利用传统手段将文档内容转换为视频,比如根据文档内容录制一个视频,不仅需要投入大量的时间和精力,而且往往需要具备专业的视频编辑技能。使用大模型技术可以更加有效且智能化地解决上述问题。本实践方案旨在依托大语言模型(Large Language Models, LLMs)和多模态应用技术,向您展示如何将文档自动转换为视频,并提供配套的完整代码包,帮助您快速入门上手本实践教程。
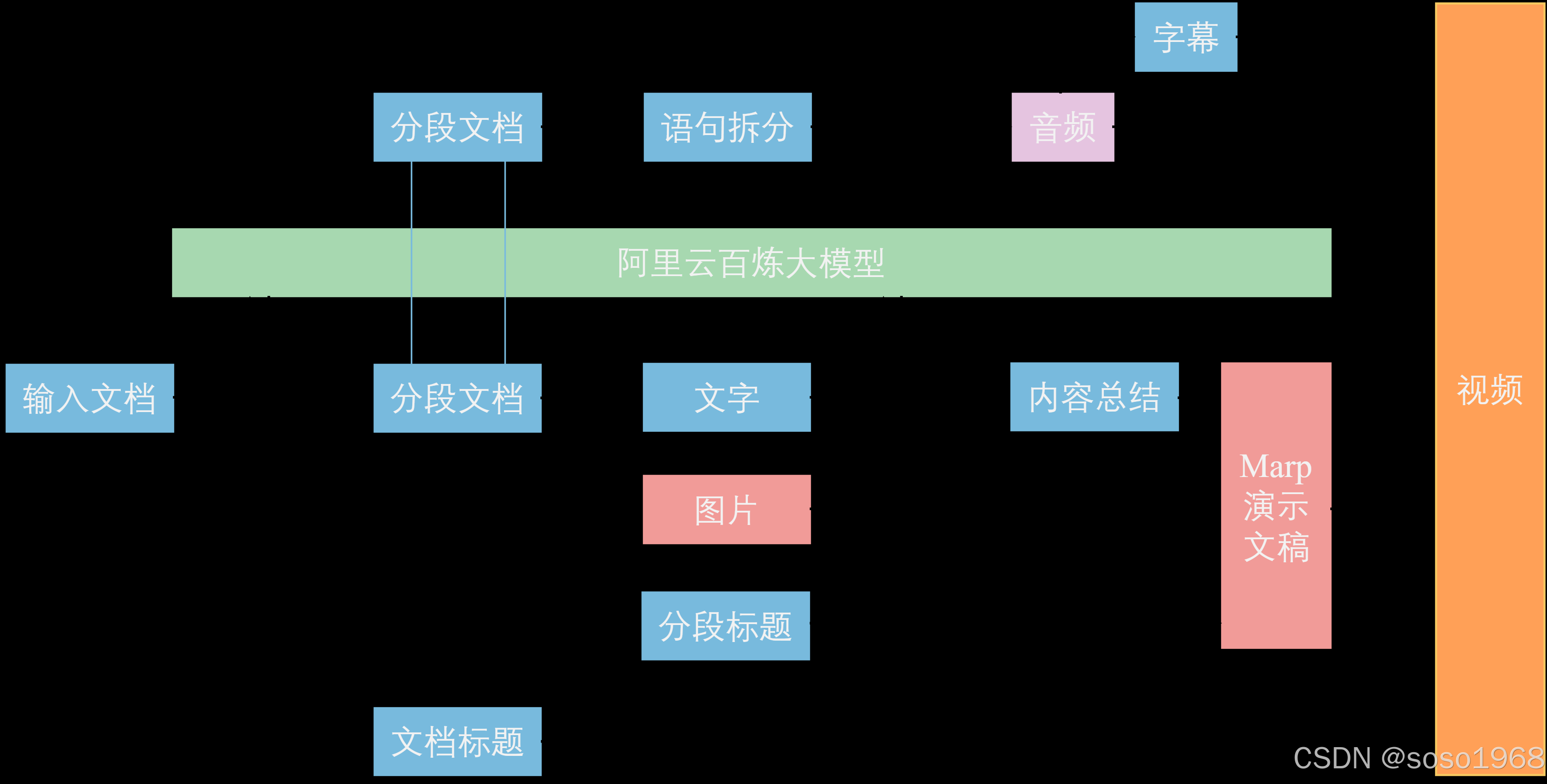
方案概览
-
**文档切片:**首先,我们运用大模型来总结文档标题,将文档划分为不同段落。并为每个段落生成一个概括性的段落标题。
-
**生成演示文稿:**紧接着,我们整合各部分内容,包括标题、正文以及图片等,利用这些素材生成演示文稿图片。
-
**生成讲解语音与字幕:**接下来,我们采用多模态大模型技术,将文字材料转换成音频文件,并依据音频的播放时长自动生成配套的文字字幕。
-
**生成视频:**最后我们将所有演示文稿图片剪辑为视频,并将音频与字幕文件嵌入视频。
准备工作
-
获取API-KEY,用于调用阿里云百炼提供的大模型。
百炼为新用户提供了免费额度,额度消耗完后按 token 计费。您可以查看 计费说明获取计费详情。
-
配置环境变量,以降低API-KEY的泄露风险。您可以参考配置API-KEY到环境变量,根据您的操作系统选择适合的环境变量配置方法。
-
本实践教程依赖音视频处理工具FFmpeg和演示文稿制作工具Marp,请您使用如下示例代码安装这两个工具:
MacOS
Windows
# 您需要在终端运行如下代码 # 请您配置国内镜像源下载 # 安装FFmpeg brew install ffmpeg # 安装Marp # 如安装出现网络问题,请配置国内镜像源或使用cnpm替代npm brew install node npm install -g cnpm --registry=https://registry.npmmirror.com cnpm install -g @marp-team/marp-cli -
本实践教程中的图片生成依赖于浏览器引擎渲染,请您确保您的工作环境中安装了浏览器应用,如Chromium,Google Chrome,Microsoft Edge等。
-
本实践教程基于Python代码,请您确认您的工作环境中已经安装Python,并安装本实践教程所需的Python库,代码示例如下:
MacOS
Windows
