03.腾讯后端一面
项目相关
面试官可能是 Go 方向的,我面试的是 Java 方向的,所以面试官也没有问我简历上的项目,主要问了实验室中做的项目,哪个项目比较有技术挑战?
面试主要问了计算级网络相关,以及如果让你来实现一个分布式锁,你该如何来实现,这一点说的时间比较久,有二十分钟左右
TCP 和 UDP
1、TCP 和 UDP 的区别?
TCP: TCP 时面向连接的协议,在传输数据之前,需要双方建立可靠的连接,即通过三次握手建立 TCP 连接
UDP: UDP 是非连接的协议,即发送端和接收端之间不建立连接,他只负责将数据包发送出去,不保证数据包的到达,因此数据包可能存在丢失、乱序、重复,也没有错误或者纠正机制
2、两者的使用场景
TCP 适用于对可靠性要求比较高的应用,比如网页浏览、远程调用、文件传输等
UDP 适用于对实时性要求较高的应用,比如视频、直播等场景,偶尔丢失数据相对于连接建立和恢复带来的延迟更加可以接收
3、两者的实时性谁更好一些?
UDP 的实时性更好一些,UDP 主要从以下几个方面来保证了较好实时性:
- 无连接: UDP 传输数据不需要建立连接,因此速度是比较快的
- 低延迟: UDP 发送数据时,不需要等待确认、恢复重传,因此大大降低了传输过程中的延迟
- 简单的协议头: UDP 的协议头只有 8 字节,TCP 的协议头至少 20 字节,因此 UDP 传输时的开销也比较小
4、如果 TCP 建立连接之后,TCP 和 UDP 的实时性谁会更好一些呢?
上边已经说了 UDP 保证实时性的几个方面,可以看到并不只是因为建立连接才会导致 TCP 的实时性较差
还有其他因素,因为 TCP 是保证 数据可靠、有序 ,因此 TCP 发送数据之后需要等待接收方确认,并且有重传机制,来保证数据到达接收方,这些都会导致在传输过程中的延时较高
TCP 还有 流量控制 和 拥塞控制 ,因此会根据网络拥堵情况调整数据包发送速率,在保证了数据包可靠性的同时,也带来了一定的传输延时
因此,TCP 建立连接之后,UDP 的实时性还是比 TCP 好得多,因为实时性好并不只是因为 UDP 是无连接的
红黑树
5、红黑树的特性了解吗?
红黑树是自平衡的二叉搜索树,红黑树包括以下 5 个特性:
1、每个节点要么是黑色要么是红色
2、根节点始终都是黑色
3、叶子节点不包含任何数据,并且都设置为黑色
4、如果一个节点是红色,则它的子节点必须是黑色
这条性质确保了从根到叶子的路径上不会出现两个连续的红色节点,有助于避免树的局部区域出现过高的密度,这是通过颜色的变化来轻微调整树的平衡。
5、从一个节点到该节点的子孙节点的所有路径上包含相同数目的黑节点
红黑树最关键的性质,确保了树的平衡。无论从哪个节点到其叶子节点的路径,经过的黑色节点数量必须相同。这确保了最长的可能路径(红色和黑色交替出现)最多是最短可能路径(全黑色)的两倍长,保证了查询性能的稳定
6、红黑树如何保证比较好的查询性能?
红黑树是通过维持树的平衡来保证比较好的查询性能,平衡的二叉搜索树的数据结构可以让查询、插入、删除的时间复杂度达到 O(logn)
当新插入元素,红黑树会通过 旋转 和 重新染色 来调整树的结构,满足上述的特性,保证了红黑树的平衡,使得查询性能较为稳定,在 Java 的 HashMap 中就使用到了红黑树来优化数据的查询性能
MySQL
7、MySQL 的存储引擎平常使用哪个?
