一、TL;DR
- 做了什么:提出了一种对比式语言 - 音频预训练流程,通过将音频数据与自然语言描述相结合来构建音频表征
- 怎么做的 :发布了 LAION-Audio-630K的音频 - 文本对的大型数据集+构建了对比式语言 - 音频预训练模型
- 得到了什么结果:文本到音频检索、零样本音频分类和有监督音频分类都达到了SOTA
- 开源贡献:数据集和模型全部公开
paper:https://arxiv.org/pdf/2211.06687
code:https://github.com/LAION-AI/CLAP
**warning:**其实我试了下,效果一般哈,没有SOTA的图像对比学习模型那么惊艳
二、Introduction
音频-文本对比学习困难点:
- 数据收集困难:不同的音频任务需要精细标注,限制了可用音频数据的数量
为什么现在可以做:
- CLIP证明类比证明训练此类模型只需成对的音频和文本数据,收集难度变低
- AudioClip和 WaveCLIP证明初步可行
motivation:
- 上述模型均在相对较小的数据集上训练,需要进一步大规模数据集训练和实验
- 现有工作缺乏对音频 / 文本编码器的选择及超参数设置的全面研究
- 模型难以适应不同长度的音频输入,尤其是基于 Transformer 的音频编码器,亟需一种解决方案来处理可变长度的音频输入
- 大多数语言 - 音频模型研究仅关注文本到音频检索任务,而未评估其音频表征在其他下游任务中的表现
针对上述问题,本文在数据集、模型设计和实验设置方面做出了以下贡献:
- 发布了最大的公开音频描述数据集 LAION-Audio-630K 数据集,同时采用 **"关键词到描述"**模型将 AudioSet 的标签增强为对应的描述文本。该数据集也可为其他音频任务提供支持。
- 构建了一套对比式语言 - 音频预训练流程。选取了两种音频编码器和三种文本编码器进行测试,并采用特征融合机制来提升模型性能,同时使模型能够处理可变长度的输入。
- 我们在模型上开展了全面的实验,包括文本到音频检索任务,以及零样本和有监督音频分类下游任务 。
- 实验结果表明,数据集规模的扩大、"关键词到描述" 增强方法以及特征融合机制,能从不同角度提升模型性能。
