💕💕作者:计算机源码社
💕💕个人简介:本人八年开发经验,擅长Java、Python、PHP、.NET、Node.js、Spark、hadoop、Android、微信小程序、爬虫、大数据、机器学习等,大家有这一块的问题可以一起交流!
💕💕学习资料、程序开发、技术解答、文档报告
💕💕如需要源码,可以扫取文章下方二维码联系咨询
💕💕Java项目
💕💕微信小程序项目
💕💕Android项目
💕💕Python项目
💕💕PHP项目
💕💕ASP.NET项目
💕💕Node.js项目
💕💕大数据项目
💕💕选题推荐
项目实战|基于大数据的家庭能源消耗数据分析与可视化系统源码
文章目录
1、研究背景
随着全球能源需求的不断增长和环境问题的日益严峻,家庭能源消耗的管理和优化成为了一个重要的课题。传统的能源管理方式往往缺乏对家庭能源消耗的精确分析和实时监控,导致能源浪费和效率低下。为了应对这一挑战,基于大数据的家庭能源消耗数据分析与可视化系统应运而生。该系统利用Python、大数据、Spark、Hadoop等先进技术,结合Vue、Echarts等前端可视化工具,以及MySQL数据库,实现了对家庭能源消耗数据的高效收集、存储、分析和展示。通过数据挖掘和机器学习算法,系统能够深入挖掘家庭能源消耗的模式和规律,为家庭能源管理提供科学依据。
2、研究目的和意义
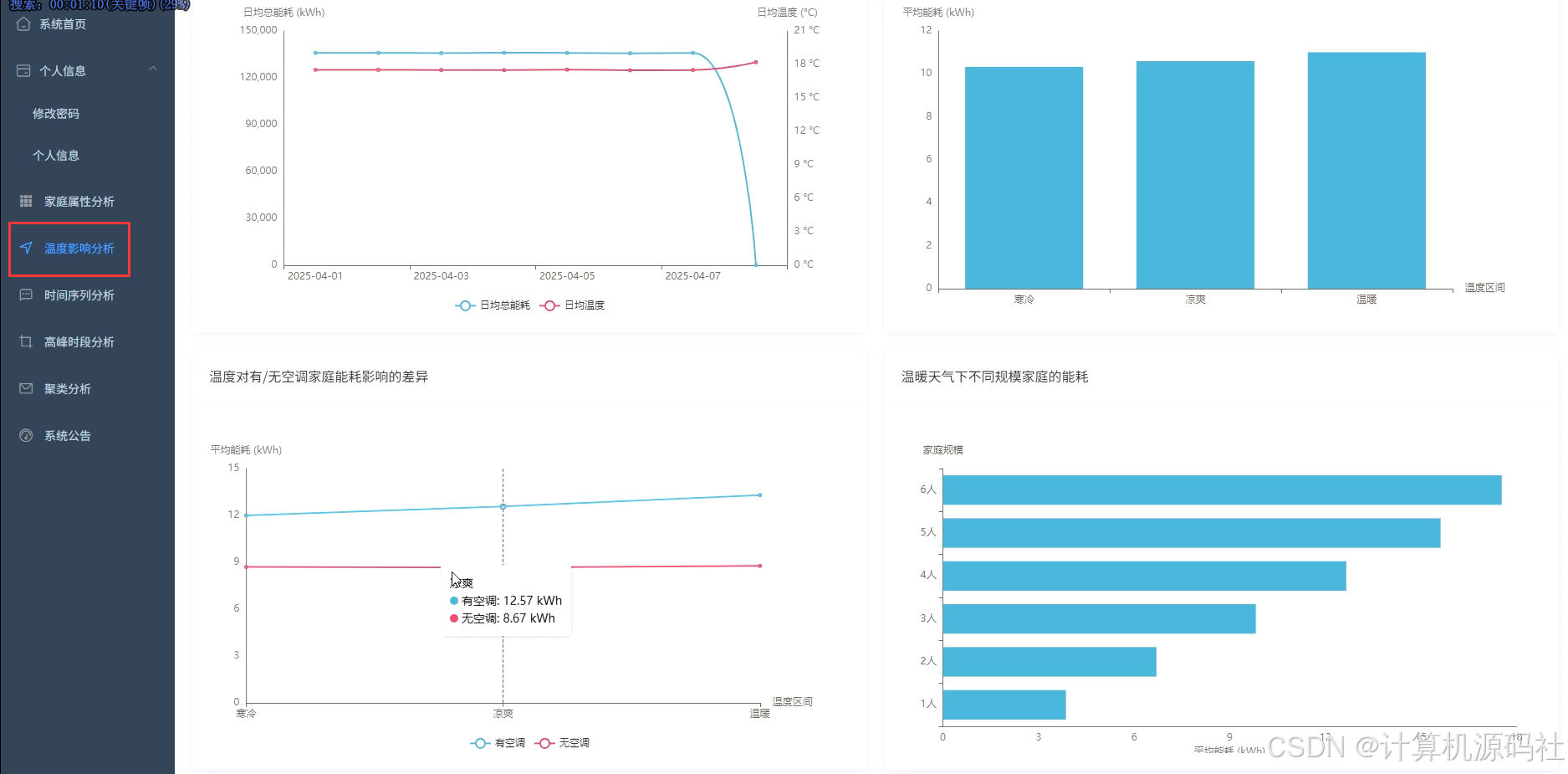
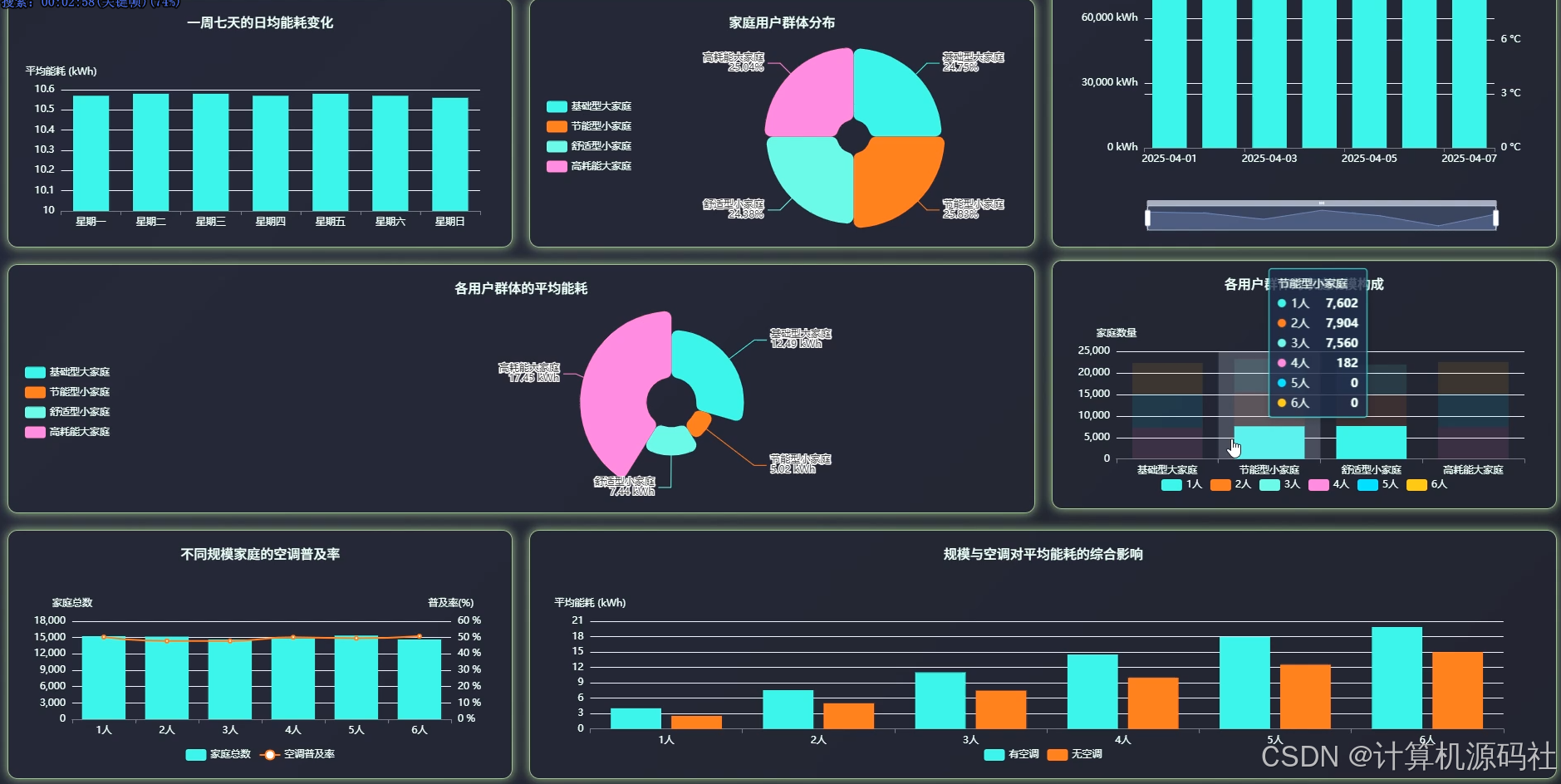
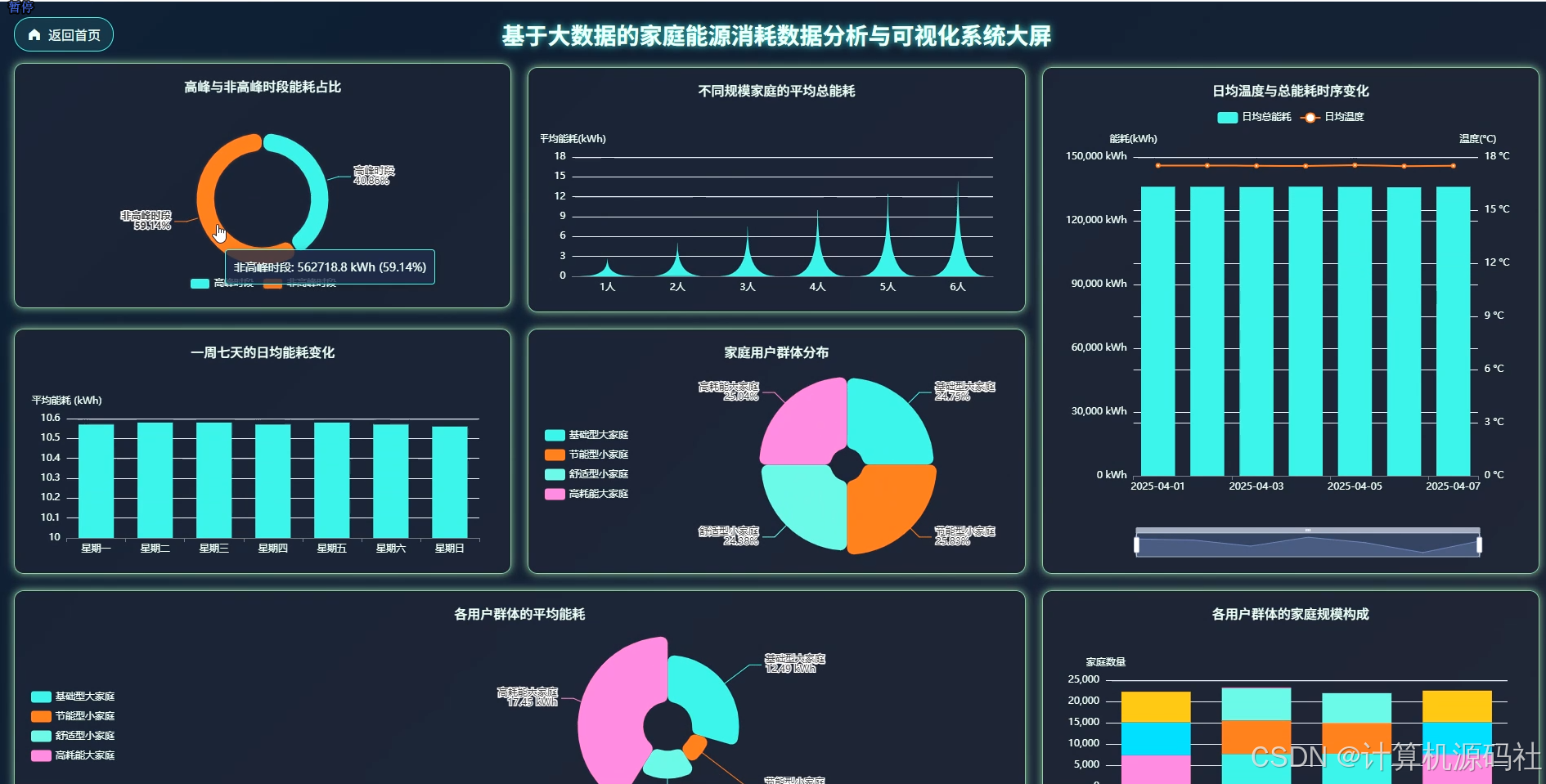
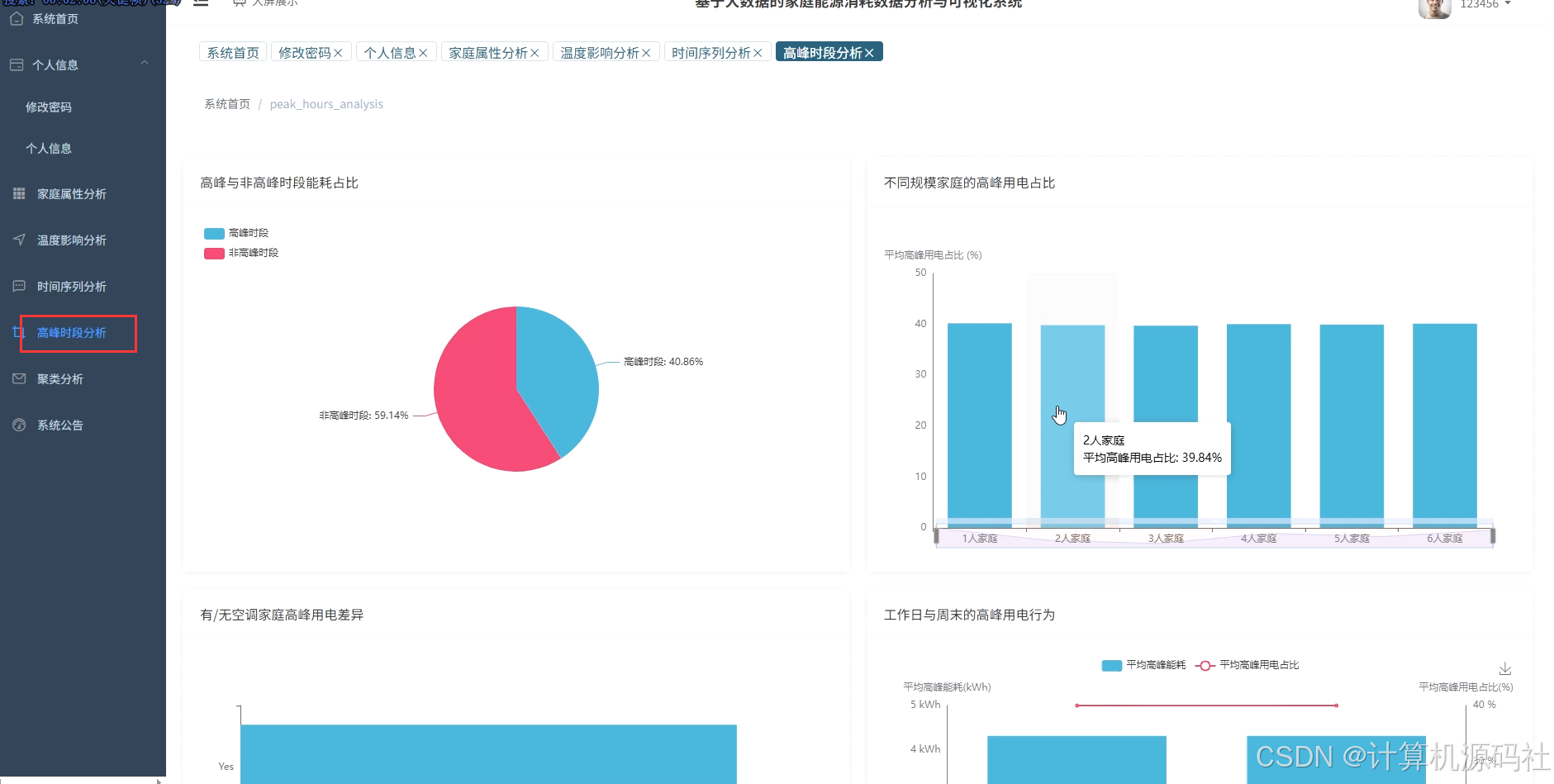
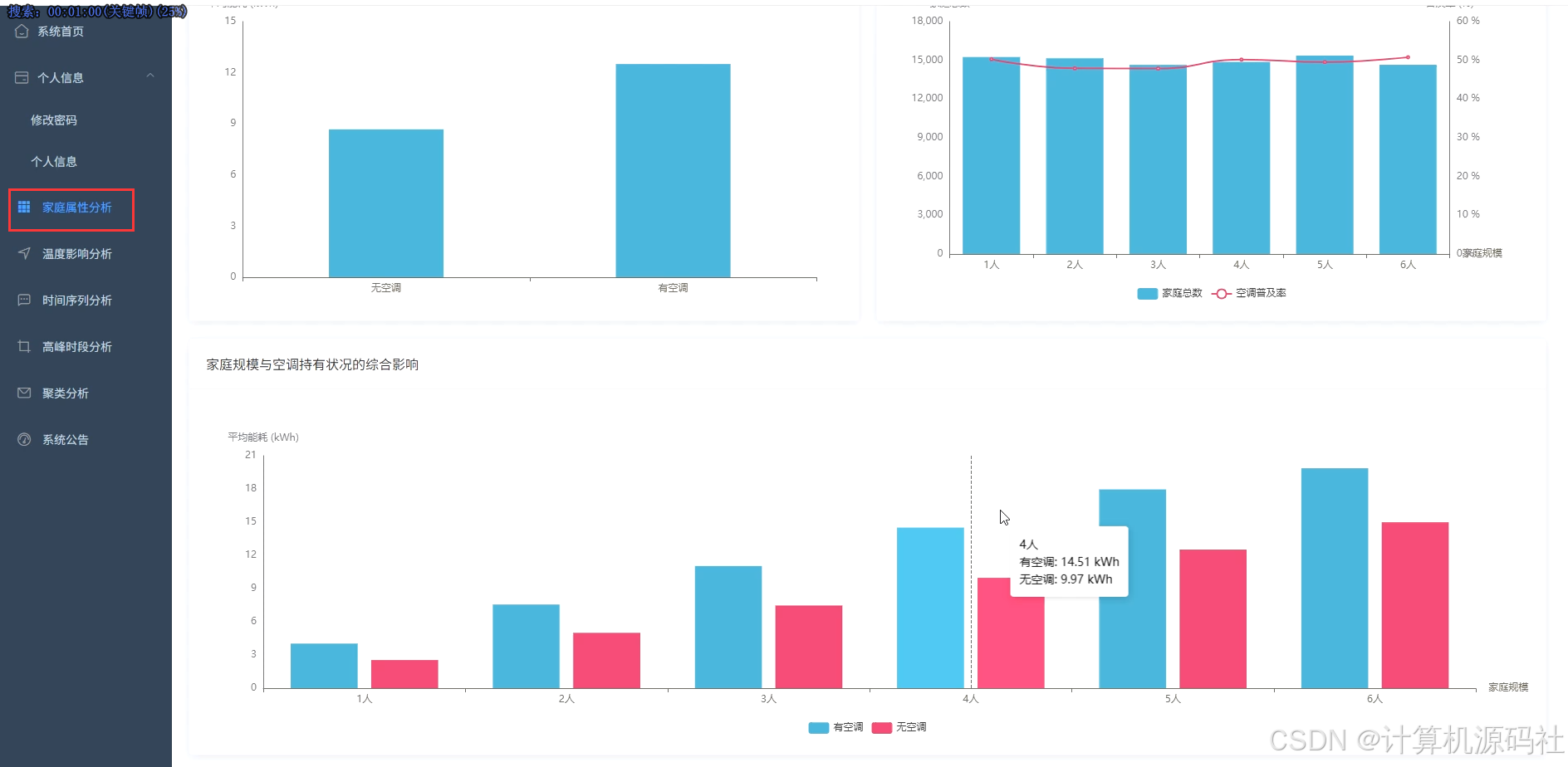
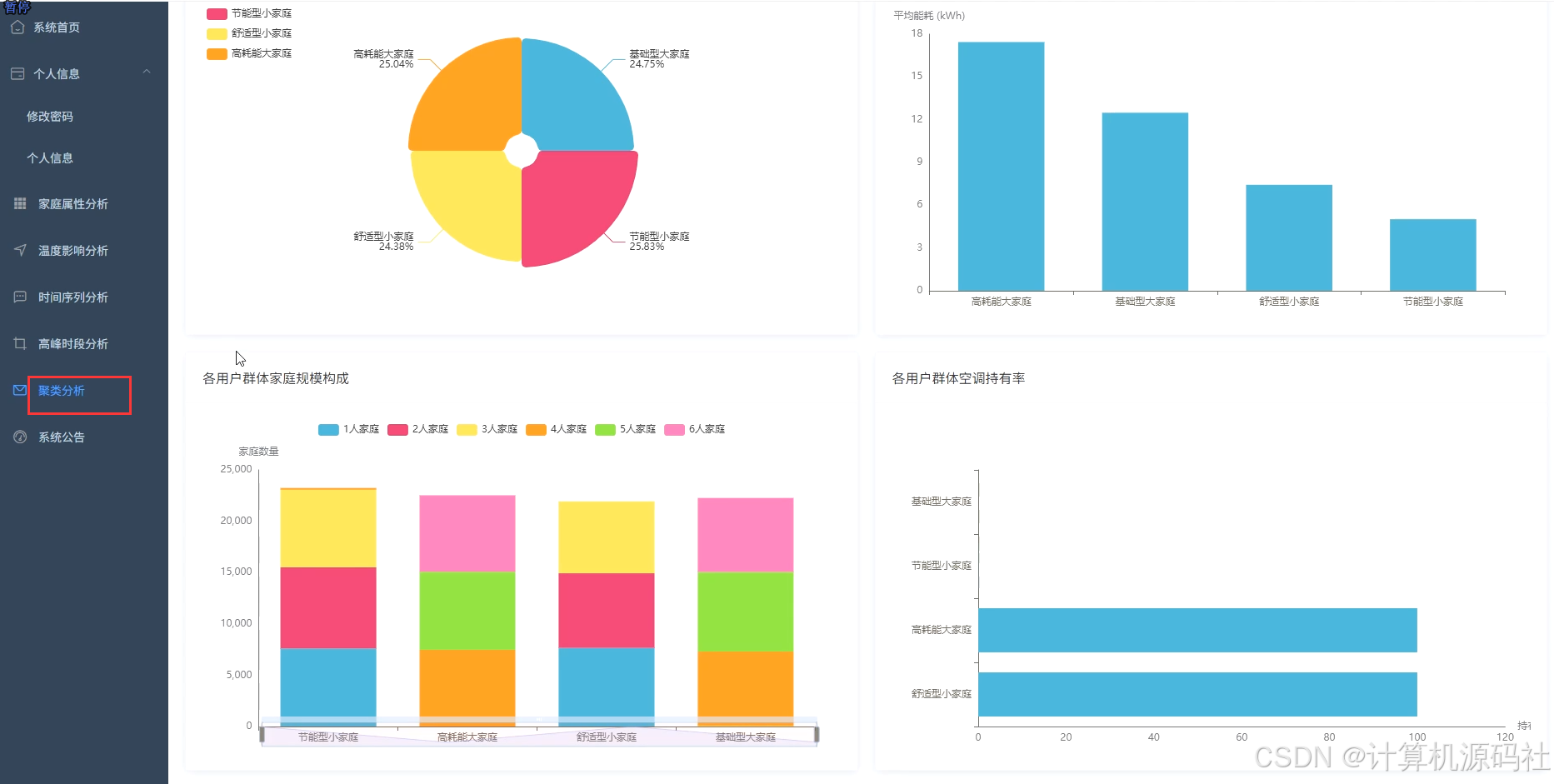
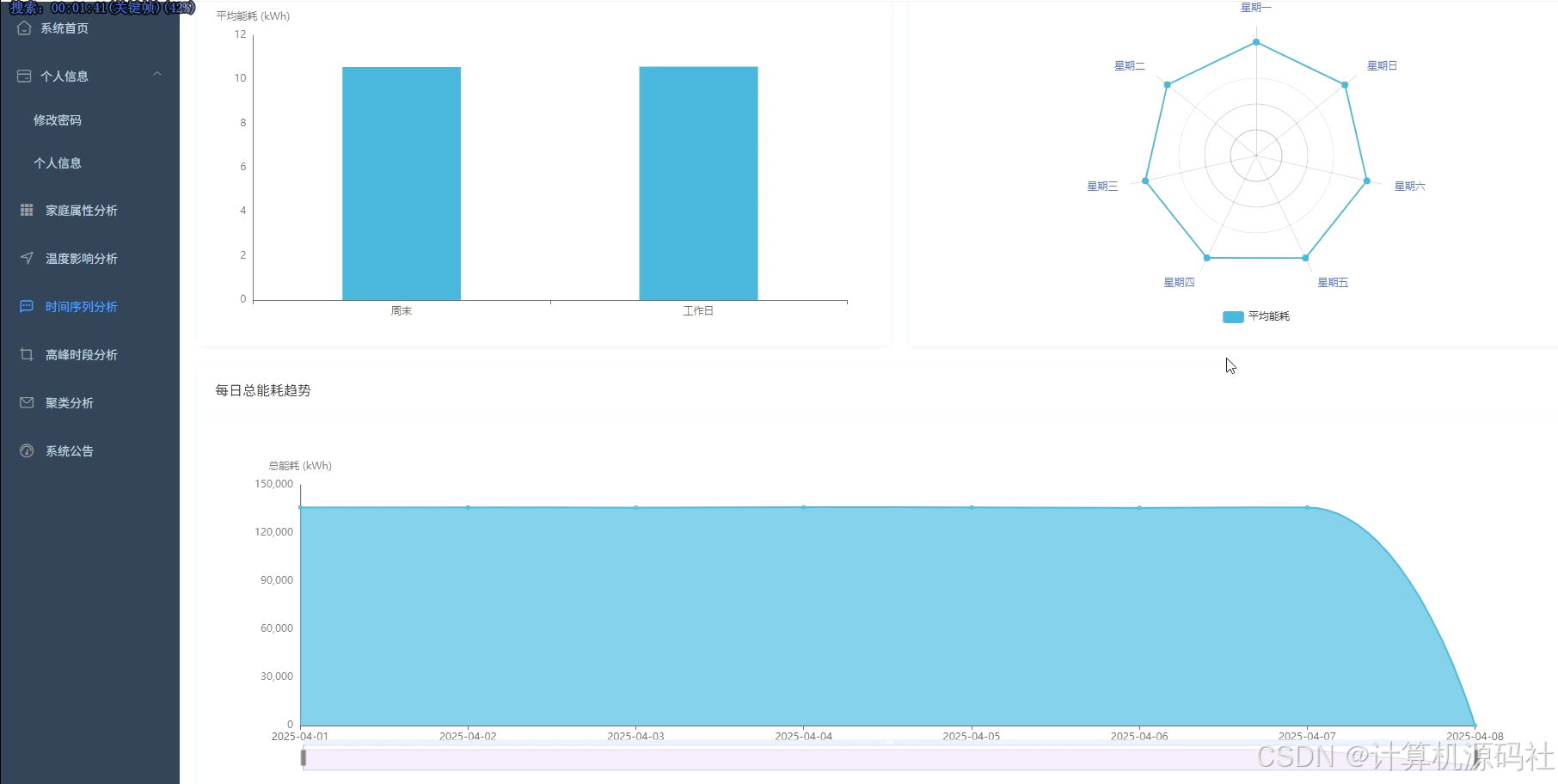
本系统的主要目的是通过大数据分析和可视化技术,实现对家庭能源消耗的全面监控和精准分析,从而帮助用户优化能源使用,降低能源成本,提高能源利用效率。系统通过收集家庭的用电、用水等能源消耗数据,利用数据挖掘和机器学习算法,分析家庭能源消耗的模式和趋势,识别能源浪费的环节,并提供针对性的节能建议。系统还通过可视化界面,直观展示家庭能源消耗的详细信息,包括高峰与非高峰时段能耗占比、不同规模家庭的平均总能耗、日均温度与总能耗时序变化等,使用户能够清晰了解家庭能源消耗情况,从而采取有效措施进行节能。
开发基于大数据的家庭能源消耗数据分析与可视化系统具有重要的现实意义,它有助于提高家庭能源管理的科学性和精准性,通过数据分析和可视化展示,用户可以直观了解家庭能源消耗的具体情况,从而采取有效的节能措施。该系统有助于推动家庭能源消耗的优化和节能减排,通过识别能源浪费的环节,提供节能建议,有助于减少能源消耗,降低碳排放,实现绿色发展。该系统还有助于提高能源利用效率,通过优化能源使用,降低能源成本,为家庭节省开支,同时也为能源供应方提供数据支持,优化能源分配和调度。该系统的开发对于促进家庭能源管理的智能化、精细化和绿色化具有重要意义。
3、系统研究内容
本系统的开发内容包括数据收集、数据处理、数据分析、数据可视化和用户交互等多个方面,系收集家庭的用电、用水等能源消耗数据,并利用大数据技术进行存储和管理。系统利用Spark、Hadoop等大数据处理技术,对收集到的数据进行清洗、转换和整合,为数据分析提供高质量的数据基础。然后系统通过数据挖掘和机器学习算法,对家庭能源消耗数据进行深入分析,挖掘能源消耗的模式和规律,识别能源浪费的环节,并提供节能建议。系统利用Vue、Echarts等前端可视化工具,将分析结果以图表、仪表盘等形式直观展示,使用户能够清晰了解家庭能源消耗情况。
4、系统页面设计
如需要源码,可以扫取文章下方二维码联系咨询
5、参考文献
1马莉. 基于大数据技术的能源数据监测与智能分析平台研究J.中国信息界,2025,(02):149-151.
2高嘉赓. 基于大数据分析的电力系统负荷预测与规划优化J.光源与照明,2025,(01):78-80.
3张轩豪,盘海,陈志军,等. 能源数据管控平台在冶金环保企业应用的实践研究J.冶金标准化与质量,2024,62(06):36-40.
4宋琳,张成祥. 甲醇生产企业数字化标准化能源管理系统建设研究J.中国标准化,2024,(20):115-120.
5吴群.基于物联网的钢铁行业节能检测信息系统D.浙江理工大学,2022.DOI:10.27786/d.cnki.gzjlg.2022.000307.
6庞贯鹏.能源综合管理系统的设计与实现D.西安电子科技大学,2021.DOI:10.27389/d.cnki.gxadu.2021.000234.
7任盈竹.基于大数据分析的智慧城市自动驾驶车流智能管理研究D.北京邮电大学,2021.DOI:10.26969/d.cnki.gbydu.2021.000808.
8刘宇翔,段素梅,刘刚,等. 物联网在螺旋埋弧焊管生产线建设中的应用J.焊管,2021,44(02):60-65.DOI:10.19291/j.cnki.1001-3938.2021.02.013.
9赵金超.基于LSTM混合模型的能耗数据分析与平台设计D.青岛科技大学,2020.DOI:10.27264/d.cnki.gqdhc.2020.000233.
10刘聪.基于数据仓库的机场能源信息管理研究D.中国民航大学,2017.
11邓小元.基于物联网技术的能源监测与节能管理系统研究D.华北电力大学(北京),2017.
12张新.水泥企业能源数据存储与分析系统研究D.济南大学,2016.
13林鹏.乳山市大型企业能源数据分析系统的设计与实现D.山东大学,2016.
14姬海臣,陈治平. "智慧能源工业云"系统平台的创新设计J.上海节能,2015,(09):474-478.DOI:10.13770/j.cnki.issn2095-705x.2015.09.004.
15黄俊杰.南朗镇企业能源消耗数据管理系统分析与设计D.云南大学,2015.
16杨琪.电力能源实时数据仓库系统研究与实现D.西安科技大学,2012.
17卢意.高校能源管理信息系统的设计与实现D.电子科技大学,2011.
18石巍.能源管理系统在生物制药企业中的应用D.复旦大学,2011.
19魏海明. 冶金能源管理系统的发展J.宝钢技术,2007,(05):28-31+34.
20陈小文.企业计量中数据仓库解决方案的设计与实现D.东北大学,2007.
6、核心代码
python
# 初始化Spark会话
spark = SparkSession.builder.appName("FamilyEnergyConsumptionAnalysis").getOrCreate()
# 读取能源消耗数据
def load_data(file_path):
df = spark.read.csv(file_path, header=True, inferSchema=True)
return df
# 数据预处理
def preprocess_data(df):
# 将日期字符串转换为日期类型
df = df.withColumn("date", col("date").cast("date"))
# 提取小时信息
df = df.withColumn("hour", hour(col("timestamp")))
# 过滤掉异常值
df = df.filter((col("energy_consumption") >= 0) & (col("energy_consumption") <= 100))
return df
# 特征工程
def feature_engineering(df):
# 创建新特征
df = df.withColumn("day_of_week", col("date").dayofweek)
df = df.withColumn("month", col("date").month)
# 特征选择
features = ["hour", "day_of_week", "month", "temperature"]
return df.select(features + ["energy_consumption"])
# 构建决策树模型
def build_model(training_data):
# 特征向量化
assembler = VectorAssembler(inputCols=["hour", "day_of_week", "month", "temperature"], outputCol="features")
# 决策树分类器
dt = DecisionTreeClassifier(labelCol="energy_consumption", featuresCol="features")
# 构建Pipeline
pipeline = Pipeline(stages=[assembler, dt])
# 训练模型
model = pipeline.fit(training_data)
return model
# 模型评估
def evaluate_model(model, test_data):
predictions = model.transform(test_data)
# 计算准确率
accuracy = predictions.filter(col("prediction") == col("energy_consumption")).count() / test_data.count()
return accuracy
# 数据可视化
def visualize_data(df, column_name):
plt.figure(figsize=(10, 6))
sns.lineplot(x="date", y=column_name, data=df, marker='o')
plt.title(f'Trend of {column_name}')
plt.xlabel('Date')
plt.ylabel(column_name)
plt.grid(True)
plt.show()
# 主函数
def main():
# 加载数据
df = load_data("energy_consumption_data.csv")
# 数据预处理
df = preprocess_data(df)
# 特征工程
df = feature_engineering(df)
# 划分训练集和测试集
training_data, test_data = df.randomSplit([0.8, 0.2], seed=42)
# 构建模型
model = build_model(training_data)
# 评估模型
accuracy = evaluate_model(model, test_data)
print(f"Model Accuracy: {accuracy}")
# 可视化
visualize_data(df, "energy_consumption")
if __name__ == "__main__":
main()💕💕作者:计算机源码社
💕💕个人简介:本人八年开发经验,擅长Java、Python、PHP、.NET、Node.js、Spark、hadoop、Android、微信小程序、爬虫、大数据、机器学习等,大家有这一块的问题可以一起交流!
💕💕学习资料、程序开发、技术解答、文档报告
💕💕如需要源码,可以扫取文章下方二维码联系咨询