平常使用的 InnoDB 存储引擎,接下来说了常见的存储引擎: InnoDB 和 MyISAM 以及他们的区别
MySQL 中存储引擎的发展:
MySQL 在 5.5 版本之前使用 MyISAM 作为 默认的存储引擎 ,在 5.5 版本之后,引入了 InnoDB 存储引擎取代了 MyISAM
接下来介绍一下这两种存储引擎,来看一下它们的区别以及各自适用的场景
MyISAM 存储引擎
MyISAM 的特点如下:
- 不支持事务 ,容易出现数据丢失
- 表级锁定 ,高并发场景下表现不好
- 数据、索引 分离存储 ,适合查询操作
MyISAM 不支持事务,因此更新操作会导致数据丢失,并且是表级锁定,锁的粒度太大了,因此 MyISAM 比较适合 查询较多的场景 ,如下:
- 查询报表场景 (全都是查询计算操作,因此使用 MyISAM 性能较高)
- 在配置数据库读写分离场景下, MySQL 从库 可以使用 MyISAM 存储引擎
InnoDB 存储引擎
InnoDB 是目前使用较多的存储引擎,特点如下:
- 支持 事务 ,可以对操作失败的事务数据进行回滚恢复,数据可靠性较高
- 采用 MVCC 来支持高并发,并且实现了不同的事务隔离级别:读未提交、读已提交、可重复读(默认隔离级别)、可串行化
- 支持 行级锁 ,行级锁标志着更小的锁粒度,会带来更高的并发度
- InnoDB 的表是基于 聚簇索引 建立:聚簇索引对主键查询有很高的性能,但是主键不宜设置过大,因为二级索引中都包含主键列,如果主键过大,会导致其他索引过大
- InnoDB 基于 BufferPool 大幅提升了更新操作的性能,所有更新操作基于内存操作,再通过顺序写日志文件(bin log、undo log、redo log)来保证数据的一致性
总结
MyISAM 存储引擎 由于不支持事务,并且只有表锁没有行锁,导致了它如果执行发生错误容易丢失数据,并且锁的粒度太大了,导致无法承载高并发的写操作
但是 MyISAM 可以支持 很好的查询性能 ,因为它的 索引 和 数据 是分开存放的,因此可以缓存更多的索引,查询性能较好,在 大量查询操作 的场景中,MyISAM 可以有很好的性能表现
InnoDB 相对于 MyISAM 来说,更适合 写操作比较多 的场景,因为 InnoDB 支持事务、支持行级锁、有 MVCC、BufferPool 机制,因此在有大量更新操作的场景下使用 InnoDB 性能会更好,并且使用 InnoDB 可以 支持事务 保证多个更新操作的数据一致性
8、MySQL 的事务特性?
事务特性:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)
原子性: 保证事务内的操作要么全部成功,要么全部失败
一致性: 一致性保证数据库从一个一致的状态转换到另一个一致的状态,保证在并发环境下,执行事务后数据库状态也必须是一致的
隔离性: 隔离性定义了一个事务在执行过程中,对其他事务修改结果的可见性,MySQL 中包含了:读未提交、读已提交、可重复读、串行化四种隔离级别
持久性: 持久性确保了事务一旦提交,结果就永久的存储了下来,即保存到了磁盘中,即使数据库宕机,数据也不会丢失
9、MySQL 如何实现的事务?
MySQL 实现事务的话,通过 undo log、redo log、bin log 来实现,MySQL 执行一个事务的流程如下:
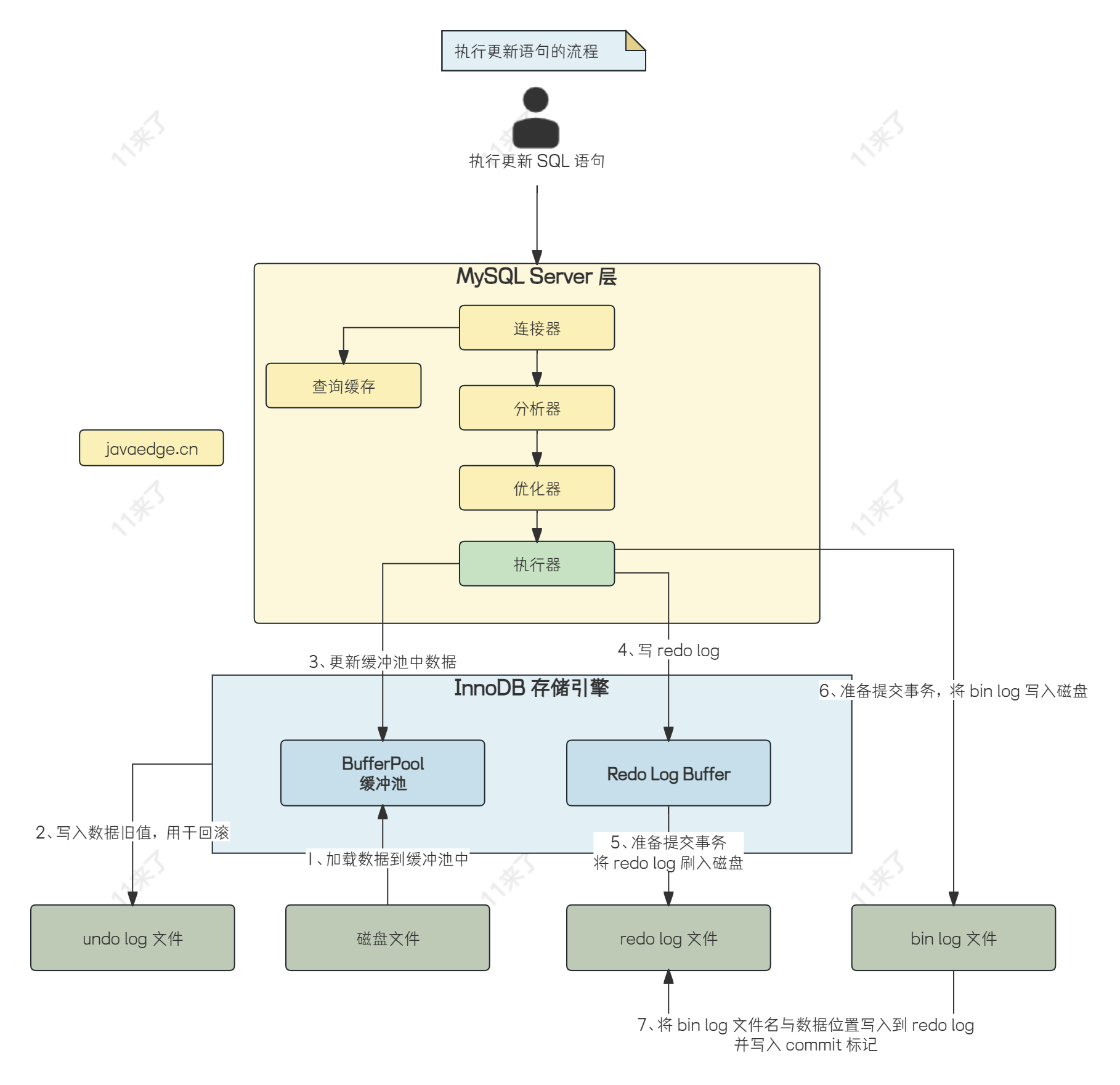 BufferPool
