文章目录
- 一、分布式与微服务概念
- 二、Dubbo基本概念
-
- [1. 核心组件](#1. 核心组件)
- [2. 工作流程](#2. 工作流程)
- [3. 主要特性](#3. 主要特性)
一、分布式与微服务概念
1.大型互联网架构目标
- 传统项目和互联网项目的区别:
传统项目用户:企业员工
互联网项目:网民
在互联网时代,随着用户基数的急剧增长和技术的不断进步,互联网项目与传统项目相比有了显著的区别。互联网项目主要面向广泛的网民群体,而传统项目则更多服务于特定的企业内部员工。因此,互联网项目更加注重用户体验,包括界面的美观度、功能的丰富性、加载的速度以及系统的稳定性。
用户体验: 关注美观、功能、速度、稳定性。
- 衡量网站的性能指标:
- 响应时间: 指执行一个请求从开始到最后收到响应数据所花费的总体时间。
- 并发数: 指系统同时能处理的请求数量。
- 并发连接数: 指的是客户端向服务器发起请求,并建立了TCP连接,每秒钟服务器连接的总TCP数量。
- 请求数: 指每秒请求数(QPS)。请求数>=并发连接数
- 并发用户数: 单位时间内有多少用户访问。
- 吞吐量: 指单位时间内系统能处理的请求数量。
- QPS: 每秒查询书。
- TPS: 每秒事务数。一个事务是指一个客户机向服务器发送请求然后服务器做出反应以及客户机收到反应的过程。
- 高性能: 提供快速的访问体验。
- 高可用: 网站服务一直可以正常访问。
- 可伸缩: 通过硬件增加/减少,提高/降低处理能力。
- 高可扩展: 系统间耦合低,可以很方便地新增/移除功能/模块。
- 安全性: 提供网站安全访问和数据加密,安全存储等策略。
- 敏捷性: 随需应变,快速响应。
2.集群和分布式
在互联网架构中,为了实现上述目标,通常会采用集群和分布式计算的技术方案。通过集群,可以将多台服务器组合成一个整体来提供服务,从而达到负载均衡和故障冗余的目的。而分布式计算则是将任务分散到多台计算机上并行处理,进一步提高系统的处理能力和效率。
(1)集群 (Cluster)
集群是指一组协同工作的计算机节点,它们作为一个整体对外提供服务。集群技术主要用于解决单点故障问题,提高系统的可靠性和可用性,同时也能通过负载均衡来提升系统的处理能力。在互联网应用中,常见的集群类型包括:
- Web服务器集群:通过负载均衡器将请求分发给多个Web服务器实例,以分散请求压力,提高响应速度。
- 数据库集群:采用主从复制或多主复制模式,确保数据的一致性和可靠性,同时支持读写分离,增强数据库的处理能力。
- 缓存集群:利用分布式缓存技术,如Redis Cluster或Memcached,加速数据读取速度,减轻后端数据库的压力。
(2)分布式计算 (Distributed Computing)
分布式计算是一种计算模型,其中多台计算机通过网络连接,共同完成一项任务。每台计算机称为节点,它们之间通过消息传递进行通信和协作。分布式计算的核心优势在于能够充分利用网络中各节点的计算资源,实现大规模数据处理和复杂任务的并行执行。在互联网架构中,分布式计算的应用非常广泛,例如:
- 分布式文件系统:如Hadoop HDFS,用于存储海量数据,支持数据的高可靠性和高可扩展性。
- 分布式数据库:如Cassandra和MongoDB,设计用于处理大规模数据集,支持水平扩展和高并发访问。
- 分布式消息队列:如Kafka和RabbitMQ,用于异步处理数据流,实现系统间的解耦,提高系统的稳定性和响应速度。
- 分布式计算框架:如Apache Spark和Flink,用于执行复杂的分析任务,支持实时数据处理和机器学习算法。
(3)集群与分布式的关系
虽然"集群"和"分布式"这两个术语经常被一起提及,但它们侧重的方面有所不同:
- 集群更关注于如何将多台机器组织起来,共同提供服务,重点在于提高系统的可用性和性能。
- 分布式则更强调如何将一个任务分解为多个子任务,由网络中的多个节点并行处理,重点在于数据的分布存储和计算任务的并行执行。
然而,在实际应用中,两者往往是相辅相成的。例如,在一个分布式系统中,为了提高系统的可用性和性能,通常会采用集群技术来部署关键组件,如Web服务器、数据库和缓存等。同样,一个集群系统也可能需要使用分布式计算技术来处理大规模数据和复杂任务。
(4)实践中的应用案例
- 电商网站:在大型促销活动期间,电商平台需要处理巨大的流量。通过将Web服务器、数据库和缓存部署为集群,可以有效地分担请求压力,确保系统的稳定运行。同时,使用分布式消息队列处理订单和物流信息,可以提高系统的响应速度和处理能力。
- 大数据平台:在处理PB级别的数据时,分布式文件系统和分布式计算框架是必不可少的工具。通过将数据切片存储在多台机器上,并利用MapReduce等算法并行处理数据,可以大幅缩短数据处理的时间。
3.架构演进
单体架构 -> 垂直架构 -> 分布式架构 -> SOA架构 -> 微服务架构
(1)单体架构