# 您需要在终端运行如下代码 # 为了提高下载速度,推荐您配置国内镜像源 pip install --upgrade pip pip install pyppeteer pip install dashscope pip install --upgrade dashscope pip install pydub pip install natsort pip install moviepy pip install ffmpeg-python pip install --upgrade urllib3 requests
快速体验
如果您希望快速尝试,可以直接下载本教程中提供的完整代码到您的本地工作环境中,并在本地执行如下命令:
MacOS
Windows
# 解压缩
unzip doc2video.zip
# 进入文件目录
cd doc2video
# 更改权限
chmod +x run.sh
# 运行脚本
./run.sh为了帮助您理解方案流程,并能够根据实际需要进行个性化定制,下面我们将为您介绍如何从 0 开始,逐步构建一个文档生成视频的工程。
步骤一:准备素材
请您将文档中的文字、Markdown格式的图片链接等内容写到Markdown文件中,并以section_1.md 的格式命名,保存到input 文件夹中。我们将下面提供的section_1.md文件作为示例输入文档。
section_1.md
您可以直接使用完整代码中我们提供的图片、风格文件等素材,并将其全部保存到style文件夹中。
您需要在您的工作环境目录下创建一个Python文件main.py,以便于设置参数以及函数调用,示例代码如下:
您需要将main.py 保存到与input 、style 文件夹相同的路径目录下。在后续流程中,您需要在main.py 中导入各模块函数并且调用它们,我们已经在上述main.py文件中标注了引用或调用函数的位置。在调用各模块函数后,如果您想测试输出,您可以直接在终端运行以下代码:
python main.py步骤二:文档切片
在这一部分中,我们运用大模型为输入文档生成文档标题并划分段落,然后借助大模型对每个段落的内容进行归纳总结,同时为每个段落自动生成相应的段落标题。
划分文本段落
我们借助API调用阿里云百炼提供的通义千问系列大模型通义千问-Plus,为输入文档生成一个文档标题并划分段落。
通义千问-Plus是通义千问超大规模语言模型的增强版,支持中文英文等不同语言输入。能力均衡,推理效果和速度介于通义千问-Max和通义千问-Turbo之间,适合中等复杂任务。您也可以根据实际应用需求来选择合适的大模型,详见 模型列表。
通义千问-Plus的输入和输出成本分别为0.004元/千Token和0.012元/千Token,新用户在开通百炼服务后的30天内拥有100万Token的免费额度。
新建一个名为theme_generate.py的Python文件,代码示例如下:
theme_generate.py
在theme_generate.py 中,我们定义了一个函数theme_generate_with_qwen_plus ,通过API调用通义千问-Plus 为文档生成一个文档标题。在main.py中导入并调用该函数,代码示例如下:
导入并调用theme_generate_with_qwen_plus
我们可以调用该函数来获取示例文档section_1.md的文档标题:

示例文档的标题:大模型:影响与应用。
接下来新建一个名为doc_split.py的Python文件,代码示例如下:
doc_split.py
在doc_split.py 中,我们定义了一个函数doc_split_with_qwen_plus ,通过API调用通义千问-Plus 将输入文档划分为不同段落并为每个段落总结一个段落标题。在main.py中导入并调用该函数,代码示例如下:
导入并调用doc_split.py
调用该函数来为示例文档section_1.md 划分段落并生成段落标题,输出的JSON文件section_1.json 会被保存到**./material/json**中:

输出section_1.json。"title"字段为段落标题,"content"字段为段落内容,图片链接单独保存在字段中。
提炼内容
接着我们通过API调用百炼平台大模型通义千问-Plus,总结提炼各个段落的内容。
新建一个名为qwen_plus_marp.py的Python文件,代码示例如下:
qwen_plus_marp.py
在qwen_plus_marp.py 中,我们定义了一个函数call_with_stream ,通过API调用通义千问-Plus来处理各段落中的内容,具体如下:
-
文字内容:提炼关键要点,以Markdown格式输出。
-
图片链接:直接输出该链接。
我们将在整合图文素材时导入并调用call_with_stream函数。
步骤三:生成演示文稿
在这一部分中,我们将图文素材整合到Markdown文件中,并生成演示文稿图片。
在介绍详细流程和代码之前,我们首先简单介绍一下这部分用到的工具:Marp。Marp是一款基于Markdown语法的开源演示文稿制作工具。您只需要通过编辑Markdown文本,即可生成精美的演示文稿。如果您是VS Code使用者,您还可以下载安装Marp for VS Code插件来实时预览。您也可以参考Marp官方文档,打造出独具个人风格特色的演示文稿。
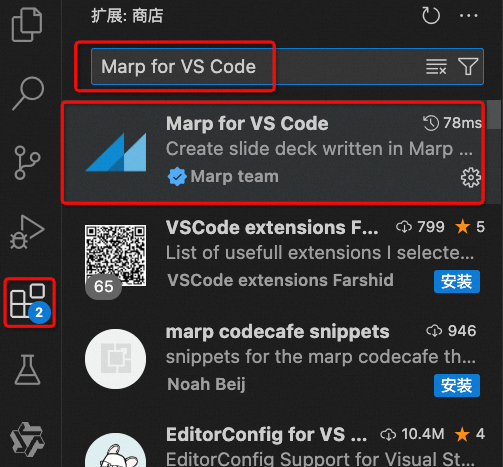
在VS Code的扩展中搜索并安装Marp for VS Code。