BufferPool
1、如果需要更新的数据不在缓冲池中,就先去磁盘中加载数据页,把需要修改数据所在的数据页,缓存到 BufferPool,BufferPool 中缓存的其实就是一个个的数据页
2、修改记录前,写 undo 日志,记录更改前数据,如果事务执行失败,使用 undo 日志进行数据回滚
3、更新 Buffer Pool 中的数据,并且将 redo log 写到 redo buffer 中
4、提交事务时,会做两件事情:将 bin log 日志写入到磁盘,保存操作记录;将 redo buffer 中的 redo log 刷到磁盘中去,保存操作记录。
bin log 会按照一定的策略刷新到磁盘中去(通过 innodb_flush_log_at_trx_commit 参数来控制)
当 bin log 成功写入到磁盘后,接着就会完成事务的最终提交,之后会将更新的 bin log 的文件名称以及 bin log 日志在文件里的位置都写入到 redo log 中去,并且在 redo log 里写入一个 commit 标记
5、数据持久化,IO 线程不定期把 Buffer Pool 中的数据随机写入到磁盘,完成持久化
扩展:undo log、redo log、bin log 的作用
bin log、redo log、undo log 作用:
-
bin log:bin log 叫做归档日志,主要记录了做了什么操作,比如更新一行数据,bin log 就记录了对哪一行数据做更改,更新前的值是什么,更新为了什么值。bin log 日志是用于恢复磁盘中的数据
其中 redo 日志和 undo 日志是 InnoDB 引擎特有的,而 bin log 是属于 Server 层的,与存储引擎无关
-
redo log:redo log 叫做重做日志,用于恢复 BufferPool 中的数据
-
undo log:用于进行数据的回滚
分布式锁
7、如果让你来实现一个分布式锁,该如何实现?
实现分布式锁的话,肯定需要一个地方去存储锁的信息,可以选择 Redis 或者 Zookeeper 来存储,这样所有的节点都可以感知到分布式锁的存在,达到多个节点互斥的效果
一般使用中,就是基于 Redis 或者 ZooKeeper 的分布式锁使用的比较多,这里说一下基于 Redis 如何实现一个分布式锁(也就是 Redis 的客户端工具 Redisson 如何实现的分布式锁)
首先,锁信息存在 Redis 中,要可以看得出来是哪个应用中的哪个线程持有的这把锁,这样是为了之后可以进行 重入锁 的操作,基于这样的考虑,在 Redis 中使用哈希结构来存储,如下:
"11_come": {
ffa56698-e0f7-4412-ad5a-00669156d187:1: 1
}11_come:哈希结构的名称,也就是我们加的分布式锁的 Nameffa56698-e0f7-4412-ad5a-00669156d187:1::持有锁的线程的唯一标识,由threadId标识,但是多个应用的threadId可能重复,因此前边再加上一个UUID,即组成为:UUID + threadId,这样就可以保证每个线程的标识都是唯一的,这个UUID需要存储下来,因为要保证同一个线程来获取锁的时候拿到的 UUID 都是相同的,这样才可以进行 锁的重入1:哈希结构中,后边的 1 表示当前线程的重入次数
这样锁的存储就已经实现好了
8、如果多个应用同时去加锁,如果一起查询,锁结构并不存在,因此同时去加锁,这样会不会存在问题?
