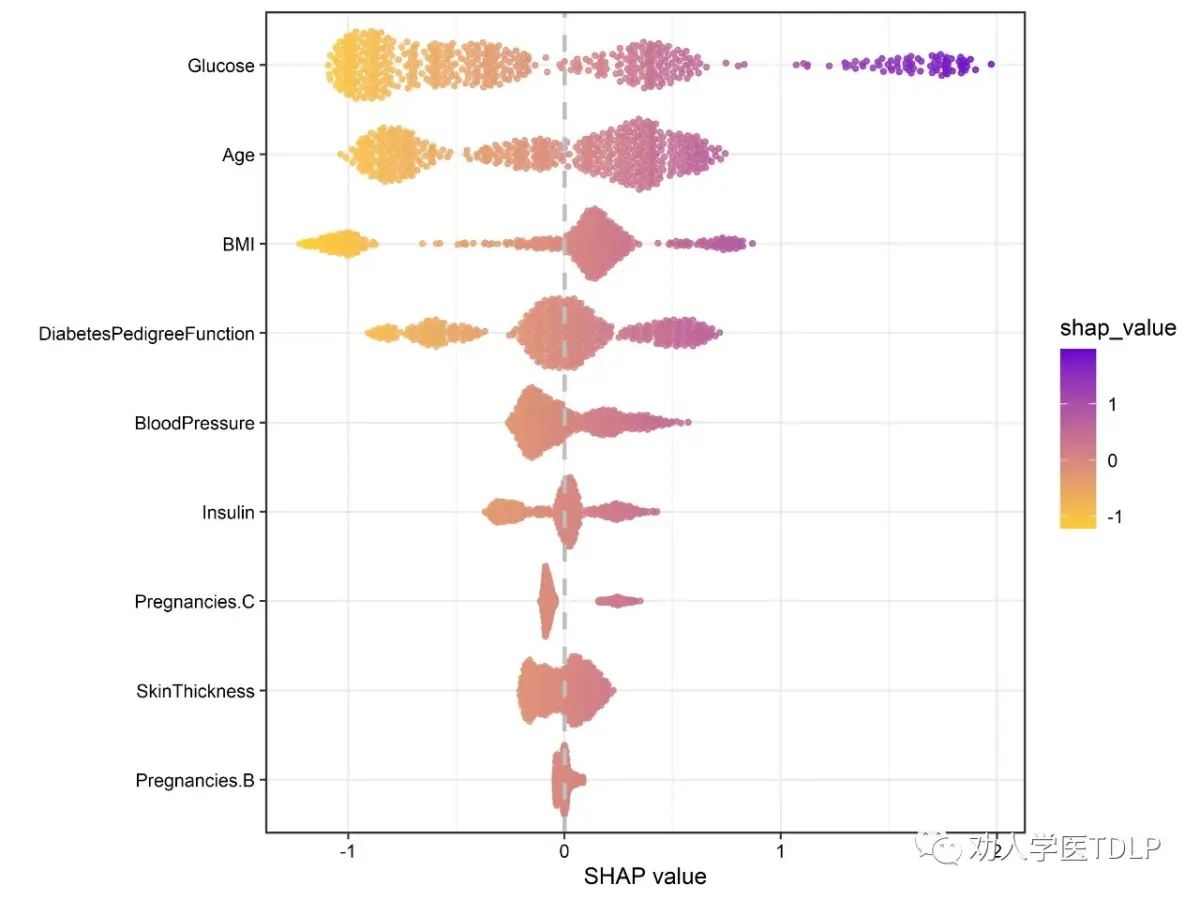
基于ggplot2的SHAP值可视化
从上图中我们可以看出患者血糖对结局影响最大,其次是年龄、BMI。
下面我们再根据SHAP重要性值做一个SHAP重要性图
p2 <- shap_df %>%
select(feature, shap_importance) %>%
filter(row_number() == 1) %>%
ggplot(aes(x = reorder(feature, shap_importance), y = shap_importance,fill=feature)) +
geom_col(alpha=0.6) +
coord_flip() +
xlab(NULL) +
ylab("mean(|SHAP value|)")+
scale_fill_brewer(palette = "Set1")+
theme_bw()+
theme(legend.position = "",
axis.text = element_text(color = "black"),
panel.border = element_rect(linewidth = 1))
p2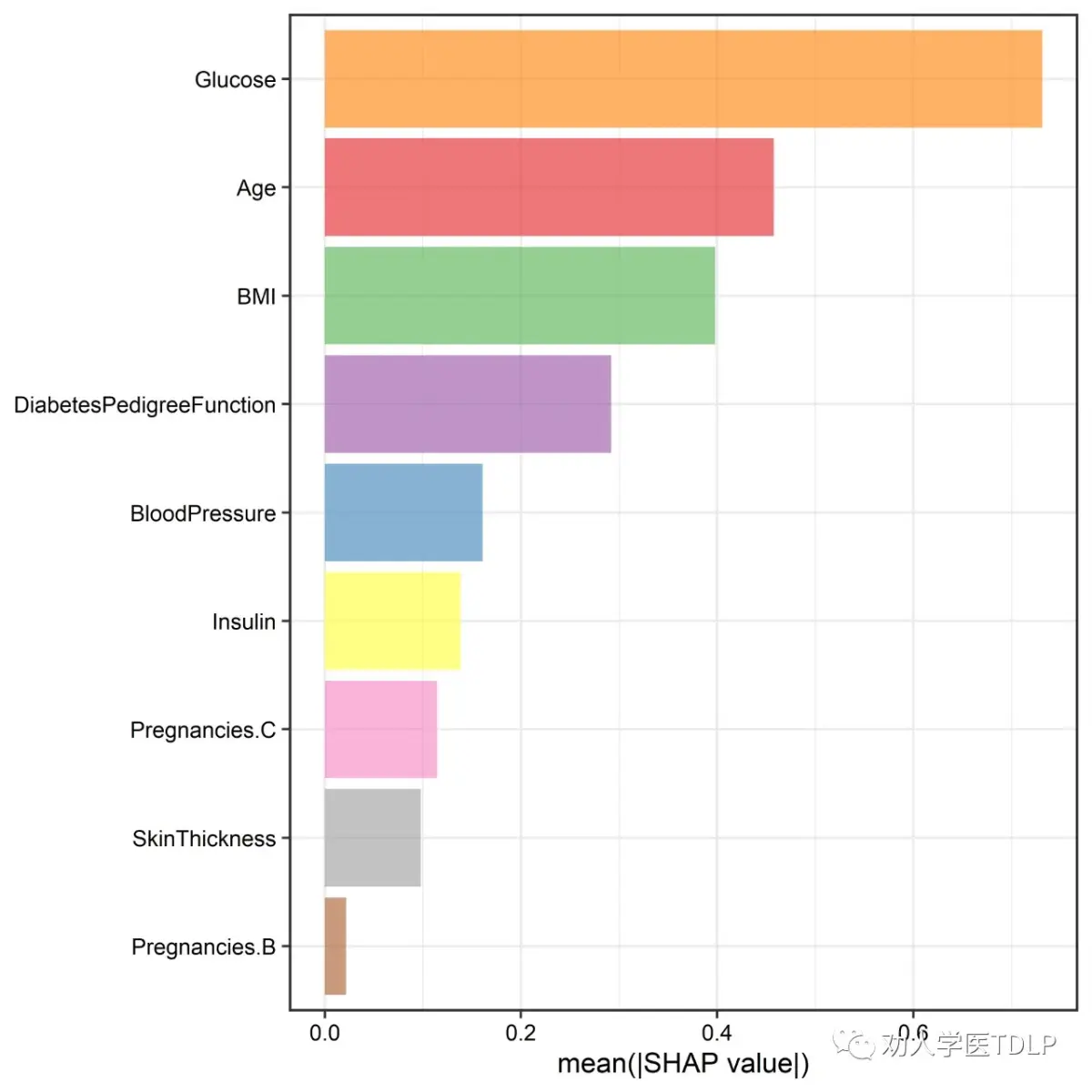
SHAP重要性图
