Referer
描述了当前这个页面是从哪里来的(从哪个页面跳转过来的)
浏览器中,直接输入 URL/点击收藏夹打开的网页,此时是没有 referer。当你在 sogou 页面进行搜索时,新进入的网页就会有 referer 
有一个非常典型的用途:广告中
- 在搜索广告中,都是按照点击计费的,双方都要进行次数统计
- 一个公司可能会在很多平台上投放广告,要知道这个点击是从哪个平台上来的,就可以看
referer
referer 是否会被篡改呢?
这种情况在十年前左右是非常常见的,运营商(中国移动/中国联通/中国电信)进行篡改。
-
有动机
- 他们自己有广告系统,就可以把
referer改成他们自己广告系统的referer(比如,明明是从搜狗进入的改为从他们的网站进入的)
- 他们自己有广告系统,就可以把
-
有能力
- 运营商提供了通信设施,在对应的路由器/交换机上部署程序,让程序解析
HTTP数据,把referer改成自己的就可以了
- 运营商提供了通信设施,在对应的路由器/交换机上部署程序,让程序解析
这种行为叫"运营商劫持"。当年,互联网那个还是个新鲜东西,对应的法律还不是特别的完备。官司当然能打,大了官司也肯定能打赢,但是中间花的时间一定会非常长(之前没有可以参考的法律条文或者是相关案例),再加上运营商手下也有强悍的法务团队,进行反复拉扯。赢了官司,输了买卖。
当时百度就联合搜狗、360 这些广告平台,一起去打官司。光法律还不够,在技术上还要进行反制,让你这样的劫持操作不能继续下去。这时候,HTTPS 就登场了。
HTTPS 中的 S 就是 SSL(网络中用于加密的协议),加密就能把 header 和 body 进行加密,网络上传输就是密文了。运营商想要修改,就得先破解,就算你能解密,你也篡改不了(一旦修改就能被用户的浏览器感知到)
当时这些广告平台就纷纷升级成了 HTTPS,后续越来越多的网站都引入了 HTTPS。直到今天,现在网络上 HTTPS 的网站是绝对的主流,反而纯 HTTP 的网站很少见了
Cookie
非常重要的报头中的属性,要更复杂一些。程序员自定义的键值对
浏览器与持久化存储
Cookie 本质上是一个浏览器这边,进行本地持久化存储(数据要存储到硬盘中)数据的机制
浏览器作为电脑上的程序,能否直接读写本地磁盘文件呢?
- 可以,因为系统提供了 API 用来操作文件,作为一个程序当然可以调用这些 API 来操作了
浏览器上运行的网页,能否通过浏览器提供的 API 来读写本地磁盘文件呢?
- 理论可行,但浏览器禁止了这种做法(浏览器并没有给网页提供这样的 API),一个网页不能直接读写你的硬盘文件
- 禁止这种做法是为了安全性。随手一点,网页就打开了。万一打开的是恶意网站,此时人家通过网页直接把你电脑上的所有学习资料都给你删了,必然会造成重大损失
但是确实有些网站,是需要把一些信息保存到浏览器这边,进行持久保存的。比如当前登录用户的身份信息。浏览器退而求其次,给网页提供了这样的 API,能够有限度(按照键值对的格式)的存储数据,而不能随意访问文件系统
Cookie 的作用
Cookie 就是这样的一种存储机制,还有 LocalStorage、indexDB。他们都是浏览器提供的网页可以存储数据的机制
HTTP 请求中的 Cookie 字段,就是把本地存储的 Cookie 信息发送到服务器这边。HTTP 响应中会有一个 Set-Cookie 字段,就是服务器告诉浏览器你要在本地保存哪些信息。这些都是键值对结构,程序员自定义的
