引言:复杂 SQL 背后的性能隐患
在企业级数据库应用不断发展的今天,SQL 的使用场景已经远远超出了最初的简单查询范畴。现实系统中的 SQL 往往承载着复杂的数据处理逻辑,例如统计分析、业务报表、数据聚合与实时分析等。因此,在编写 SQL 时,开发者通常会引入 CTE(Common Table Expression,公用表表达式)、嵌套子查询、窗口函数以及多种聚合操作来组织复杂逻辑,使得 SQL 结构更加清晰、可读性更强。
然而,从数据库执行层面来看,SQL 结构越复杂,对查询优化器的挑战就越大。特别是在涉及 多表关联(JOIN) 的复杂查询中,如果过滤条件没有在数据读取阶段发挥作用,而是等到中间结果生成之后才被应用,那么系统就可能需要处理远远超出实际需求的数据量,导致查询效率大幅下降。
很多数据库工程师在实际项目中都会遇到这样的情况: 某条 SQL 在开发环境执行得很快,但在生产环境却变得异常缓慢。进一步分析执行计划后会发现,问题往往出现在 子查询产生了庞大的中间结果集,而真正具有过滤能力的条件却没有提前参与执行。
针对这一类问题,金仓数据库(KingbaseES) 在 V009R002C014 版本中引入了一项重要优化能力------基于代价模型的连接条件下推(Cost-based Join Predicate Pushdown)。该机制通过"语义等价判断 + 执行代价评估"的方式,在保证查询结果正确的前提下,使复杂 SQL 的执行效率得到显著提升。
接下来,本文将从问题产生的原因入手,逐步介绍这一优化机制的设计思想以及在实际场景中的性能提升效果。
一、复杂查询为何容易成为性能瓶颈?
1.1 常见复杂 SQL 的执行特征
在实际业务系统中,复杂 SQL 通常会呈现出一种典型结构:
- 子查询内部逻辑复杂
- 过滤条件出现在外层 JOIN
例如:
- 子查询中包含
DISTINCT - 使用
GROUP BY聚合 - 包含窗口函数(Window Function)
- 存在多层嵌套结构
而真正用于筛选数据的条件,却往往出现在外层 JOIN 中。

从 SQL 语义角度来看,这种写法没有任何问题。但从执行角度来看,如果数据库优化器无法将外层条件提前应用到子查询阶段,就会产生明显的性能问题。
执行过程可能会变成:
- 子查询对底层表进行 完整扫描
- 执行所有复杂计算(去重、聚合等)
- 生成一个庞大的中间结果集
- 外层 JOIN 再进行过滤
这种执行顺序会导致大量无效数据参与计算,系统资源被严重浪费。
换句话说,这类性能问题的本质可以总结为:
过滤条件应用得太晚,数据裁剪没有在早期阶段完成。
1.2 为什么谓词下推并不容易实现?
