
引言:编程世界的革命性思维
作为一名程序员,你一定遇到过这些糟心时刻:
- 程序运行到一半突然崩溃,提示"段错误"
- 多线程环境下数据莫名其妙被改乱
- 内存使用量不断增长,最后程序因为内存不足而崩溃
这些问题在C/C++中很常见,但在Rust中,它们大多在编译阶段就被消灭了!秘诀就是Rust的所有权系统和零成本抽象哲学。
第一部分:惊奇的内存管理新思维
内存管理的演进:从手动到自动
编程语言的内存管理主要有三种方式:
- 手动管理(C/C++):程序员自己分配和释放内存,容易出错
- 垃圾回收(Java/Go/Python):运行时自动回收不再使用的内存,但有性能开销
- 所有权系统(Rust):编译时通过规则保证内存安全,无运行时开销
Rust选择了第三条路,通过编译时的严格检查,既保证了安全,又获得了性能。
环境搭建:在Windows + VSCode中搭建Rust游乐场
安装Rust
- 下载安装包:
-
- 访问 https://www.rust-lang.org/tools/install
- 下载 rustup-init.exe
- 运行安装:
-
- 双击运行
rustup-init.exe
- 双击运行
-
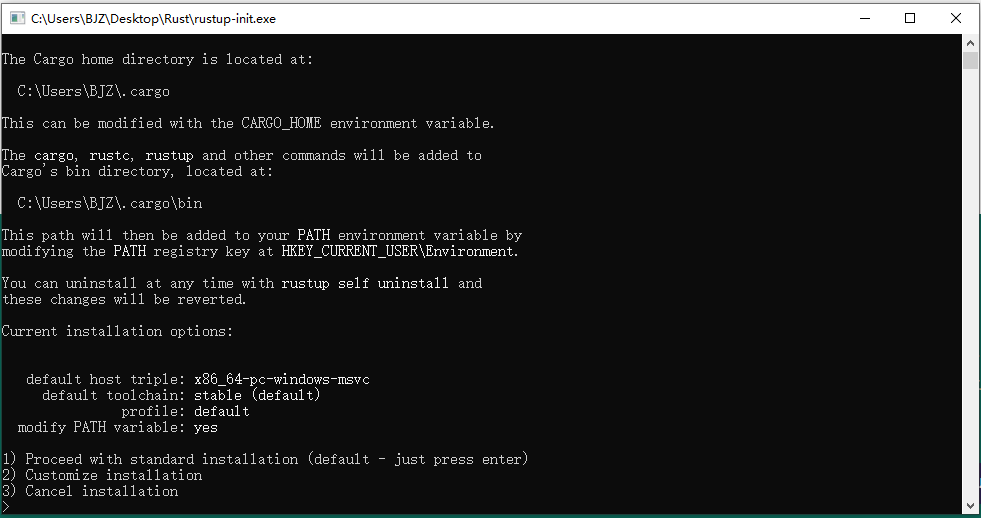
- 按回车选择默认安装(推荐)
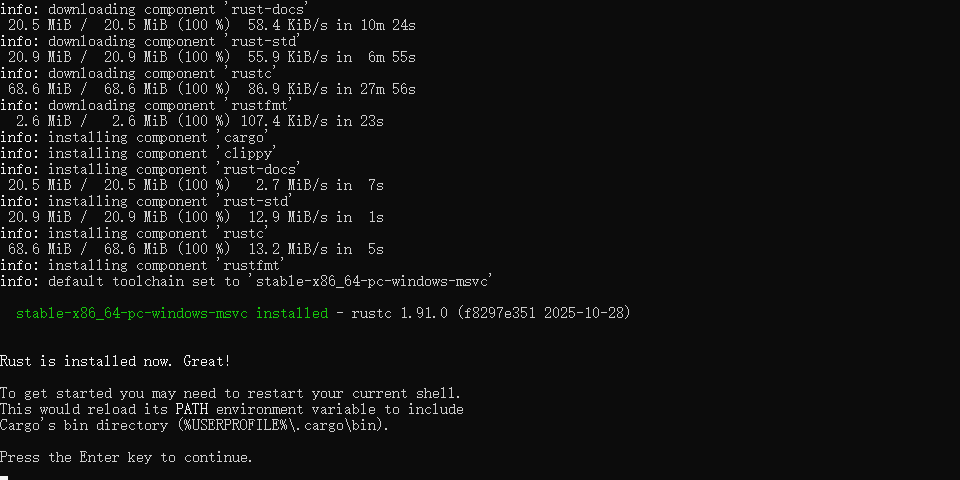
- 等待安装完成
-
验证安装:打开新的命令提示符或PowerShell,输入:
rustc --version
cargo --version
配置VSCode
- 安装Rust扩展:
-
- 打开VSCode
- 点击左侧扩展图标(或按 Ctrl+Shift+X)
- 搜索并安装 rust-analyzer 扩展
- 安装其他有用扩展(可选):
-
- Better TOML - 用于编辑Cargo.toml文件
- crates - 帮助管理依赖
- CodeLLDB - 调试支持
创建第一个项目
在PowerShell或命令提示符中:
# 创建项目目录
cargo new rust_learning
cd rust_learning
# 用VSCode打开项目
code .