我们也可以把两个拼图展示
library(patchwork)
plot<-p1+p2&
plot_layout(widths = c(2,1))
plot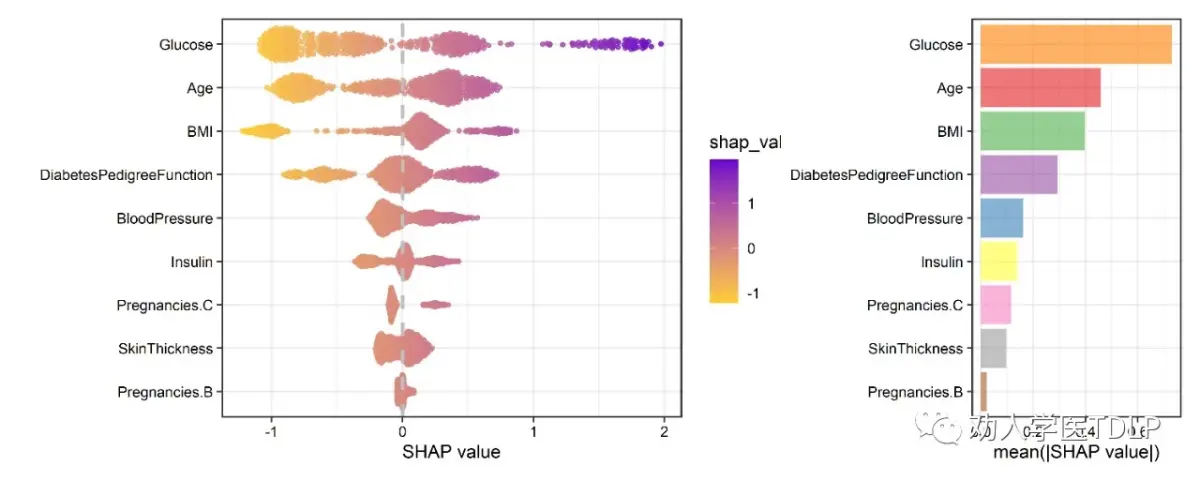
SHAP值可视化及SHAP重要性排序
下面我们用之前封装好的SHAP.R函数看看效果
source("shap.R")
shap_result = shap.score.rank(xgb_model =xgb.fit.final,
X_train =data_train3,
shap_approx = F)
#计算前10个特征的SHAP值
shap_long_hd = shap.prep(X_train =data_train3 , top_n =9)
#SHAP值可视化
shapR<-plot.shap.summary(data_long =shap_long_hd)
shapR
可以看到结果是一致的。
我们还可以利用这些信息来创建与PDPs(部分依赖图)相对应的另一种方法。基于Shapley值的依赖图将一个特征的Shapley值显示在y轴上,将该特征的值显示在x轴上。通过为数据集中的所有观察值绘制这些值,我们可以看到随着特征的值变化,其归因重要性如何变化。
shap_df %>%
