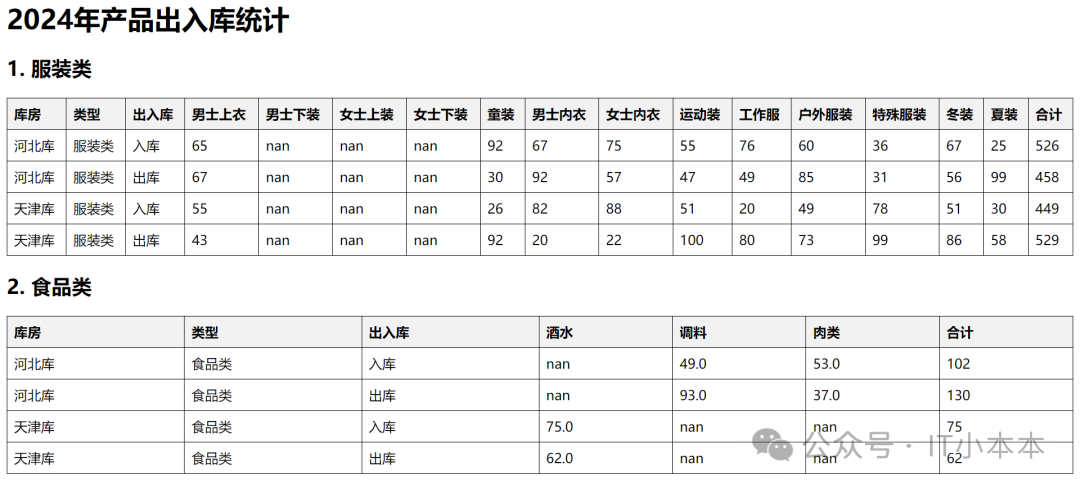
有如下数据,需要对数据合并处理,输出到数据库。
数据样例:👇
excel内容:
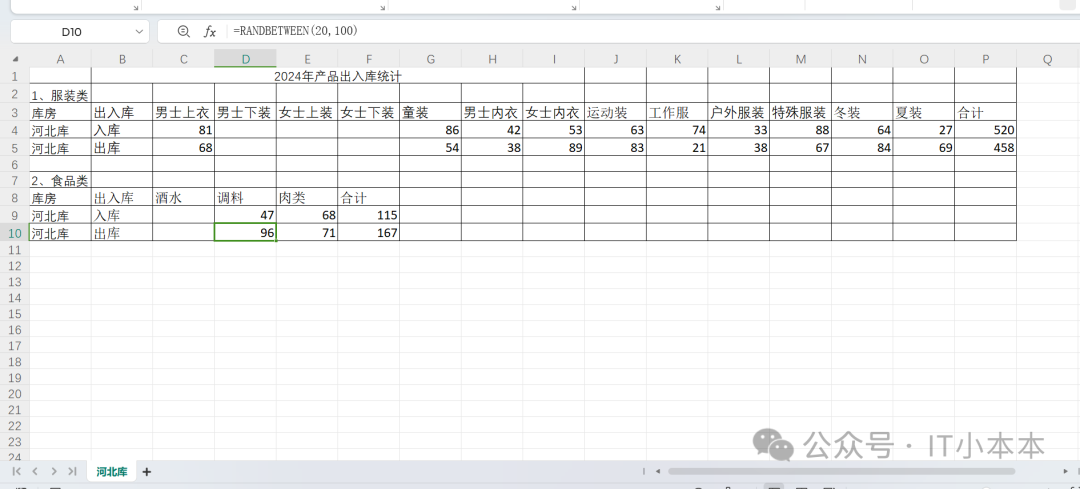
出入库统计表河北库.xlsx:
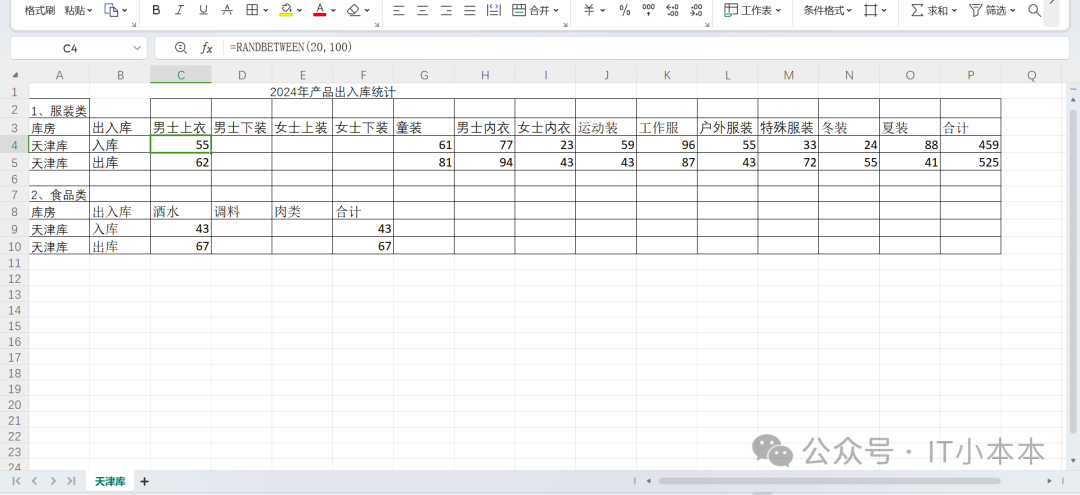
出入库统计表天津库.xlsx:
01实现过程
1、创建test.py文件,然后将下面代码复制到里面,最后运行
python
# 导入必要的库,pandas 用于数据处理,sqlalchemy 用于连接数据库
import pandas as pd
from sqlalchemy import create_engine
def read_excel_data(file_name):
# 读取整个 Excel 文件,header=None 表示不使用第一行作为列名
df = pd.read_excel(file_name, header=None)
# 找到服装类和食品类的起始行,使用 df[df[0] == '条件']来筛选特定内容的行,index[0]获取索引,+1 得到起始行的下一行
clothing_start = df[df[0] == '1、服装类'].index[0] + 1
food_start = df[df[0] == '2、食品类'].index[0] + 1
# 读取服装类数据,header 参数指定起始行,nrows 指定读取的行数
clothing_df = pd.read_excel(file_name, header=clothing_start, nrows=2)
# 读取食品类数据,同理
food_df = pd.read_excel(file_name, header=food_start, nrows=2)
return clothing_df, food_df
# 定义一个函数用于从 Excel 文件中读取特定部分的数据
# 读取河北库和天津库的数据
df1_clothing, df1_food = read_excel_data('出入库统计表河北库.xlsx')
df2_clothing, df2_food = read_excel_data('出入库统计表天津库.xlsx')
# 调用函数读取两个不同库的服装类和食品类数据
# 合并服装类数据,pd.concat 用于连接多个 DataFrame
clothing_combined = pd.concat([df1_clothing, df2_clothing])
clothing_combined['类型'] = '服装类'
# 将两个库的服装类数据合并,并添加类型列
# 合并食品类数据,同理
food_combined = pd.concat([df1_food, df2_food])
food_combined['类型'] = '食品类'
# 定义列顺序
clothing_columns = ['库房', '类型', '出入库', '男士上衣', '男士下装', '女士上装', '女士下装', '童装',
'男士内衣', '女士内衣', '运动装', '工作服', '户外服装', '特殊服装', '冬装', '夏装', '合计']
food_columns = ['库房', '类型', '出入库', '酒水', '调料', '肉类', '合计']
