文章作者:尚志忠
编辑整理:曾辉
行业背景
随着大数据、云计算、5G、人工智能等技术的快速发展,以及医疗信息化建设的不断深入,数据中台作为打通医疗数据融合壁垒、实现数据互通与共享、构建高效数据应用的关键信息平台,正逐渐成为推动医疗行业数字化转型和创新发展的重要力量。

星海·济世医疗数据中台介绍
中国电信依托多年行业积累,定制打造医疗行业数据中台,以夯实卫生健康信息化新基建能力为目标,赋能行业客户,深化数据集成治理与开发应用能力,推进健康医疗大数据应用发展,充分释放数据价值。
星海·济世医疗数据中台以"湖仓一体、流批一体"技术为核心,围绕健康医疗数据在集成、存储、治理、建模、分析、挖掘、服务、应用、流通等各个环节的需求,构建数据全生命周期管理的能力平台。
关于数据处理中任务调度的思考
在医疗行业的数据处理过程中,存在着以下常见的问题:
-
复杂的数据处理逻辑与流程未能实现统一的管理和调度,数据处理流程长,依赖关系错综复杂,不易于维护和使用,同时影响工作效率,间接提高了使用数据的成本。
-
传统的调度工具支持的组件有限,不能满足在医疗行业中多场景多种异构数据源的数据处理和使用,且各种数据处理逻辑和关系不能够可视化管理,只依赖脚本和定时任务不足以支撑目前的业务发展,不能可视化的反应任务之间的依赖关系,增加了业务处理的复杂性。