从直觉上看,似乎只要把 JOIN 条件"往里推"就可以解决问题。但在数据库优化器设计中,这个过程并不像表面看起来那么简单。
其中主要存在两个关键难点。
1. 查询语义的正确性
数据库优化器必须确保任何优化都不会改变 SQL 的结果。
但在某些结构中,谓词位置的改变可能影响最终结果,例如:
GROUP BYDISTINCTWINDOW FUNCTIONUNION- 非确定性函数
例如,在聚合之前和聚合之后进行过滤,其结果可能完全不同。
因此,优化器必须非常谨慎地判断:
该谓词是否可以安全地下推。
2. 执行成本的评估
即使在语义上允许下推,也不代表一定能够提升性能。
例如,如果谓词被下推后,子查询变成 参数化执行(Parameterized Execution),那么在某些情况下可能会导致子查询被重复执行。
如果外层驱动表的记录数量较大,就可能出现以下情况:
- 子查询执行次数急剧增加
- 总体计算成本反而上升
因此,一个成熟的优化器不仅要判断:
是否可以下推还必须判断:
是否值得下推二、传统查询优化策略的局限
在许多数据库系统中,为了避免影响查询语义,优化器通常采用比较保守的执行策略。
这种策略通常表现为:
-
子查询完全执行
对底层表进行完整扫描,并完成所有计算逻辑。
-
生成中间结果
子查询结果被完整物化。
-
外层 JOIN
在 JOIN 阶段再应用过滤条件。
这种执行方式通常被称为:
"先计算,后过滤"
当数据规模较小时,这种方式不会带来明显问题。但在数据量较大的场景中,就会产生明显的性能瓶颈:
- 中间结果集过大
- JOIN 阶段计算量增加
- 内存和 I/O 开销上升
因此,如果能够在扫描阶段就进行数据过滤,就可以显著减少系统负担。
三、金仓数据库的优化思路
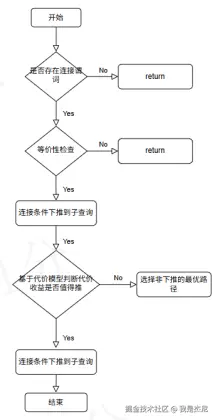
为了解决上述问题,金仓数据库(KingbaseES) 在最新版本中引入了 基于代价模型的连接条件下推机制。
该优化机制通过两层决策逻辑来保证优化的安全性和有效性。
3.1 第一层:语义等价判断
在执行谓词下推之前,优化器会对 SQL 结构进行详细分析。
主要包括以下步骤:
1. 查询结构识别
优化器会识别子查询中是否存在:
- 聚合函数
- DISTINCT
- 窗口函数
- UNION
如果存在可能影响结果的结构,则需要进一步分析是否允许下推。
2. JOIN 条件拆分
JOIN 条件会被拆解为两个部分:
- 依赖外层表的部分
- 子查询内部列的部分
例如:
ini
s1.a = s2.a其中:
s1.a来自外层表s2.a来自子查询
优化器会将其转化为子查询内部可使用的过滤条件。
3. 参数化谓词注入
如果语义检查通过,优化器就会将 JOIN 条件转换为 参数化过滤条件,并将其注入到子查询执行阶段。
这样子查询在扫描底层数据时,就可以利用这些条件提前过滤数据。
其核心目标是:
在不改变查询结果的前提下,将过滤操作尽可能提前。
3.2 第二层:基于代价模型的决策
在确认语义安全之后,优化器还需要判断这种优化是否真的有利。
为此,系统会对不同执行方案进行成本估算。
评估内容主要包括:
扫描成本
比较两种执行方式:
- 子查询一次性全量执行
- 子查询根据外层参数多次执行
外层表规模
如果外层表数据量较大,子查询可能被重复执行很多次,从而导致性能下降。
计算与 I/O 成本
优化器会综合考虑:
- CPU 计算量
- 磁盘 I/O
- 数据扫描行数
- 内存使用情况
如果评估结果表明下推会带来性能提升,则优化器才会选择该执行计划。
四、实际测试:性能提升有多明显?