这里面试官问的意思就是如何去保证多个应用去同时加锁,判断锁结构是否存在以及加锁的操作如何保证原子性
可以通过 lua 脚本来保证这一系列操作的原子性,通过 lua 脚本可以保证命令执行的 原子性 ,即 Redis 在执行 lua 脚本时,不会被其他操作打断
9、锁的过期时间如何设置呢?
如果加锁的时候,指定了过期时间,就使用指定的时间,如果没有指定,就给一个默认的过期时间,可以设置 30s
10、会不会导致用户还没有执行完,锁就已经被释放了?
不会的,因为还有一个后台任务去进行一个 锁续期 的操作,比如过期时间为 30s,那么就在 1/3 的时间(10s)之后,就去判断用户线程是否还在执行任务,如果还在执行的话,就去进行一个锁续期的动作,即将锁的过期时间重置为 30s
11、如何去判断用户线程是否还在执行任务?
这个后台任务是在加锁的时候去启动的,其实就是一个延时任务,延时 10s 的时间去进行锁续期的操作,在执行完锁续期操作执行,再次去启动这个延时任务,进行下一次的锁续期操作
那么如果加锁的这个用户线程已经执行完毕之后,就不会去执行这个延时任务了,当然也就不会进行锁续期操作了
12、如果在高并发的场景下,用户加锁的机器宕机了,会导致其他线程一直拿不到锁,这个该如何去解决?
面试官问的意思是,想要如何在用户宕机之后,怎么去知道这个用户所在的机器宕机了,主动的去释放掉这个锁
我先回答的是每个锁有一个超时时间,超过这个时间锁就会被释放掉了,但是面试官说默认的超时时间 30s 太长了,在海量任务的场景下会将其他请求都阻塞 30s,这样是不可以接受的
之后我说,那就要感知到这个进程节点是否还存活,可以将这个线程注册一个节点到 ZooKeeper 中,注册为 临时节点 ,当这个机器宕机,线程也就没了,ZooKeeper 中的临时节点就会消失,当监听到这个节点消失,就可以去 Redis 中将这个节点的锁给主动删除掉
13、如果线程在获取锁之后,一直得不到调度,那么这个线程就不会进行锁续期,导致锁过期了该怎么办?
这个我说的是将执行锁续期的时间点放的靠前一些
因为这个线程可能暂时得不到调度,但是后边迟早要得到调度,因此锁续期的时间点在过期时间的 1/3 处,也就是过期时间为 30s,那么当过了 10s 之后就来执行锁续期的这个操作,而不是等到第 28、29 秒的时候再来执行锁续期,这样可能导致线程没有得到调度,没来得及执行锁续期,锁就已经过期了,但是这个线程的任务还没有执行完毕
14、如果进程并没有挂掉,而是线程出现问题,比如抢占不到 CPU 资源,此时去监听这个进程是否挂掉就没有用了,该怎么办?
这里问的是,上边我说将线程节点作为临时节点注册到 ZooKeeper 中,但是如果进程没挂,而是线程得不到 CPU 调度,那通过这种方式也无法感知到这个问题
我回答的是,既然要应对这种问题,就要探测这个线程是否在执行,那么就可以在加锁的用户线程中加一个发送心跳的操作,在另外一个服务中去接收这个心跳,如果在一段时间内都收不到用户线程的心跳,那么就说明这个用户线程出现问题了,一直没有得到执行,因此就可以主动的去将这个用户线程加的分布式锁给释放掉,那么这里判断线程出现问题的时间就可以设置的短一些,比如 5s 都没有收到该线程的心跳,那么就判断该线程得不到调度,出现问题,就主动去释放他的锁
面试到这里就结束了,之后出了一道算法题,实现 Compartor 排序就可以完成,比较简单
面试复盘:
问的分布式锁的最后一个问题,感觉还存在一些问题,线程得不到调度之后,我们去主动释放该线程的锁了,那么加入这个线程之后又重新被调度了,那就会出现问题了,所以在释放这个线程锁之后,还要将这个线程任务给杀掉,避免之后又重新得到调度从而出现并发安全问题
我觉得这种情况概率很低,在 Redisson 客户端中也没有进行这样的处理,如果有一些想法的话,可以在留言中指出,一起讨论一下!
本文由mdnice多平台发布