filter(feature %in% c("BMI", "Glucose")) %>%
ggplot(aes(x = feature_value, y = shap_value)) +
geom_point(aes(color = shap_value)) +
scale_colour_viridis_c(name = "Feature value\n(standardized)", option = "C") +
facet_wrap(~ feature, scales = "free") +
scale_y_continuous('Shapley value', labels = scales::comma) +
xlab('Normalized feature value')+
theme_bw()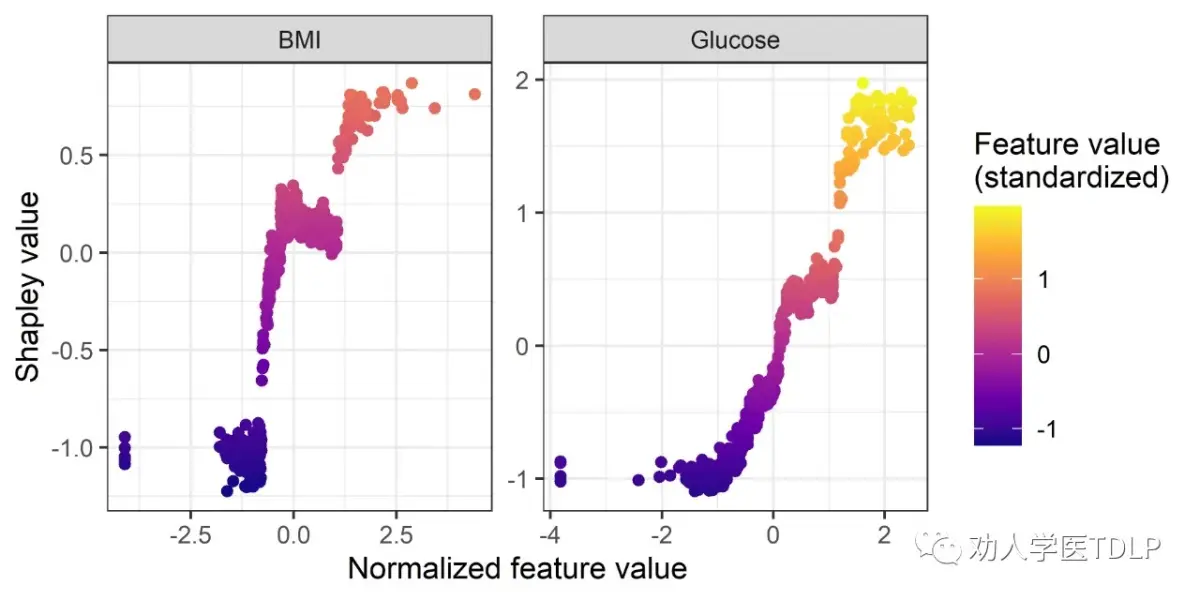
我们可以看到BMI和血糖与SHAP值明显正相关,随着这两个特征值增大,SHAP值也逐渐增大,说明对结局的影响也增加。
终于,这个系列(有监督机器学习)更新到今天结束了。希望大家都有收获,下个系列我们再见!

图源于网络
**参考来源:**Bradley Boehmke & Brandon Greenwell R与机器学习
© 著作权归作者所有,转载或内容合作请联系作者

喜欢的朋友记得点赞、收藏、关注哦!!!