- 单体架构: 把所有模块放在一起的应用。
- 优点:开发和部署都简单方便
- 缺点:项目启动型慢,可靠性差,扩展性、可维护性、可伸缩性都差,性能不好
(2)垂直架构

- 垂直架构: 将单体架构中的多个模块拆分成多个独立的项目。
- 优点:从一定程度上解决了单体结构可靠性差,扩展性、可维护性、可伸缩性都差,性能不好的问题。
- 缺点:重复的功能太多。
(3)分布式架构

- 分布式架构: 在垂直架构的基础上,将公共业务模块抽取出来,作为独立的服务,供其他调用者消费,以实现服务的共享和重用。通过RPC协议来进行服务彼此的调用。
- 优点:解决了垂直架构重复功能太多的问题。
- 缺点:服务提供方一旦产生变更,所有消费方都需要变更。
(4)SOA架构

- SOA架构: SOA,即Service-Oriented Architecture,面向服务的架构,是一个组件模型,将应用程序拆分成不同的服务,并根据接口和契约将这些服务联系起来。
- ESB:Enterprise Service Bus,企业服务总线,服务中介,主要是提供了一个服务于服务之间的交互。提供了负载均衡、流量控制、加密处理、服务监控、异常处理、监控报告等功能。
(5)微服务架构
- 微服务架构: 在SOA上进行了升级。业务彻底地组件化和服务化,原有的单个业务系统拆分为多个可以独立开发、设计、运行的小应用。小应用之间通过服务完成交互和集成。
- 特点:
- 服务组件化,开发者可以自由选择开发技术,也不需要协调其他团队;
- 服务间交互一般使用Rest API;去中心化,每个微服务都有自己私有的数据库持久化业务数据;
- 各个微服务可以很方便很独立地自动化部署、测试、运维。
- 特点:

Dubbo是一种广泛使用的Java RPC框架,它诞生于SOA时代,而Spring Cloud则是微服务架构下的一套解决方案,它们分别代表了两个不同阶段的技术实践。
二、Dubbo基本概念
阿里巴巴公司开源的一个高性能、轻量级的Java RPC框架,后被Apache收购。
- 架构:
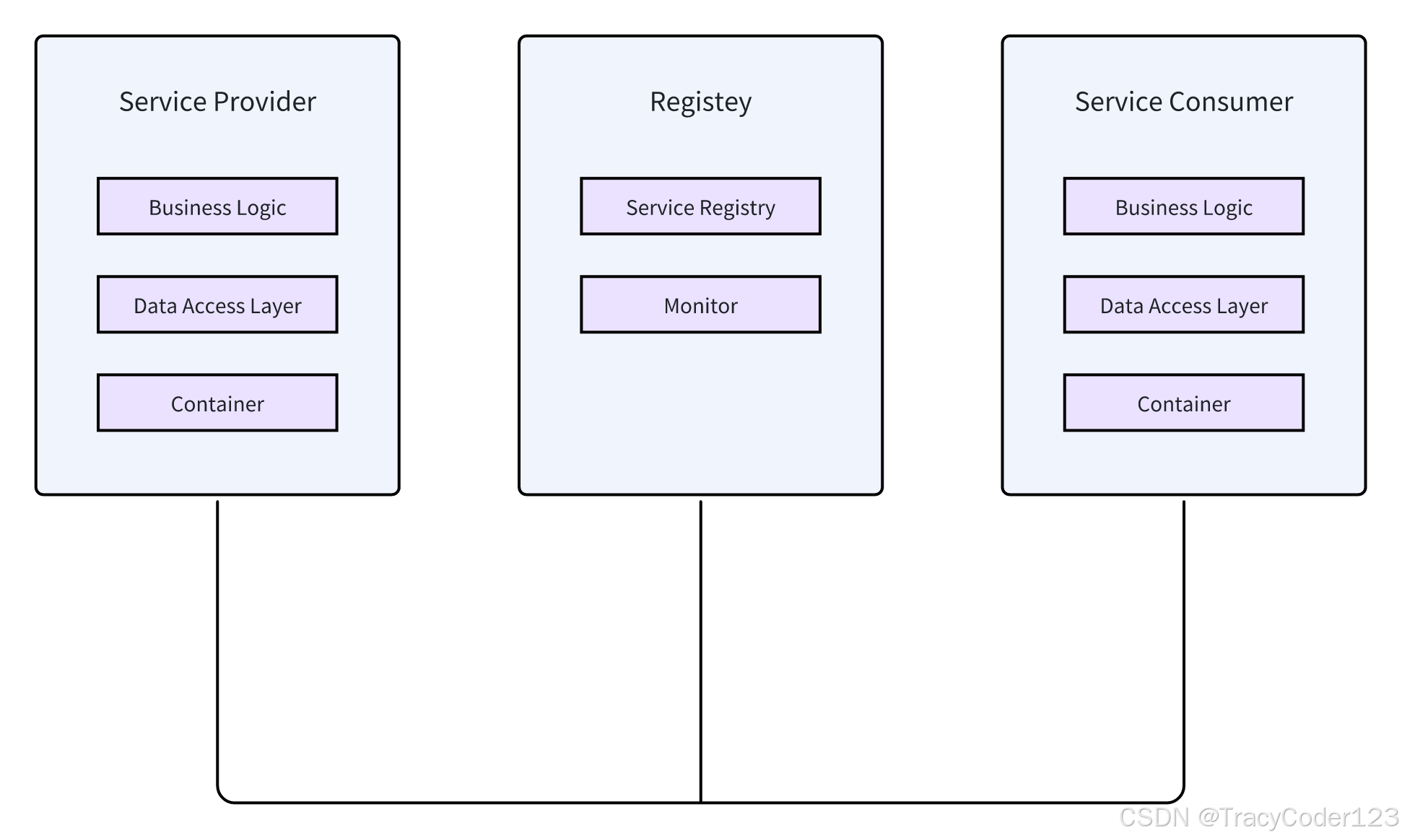
Service Provider:服务提供者,负责实现业务逻辑并将服务注册到注册中心。
Registry:注册中心,管理服务提供者和消费者的地址列表及状态。
Service Consumer:服务消费者,通过注册中心发现服务并发起远程调用。
1. 核心组件
Dubbo 的架构主要包括以下几个核心组件:
- Provider(服务提供者):暴露服务的服务提供方,负责实现服务,并将服务注册到注册中心。
- Consumer(服务消费者):调用远程服务的服务消费方,通过注册中心发现服务,并发起远程调用。
- Registry(注册中心):管理服务提供者和消费者的地址列表及状态,支持服务的动态注册与发现。常见的注册中心实现有 ZooKeeper、Nacos 等。
- Monitor(监控中心):收集服务调用的统计信息,如调用次数、成功率、平均耗时等,用于服务治理和性能优化。
- Container(容器):服务运行的容器,如 Spring 容器、Jetty 容器等,负责启动和管理服务提供者和消费者。
2. 工作流程
-
服务提供者启动:
- 服务提供者启动时,会将自身的服务地址和接口信息注册到注册中心。
- 注册中心会维护一个服务提供者的列表,记录每个服务的地址、版本号等信息。
-
服务消费者启动:
- 服务消费者启动时,会从注册中心订阅所需的服务。
- 注册中心会将服务提供者的地址列表推送给服务消费者,并在服务提供者列表发生变化时通知消费者。
-
服务调用:
- 服务消费者通过本地代理对象(Stub)调用远程服务。
- 本地代理对象通过网络将请求发送到服务提供者。
- 服务提供者接收到请求后,执行业务逻辑并返回结果。
- 结果通过网络返回给服务消费者,服务消费者通过本地代理对象获取到结果。
-
监控:
- 监控中心会收集服务调用的统计信息,如调用次数、成功率、平均耗时等。
- 监控中心可以用于服务治理和性能优化,帮助管理员及时发现和解决问题。
3. 主要特性
- 透明化的远程方法调用:开发者只需编写本地方法调用的代码,无需关心底层的网络通信细节。
- 智能容错和负载均衡:Dubbo 提供了多种负载均衡策略(如随机、轮询、最少活跃调用数等),并在服务调用失败时自动切换到其他服务提供者。
- 服务自动注册与发现:服务提供者和消费者通过注册中心进行服务的注册和发现,简化了服务的管理和维护。
- 高性能:Dubbo 使用 Netty 作为网络通信框架,支持高效的异步非阻塞 I/O 操作。
- 丰富的配置管理:支持多种配置方式(如 XML、注解、API 等),方便开发者根据需求进行配置。