1.selenium的作用和工作原理
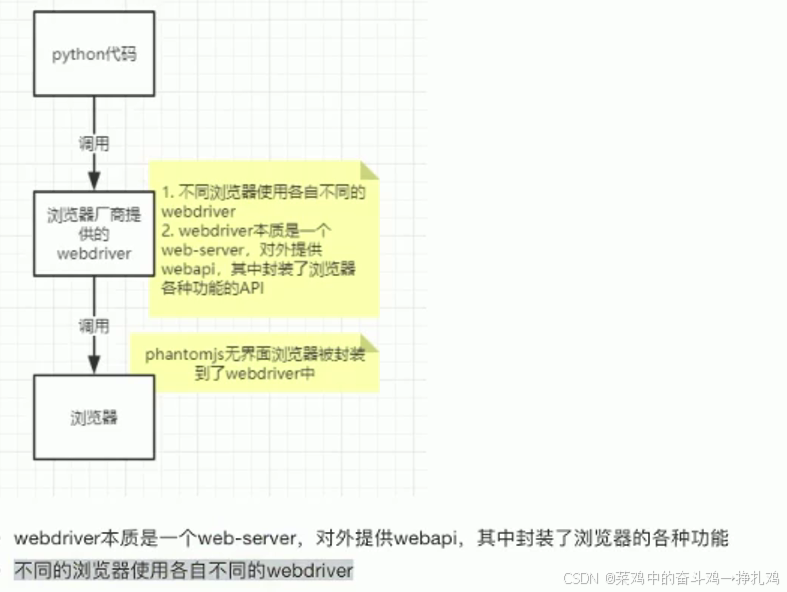
2. 使用selenium,完成web浏览器调用
python
# -*- coding: utf-8 -*-
# 自动化测试工具,降低难度,性能也降低
from selenium import webdriver
driver = webdriver.Edge()
driver.get("https://www.itcast.cn/")
driver.save_screenshot("itcast.png")
print(driver.title)
# 一定要退出!不退出会有残留进程
driver.quit()
# from selenium import webdriver
# from selenium.webdriver.edge.options import Options
#
# # 创建Edge选项对象
# options = Options()
# # 设置无头模式
# 启动无头模式,让浏览器在后台运行
# options.add_argument('--headless')
# 禁用GPU硬件加速,通常建议在无头模式下使用。
# options.add_argument('--disable-gpu')
#
# # 初始化WebDriver并传入无头模式选项
# driver = webdriver.Edge(options=options)
#
# # 访问指定网址
# driver.get("https://www.itcast.cn/")
#
# # 截图并保存
# driver.save_screenshot("itcast.png")
# print(driver.title)
#
# # 一定要退出!避免残留进程
# driver.quit()3.简单使用
python
# -*- coding: utf-8 -*-
import time
from selenium import webdriver
from selenium.webdriver.common.by import By # 导入 By 模块
driver = webdriver.Edge() # 启动 Edge 浏览器
driver.get("https://www.baidu.com")
time.sleep(3)
# 在百度搜索框中使用 XPath 搜索 'python'
driver.find_element(By.XPATH, '//*[@id="kw"]').send_keys('python') # 使用 XPath 定位
# 或者使用 CSS Selector 搜索 'python'
# driver.find_element(By.CSS_SELECTOR, '#kw').send_keys('python') # 使用 CSS Selector 定位
# 在百度搜索框中搜索'python'
# driver.find_element(By.NAME, 'wd').send_keys('python') # 使用 By.NAME 定位搜索框
# 点击'百度搜索'
driver.find_element(By.ID, 'su').click() # 使用 By.ID 定位'百度一下'按钮
time.sleep(6)
# 退出浏览器
driver.quit()4.driver的属性和方法

python
# -*- coding: utf-8 -*-
import sys
import time
from selenium import webdriver
# 设置标准输出为utf-8编码
sys.stdout.reconfigure(encoding='utf-8')
url = 'http://www.baidu.com'
# 创建浏览器对象
driver = webdriver.Edge()
# 访问指定url地址
driver.get(url)
# # 显示源码
# print(driver.page_source)
# # 显示响应对应的url
# print(driver.current_url)
#
# time.sleep(3)
# driver.get('http://www.douban.com')
#
# time.sleep(3)
# driver.back()
#
# time.sleep(2)
# driver.forward()
#
# time.sleep(3)
# # driver.close()
# 用于验证是否运行或验证码截图保存处理
driver.save_screenshot('baidu.png')
driver.quit()4.元素定位
elements = driver.find_elements(by=By.<定位方式>, value='选择器')
常用的定位方式:
By.ID:通过元素的 ID 属性查找元素。
By.NAME:通过元素的 name 属性查找元素。
By.XPATH:通过 XPath 查找元素。
By.CSS_SELECTOR:通过 CSS 选择器查找元素。
By.CLASS_NAME:通过元素的类名查找元素。
By.TAG_NAME:通过标签名称查找元素。
By.LINK_TEXT 和 By.PARTIAL_LINK_TEXT:通过链接的文本查找元素。
常用XPATH和CSS_SELECTOR(万金油XPATH)
下面代码使用的是:driver.find_element() 注意这里element没有加s,只适用于单个元素。
python
# -*- coding: utf-8 -*-
import time
from selenium import webdriver
from selenium.webdriver.common.by import By # 导入 By 模块
driver = webdriver.Edge() # 启动 Edge 浏览器
driver.get("https://www.baidu.com")
time.sleep(3)
# 在百度搜索框中使用 XPath 搜索 'python'
driver.find_element(By.XPATH, '//*[@id="kw"]').send_keys('python') # 使用 XPath 定位
# 或者使用 CSS Selector 搜索 'python'
# driver.find_element(By.CSS_SELECTOR, '#kw').send_keys('python') # 使用 CSS Selector 定位
# 在百度搜索框中搜索'python'
# driver.find_element(By.NAME, 'wd').send_keys('python') # 使用 By.NAME 定位搜索框
# 点击'百度搜索'
driver.find_element(By.ID, 'su').click() # 使用 By.ID 定位'百度一下'按钮
time.sleep(6)
# 退出浏览器
driver.quit()selenium结合XPATH简单使用:
python
# -*- coding: utf-8 -*-
from selenium import webdriver
from selenium.webdriver.common.by import By
# 打开目标URL
url = 'https://cq.58.com/hezu/?PGTID=0d100000-0002-59f0-74d2-1a2d488460c0&ClickID=5'
# 初始化Edge浏览器
driver = webdriver.Edge()
# 打开页面
driver.get(url)
# 使用 find_elements 获取所有匹配的元素
el_list = driver.find_elements(By.XPATH, '/html/body/div[6]/div[2]/ul/li/div[2]/h2/a')
# 遍历并打印每个元素
for el in el_list:
print(el.text) # 打印元素的文本内容
# 关闭浏览器
driver.quit()