-
多系统之间的定时任务缺乏统一的调度机制,这些任务可能由不同系统的不同团队开发和维护,导致资源浪费和运维成本上升。缺乏统一的调度平台,使得运维人员需要手动监控和管理这些任务。
基于任务调度和管理相关的以上问题,我们认为一个平台级的产品必要要有一款优秀的调度工具,不仅要具备基于时序的主动触发能力和基于事件的被动触发能力,同时要能够支持丰富的组件方便数据处理任务的开发,还需要具备运行时监控能力和分布式的架构下资源调度及均衡能力。
经过不断的学习和探索使用发现Apache DolphinScheduler 调度器在处理以上问题的过程中,有明显的优势。
技术特点及优势
技术特点
Apache DolphinScheduler 是一个分布式易扩展的带有强大可视化 DAG 界面的新一代工作流调度平台 ,立项之初即确立了使命 ------ "解决大数据任务之间错综复杂的依赖关系,使整个数据处理过程直观可见",至此配置工作流程无需代码即可完成!
作为强大的DAG可视化界面的分布式大数据工作流调度平台,Apache Dolphin Scheduler 解决了复杂的任务依赖关系和简化了数据任务编排的工作。
它以开箱即用的、易于扩展的方式将众多大数据生态组件连接到可处理 100,000 级别的数据任务调度系统中来。
其整体特征如下:
(1)云原生设计:支持多云、多数据中心的跨端调度,同时也支持K8s Docker部署与扩展,性能上可以线性增长,在用户测试情况下最高已经支持10万的并行任务控制;
(2)高可用、高稳定性:去中心化的多Master/Worker的架构,可以自动任务平衡,自动高可用,确保任务在任何节点死机的情况下可以具有完整性完成整体调度;
(3)用户界面友好:可视化的DAG图,包括子任务,条件调度、脚本管理、多租户等方便功能,并具有让运行任务实例与任务模板分开,让你的平台维护人员和数据科学家都有一个方便易用的开发和管理平台;
(4)支持多种数据场景:支持流数据处理,批数据处理,暂停、回复、多租户等,对于spark,hive,MR,flink,clickhouse等等平台都可以方便直接调用;
(5)支持多种调度机制:任务调度机制,支持时间触发,包括定时触发、循环触发、间隔触发;事件触发机制,支持前置触发和后置触发;
(6)支持数据分析、可视化的监控功能、完善的告警模块。
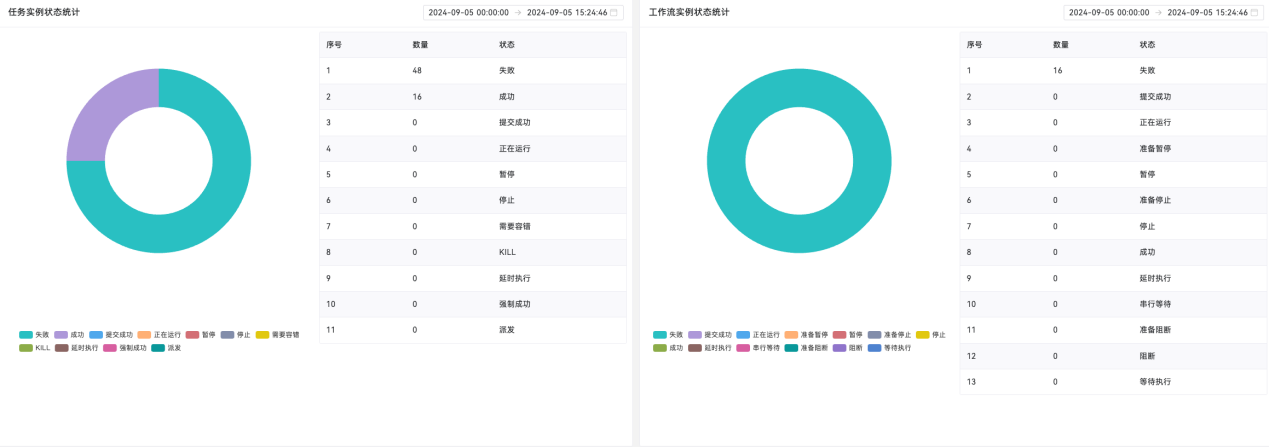
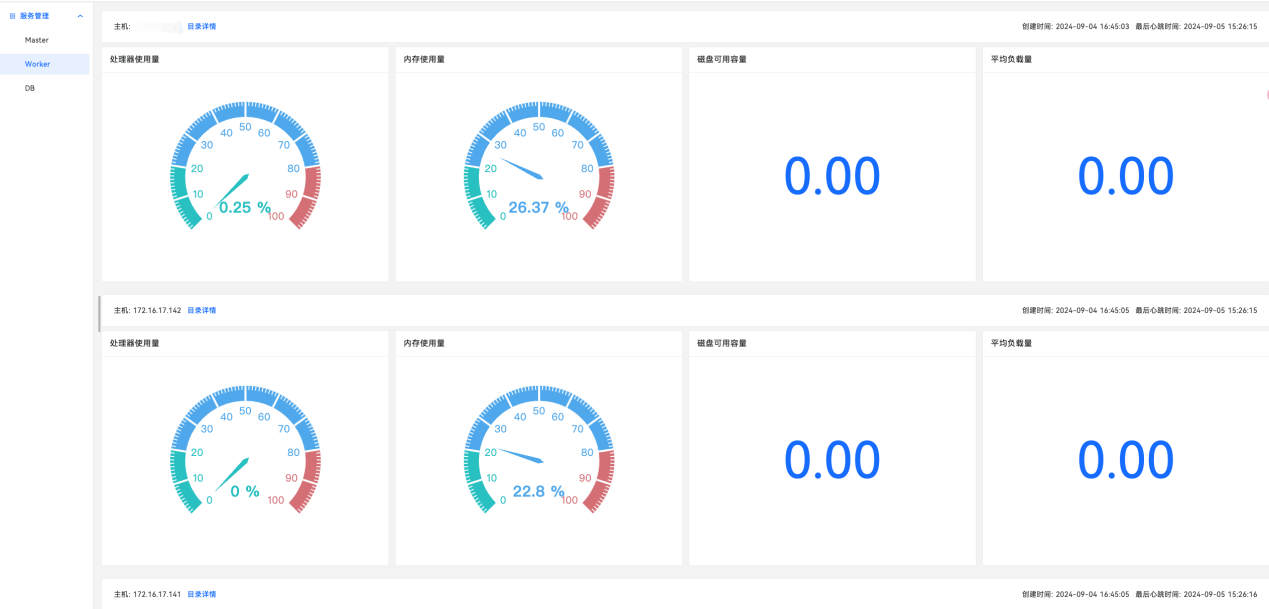
