视频去噪是一种视频处理技术,旨在从视频帧中移除噪声和干扰,提高视频质量。噪声可能由多种因素引起,包括低光照条件、高ISO设置、传感器缺陷等。视频去噪对于提升视频内容的可视性和可用性至关重要,特别是在安全监控、医疗成像和视频制作等领域。
视频去噪技术通常采用以下几种方法:
-
时间滤波器:利用连续帧之间的时间相关性来减少噪声。这种方法假设在短时间内场景的变化较小,因此可以通过平均多帧来减少随机噪声。
-
频域方法:通过转换视频到频域(如使用傅里叶变换),然后应用滤波器来去除噪声频率成分。
-
空间滤波器:在单个帧内部应用,如中值滤波和高斯滤波,这些滤波器可以有效去除噪点而保留边缘信息。
-
深度学习方法:最近,利用深度神经网络,特别是卷积神经网络(CNNs)和生成对抗网络(GANs),进行视频去噪取得了显著的进展。这些方法通常能够学习更复杂的噪声模式并且更好地恢复视频质量。
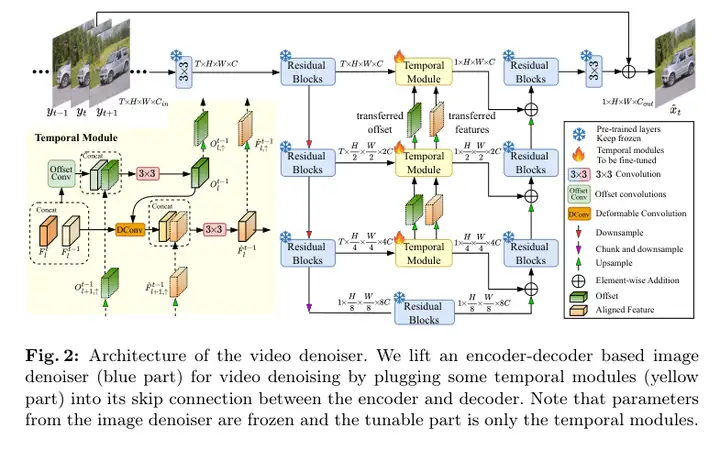
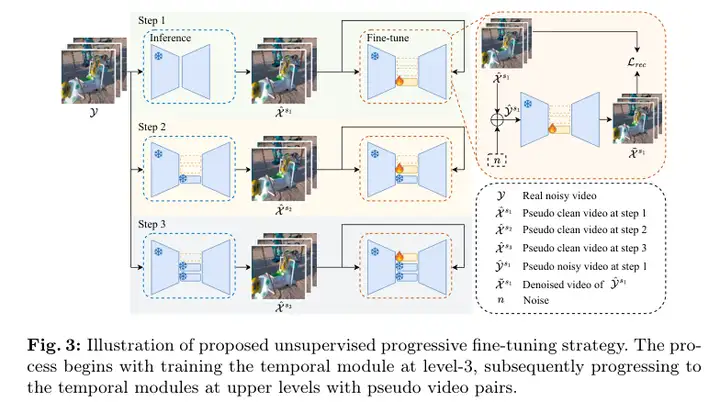
(TAP框架)属于深度学习范畴,它结合了时间模块与预训练的图像去噪网络,利用无监督学习方式从未配对的噪声视频中恢复清晰帧。这种方法的创新点在于它不仅使用了传统的空间去噪技术,还整合了时间信息来增强去噪效果,并通过逐步微调策略进一步优化性能。
视频去噪技术的提升对多个领域有重要意义:
- 提高视频质量:在低质量源材料(如老旧录像带或低光环境拍摄的视频)中提升视觉体验。
- 增强后续视频分析的准确性:清晰的视频能更好地支持面部识别、行为分析等智能视频分析任务。
- 节省存储和传输带宽:去除噪声后的视频可以更有效地编码,降低数据量,减少存储和传输成本。

论文作者:Zixuan Fu,Lanqing Guo,Chong Wang,Yufei Wang,Zhihao Li,Bihan Wen
作者单位:Nanyang Technological University
论文链接:http://arxiv.org/abs/2409.11256v1
内容简介:
1)方向:视频去噪
2)应用:视频去噪
3)背景:最近深度学习在图像和视频去噪方面取得了显著进展,但获取动态场景的配对视频数据的挑战阻碍了深度视频去噪技术的实际部署。与此相比,在图像去噪中,配对数据更容易获得。
4)方法:本文提出了一种新颖的无监督视频去噪框架TAP,该框架将可调节的时间模块集成到预训练的图像去噪器中。通过引入时间模块,方法可以利用噪声帧之间的时间信息,增强空间去噪的能力。此外,还引入了逐步微调策略,使用生成的伪干净视频帧对每个时间模块进行精细调整,逐步提升网络的去噪性能。
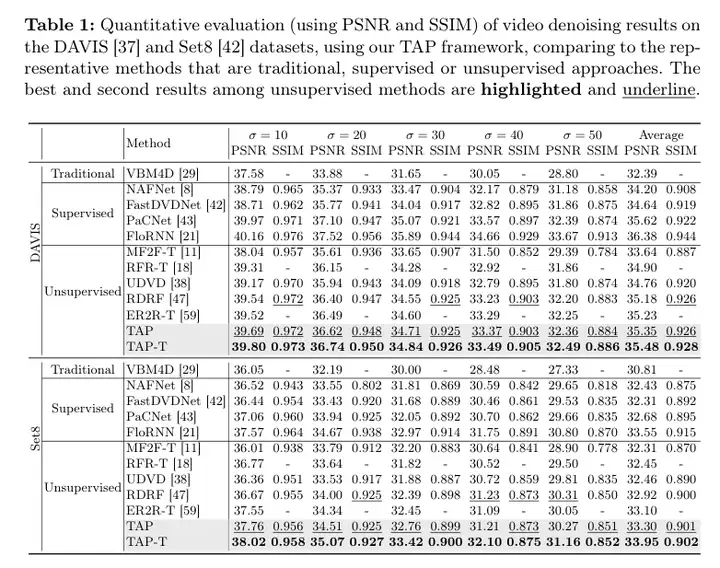
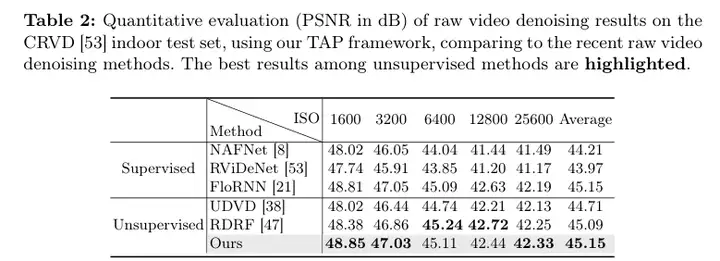
5)结果:与其他无监督视频去噪方法相比,该框架在sRGB和原始视频去噪数据集上表现出优越的性能。