- 文本到音频检索和音频分类任务中达到了当前最先进(SOTA)水平,甚至可与有监督模型的性能相媲美。
三、LAION-AUDIO-630K 及训练数据集
3.1 LAION-Audio-630K
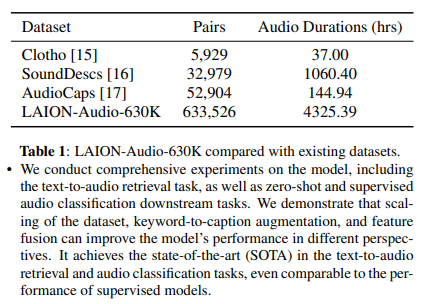
LAION-Audio-630K:
- 包含 633,526 个音频 - 文本对,总时长 4,325.39 小时。
- 涵盖人类活动、自然声音和音效等音频类型,数据来源于 8 个公开网站的资源 。
- 其规模远超以往的音频 - 文本数据集(如表 1 所示)。
3.2 训练数据集
为测试模型性能在不同规模和类型的数据集上的表现,本文采用三种训练集设置(从小到大),分别使用以下三个数据集:
- AudioCaps+Clotho(AC+CL):包含约 55K个音频 - 文本对训练样本;
- LAION-Audio-630K(LA.):包含约630K 个音频 - 文本对;
- AudioSet :包含 190 万个音频样本,但仅提供每个样本的标签。
3.3 数据集格式与预处理
整合所有数据集后,带有文本描述的音频样本总数增至 250 万:
- 本研究中所有音频文件均预处理为单声道、48kHz 采样率的 FLAC 格式。
- 对于仅含标签或关键词的数据集,通过模板 "The sound of label-1, label-2, ..., and label-n" 或 "关键词到描述" 模型将标签扩展为描述文本。
四、 模型架构
4.1 对比式语言 - 音频预训练
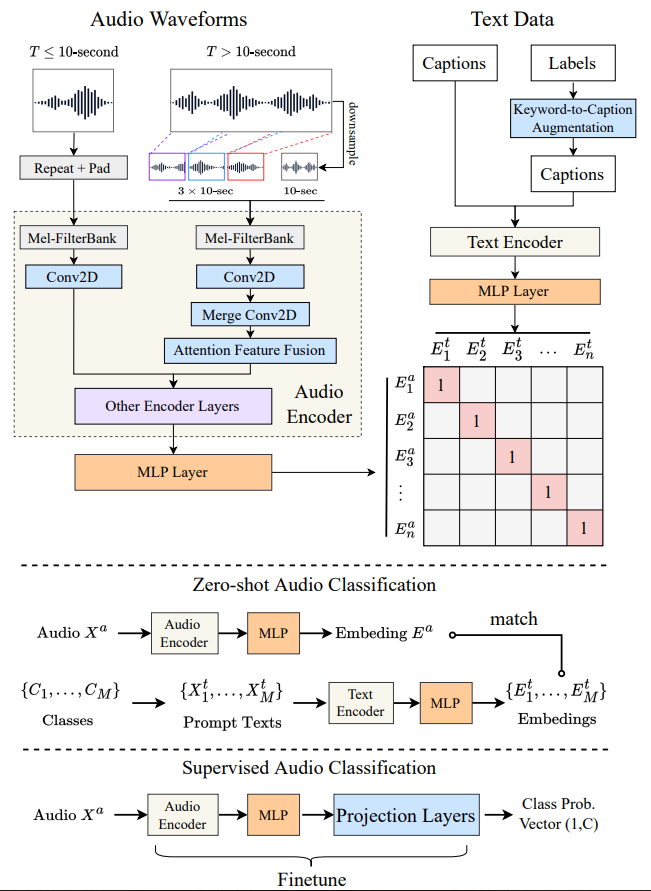
LAION - audio 的 CLAP(Contrastive Language - Audio Pretraining)模型是一个对比语言 - 音频预训练模型,借鉴了 CLIP 的思想,通过大规模音频 - 文本对数据进行预训练,学习音频和语言的联合表征。以下是其模型结构和推理过程的详细介绍:
4.1.1 模型结构
- 音频编码器 :默认使用 HTSAT(Hierarchical Token - Semantic Audio Transformer)作为音频编码器。HTSAT 是一种层次化的音频 Transformer 模型,能够有效地处理不同长度的音频输入,可将音频信号编码为固定维度的向量表示(本文还对比了PANN)。