为了验证该优化机制的效果,我们设计了多个测试场景。
4.1 DISTINCT 场景测试
测试 SQL:
sql
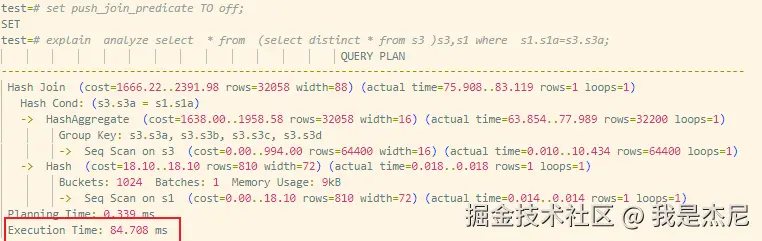
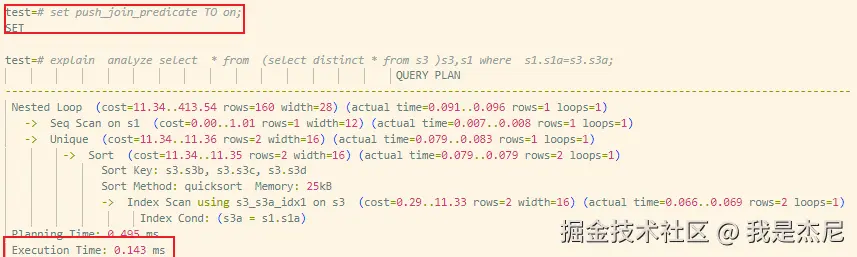
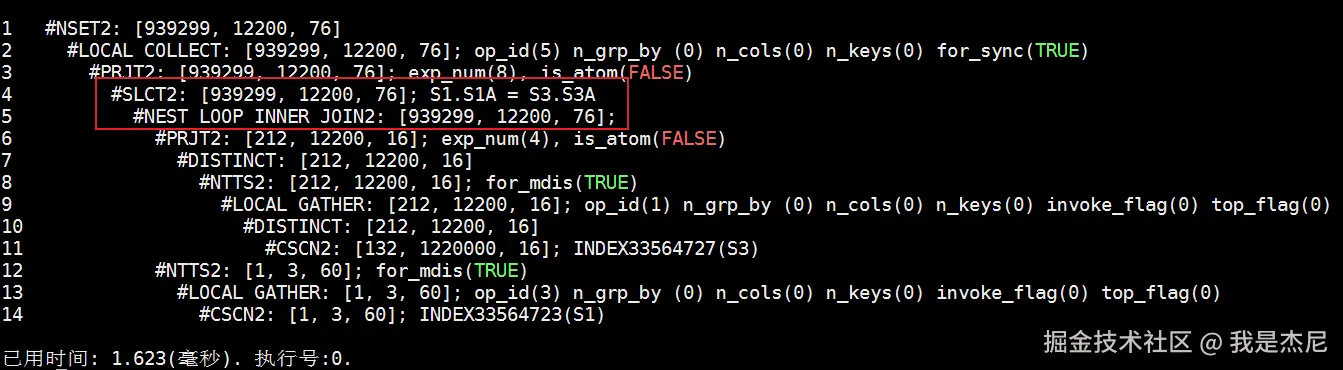
Select * from (select distinct * from s3) s3, s1 where s1.s1a = s3.s3a;执行结果如下:
性能对比:
| 执行策略 | 执行方式 | 耗时 | 性能表现 |
|---|---|---|---|
| 未使用下推 | 子查询全量扫描 + 去重 | 约84ms | 基准 |
| 启用下推 | 扫描阶段提前过滤 | 约0.14ms | 提升600倍 |
| 竞品数据库 | Nested Loop | 约1.62ms | 无明显优化 |
优化后的执行计划中,JOIN 条件在扫描阶段就发挥了作用,使得:
- 去重数据规模显著减少
- 子查询扫描数据量大幅下降
- 后续 JOIN 开销极低
4.2 极端复杂查询测试
为了进一步验证优化效果,我们构造了一个包含以下特性的 SQL:
- 多层嵌套子查询
UNIONDISTINCTWINDOW FUNCTION
在未启用优化时,执行流程如下:
- 左侧子查询进行两次全表扫描
- UNION 合并结果
- 执行 DISTINCT 去重
- 与 s1 进行 JOIN
右侧子查询:
- 全表扫描
- GROUP BY
- 执行窗口函数
最终两个大结果集再进行 JOIN。
执行计划如下:
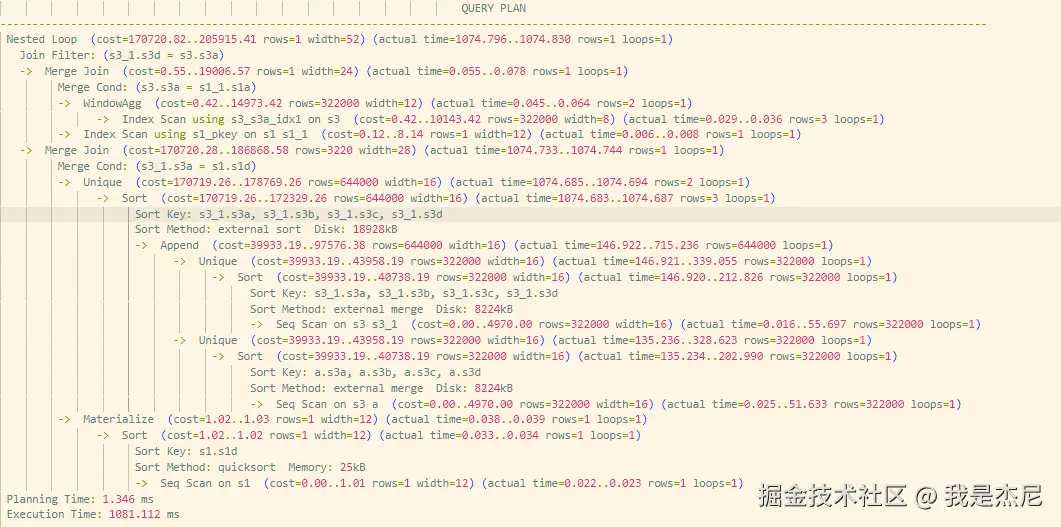
执行时间:
1081ms当启用连接条件下推之后:
- JOIN 条件被注入到各个子查询内部
- 扫描阶段即可进行过滤
- 中间结果集规模显著下降
优化后的执行计划:
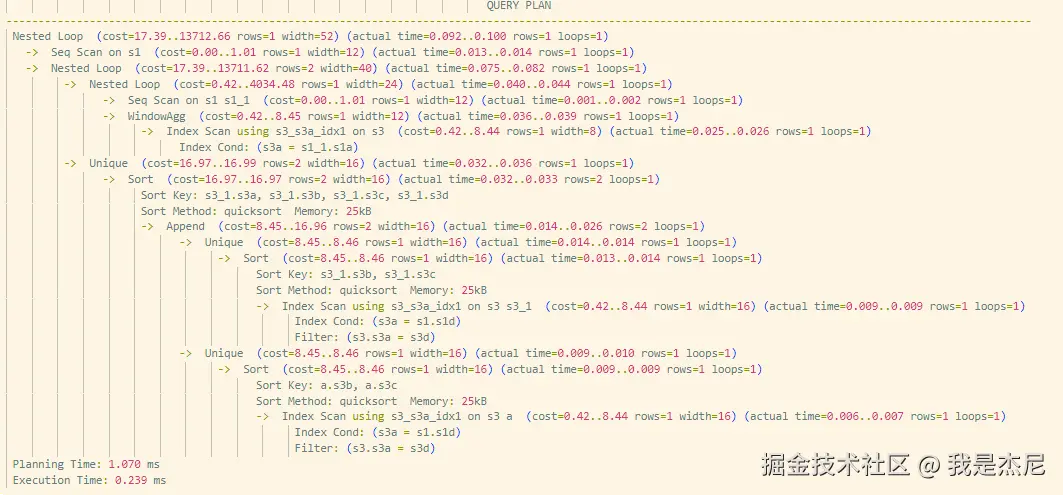
执行时间:
0.23ms整体性能提升接近:
yaml
5000倍五、总结
复杂 SQL 查询的性能问题往往源于一个核心因素:
数据过滤没有在正确的阶段发生。
如果过滤条件能够在数据扫描阶段发挥作用,就可以显著减少中间数据规模,从而提升整体执行效率。
然而,实现这一目标并不简单,因为数据库优化器必须同时解决两个问题:
- 保证查询语义不变
- 确保优化能够带来实际收益
金仓数据库通过 语义等价分析 + 成本模型评估 的双重机制,实现了智能的连接条件下推策略,使得复杂查询在保证正确性的前提下获得显著性能提升。
这一优化对于以下场景尤为重要:
- 数据分析型查询
- 复杂报表系统
- OLAP 场景
- 混合负载数据库
随着数据规模不断增长以及 SQL 查询结构日益复杂,基于代价模型的谓词下推技术也将成为未来数据库查询优化器的重要发展方向之一。