在Hadoop的core-site.xml文件中存在三个可选配置,如下
xml
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.users</name>
<value>hdfs,yarn</value>
</property>使用最多的是上面两个,但是它们是干什么的很多人就蒙圈了,只知道配置hive或者其他生态圈服务时配置上就能让鉴权好使,为什么好使说不上来,这篇就告诉你这三个配置是干啥的
首先Hadoop整体用户体系,采用的是依赖Linux用户模式,它自己不主动生成,只会在一个linux用户首次操作hdfs时,默认在hdfs:/namenode:端口/user下生成一个对应用户的主路映射,当然有些服务或操作用的是/tmp路径,会在/tmp下对应的服务路径下生成用户映射路径,而不是/user,但是这个映射路径里面通常情况下是没有东西的,比如说环境变量等等这些在hdfs中是不存在的,对于hdfs主管上来讲只有一种情况里面会有东西,就是某个用户去操作的东西需要某些类库时,hdfs会自动将用到的资源放在该用户的映射路径下。
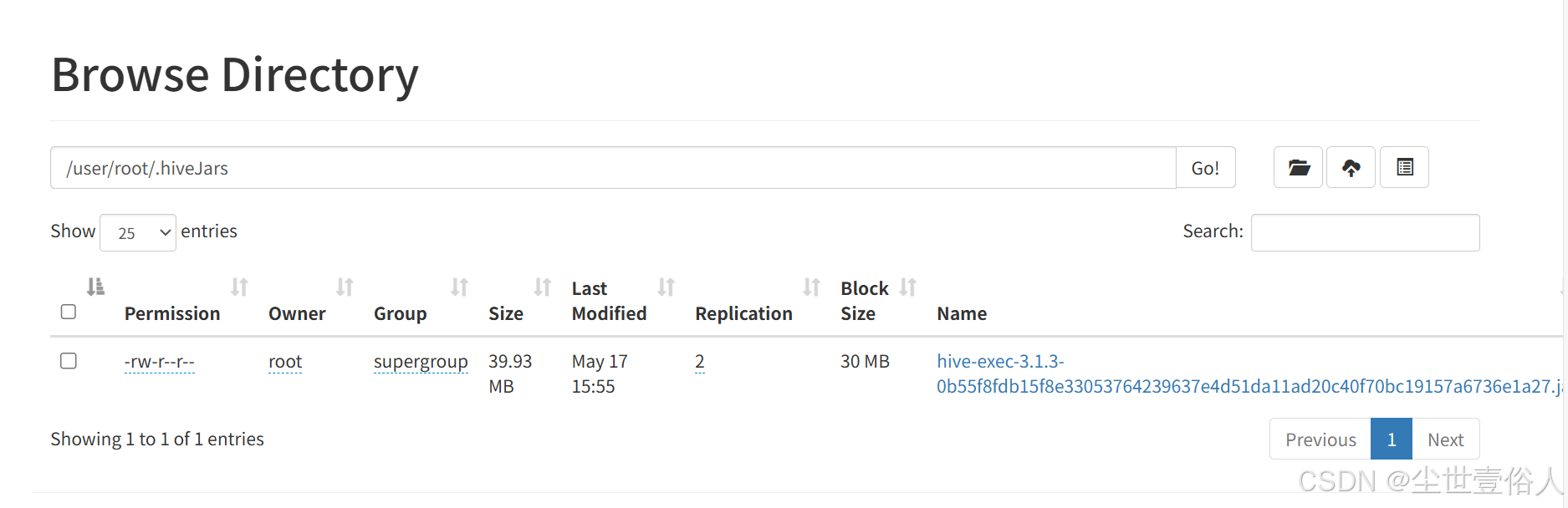
最常见的就是hive服务,如果手边有测试集群,按照你的搭建手册可以在代理用户的映射路径下看到如下的类似路径以及资源
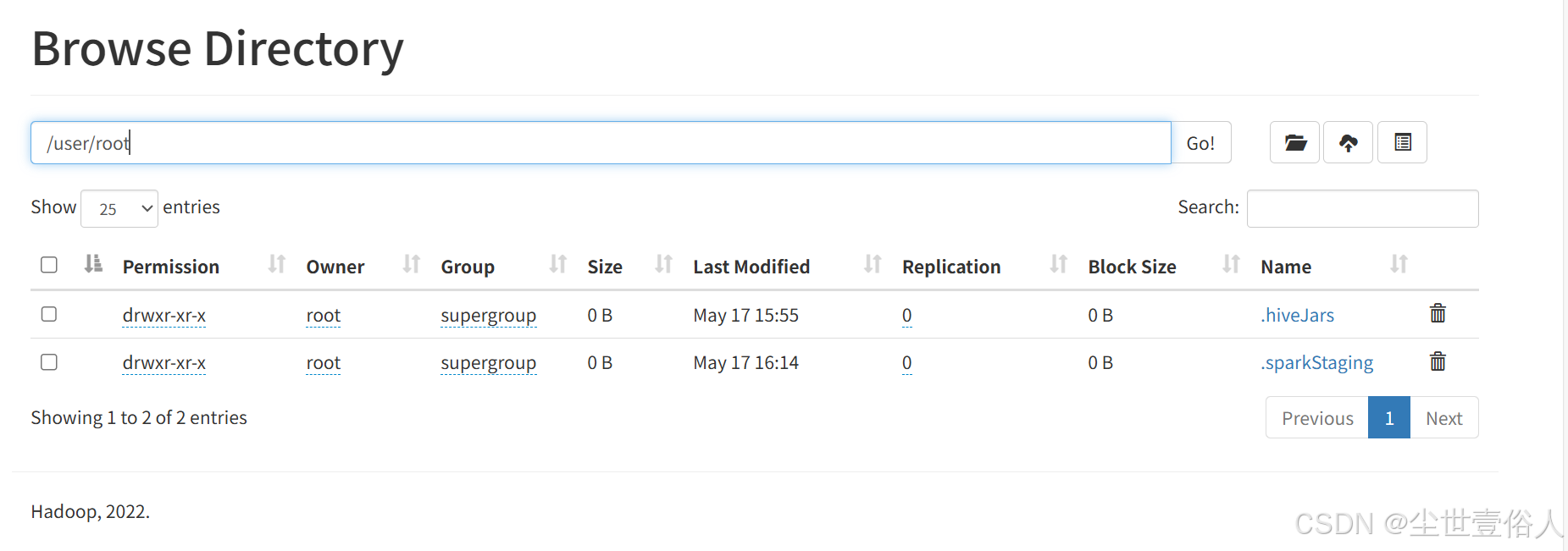
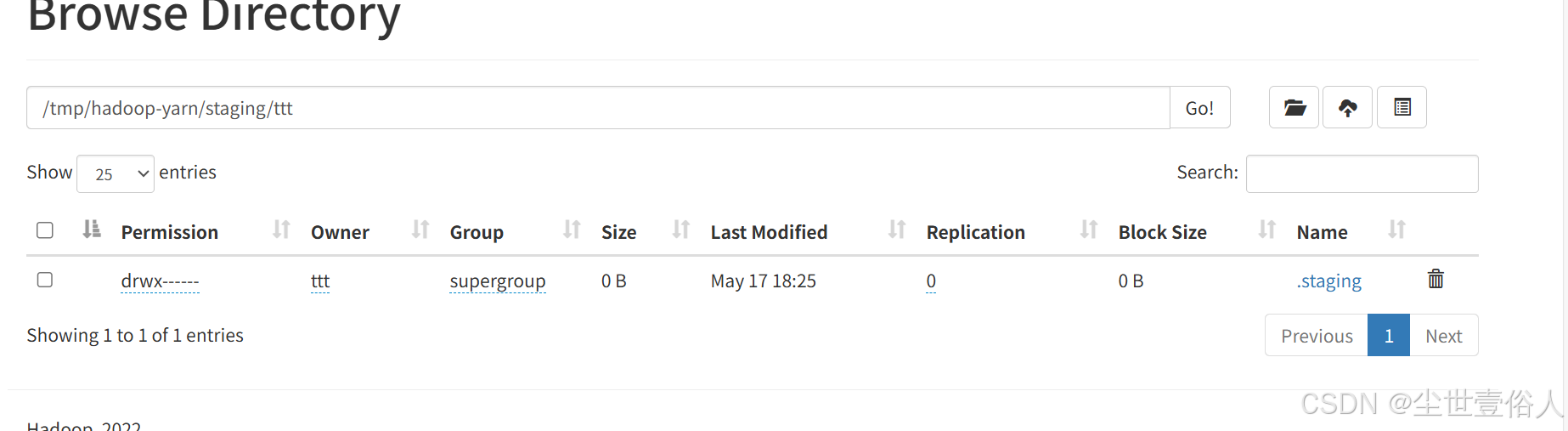
再或者提交mr之后,会在/tmp下的hadoop-yarn下生成映射路径并,存在一个临时任务提交路径
到此,hadoop依靠linux用户体系实现了不同用户的权限隔离,但是hadoop自身有两个权限风险
1、它自身的构建用户(2.x是文件所属以及运行format的用户,3.x是文件所属以及配置文件中写死的用户),拥有不在权限隔离能力之内的超级权限
2、hdfs中,是否有路径读取权限看的是路径自身的权限控制,但是能否写操作看的是目标路径的父路径权限,注意是第一级父路径,再往上的父级没有影响,这就导致当A、B两个用户,在一个同组、其他用户有写权限的路径下的所有文件是可以互删的,所以hadoop默认的路径权限是755
对于第一个风险,hadoop并没有做一刀切,因为一个文件系统确实需要一个超级用户的角色,比如作为使用方你把linux的root用户密码泄露了,总不能说是Linux的不适吧。不过hadoop2.x从3.x发展时加强了安全相关的控制细节,使得3.x的超级管理用户可以在配置文件中更改
重点是第二个风险,为了数据安全业内有很多处理方案,比如hadoop本身支持你不用hdfs,只要技术足够,你可以内嵌其他的文件系统,比如百度的BOS对象存储系统。但如果你仍然选择使用hdfs,在合理设置默认文件路径权限的同时,争对确实有跨用户身份的场景,比如hive这种启动之后多用户各自操作表的服务,hadoop提供了开头的三个配置