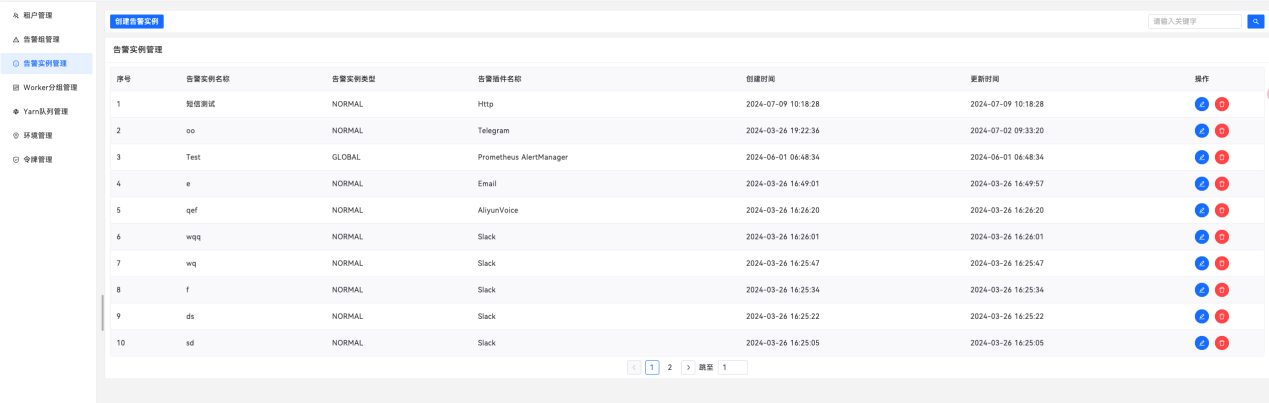
技术优势
首先,Apache Dolphinscheduler调度系统的本质是满足用户使用其进行做调度的需求,其最大的优势在于方便、简易、美观,这使得即使是不懂代码的人也能使用它进行调度操作。
这一点使得Dolphinscheduler调度系统在众多调度系统中脱颖而出,成为用户优选的原因之一。
其次,海豚调度作为开源项目,其成功得益于全球顶尖人才的参与和贡献。开源模式打破了公司和组织的边界,甚至国家和国家的边界,使得全球最顶尖的架构师、开发者等能够组织到一起,共同为项目贡献力量。这种模式凝聚了全球最顶尖的人才的想法,使得项目能够持续多年,并且帮助更多的人,而不仅仅是为了某一家公司的盈利或发展。
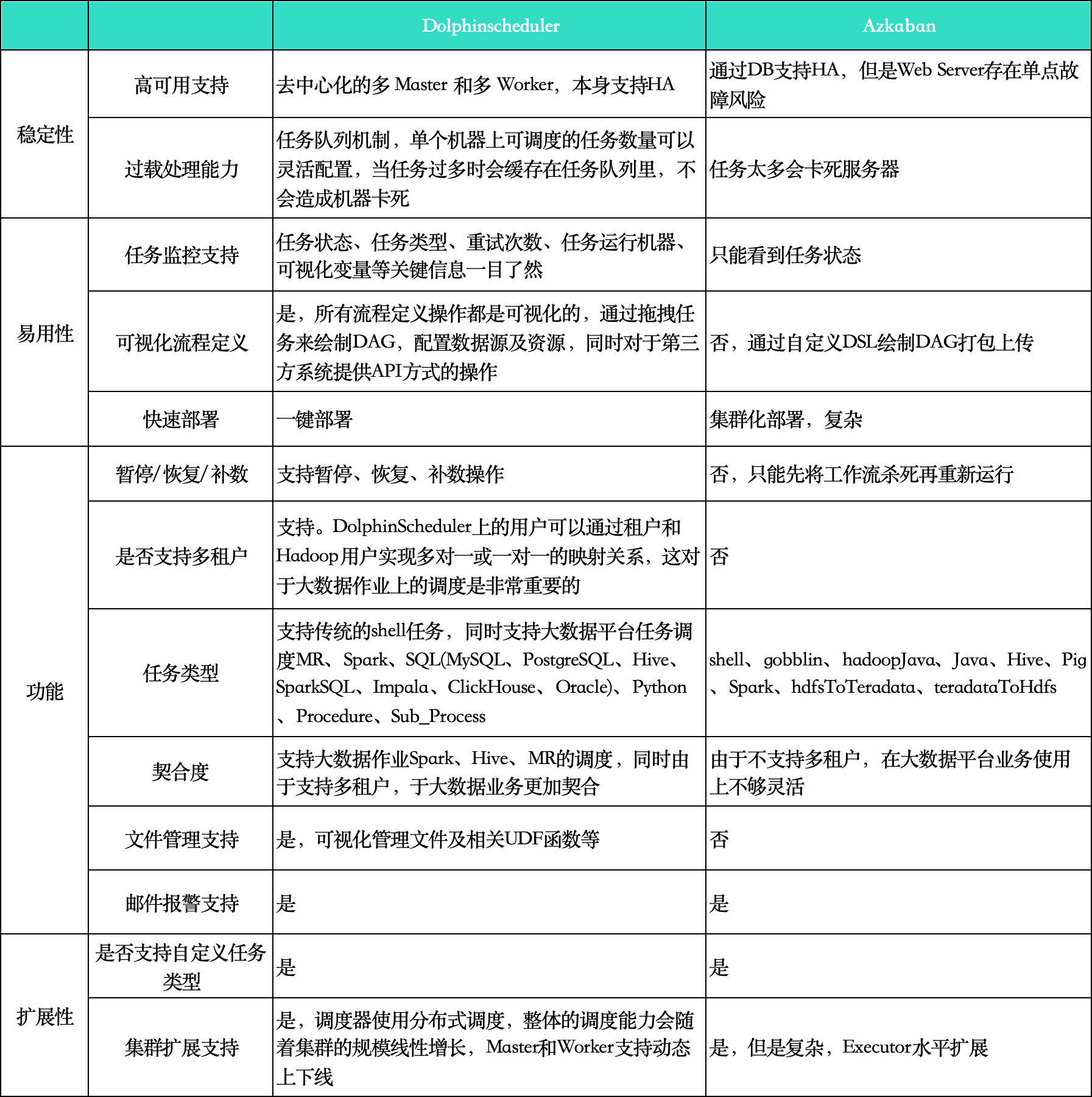
再次,我们将Apache DolphinScheduler和原本采用的系统调度器Azkaban进行了对比,发现Azkaban中的缺点不可忽视,如无可视化界面、任务调度多时易卡死、部署复杂、无法暂停任务、集群扩展差等。
对比如下:
用海豚做什么:
-
