
我的主页:************2的n次方_****************


1. HTTP 的简单介绍
HTTP :超文本传输协议,不仅能传输文本,还能传输图片,音频文件,视频······
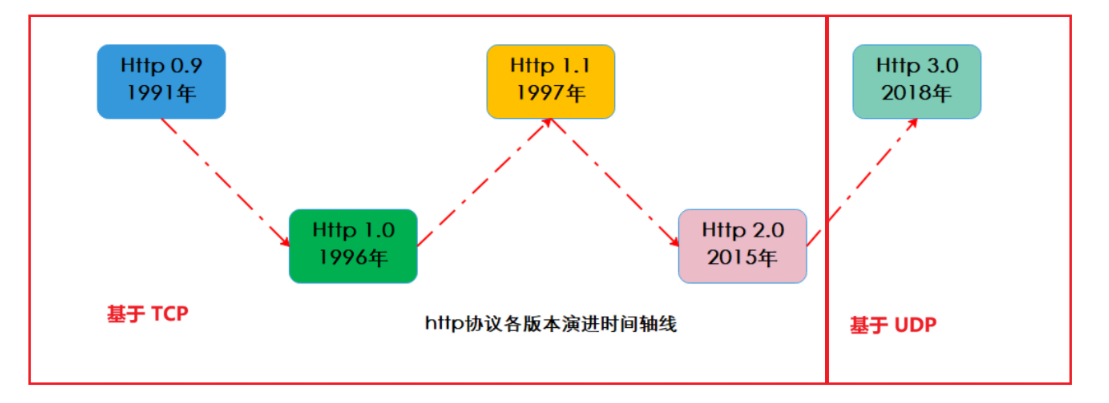
目前基本上都用的是 1.1 版本

https 可以认为是 http 的升级版,区别就是引入了一个"加密层"(https 的安全性更高一些)
2. HTTP的报文格式
2.1. 请求
先来看请求格式:

第一行为请求行,包括方法和 URL 已经对应的版本号,之间通过空格区分
接下来是请求头,每一行通过换行区分,其中是多个键值对,通过":"分割
然后是一个空行,表示请求头的结束
最后是消息主题(可能有也可能没有)

2.2. 响应
响应的基本格式:
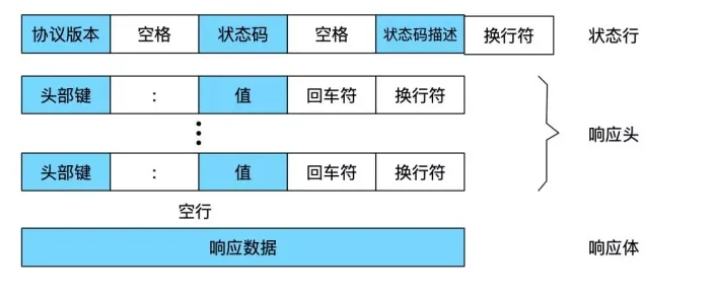
响应和请求的格式是类似的,不过首行表示的是协议的版本号和状态码以及状态码的描述,中间也是用空格区分,其他和请求都是类似的
接下来介绍一下 URL:唯一资源定位符,与之对应的还有一个 URI(唯一资源标识符)
URL 格式:

端口:不写端口的话,浏览器会自动拼接一个端口(不是随机分配的端口,描述的是服务器的端口,是固定的),根据协议,如果是 http,浏览器自动加上 80 端口,如果是 https,浏览器自动加上 443 端口
查询字符串部分(query string):键值对结构,针对访问的资源进行补充说明,可以有多个,一般是程序员自定义的
URL encode:URL 编码)是一种将字符转换为可在 URL 中安全传输的格式的方法。在 URL 中,有些字符具有特殊含义,比如 "/"、"?"、"&" 等。如果 URL 中包含这些特殊字符或者其他一些非 ASCII 字符,可能会导致 URL 解析错误。URL 编码通常将特殊字符和非 ASCII 字符转换为 "%" + 两位十六进制数字的形式。
日常开发时,大多数不需要手动处理转码,使用的一些库中一般是自带了 url encode / decode 的功能的
3. HTTP 的方法
3.1. GET 和 POST
http 的方法:
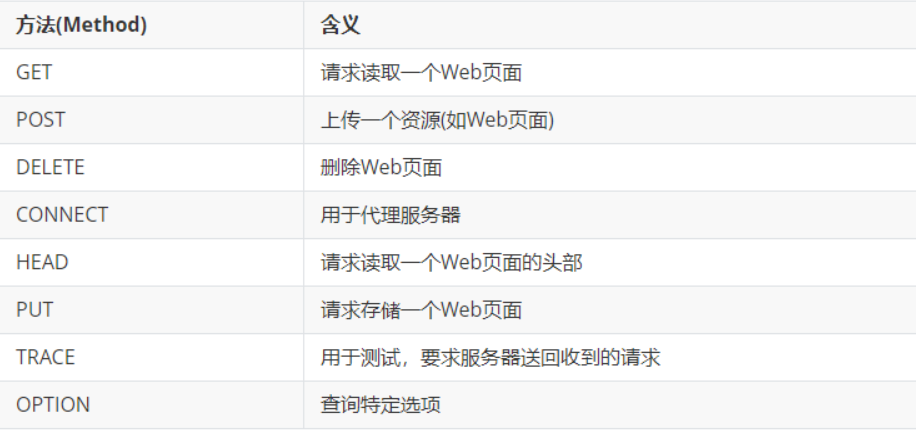
GET:从服务器拿到一个数据,直接在浏览器中输入一个 url 就会触发 GET 请求,HTML 页面中的很多元素会进一步触发 GET 请求,下面用 Fiddler 抓包工具来看一下:
上面的这些大部分都是进一步发出的请求
这里抓包的两种方式:当打开浏览器界面之后再次刷新,此时抓到的请求并不是很多,但是如果使用 ctrl + F5 就会有一堆请求,因为上述得到的内容主要是一些 css,JS,图片等文件,这些内容一般都是固定的,改变频率很低,所以第一次获取时就会缓存到硬盘上,后续再搜索时就没必要重复上面保存的内容了,有效的节省了带宽,加快了页面的展示速度
JS 代码也能够触发 GET 请求
POST:向服务器发送一个数据,一般是登录/注册的场景:

或者是上传一个文件:

大多数情况使用的是 GET,然后就是 POST,其他方法基本不怎么使用
Restful 风格:
post:新增(把给服务器的数据放到 body 中)
delete:删除(把给服务器的数据放到 query string 中)
put:查找(把给服务器的数据放到 body 中)
get:修改(把给服务器的数据放到 query string 中)
3.2. 面试题:GET 和 POST 的区别
其实这两种方法并没有本质的区别,GET 能用的场景 POST 也能用,不过在使用习惯上还是有一定的区别的:
- 语义不同。也就是方法的含义不同,get 就是获取数据,post 就是提交数据,使用 get 提交数据也可以,但并不推荐。
- 传递数据的方式不同。get 传递数据通常是通过 query string 把自定义数据交给服务器,post 传递数据是通过 body 把自定义数据交给服务器,给 get 也能加 body,但是有些库不支持解析
- 在 http 官方文档中,建议 get 方法对应的请求通常设置为幂等的,即多次执行相同的 GET 请求应该产生相同的结果,不会对服务器状态产生副作用。post 方法对幂等性没有要求。
- 承接幂等性。get 方法如果设置为幂等的,此时 get 的结果是可以缓存的,post 不设置为幂等性,post 就不会缓存
4. 请求报头和响应报头
报头(header)是指在请求和响应消息中用于传递附加信息的部分,由一系列的键值对组成,每个键值对称为一个报头字段,报头字段的格式通常为"字段名: 字段值",接下来看一些常见的报头:
- Host: 表示服务器主机的地址和端口。一般情况下和 URL 是一样的。
- **Content-Length:**表示 body 中的数据长度,单位是字节。指明了 http 数据报到哪里会结束,在 http3.0 之前是基于 TCP 的,而 TCP 是面向字节流的,存在粘包问题,当时介绍的解决粘包问题就是指定分隔符和数据报长度。
- **Content-Type:**表示 body 中的数据格式。
在一个请求或响应中,没有 body,就没有上面的两个字段,如果有的话必须要包含上面的两个字段
在 Fiddler 抓个包看一下
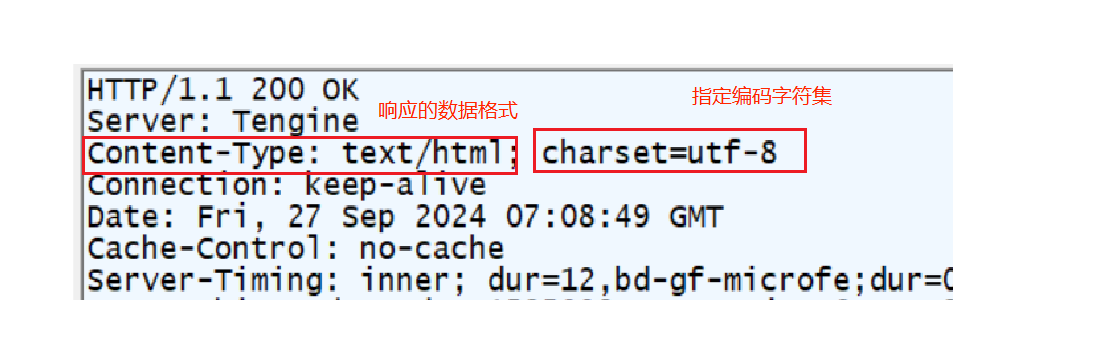
这里就看到了相应的数据格式为 text/html,也会在 Content-Type 中指定 body 的编码格式,如果不指定或者与实际的编码格式不匹配就会出现乱码
除了 text/html 格式外还有下面这些:


一般情况下 ,text/html,text/css,application/javascript 经常出现在响应中,application/json 请求和响应都会出现。
4.1. UA
User Agent(UA):一个向访问的网站提供特定设备和软件信息的字符串

通过 UA 获取用户的浏览器信息和操作系统信息,可以判定当前用户的浏览器版本都支持哪些特性,目前 UA 的主要作用就是用来做数据统计,区分 PC 端和移动端
4.2. Referer 字段
网站可以通过 "Referer" 字段了解用户是从哪个页面链接到当前页面的,以此来分析用户的行为,流量信息等

但是 Referer 字段可以被用户或恶意软件伪造
4.3. Cookie
概念:Cookie 是服务器发送到用户浏览器并保存在本地的一小块数据,当用户再次访问同一服务器时,浏览器会将 Cookie 发送回服务器,按照域名为维度来进行分类,一个域名下可能会有多个 Cookie,后续访问哪个域名就把这个域名下的 Cookie 带入到请求中
结构:Cookie 也是键值对结构,通过"; "来区分键值对,"="来区分键和值,键和值的含义一般也都是程序员自定义的,Cookie 就相当与是浏览器给网站提供的一种"客户端存储数据"的机制

Cookie 里面的内容也是来自于服务器,首次访问某个网站之后,可能是不带 Cookie 的,在首次响应之后就会有 Set-Cookie 这样的报头,把一些键值对写回到浏览器,浏览器后续再访问这个网站就会带有 Cookie
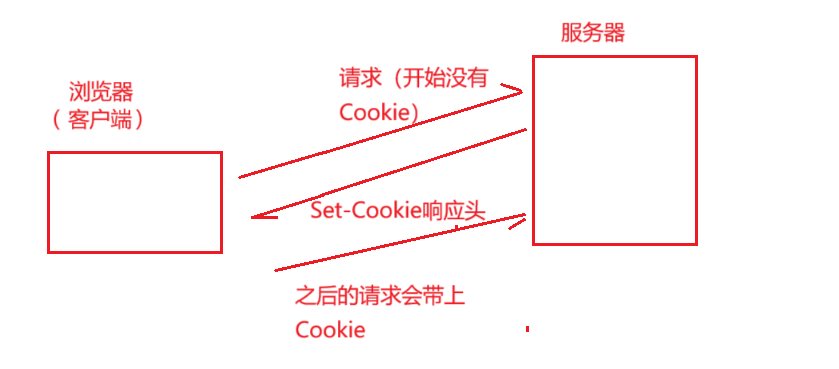
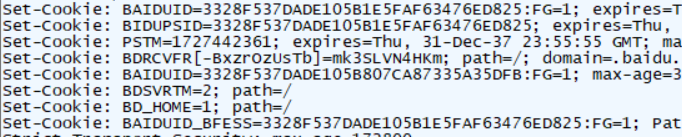
应用场景:浏览器中提示的是否保存此站点密码或者用户的偏好设置,还可以保存用户的登录状态,例如,有的网站登录和未登录之后可供访问的内容不同,当用户首次访问时需要进行登录,登录成功,同时服务器会返回一个身份信息(会话 ID,服务器生成的一个随机的唯一的字符串,服务器也会使用类似哈希表的结构来以 id 为 key,用户信息为值存储),就会通过Cookie 保存下来,之后用户访问其他页面都会带着 Cookie 保存的身份信息去访问,服务器收到 Cookie 之后就会读取到里面的 session id,在哈希表中查找验证
4.4. 状态码
4.4.1. 成功状态
200 OK:表示响应已经成功
4.4.2. 重定向状态码
302 Found:表示请求的资源临时被移动到了其他位置,浏览器会自动重定向到新的 URL。
4.4.3. 客户端出错
403 Forbidden:表示服务器理解请求,但拒绝执行,通常是因为用户没有足够的权限访问资源。

404 Not Found:表示服务器无法理解客户端的请求,可能是请求格式错误,浏览器访问的资源没有在服务器中找到

405 Method Not Allowed:表示服务器接收到的请求方法不被允许,例如尝试使用 POST 方法向一个只允许 GET 方法访问的资源发送请求,服务器就可能返回 405 状态码。
4.4.4. 服务器出错
500 Internal Server Error:表示服务器内部发生错误,无法完成请求。
504 Gateway Timeout:网关超时。当客户端向服务器发送请求,而服务器作为网关或者代理在等待上游服务器的响应时超时,服务器负载过高时就会返回这个状态码。