由于Marp在将Markdown转换为演示文稿时采用了特定的格式规范和扩展语法,我们准备了一个Python脚本------markdown_gather.py,用于汇总一些优化和调整Markdown格式内容的函数,代码示例如下:
markdown_gather.py
您需要将其和main.py、各函数文件放在同一路径目录下,并在后续调用该文件中的函数。
整合图文素材
我们将调用前文步骤二中"提炼内容"部分介绍的函数call_with_stream 得到文档各段落关键要点、标题、图片链接等内容,并将它们整合为Markdown格式,输出Markdown文件。新建一个名为json2md.py的函数文件,代码示例如下:
在json2md.py中,我们定义了多个函数,主要作用如下:
-
将归属于同一段落的标题、文本内容与其对应的图片链接整合在一起;
-
使用"---"分隔不同段落的内容,以生成多张演示文稿图片。
-
设置演示文稿背景。
您需要在main.py 中导入并调用json2md.py中的函数,代码如下:
导入并调用json2md.py中的函数
为了美化演示文稿,我们进一步添加阿里云Logo、标题页,并调整Markdown格式以适配Marp语法。我们通过导入并调用前文提供的markdown_gather.py中的函数实现,代码如下:
导入并调用markdown_gather.py中的函数
将步骤二中输出的section_1.json 作为输入,输出的Markdown文件section_1.md 会被保存在**./material/markdown**中,效果演示如下:
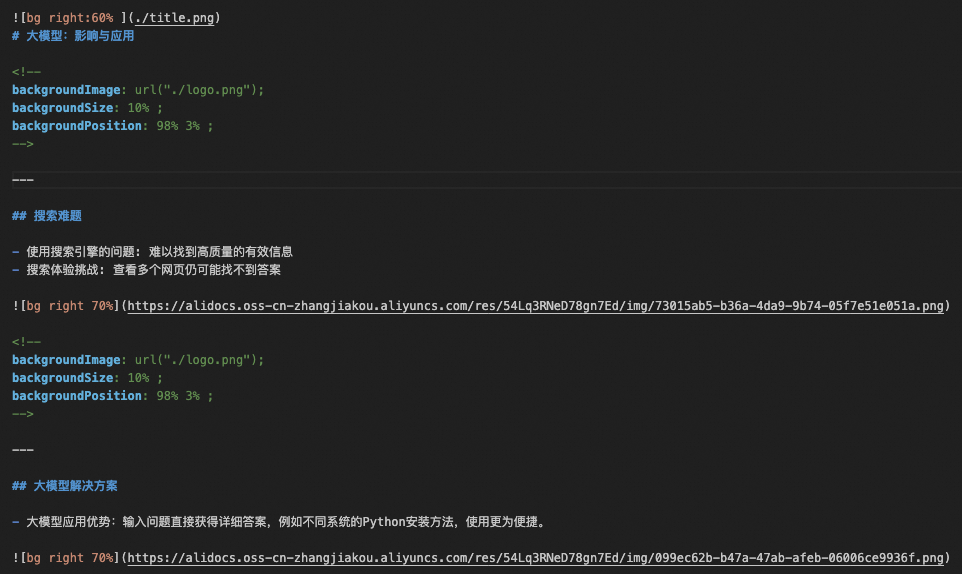
素材整合后的示例输出section_1.md。
生成演示文稿
接下来我们基于Marp生成演示文稿。在使用Marp生成演示文稿前,我们需要定义Marp的整体风格及全局样式。我们可以在Markdown文件的顶部设置,例如:
---
marp: true
theme: gaia
----
marp: true,表示该Markdown文件会被当作Marp演示文稿来处理;
-
theme: gaia,表示将Marp的主题设置为gaia(Marp官方主题之一)。
您可以在本实践教程的完整代码中style 文件夹里获取我们为您准备的Markdown风格文件style.md ,并将其置于Markdown文件的开头。您可以通过在main.py 中导入并调用markdown_gather.py中的函数来实现,具体代码如下:
得到的输出如下:
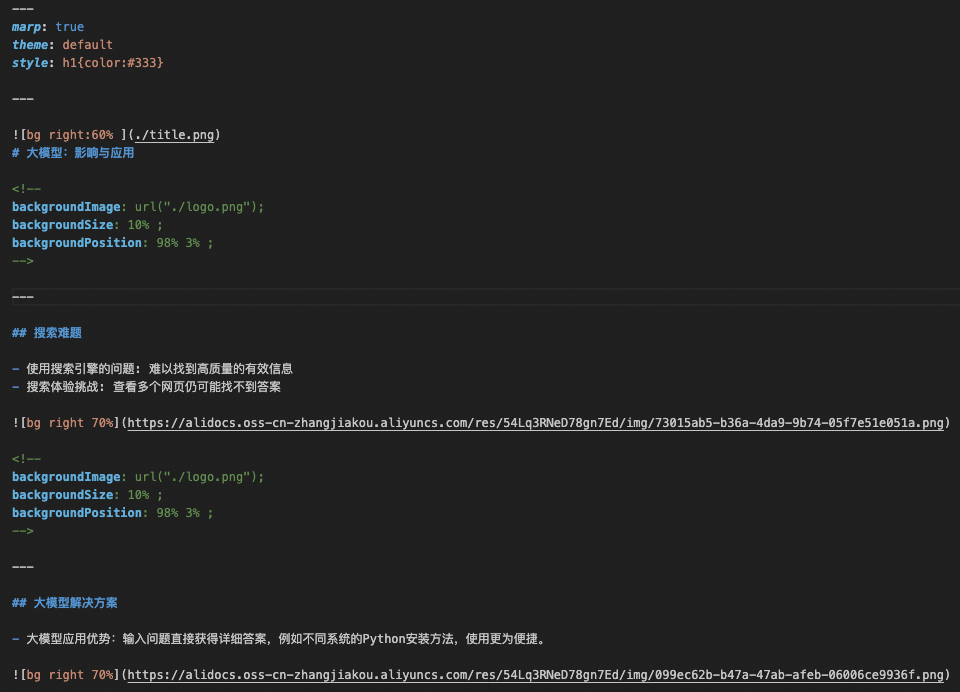