三个配置作用是向hadoop表明,当前存在一个起到代理作用的用户,它要在后期使用时,能够用来代替受信域内所有用户的身份,从而以对应身份做相关操作。所有被标记为代理作用的用户hadoop在内部都会有一系列的安全管控,并提供了统一的api,使得其他服务内部可以去调用做正常的鉴权,作为使用方,你不需要关注,你只需要知道一个服务,要想在hadoop上,执行多用户直接操作就必须持有一个用来做代理的代理用户。
不止hive,早先的hue、ooize都是这样,就以以hive为例,当你不配置代理用户,或者配置了代理用户,但是启动服务器用的不是代理用户,此时在hive的日志文件中,你就会看到如下的报错User ${启动服务的用户} is not allowed to perform this API call。关键是这个报错只会出现在hive的log4j日志文件中,如果你没放开log4g,你会永远卡在hivemeta、hiveserver2启动不报错,单hiveserver2一直在重试sessionid的流程上
同样的代理用户会持有一切必要的资源,比如hive的exe.jar,这点就和最开始的截图中显示的那样。
综上所述,这三个配置只要你的授信域是合理的,且正常使用,就不用担心代理用户会主动拥有授信域下用户的权限,这里的主动是指非授信域发起操作时,代理用户被随意登录直接以授信域权限操作某些东西,因为代理用户是面向服务端以统一的api接口管控,也不用担心授信域内任何一个用户都有其他用户的权限,因为是代理用户获得了授信域内用户的身份,去做操作,而不是授信域用户直接以代理角色去执行操作
一般情况下,任然采用hdfs的场景,如果是私有云,这一点一般不操作,公有云的话会设一道路径墙,通俗的将就是hdfs上除了hive的数据存放根路径之外的其他路径权限都是700,hive数据存放根路径自身是700,不同用户申请账号的时候单独在下面存在一个用户级别隔离的路径,按照需要另行设置权限
其实这个东西在Hadoop2.x较低版本的时候,你不配置也不影响使用,只是随着时间的推移,hadoop的安全相关越来越严格
至于代理用户,商用环境下一般都是给专属某个服务配置代理,比如hive服务的用户,或者其他的一些,至于授信域,一般没有特殊需求就是*,而授信域是ip、用户组、还是某个用户就看具体情况而定了
最后要说的是一个使用上的注意点,使用hadoop配置好代理用户之后,会稍微影响服务的连接或者使用方式,就用hive来说,当你配置一个名为hive的用户做代理用户,并以hive用户启动服务之后,在服务器上用beeline连接的话,非hive用户就不能直接写/opt/hive-3.1.3/bin/beeline -u jdbc:hive2://node1:10000 -n root -p 123456这样的启动连接命令了,这点和hive配置了hiveserver2高可用一样,其他用户使用,必须在beeline的会话窗口中连接
bash
[root@node1 ~]# /opt/hive-3.1.3/bin/beeline