# 处理服装类数据,reindex 用于重新排列列的顺序
clothing_result = clothing_combined.reindex(columns=clothing_columns)
# 处理食品类数据,同理
food_result = food_combined.reindex(columns=food_columns)
# 生成 HTML 内容
html_content = f"""
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>2024 年产品出入库统计</title>
<style>
table {{
width: 100%;
border-collapse: collapse;
}}
th, td {{
border: 1px solid black;
padding: 8px;
text-align: left;
}}
th {{
background-color: #f2f2f2;
}}
</style>
</head>
<body>
<h1>2024 年产品出入库统计</h1>
<h2>1. 服装类</h2>
<table>
<thead>
<tr>
{''.join([f'<th>{col}</th>' for col in clothing_columns])}
</tr>
</thead>
<tbody>
{''.join([f'<tr>{" ".join([f"<td>{item}</td>" for item in row])}</tr>' for row in clothing_result.values])}
</tbody>
</table>
<h2>2. 食品类</h2>
<table>
<thead>
<tr>
{''.join([f'<th>{col}</th>' for col in food_columns])}
</tr>
</thead>
<tbody>
{''.join([f'<tr>{" ".join([f"<td>{item}</td>" for item in row])}</tr>' for row in food_result.values])}
</tbody>
</table>
</body>
</html>
"""
# 使用字符串格式化生成 HTML 内容,包括表格结构和数据
# 将 HTML 内容写入文件
with open('output.html', 'w', encoding='utf-8') as file:
file.write(html_content)
# 打开文件并写入生成的 HTML 内容
# 连接 MySQL 数据库
engine = create_engine('mysql+pymysql://root:root@127.0.0.1:3306/test01')
# 使用 sqlalchemy 创建数据库连接引擎
# 将数据写入 MySQL 数据库
clothing_result.to_sql('clothing_table', con=engine, if_exists='replace', index=False)
food_result.to_sql('food_table', con=engine, if_exists='replace', index=False)
# 将处理后的服装类和食品类数据分别写入 MySQL 数据库中的不同表,如果表已存在则替换,并且不写入索引列02最终结果
1、找到output.html

2、双击output.html运行看到如下结果