用海豚实现对指标计算程序的定时调度:编写java程序实现指标计算功能,采用海豚可以灵活的传递主程序参数,满足计算程序多维度数据处理,操作可视化。
-
对复杂关联查询的关联脚本进行定时调度:海豚支持流式方式组装任务,满足了多表多条件复杂查询串联执行,可以及时监控任务的执行状态,支持重试、指定节点恢复失败、暂停、恢复、终止任务等操作。
综上所述,选择Apache Dolphinscheduler调度的原因不仅在于其用户友好、易于使用的特点,还在于其作为一个开源项目所具有的全球顶尖人才的参与和贡献,这些因素共同使得Dolphinscheduler调度成为一个值得选择的调度系统。
生产实践
二次开发
我们在使用Apache DolphinScheduler时,经过各种场景的试用和测试,升级了用户体系,重构了项目级参数功能,优化了用户体验,修改了调度Java任务的异常问题。
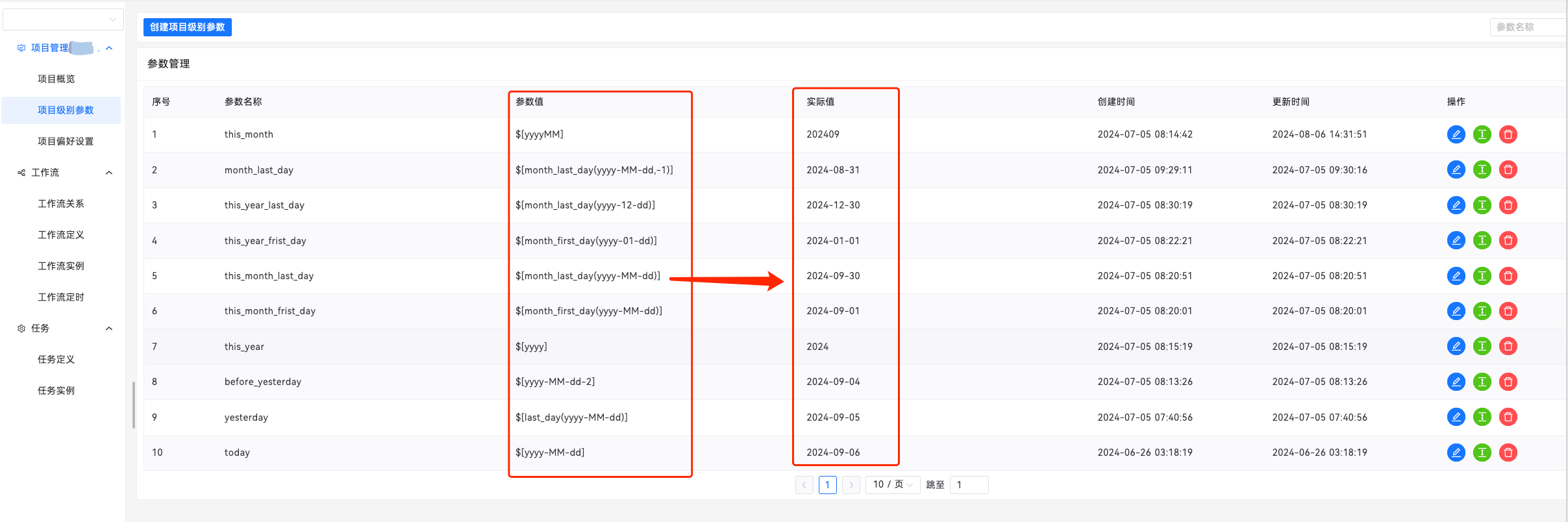
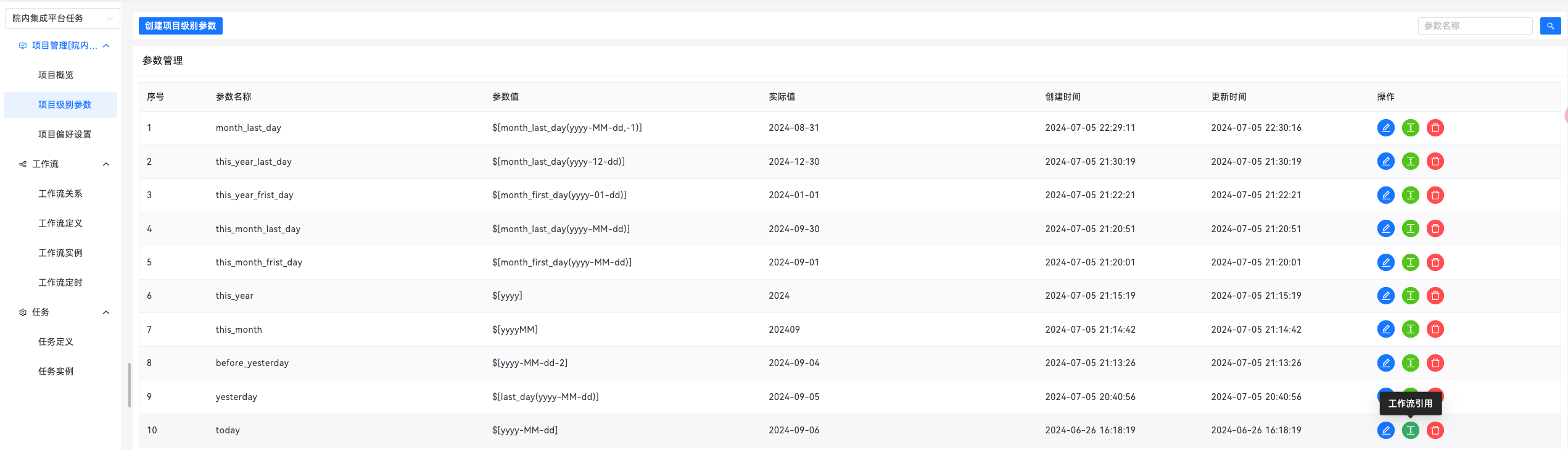
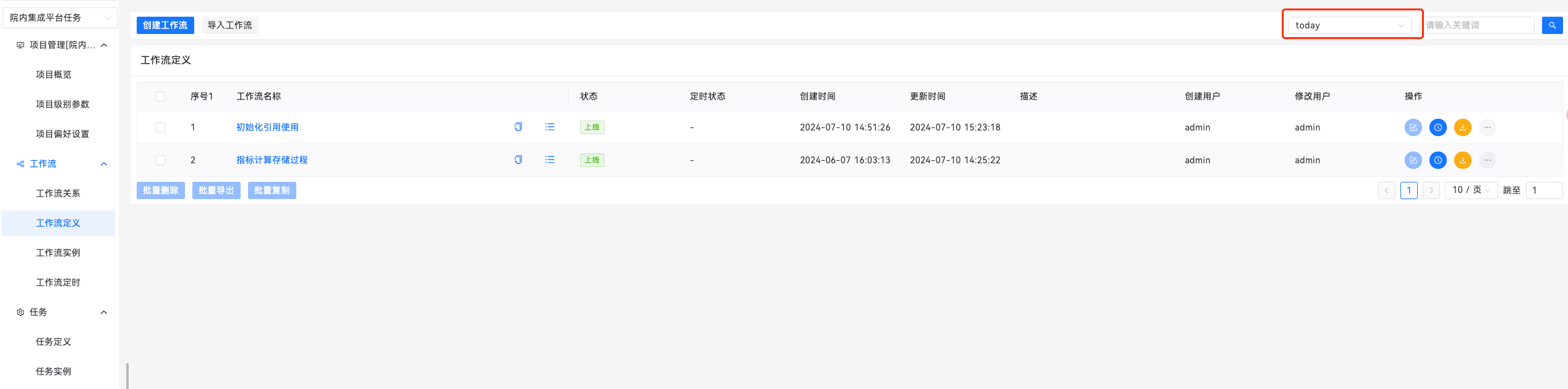
1、项目级别变量
动态扩展项目中项目级别参数的使用,并在列表中对对应的参数的实际值进行展示等,同时可以根据项目参数的名称对引用了该参数的工作流进行查询跳转。