- 文本编码器:通常采用 BERT 或其变体作为文本编码器,将文本转换为固定维度的向量表示,捕捉文本中的语义信息(本文还对比了CLIP和RoBert)。
- 投影层:将音频编码器和文本编码器输出的特征映射到相同的潜在空间,使音频和文本特征处于同一维度空间,便于后续计算相似度。
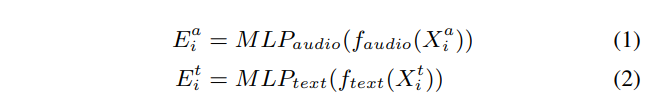
4.1.2 推理过程
- 数据准备:获取待处理的音频数据和文本数据。音频数据通常需要先转换为对数 Mel 频谱图等合适的格式,这是音频处理中常见的表示形式,能更好地捕捉音频的频率特征。
- 特征提取:将处理后的音频数据输入音频编码器,音频编码器提取音频特征,生成音频向量表示;同时,将文本数据输入文本编码器,文本编码器提取文本特征,生成文本向量表示。
- 投影映射:音频向量和文本向量分别通过投影层,映射到同一个潜在空间中,得到具有相同维度的音频嵌入和文本嵌入。
- 相似度计算:计算投影后的音频嵌入和文本嵌入之间的相似度,通常使用点积作为相似分数。该分数反映了音频和文本之间的语义关联程度,相似度越高,说明音频和文本的匹配度越高。
- 结果输出 :根据计算得到的相似度分数,可用于不同的下游任务。
- 例如在文本 - 音频检索任务中,可根据文本查找最相关的音频,或根据音频查找最匹配的文本描述;
- 在零样本音频分类任务中,可将输入音频与多个候选文本标签进行相似度计算,根据相似度分数将音频分类到最相关的标签类别下,也可以使用输出的embedding加一层MLP进行微调然后分类。
4.2 音频编码器与文本编码器
4.2.1 音频编码器:
两种模型构建:
- PANN :基于 CNN 的音频分类模型,含 7 个下采样 CNN 块和 7 个上采样块;
- HTSAT:基于 Transformer 的模型,含 4 组 Swintransformer 块,在三个音频分类数据集上达到最先进水平(SOTA)。
均使用**其倒数第二层的输出(一个L维向量)**作为输入发送至投影 MLP 层,
- PANN维度=2048
- HTSAT维度=768
4.2.2 文本编码器
选用三种模型:
- CLIP transformer (CLIP 的文本编码器),维度=512
- BERT ,维度=768
- RoBERTa ,维度=768
4.2.3 维度映射
最后我们对音频和文本输出均应用含 ReLU 激活函数的2层MLP,将其映射到 512 维(对比学习训练中音频 / 文本表征的维度)。
4.3 可变长度音频的特征融合
与可调整为统一分辨率的 RGB 图像不同,音频天然具有可变长度。
传统方法:
- 通常将完整音频输入编码器,然后对每帧或每块的音频嵌入取平均(即 "切片与投票"),但这种方法对长音频的计算效率较低。
我们怎么做:
- 如图 1 左侧所示,通过结合粗略的全局信息和随机采样的局部信息,在固定计算时间内对不同长度的音频输入进行训练和推理。对于时长为T秒的音频,设定固定块时长\(d=10\)秒:
- 若T<d,先重复输入,再用零值填充。例如,3 秒的输入会重复为 3×3=9 秒,再填充 1 秒零值;
- 若T>d,先将输入从T秒下采样为d秒作为全局输入;然后从输入的前 1/3、中间 1/3 和后 1/3 部分各随机切取 1 个d秒的片段作为局部输入。将这 4 个d秒的输入送入音频编码器的第一层以获取初始特征,随后通过一个在时间轴上步长为 3 的 2D 卷积层,将 3 个局部特征转换为 1 个特征。最终,局部特征与全局特征融合为:
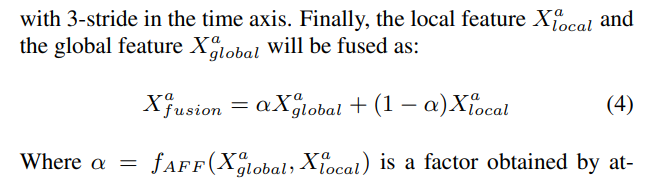
4.4 关键词到描述的增强
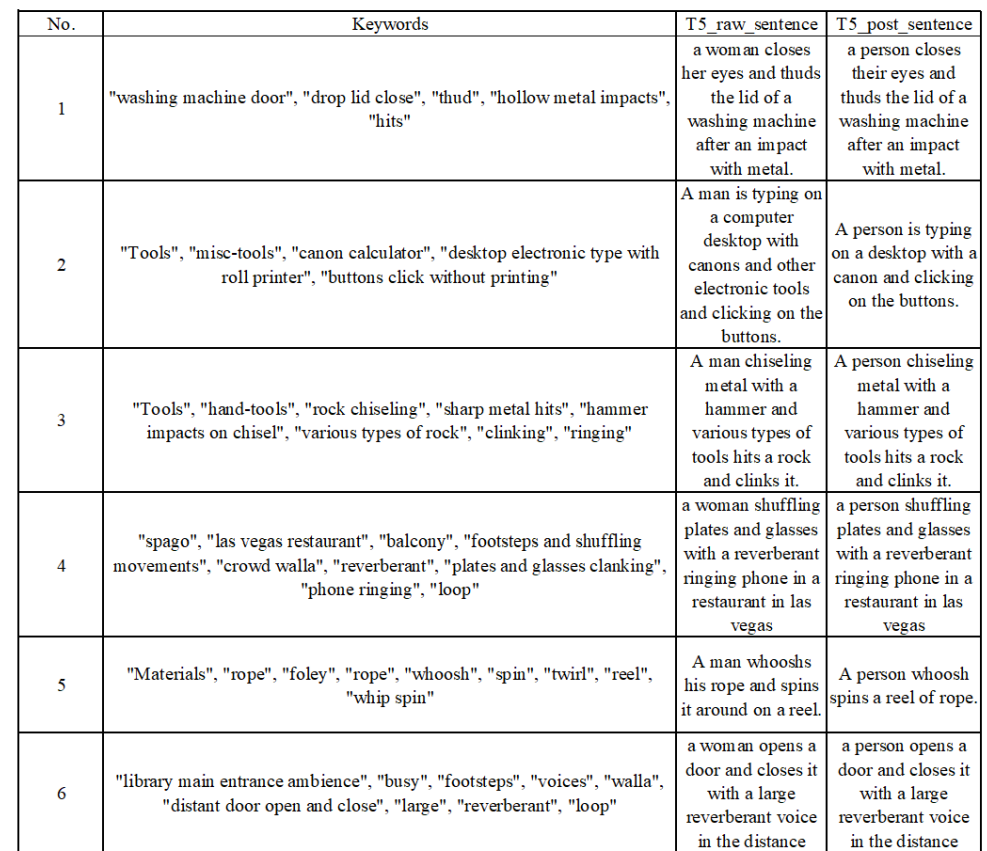
部分数据集包含与音频对应的合理标签或关键词作为关键词。
- 使用预训练语言模型 T5 基于这些关键词生成描述文本,并对输出句子进行后处理以消除偏差。例如,将 " woman " 和 " man " 替换为 " person " 以消除性别偏差。由于篇幅限制,增强示例详见在线附录。
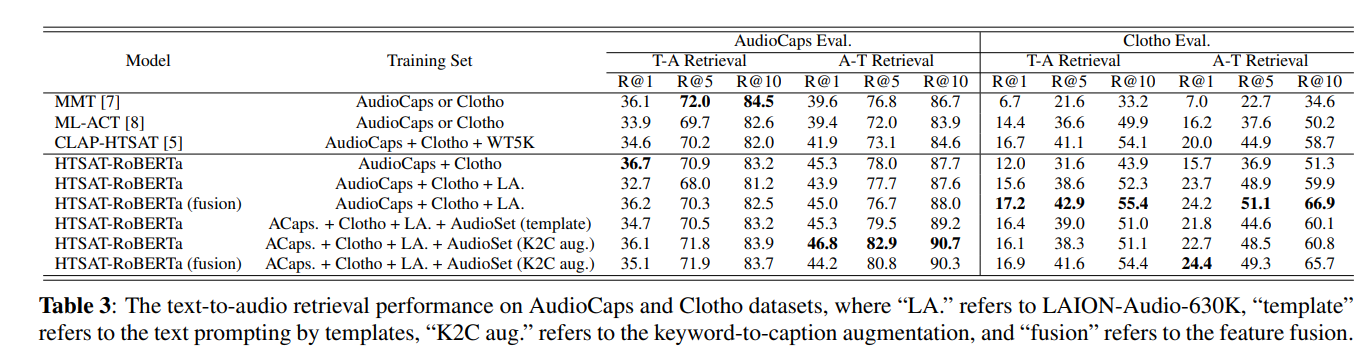
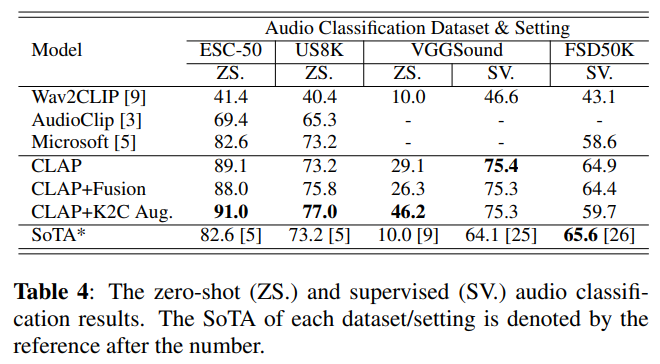
五、Experiments
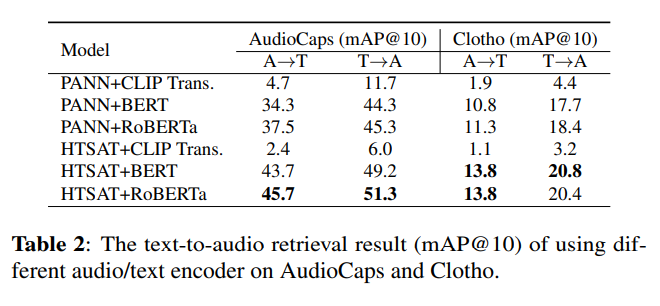
注意不同的编码器的指标: