✨作者主页 :IT研究室✨
个人简介:曾从事计算机专业培训教学,擅长Java、Python、微信小程序、Golang、安卓Android等项目实战。接项目定制开发、代码讲解、答辩教学、文档编写、降重等。
文章目录
一、前言
本系统是基于大数据技术的北京市医保药品数据分析系统,旨在通过大规模的数据处理与分析,帮助医保部门、药品生产企业及研究机构更有效地管理和分析药品数据。该系统采用了Hadoop与Spark的大数据框架,结合Python/Java的开发语言,支持Django/Spring Boot作为后端框架,前端则采用Vue和ElementUI等现代化前端技术,提供高效的数据交互界面。系统的核心功能包括药品目录的管理、药品信息的深入分析、医保报销策略的精准监控等,能够帮助用户全面了解北京市医保药品的分布、使用频率及市场占有情况,为政策制定和医疗资源配置提供数据支持。
选题背景:
随着社会医疗需求的不断增长和医保政策的逐步完善,如何精确分析和管理医保药品目录成为了医疗行业中的一个重要课题。特别是在北京这样的大城市,药品种类繁多且涵盖了各类治疗领域,从常见病到复杂疾病都有涉及。北京市作为国家医保政策的试点区域之一,涉及到大量的药品数据,包括药品类型、生产企业、医保目录等级等信息。这些数据对医保报销、药品供应链以及患者用药管理有着重要影响。因此,通过大数据分析技术对北京市医保药品数据进行深度挖掘,不仅能提升医保政策的精准度,还能为相关企业、政府和公众提供有价值的决策依据。
选题意义:
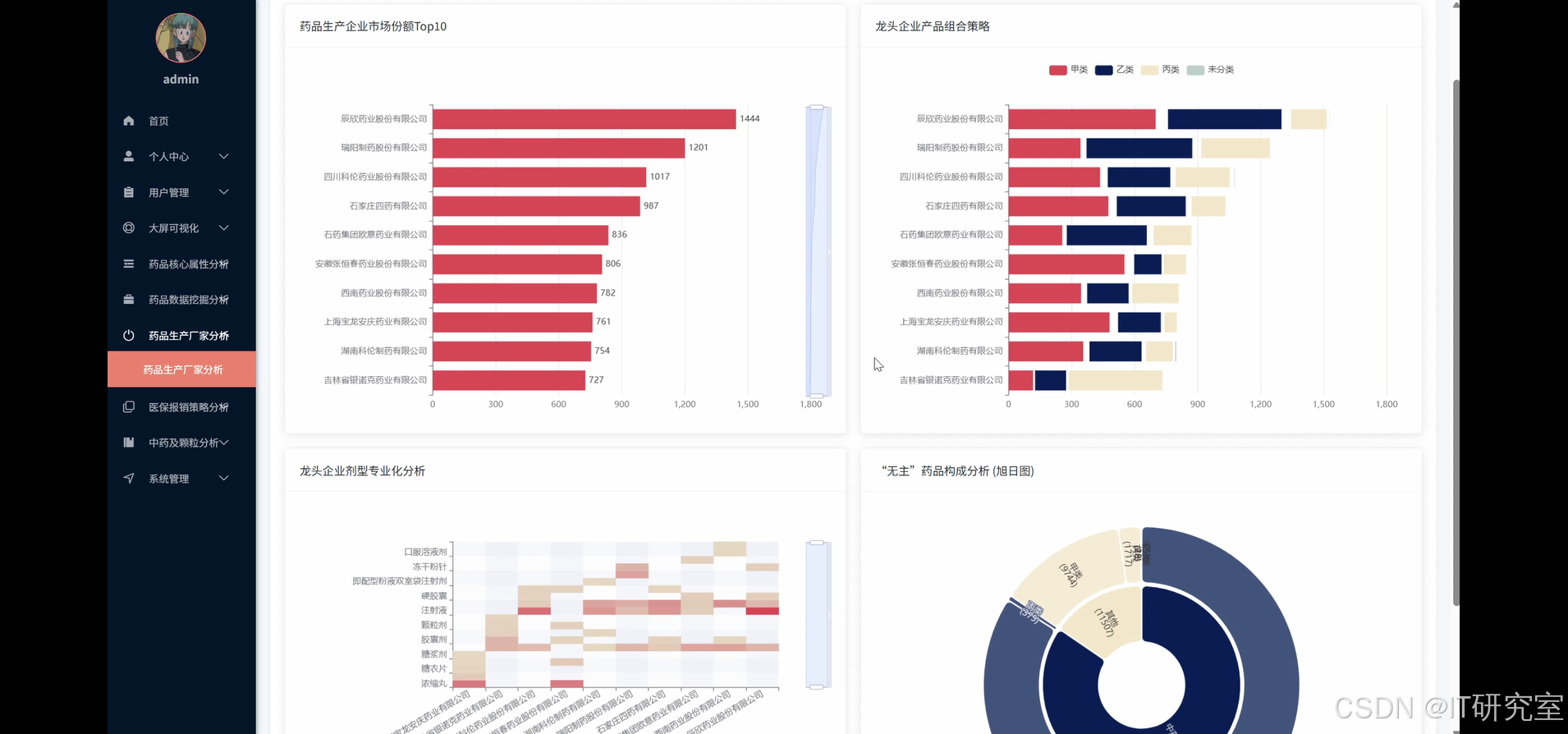
本课题具有深远的实际意义。首先,从政策角度来看,基于大数据分析能够帮助医保部门了解药品使用的整体趋势,识别出医保目录中的药品种类和分布情况,优化药品支付策略与监管措施;其次,针对药品生产企业,本系统能够帮助企业了解其产品在医保体系中的市场表现,进而调整产品组合、研发方向和市场策略;再次,对于患者和医疗机构,系统能够提供精准的医保报销数据,帮助患者降低经济负担,并协助医院进行合理的药品采购与使用决策。通过这些功能的实现,系统不仅提升了数据的透明度,也为北京市医疗保障体系的高效运行提供了坚实的数据支持。
二、开发环境
- 大数据框架:Hadoop+Spark(本次没用Hive,支持定制)
- 开发语言:Python+Java(两个版本都支持)
- 后端框架:Django+Spring Boot(Spring+SpringMVC+Mybatis)(两个版本都支持)
- 前端:Vue+ElementUI+Echarts+HTML+CSS+JavaScript+jQuery
- 详细技术点:Hadoop、HDFS、Spark、Spark SQL、Pandas、NumPy
- 数据库:MySQL
三、系统界面展示
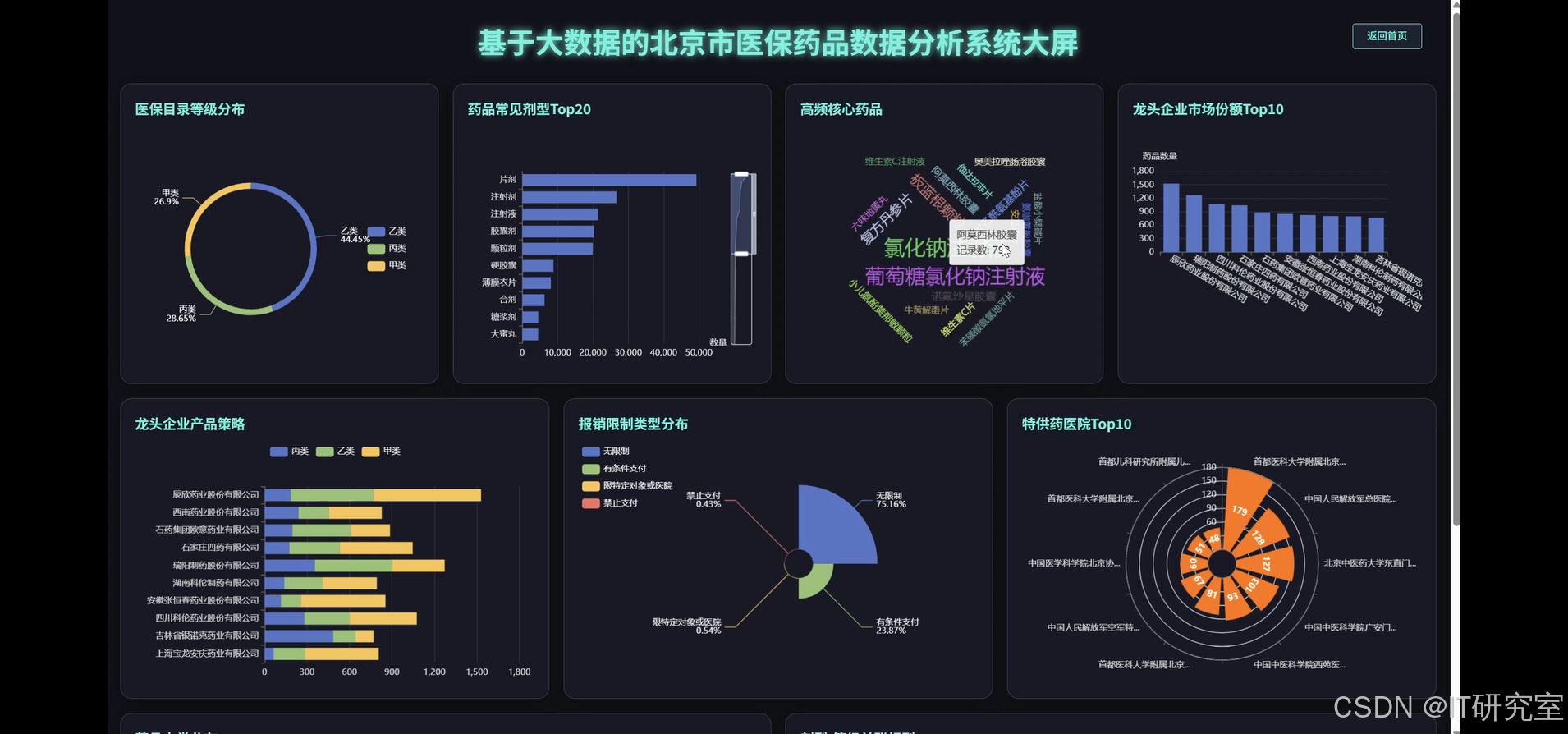
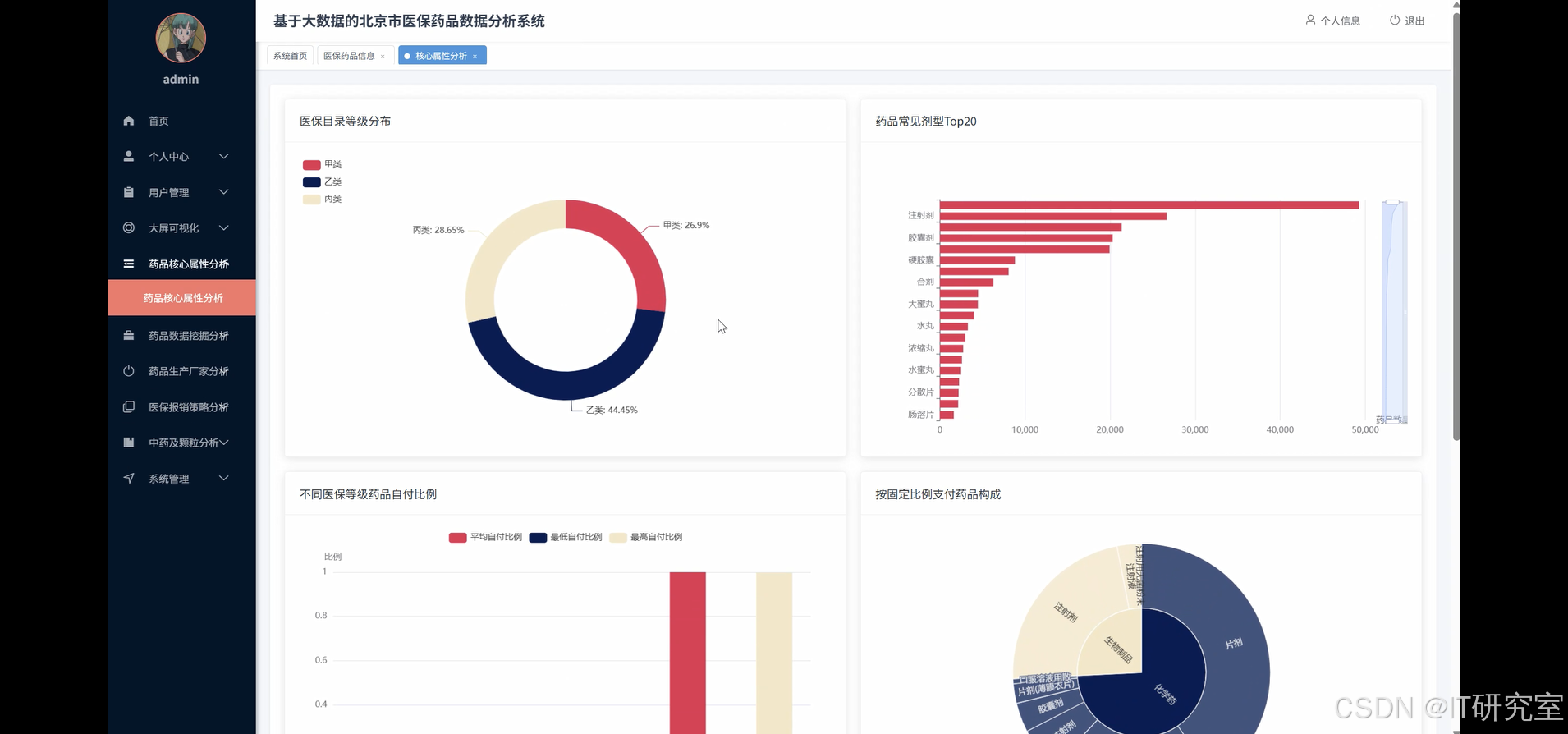
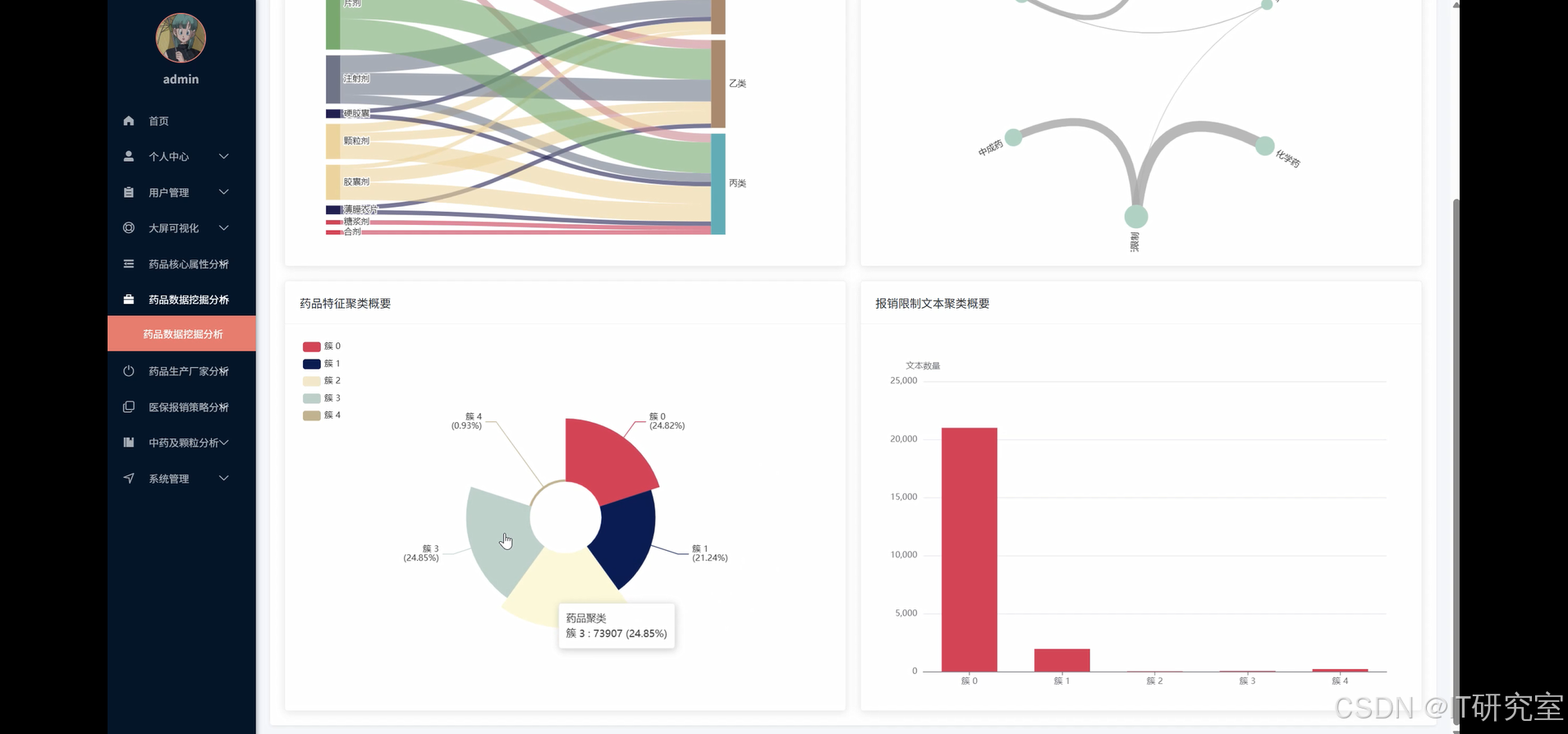
- 基于大数据的北京市医保药品数据分析系统界面展示:
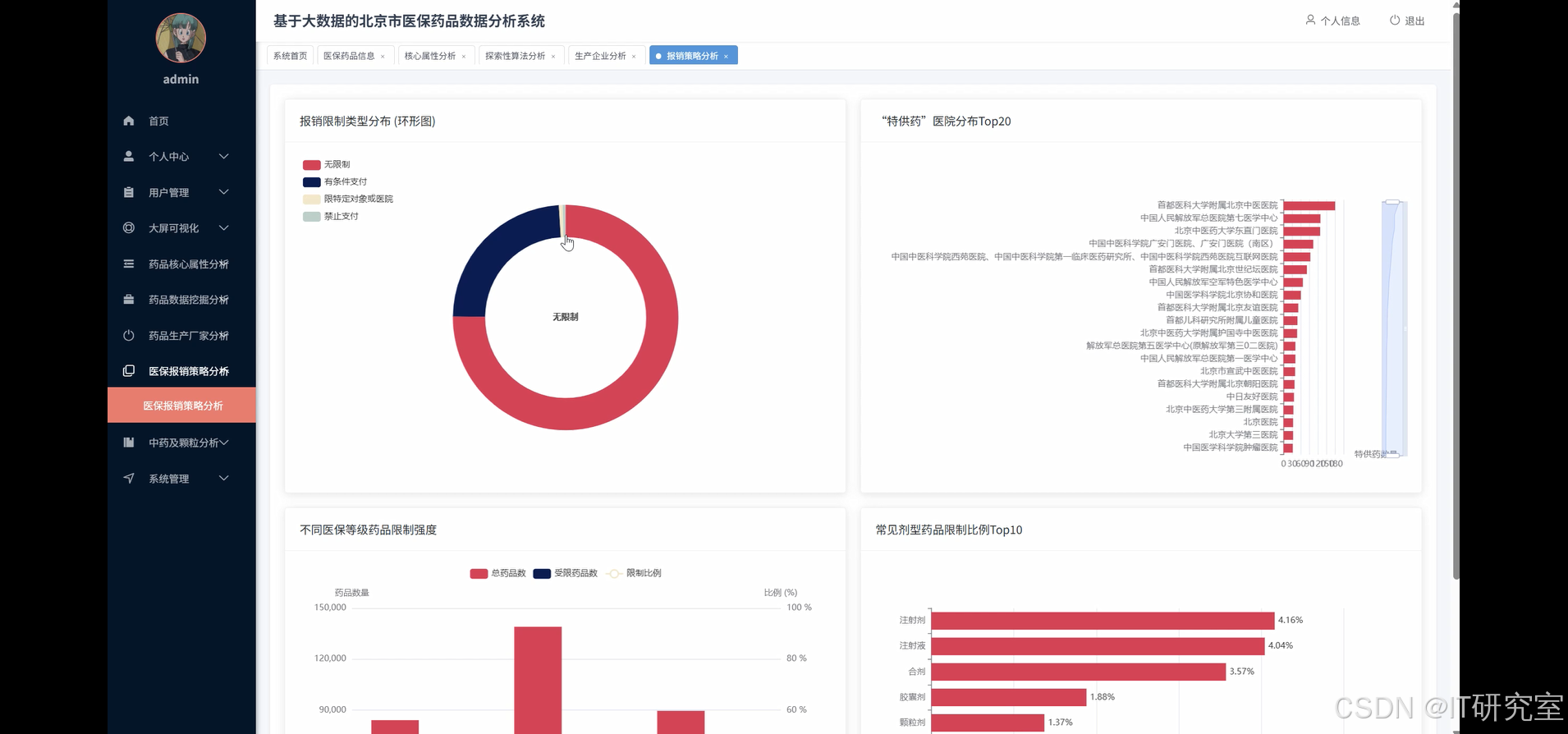
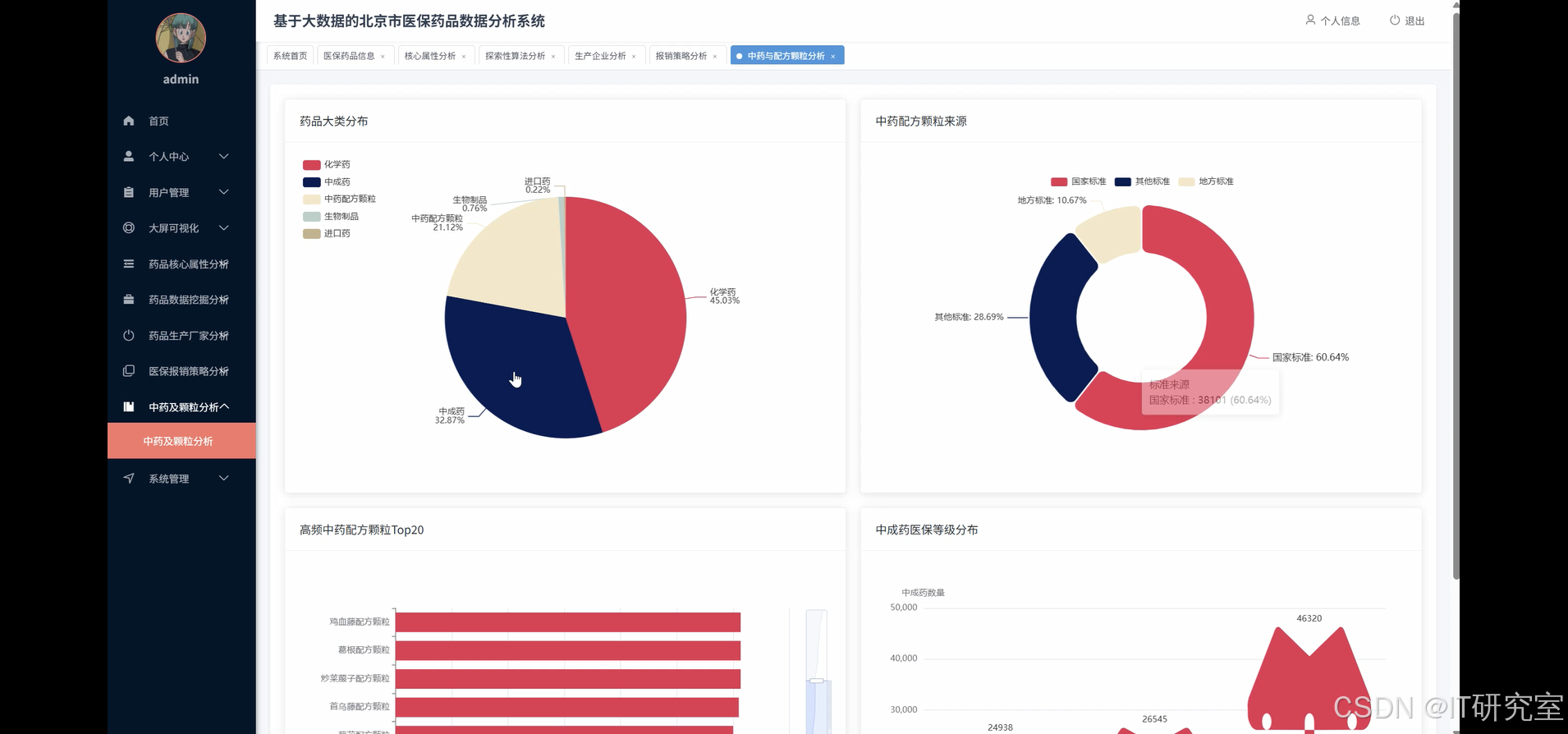
四、代码参考
- 项目实战代码参考:
java(贴上部分代码)
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, count, avg
# 初始化SparkSession
spark = SparkSession.builder.appName("Beijing Medical Data Analysis").getOrCreate()
# 加载医保药品数据
df = spark.read.csv("beijing_medicare_data.csv", header=True, inferSchema=True)
# 1. 药品目录等级分布分析
def insurance_level_distribution(df):
return df.groupBy("医保目录等级").agg(count("药品名称").alias("药品数量")).orderBy(col("药品数量").desc())
# 2. 药品常见剂型分析
def dosage_form_analysis(df):
return df.groupBy("药品剂型").agg(count("药品名称").alias("药品数量")).orderBy(col("药品数量").desc())
# 3. 不同医保等级药品的自付比例分析
def self_pay_ratio_by_level(df):
return df.groupBy("医保目录等级").agg(avg("自付比例").alias("平均自付比例")).orderBy(col("平均自付比例"))
# 使用核心函数进行分析
level_distribution = insurance_level_distribution(df)
dosage_form = dosage_form_analysis(df)
self_pay_ratio = self_pay_ratio_by_level(df)
# 显示结果
level_distribution.show()
dosage_form.show()
self_pay_ratio.show()五、系统视频
基于大数据的北京市医保药品数据分析系统项目视频:
大数据毕业设计选题推荐-基于大数据的北京市医保药品数据分析系统-Spark-Hadoop-Bigdata
结语
大数据毕业设计选题推荐-基于大数据的北京市医保药品数据分析系统-Spark-Hadoop-Bigdata
想看其他类型的计算机毕业设计作品也可以和我说~ 谢谢大家!
有技术这一块问题大家可以评论区交流或者私我~
大家可以帮忙点赞、收藏、关注、评论啦~
源码获取:⬇⬇⬇