2、Java类任务
该类任务,支持使用单文件和JAR包作为程序入口。
点击项目管理 -> 项目名称 -> 工作流定义,点击"创建工作流",进入DAG编辑页面;
拖动工具栏的JAVA任务节点到画板中。
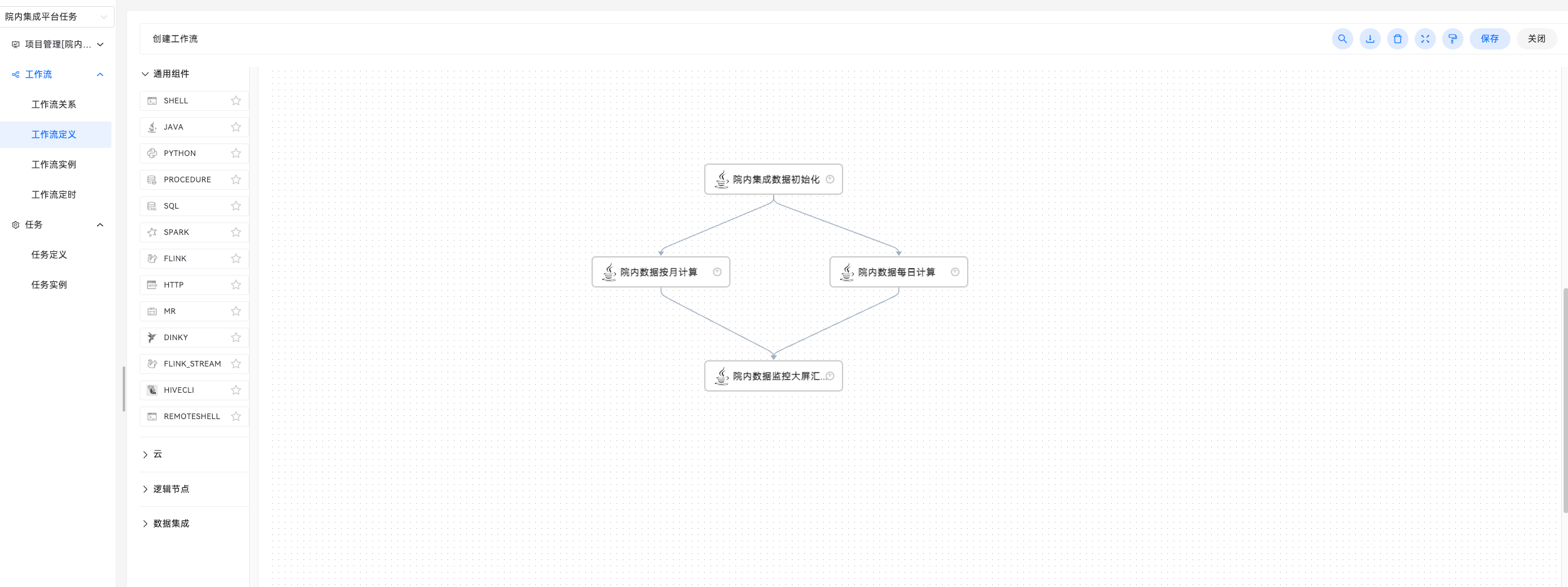
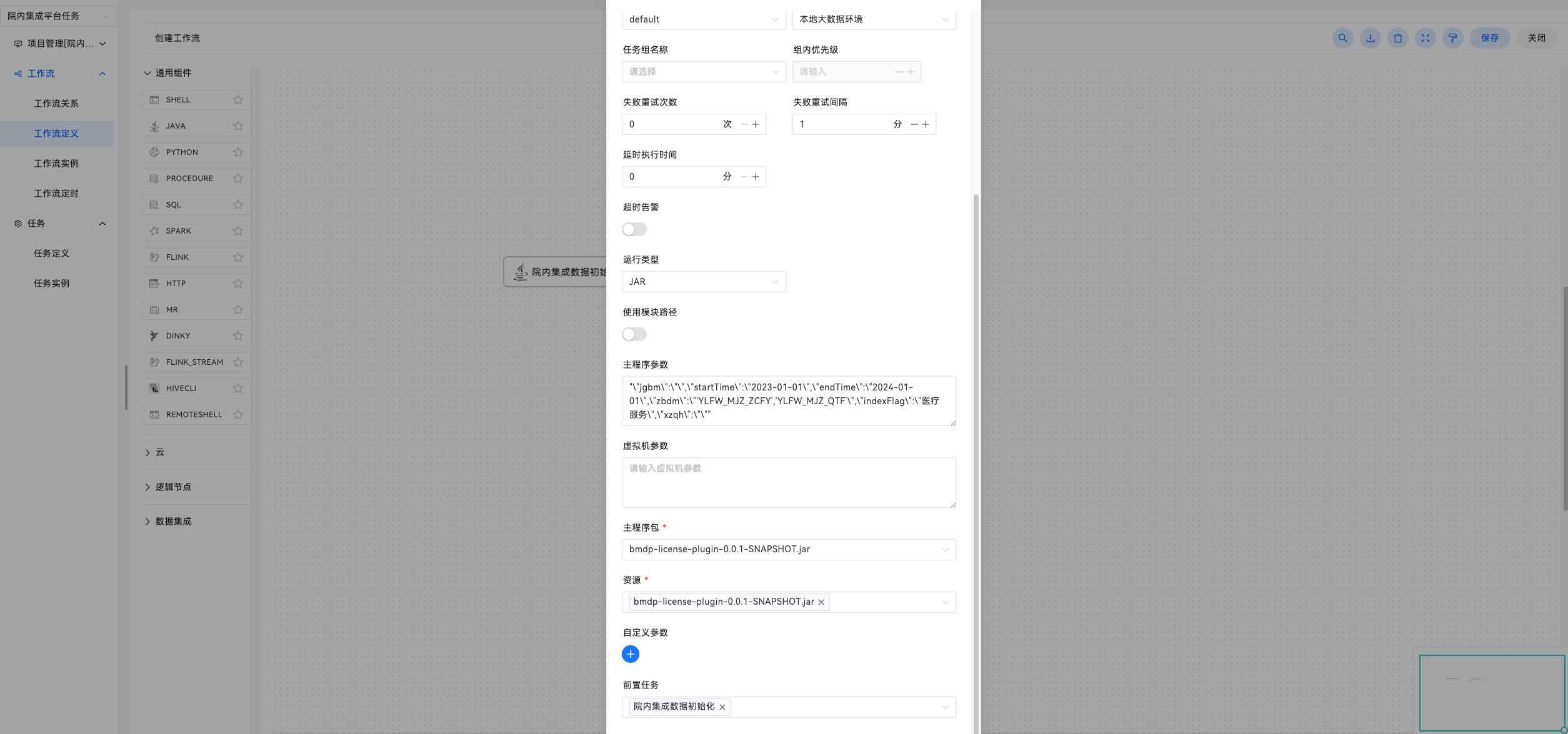
主程序参数:作为普通JAVA程序main方法入口参数;
虚拟机参数:配置启动虚拟机参数;
脚本:若使用JAVA运行类型则需要编写JAVA代码,代码中必须存在Public类,不用写Package语句;
资源:可以是外部JAR包,也可以是其他资源文件,他们会被加入到类路径或模块路径中。
3、个性化界面
按照用户操作习惯,我们重新定制了操作相关的按钮,以及按钮较多时收起、展开;
在项目管理界面,可以动态选择需要的项目包,在无需返回到项目管理首页重新选择项目。
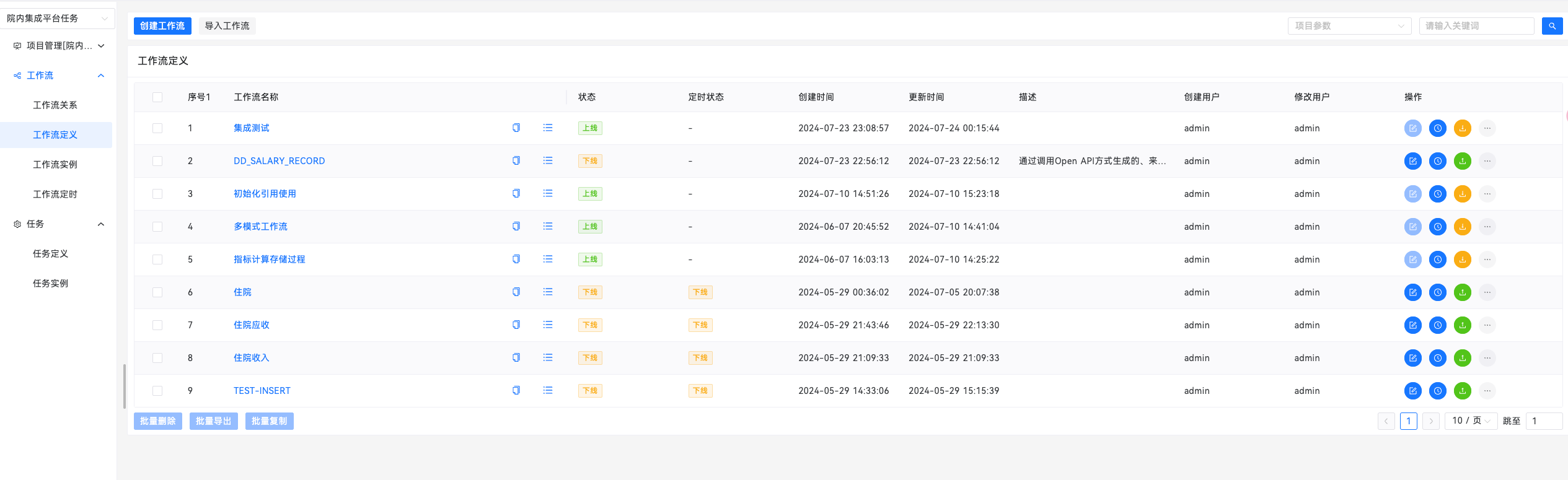
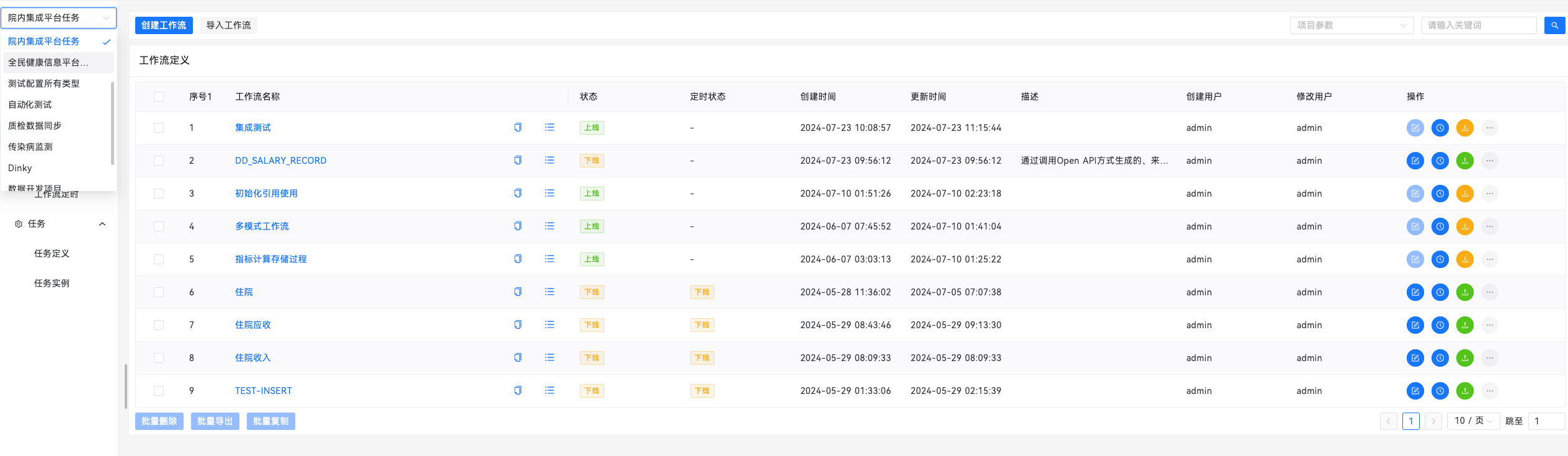
项目实践