加载风格文件style.md之后的Markdown示例输出。
得到上述的输出后,如果您是VS Code用户且已经安装了Marp for VS Code插件,那么您可以实时预览Marp演示文稿的输出效果。点击界面右上角的预览图标:
在VS Code界面左上角点击预览图标。
实时预览效果如下:
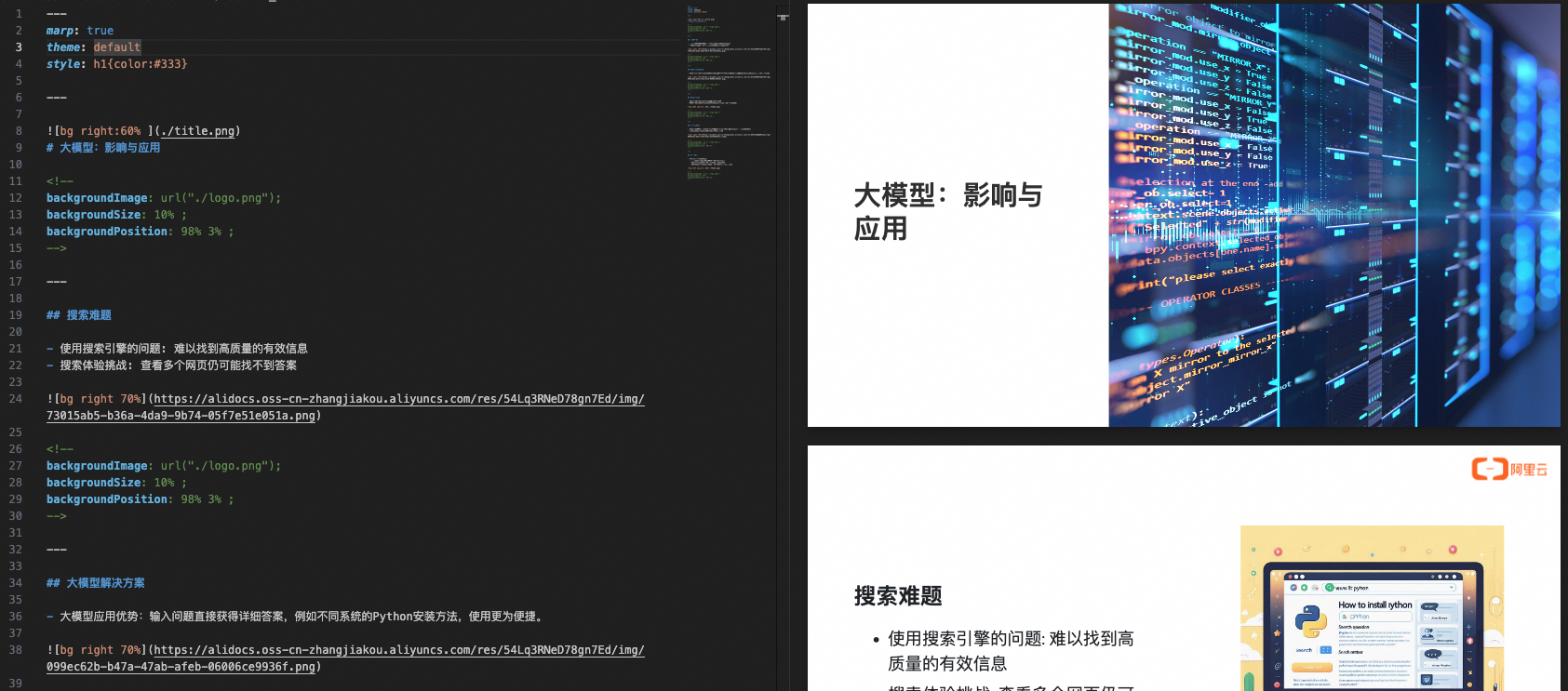
Marp实时预览效果演示。
通过预览确认了Marp演示文稿的输出内容无误后,我们将其导出为图片。新建一个名为marp2image.py的Python文件,代码示例如下:
在marp2image.py 中,我们定义了一个函数convert_md_files_to_png ,将Markdown文件导出为png格式的Marp演示文稿。在main.py 中导入并调用函数convert_md_files_to_png,代码示例如下:
导入并调用函数convert_md_files_to_png
调用函数得到的所有的输出图片均会被保存到**./material/image**中,示例如下:

示例图片。
步骤四:生成讲解语音与字幕
在这一部分中,我们利用多模态语音大模型将文字内容合成为音频,并且精确计算音频的时长,随后自动生成对应的字幕时间戳。
文字合成音频
我们将文档内容划分为若干个句子,然后通过API调用阿里云百炼提供的语音合成大模型CosyVoice ,将所有句子全部合成为mp3格式的音频文件。新建一个名为audio_generate_each_sentence.py的Python文件,代码示例如下:
audio_generate_each_sentence.py
我们在audio_generate_each_sentence.py定义了两个函数,其作用分别为:
-
process_json_file:将文档内容划分为若干个句子。
-
synthesize_md_to_speech :通过API调用百炼提供的语音合成模型CosyVoice,将所有句子全部合成为mp3格式的音频文件。
在main.py中导入并引用这两个函数,代码如下:
导入并引用process_json_file和synthesize_md_to_speech
调用函数后,所有的音频文件会被保存到**./material/audio**中的相应文件夹下。
生成字幕
接下来,我们将通过读取音频的时长以及其对应的文字内容,来生成SRT格式的字幕文件。新建一个Pyhton文件,命名为srt_generate_for_each_sentence.py,代码示例如下:
srt_generate_for_each_sentence.py