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/hive-3.1.3/lib/log4j-slf4j-impl-2.17.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/hadoop-3.2.3/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Beeline version 3.1.3 by Apache Hive
beeline> !connect jdbc:hive2://node1:10000
Connecting to jdbc:hive2://node1:10000
Enter username for jdbc:hive2://node1:10000: hive
Enter password for jdbc:hive2://node1:10000: ******
Connected to: Apache Hive (version 3.1.3)
Driver: Hive JDBC (version 3.1.3)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://node1:10000> select * from a;如果非hive用户使用参数直接连接,会报下面的错误
bash
[root@node1 opt]# /opt/hive-3.1.3/bin/beeline -u jdbc:hive2://node1:10000 -n hive -p 123456
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/hive-3.1.3/lib/log4j-slf4j-impl-2.17.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/hadoop-3.2.3/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Connecting to jdbc:hive2://node1:10000
25/05/17 23:53:50 [main]: WARN jdbc.HiveConnection: Failed to connect to node1:10000
Could not open connection to the HS2 server. Please check the server URI and if the URI is correct, then ask the administrator to check the server status.
Error: Could not open client transport with JDBC Uri: jdbc:hive2://node1:10000: java.net.ConnectException: Connection refused (Connection refused) (state=08S01,code=0)
Beeline version 3.1.3 by Apache Hive