阿华代码,不是逆风,就是我疯
你们的点赞收藏是我前进最大的动力!!
希望本文内容能够帮助到你!!

目录
引入:
通过之前的学习,我们了解到CAS本质上是JVM替我们封装好的,我们没有办法感知到
在java.util.concurrent中存放了一些我们多线程编程时常用的类
 是不是非常熟悉,我们把这个packet包简称为(JUC)
是不是非常熟悉,我们把这个packet包简称为(JUC)
一:Callable和FutureTask类
读法:"开了波哦" 译为:调用
1:对比Runnable
Runnable提供run方法,返回值为void------关注过程,不关注执行结果
Callable提供call方法,返回值类型就是执行结果的类型---------更关注结果
2:FutureTask类
在Callable中的call方法中完成任务的描述后,我们要想办法发这个任务加载给线程Thread,
但是Thread类中并没有给出Callable的构造方法,于是我们通过FutureTask这个中间类(可以理解为加载任务的装置),作为媒介,发射给Thread
即:
Callable中描述方法------卢本伟来啦~~
FutureTask中加载任务------卢本伟已准备就绪~~
Thread中传入futureTask任务执行------卢本伟启动!!
注:
Callable和FutureTask实例化的时候<>中要写返回结果的类型哦。
futureTask.get()方法是带有阻塞功能的,如果线程还没有执行完毕,get就会被阻塞,等到线程执行完了,return的结果就会被get返回回来
3:代码示例
问题:计算前5000个数字之和
看以下两段代码------用Callable类写的代码比Runnable类写的代码更加优雅~~
示例一:Runnable
java
package thread;
public class ThreadDemon37 {
private static int sum = 0;//全局变量用来保存最后的结果值
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread(new Runnable() {
int count = 0;//局部变量
@Override
public void run() {
for (int i = 1 ; i <= 5000 ; i++){
count += i;
}
sum = count;
}
});
t1.start();
t1.join();
System.out.println(sum);
}
} 示例二:Callable
示例二:Callable
此处我们不用再引入额外的成员变量了,直接借助返回值即可
java
package thread;
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.FutureTask;
public class ThreadDemon38 {
public static void main(String[] args) throws InterruptedException, ExecutionException {
Callable<Integer> callable = new Callable<Integer>() {
@Override
public Integer call() throws Exception {
int sum = 0;
for (int i = 0; i <= 5000; i++) {
sum += i;
}
return sum;
}
};
//Thread t1 = new Thread(callable);//Thread中没有提供构造函数来传入callable
//引入FutureTask类,未来要完成的任务(任务还未执行)
// 相当于在Callable中确定执行的任务
//在FutureTask装置中完成任务加载------卢本伟准备就绪~~~
//最后引入线程------卢本伟启动!!
FutureTask<Integer> futureTask = new FutureTask<>(callable);
Thread t1 = new Thread(futureTask);
t1.start();
t1.join();
System.out.println(futureTask.get());//装置获得一下结果
}
}
补充一点:.futureTask.get()方法本身自带阻塞特性,如果Callable任务还没有执行完,是会一直等待它的返回值结果的
二:ReentrantLock------可重入锁
读音:"瑞安纯特老科" 翻译为:可重入锁
科普:ReentrantLock在很早以前是比没有发展起来的synchronized功能更加强大的,他提供了两个传统的方法lock和unlock,但是在写代码的过程中lock完后往往会忘记unlock解锁,所以一般把unlock操作放到finally里面使用
1:与synchronized的区别
(1)不会阻塞
我们知道synchronized加锁,如果线程"锁竞争"失败,会陷入阻塞等待,使用了ReentrantLodk提供了trylock方法后,如果加不上锁就会返回false,不会阻塞等待。
(2)公平锁
ReentrantLock中加锁依据是:公平锁 ,所有参与**"加锁"的线程**会被放进队列里面,按顺序进行加锁。
(3)唤醒机制不同
synchronized提供wait和notify,ReentrantLock搭配Condition,功能比notify强一点
三:Semaphore------信号量
读音:"赛摸佛尔" 翻译为:信号量
科普:因为发明信号量的大佬迪杰斯特拉是个荷兰人,荷兰语的申请和释放首字母分别是P和V。实际上英语是acquire和release
1:P操作
申请一个可用资源,可用资源总数就会-1
2:V操作
释放一个可用资源,可用资源总数就会+1
打个比方:去停车场停车,现在有50个停车位,申请一个停车位(p操作),现有可用停车位为49;出来了一辆车(v操作),现有可用停车位为50;
3:PV代码示例一
java
package thread;
import java.util.concurrent.Semaphore;
/**
* Created with IntelliJ IDEA.