Cookie的作用就非常类似于去医院看病的流程
- 先去挂号,办理一个就诊卡
- 来到了脑科,见到医生,医生对我说的第一句话:先刷下就诊卡 。就诊卡上面保存着我这边的一些患者信息,刷卡之后,医生就一目了然了。医生让我去做个 B 超
- 来到了对应科室,医生第一句话还是:先刷下就诊卡。刷卡之后,医生就看到了我要做什么检查
- 回到脑科,拿着单子给医生看结果,医生见到我们还是要我们刷就诊卡。之后医生就给我们开药
- 来到药房
- 来到护士站,看就诊卡,配药打针
- 每次来到一个新的科室,都可以认为是客户端给服务器发起了一个新的请求
- 每次刷的就诊卡,就相当于是使用
Cookie中的信息,来让服务器对我这个客户端有了一个清楚的认识- 就诊卡本身,就是客户端手里拿着的持久存储数据的机制,就是
Cookie
几个重要结论
1. Cookie 从哪里来
服务器返回给浏览器的,通常都是首次访问/登陆成功之后
2. Cookie 到哪里去?
Cookie 会存储在浏览器本地主机的硬盘上,后续每次访问服务器都会带上 Cookie。不同的客户端,保存的 Cookie 是不同的。即使是一个主机,使用不同的浏览器,Cookie 大概率也不同
3. Cookie 中存什么?
键值对格式的数据。这里的内容都是程序员自定义的,和 query string 一样,外人无法知晓。不同网站的 Cookie 都是不一样的(不是一家的,键值对格式就不一样)
4. Cookie 在浏览器这边如何组织?
在硬盘本地保存,是按照不同的域名为维度分别存储。你的浏览器访问百度,有一组 Cookie;访问搜狗,也有一组 Cookie。他们彼此之间是隔离的,不会相互影响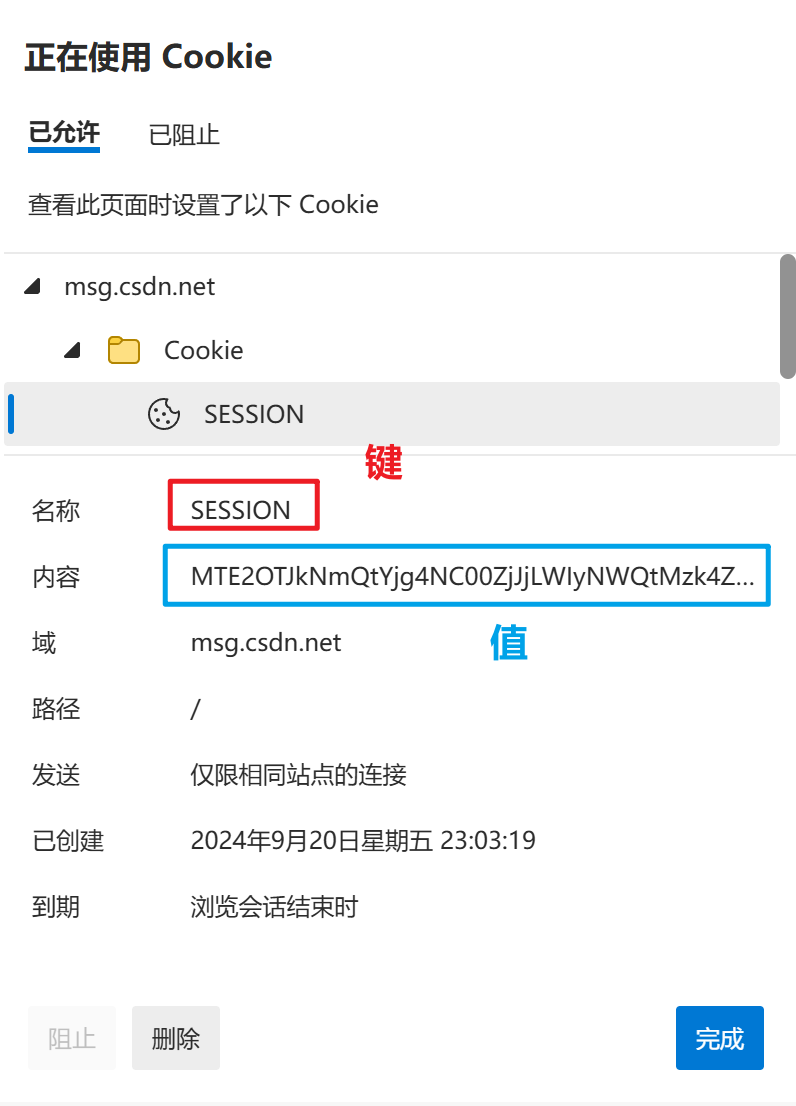
Cookie的用途是什么?
用来在客户端保存数据,其中最主要的是保存用户的身份标识,这样服务器就可以通过标识来区分用户了。
一些其他的业务数据一般不会存储到 Cookie 中,Cookie 随时可以删除掉,把业务数据存储在服务器,通过 Cookie 中的身份标识找到对应的数据(上面开的药,信息就不会存在就诊卡中,而是保存在医院的服务器中,可以通过就诊卡中的数据在医院服务器中找到要的信息)
浏览器中的账号密码不会在
Cookie中保存,Cookie是要传输给服务器的。一般浏览器保存的密码都是明文密码,明文密码放到Cookie中当然不合适。虽然有HTTPS能加密,但HTTPS是侧重于"不能被篡改",而不是"不能被解密"
一个 HTTP 请求中,有以下部分可以携带程序员自定义的数据:
query stringCookiebodyURL的pathpath
之后使用Spring搭建网站,就是围绕上述几个部分,展开进一步的编程