在srt_generate_for_each_sentence.py 中我们定义了一个函数generate_srt_from_audio,该函数通过读取输入音频的时长以及其对应的文字内容,来生成SRT格式的字幕文件。
在main.py 中导入并调用函数generate_srt_from_audio,代码示例如下:
导入并调用函数generate_srt_from_audio
调用函数会自动生成srt文件并保存在**./material/video**中,示例输出如下:
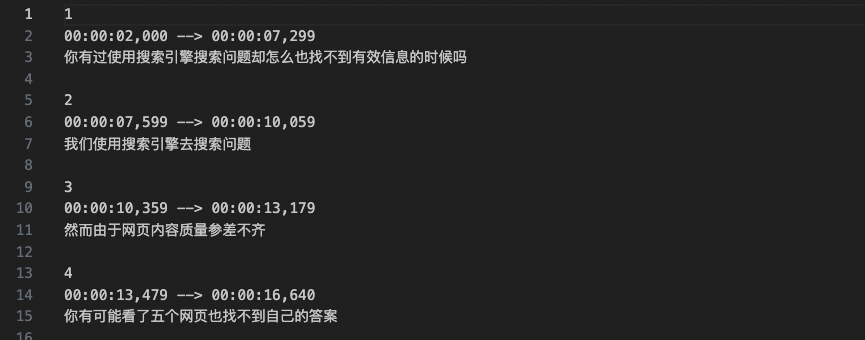
步骤五:生成视频
在这一部分中,我们将生成的演示文稿剪辑为视频,并将音频文件和字幕文件嵌入到视频中。
剪辑视频
首先我们计算每一张演示文稿在视频中的持续时间。新建一个Python文件,命名为calculate_durations_for_each_image.py,代码示例如下:
calculate_durations_for_each_image.py
在calculate_durations_for_each_image.py 中,我们定义了函数calculate_audio_durations,其功能为计算每一张演示文稿在视频中的持续时间。
在main.py 中导入并调用函数calculate_audio_durations,代码示例如下:
导入并调用函数calculate_audio_durations
接着我们将所有演示文稿剪辑为视频。新建一个函数文件,命名为movie_editor.py,代码示例如下:
movie_editor.py
在movie_editor.py 中,我们定义了函数images_to_video_with_durations ,其功能是将所有输入演示文稿按顺序剪辑为视频。在main.py 中导入并调用函数images_to_video_with_durations,代码示例如下:
导入并调用函数images_to_video_with_durations
调用代码后,生成的视频section_1.mp4 会被保存在**./material/video**中
.
嵌入音频与字幕
接下来我们将音频文件嵌入到视频中。新建一个函数文件,命名为audio2video.py,代码示例如下:
我们在函数文件audio2video.py 中定义了函数merge_audio_and_add_to_video,其功能为将音频文件嵌入到视频中。
在main.py 中导入并调用函数merge_audio_and_add_to_video,代码如下:
导入并调用函数merge_audio_and_add_to_video