* Description:
* User: Hua YY
* Date: 2024-09-30
* Time: 10:26
*/
public class ThreadDemon39 {
public static void main(String[] args) throws InterruptedException {
Semaphore semaphore = new Semaphore(1);//资源数限制为1个
semaphore.acquire();
System.out.println("p操作");
semaphore.acquire();//第二次申请
System.out.println("p操作");
semaphore.acquire();//第三次申请
System.out.println("p操作");
}
}
4:锁功能
信号量是更为广义的锁
代码示例:继续沿用解决count计数器++线程安全问题的方式
java
package thread;
import java.util.concurrent.Semaphore;
/**
* Created with IntelliJ IDEA.
* Description:
* User: Hua YY
* Date: 2024-09-30
* Time: 10:33
*/
public class ThreadDemon40 {
private static int count = 0;
//引入Semaphore进行加锁
private static Semaphore semaphore = new Semaphore(1);
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread(() -> {
try {
semaphore.acquire();//加锁
for (int i = 1 ; i <= 50000 ; i++){
count++;
}
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
semaphore.release();//解锁
});
Thread t2 = new Thread(() ->{
try {
semaphore.acquire();//加锁
for (int i = 1 ; i <= 50000 ; i++){
count++;
}
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
semaphore.release();//解锁
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(count);
}
}
四:CountDownLatch
1:引入
latch(锁存器)
举个例子,现在下载软件的速度非常快,用的是多线程下载方式,比如要下载一个1G大小的软件,我们把这个任务分成10份,**分给10个线程同时进行下载,最后在拼在一起,**速度就会快非常多。
这个"拼"的操作,就能被CountDownLatch感知到,比我们用join要更简单方便一些
2:代码示例
java
package thread;
import java.util.Random;
import java.util.concurrent.CountDownLatch;
/**
* Created with IntelliJ IDEA.
* Description:
* User: Hua YY
* Date: 2024-09-30
* Time: 10:57
*/
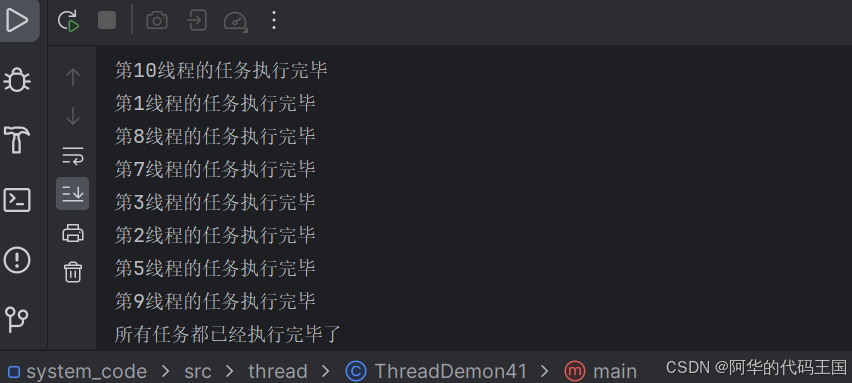
public class ThreadDemon41 {
public static void main(String[] args) throws InterruptedException {
CountDownLatch latch = new CountDownLatch(10);//创建10个线程
Random random = new Random();
int time = (random.nextInt(4)+1)*1000;//time的范围[0,4]->[1,5]->[1000,5000]
for(int i = 1 ; i <= 10 ; i++){
int count = i;
Thread t = new Thread(() ->{
try {
Thread.sleep(random.nextInt(time));//产生的随机数的范围
System.out.println("第" + count + "线程的任务执行完毕");
latch.countDown();//告知CountDownLatch有一个任务已经执行完毕了
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