使用Apache DolphinScheduler 之后,我们根据实际业务需要进行二次开发之后,很好的解决了一些需求,下列简述其中几个场景:
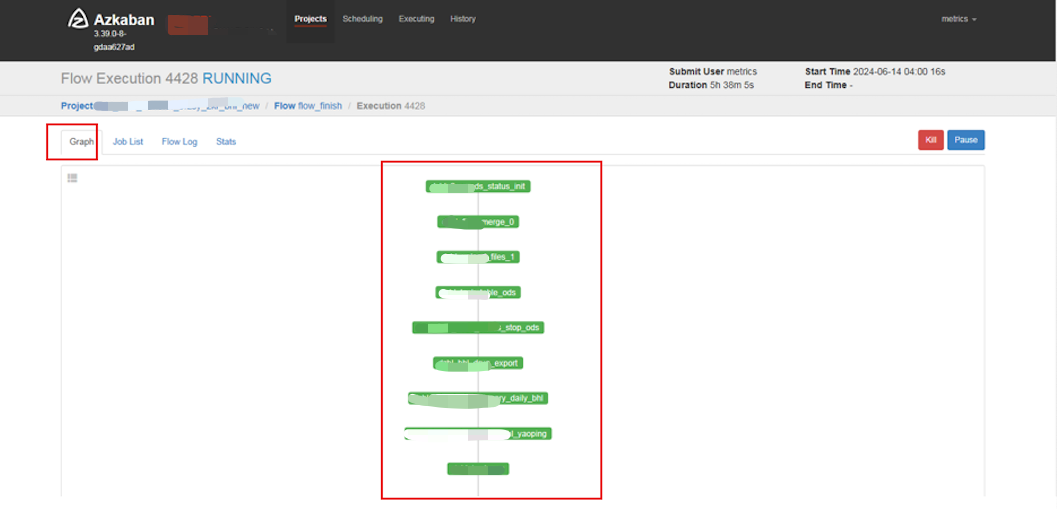
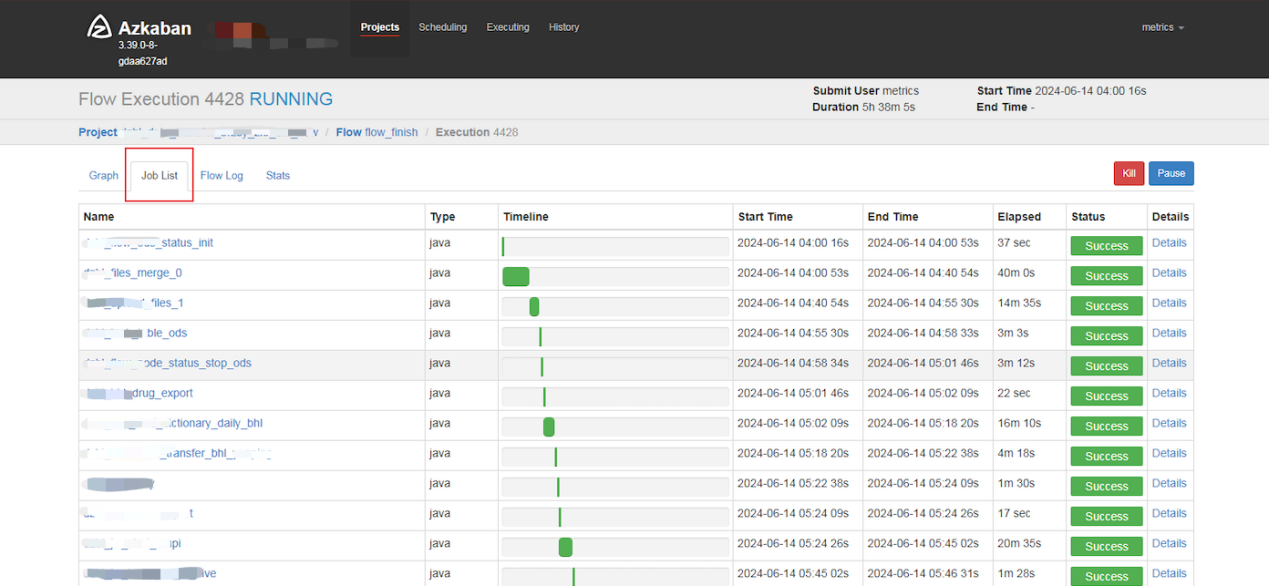
1、将原有Azkaban中的调度任务平行迁移到DolphinScheduler中
Azkaban中流程示例:
平行迁移到Apache DolphinScheduler中示例:
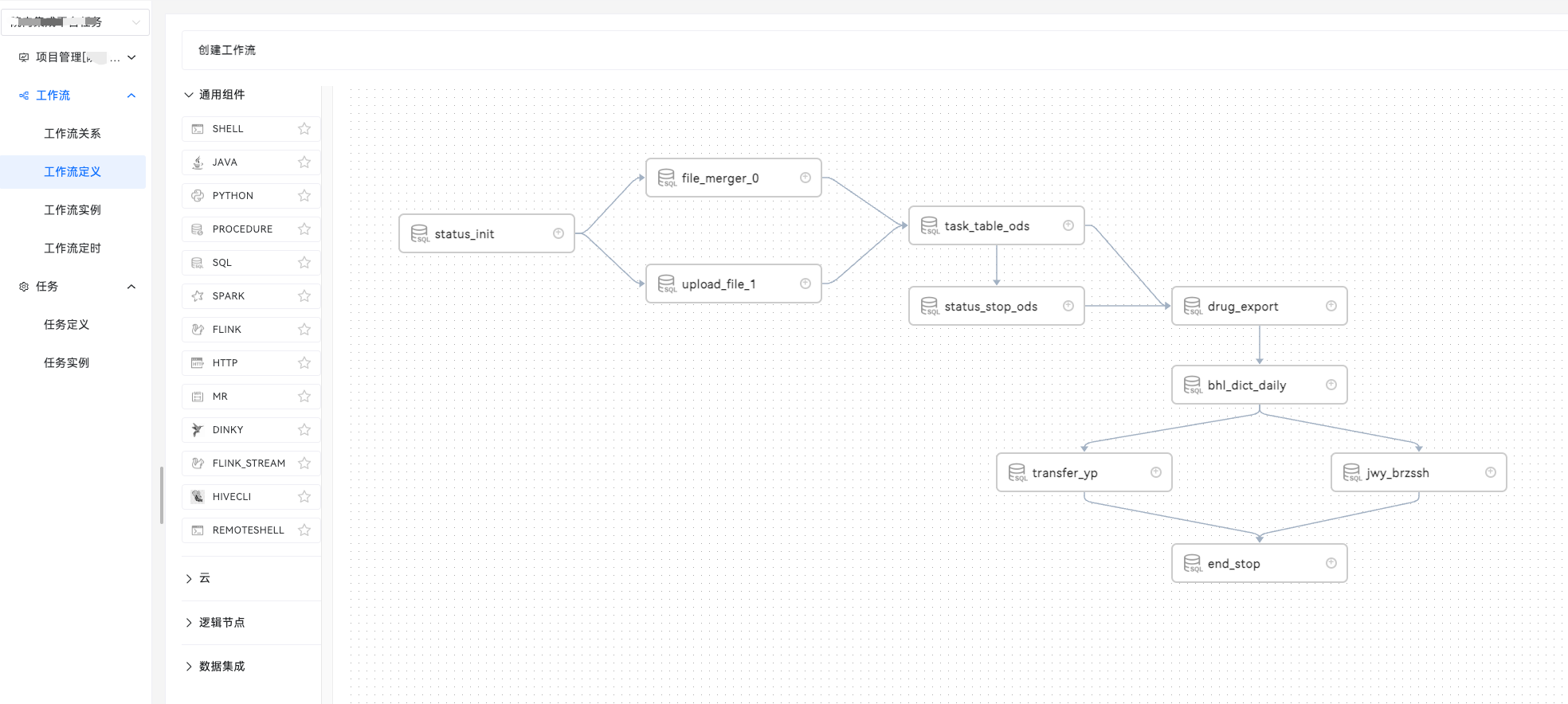
2、对于数据源模块,动态扩展了从第三方倒入数据源,增加了数据源的可用性
解决了指标计算程序定时调度问题,使用海豚调度可以灵活传递计算程序需要的参数并在调度过程打印相应日志方便跟踪排查问题。
解决了多个复杂的关联查询串联执行时中途被阻断导致的整个全流程失败问题,海豚调度可以在失败的节点重新跑流程,不需要再将成功的节点再重跑一次导致服务器资源过度占用 的问题,解决了Flink批流作业被动触发的问题。
在公司项目的生产过程中目前已实现日均1000+的任务被调度处理,包含了4条产品线的20多个业务系统,离线开发的任务多半已迁移在Apache DolphinScheduler进行配置,极大的提升了数据开发人员的研发效率,方便数据开发人员维护工作。
后期发展计划
在日常的运维工作还存在一些问题,主要包括任务失败的及时告警、多项目任务的巡检及对任务完成情况的准确把握等问题。
针对上述问题,计划实施一系列的自动化运维措施,需实现自动化推送功能,每天定时的将生产调度的报告发送到企业微信群中,包括所有任务的执行情况,成功、失败的具体情况;
对失败的任务,增强告警机制,确保任务出现问题是能够及时通知运维团队,并作出迅速的响应和处理。
未来愿景
我们团队对于 Apache DolphinScheduler 的未来愿景主要体现在以下几个方面:
- 云原生支持增强
期望Apache DolphinScheduler 进一步增强对云原生环境的支持,在生产环境可使用worker 自动扩缩容特性。
- 异构数据源的Join 组件扩展
异构数据源之间的Join组件能极大的提升数据开发的能力和效率,能解决复杂数据任务之前同步数据的一致性问题。
Apache DolphinScheduler 的未来必然能构建一个更加强大、灵活、易用和可靠的开源调度系统,以满足用户对数据处理和调度的复杂需求,推动数据处理技术的发展和进步,希望社区越来越好!
本文由 白鲸开源科技 提供发布支持!