调用代码后,生成的视频会保存在**./material/video**中。
最后我们将字幕文件嵌入到视频中。新建一个函数文件,命名为srt2video.py,代码示例如下:
我们在函数文件srt2video.py 中定义了函数merge_video_and_subtitle ,其功能为将srt字幕文件嵌入到视频中。在main.py 中导入并调用函数merge_video_and_subtitle,代码示例如下:
导入并调用函数merge_video_and_subtitle
调用代码后,生成的视频section_1_with_audio_with_subs.mp4 会被保存在**./material/video**中。
步骤六(可选):生成长文档视频
通过以上步骤,相信您已经成功地构建了完整的文档生成视频项目工程,并且能够成功地将我们提供的示例文档section_1.md 转化为视频。在实际应用中,您可能会有将更长篇幅的文档转化为视频的需求,例如阿里云大模型工程师ACA认证课程第一章第一课时认识大模型。我们建议您将长篇幅文档划分为若干短文档,并生成所有短文档对应的视频,最终将所有视频整合为一个完整的视频。
划分文档
您需要将长篇幅文档按顺序划分为若干短文档,并按特定的命名格式保存到input 文件夹中。其命名要求为section_index.md,index为短文档索引。示例如下:
生成长文档视频
新建一个Python文件,命名为merge_all_videos.py,代码示例如下:
merge_all_videos.py
在merge_all_videos.py 中,我们定义了函数merge_videos来将合并所有视频。
为了更便捷地实现所有短文档视频生成及合并所有视频的全过程,我们新建一个名为run.sh的shell脚本,代码示例如下:
在run.sh 中,顺序读取所有文档并将其依次转化为视频,最终将所有视频合并输出。您可以运行run.sh脚本来实现上述过程,代码示例如下:
MacOS
Windows
# 更改权限
chmod +x run.sh
# 运行脚本
./run.sh运行脚本后,您可以在**./result.log** 中查看代码运行日志。最终合并完成的视频output_merge_all_video.mp4 会被保存在**./material/video** 中,其内容可以参考效果演示。
总结
通过本实践教程,您将能够:
-
了解如何综合运用大语言模型、多模态应用、Marp等工具将一篇图文并茂的文档转化为更生动的讲解演示视频;
-
通过我们提供的完整代码上手完整地体验文档生成视频的端到端全过程;
-
自行调整输入文档、Marp风格文件、渲染素材等内容,个性化地打造具有您专属风格的视频。