});
t.start();
}
latch.await();//如果CountDownLatch中的任务还没有执行完毕,那么CountDownLatch就会陷入阻塞等待
System.out.println("所有任务都已经执行完毕了");
}
}
五:多线程环境使用ArrayList
引入:
原来的集合类,大部分都是线程不安全的,但是有几个例外:Vector,Stack,HashTable(这几个类现在官已经不太推荐使用了,后续可能会删掉)------因为哪怕实在单线程下也要加锁,这种情况不合理(往下看)
在这些类内部中,把一些关键的方法都加锁了,导致它们不仅在多线程场景下要加锁,而且在单线程场景下也要加锁。虽然JVM中有"锁消除"机制,但这也不是万能的,加锁带来的资源消耗依旧是不可忽视的(单线程下就没必要加锁了嘛)
1:顺序表使用同步机制
使用synchronized和ReentrantLock进行加锁,上文有提及两者的区别,往上面翻翻~~
2:套壳封装
使用Collections.synchronizedList(new ArrayList)
因为ArrayList本身各种操作都是不带锁的,我们把它作为参数传入,相当于给ArrayList封装 一下,套入Collections.synchronizedList()这个壳中,得到一个新的对象,这个新的对象调用关键的方法操作都是带有锁的
3:写时拷贝
使用CopyOnWriteArrayList
(1)添加/修改元素操作
如果我们往一个容器里面添加元素,我们不往这个容器中添加,而是先copy一份新容器,往新的容容里面添加或者修改元素
添加修改完元素之后,在将引用指向新的容器
(2)优点
①可以进行并发读 ,在"读多写少"的场景下效率非常高(在引用指向新的容器之前,读操作都可以在旧容器上完成)
(3)缺点
①相应的顺序表如果太大,copy的开销也变高了
②"写操作"非常频繁,copy的频率就会非常高,资源的消耗和占用就比较严重
③不能第一时间读到新写的数据
(4)使用场景
服务器加载配置文件的时候,就会把文件内容解析出来放到内存的数据结构中,配置文件体积小,而且修改频率低
六:多线程环境使用队列
这边以前的文章有总结过就不再加以详述
主要以自己加锁和使用BlockingQueue为主
七:多线程环境使用哈希表(面试高频)
引入
在多线程环境下,Hashtbale是线程安全的,因为在Hashtable内部的关键方法中都有进行synchronized加锁操作。
但是HashMap就不行了,在数组的基础上还涉及到链表和树化
1:ConcurrentHashMap
于是我们就加以改进,引入了ConcurrentHashMap(并发HashMap),以下是我们的改进过程
(1)缩小锁粒度
①HashMap中的加锁
当我们尝试对HashMap中的不同链表下的不同元素进行修改操作的时候,就会触发锁竞争
因为这个锁是针对整个HashMap(this)而言的
如下图中我们想修改元素1和元素2,就会触发锁竞争,
重点:
但实际上修改不同链表上的元素操作,并不会触发线程安全问题(加大了加锁的频率,资源浪费)
只有在修改同一个链表下的(相邻必触发:因为操作会涉及到同一个引用)元素可能会触发线程安全问题
于是我们在ConcurrentHashMap中进行了优化

②ConcurrentHashMap中的加锁
锁对象为每个数组中的元素**(链表的头结点)**,此时如果修改同一个链表下的元素,就会触发锁竞争。
**理解:**相当于把一个大锁拆分成了好多把小锁(这就是缩小锁粒度)
**优点:**不仅解决了线程安全问题,还降低了加锁的频率,节约了资源
注:这里的锁的数量虽然很多,但并不会增加太多的资源消耗,因为加锁对象(头结点)是现成的,不需要我们再去创建了

(2)使用CAS原子操作
在ConcurrentHashMap中,比如针对哈希表中的元素个数的维护,我们使用CAS就可以减少一些加锁。
用synchronized加锁,咱们不知道加锁处于那种阶段(程度)的加锁------可能是偏向锁,轻量级化加锁,甚至是最后升级为重量级化加锁,这件事都是不可预估的
(3)扩容的优化
负载因子=元素个数/数组长度 ,0.75是一个扩容阈值指标
①HashMap扩容机制
如果数组元素个数太多会进行扩容,链表下元素个数太多会进行树化
扩容:创建一个更大数组,把旧Hash表上的元素一下子搬过去**(一把梭哈)**,如果元素数量非常多,这里的copy操作就会非常的耗费时间,实际表现就是突然间某个操作非常卡
②ConcurrentHashMap扩容机制
扩容时,每次只搬运一部分元素,随着每次的插入/删除/添加/查找操作,都会搬运一部分元素。
内部机制:扩容时,有两份哈希表
插入操作------往新表上插
删除操作------新表旧表都删
查找操作------新表旧表都查
**优点:**确保每次操作耗费的时间都不长,避免出现卡顿的情况
**缺点:**整体扩容的时间变长了