项目结构:
rust_learning/
├── Cargo.toml
└── src/
└── main.rs所有权三定律------Rust的"交友规则"
在深入代码之前,先记住所有权的三条基本规则:
- 唯一主人:Rust中的每个值都有一个称为其所有者的变量
- 一次一人:一次只能有一个所有者
- 人走茶凉:当所有者离开作用域,这个值将被丢弃
String类型------所有权的完美示例
场景1:基本的所有权转移
fn main() {
println!("=== 所有权基础演示 ===");
// 创建一个String(在堆上分配内存)
let s1 = String::from("hello");
println!("s1 = {}", s1);
// 所有权从s1转移到s2
let s2 = s1;
// 这行会编译错误!s1已经不再拥有数据
// println!("s1 = {}", s1); // 取消注释会报错
println!("s2 = {}", s2); // 这个可以正常工作
println!("s1 的所有权已经转移给 s2 了!");
}运行 cargo run 你会看到输出。现在取消注释那行代码,看看编译器错误:
error[E0382]: borrow of moved value: `s1`为什么需要这样?
fn main() {
println!("=== 深入理解所有权转移 ===");
let s1 = String::from("hello");
// 此时内存布局:
// 栈上 (s1): [ptr → 堆内存地址, len=5, capacity=5]
// 堆上: ['h', 'e', 'l', 'l', 'o']
println!("创建 s1 成功,数据在堆上");
let s2 = s1;
// 发生了什么:
// 1. 不是深度复制堆数据(那样成本高)
// 2. 只是复制了栈上的指针信息
// 3. s1 被标记为"已移动",不能再使用
// 4. 这样避免了双重释放内存的问题!
println!("s1 移动到 s2,s1 现在无效了");
println!("这是为了防止同一块内存被释放两次");
}克隆------当真的需要复制数据时
fn main() {
println!("=== 克隆:真正的复制 ===");
let s1 = String::from("hello");
println!("s1 = {}", s1);
// 深度复制:复制堆上的数据
let s2 = s1.clone();
// 现在两个变量都有效!
println!("克隆后:");
println!("s1 = {}", s1);
println!("s2 = {}", s2);
println!("看,这次两个都可以用了!");
println!("但注意:克隆是有成本的,它真的在堆上复制了数据");
}什么时候使用克隆?
- 当你确实需要数据的独立副本时
- 当性能开销可以接受时
- 对于小对象或一次性操作
函数调用中的所有权舞蹈
所有权进入函数
fn take_ownership(some_string: String) {
println!("函数内部接收到的: {}", some_string);
// some_string在这里离开作用域,drop函数被自动调用,内存被释放
println!("函数结束,some_string 的内存被自动释放");
}
fn main() {
println!("=== 函数中的所有权转移 ===");
let s = String::from("hello");
println!("调用函数前: s = {}", s);
// s的所有权被移动到函数中
take_ownership(s);
// 这行会编译错误!s的所有权已经没了
// println!("调用函数后: s = {}", s); // 取消注释会报错
println!("s 的所有权已经交给函数,再也回不来了");
}返回所有权
fn take_and_give_back(some_string: String) -> String {
println!("函数处理: {}", some_string);
some_string // 返回所有权
}
fn main() {
println!("=== 所有权往返 ===");
let s1 = String::from("hello");
println!("调用函数前 - s1 = {}", s1);
// s1的所有权移动到函数,然后返回给s2
let s2 = take_and_give_back(s1);
// s1已经无效,但s2有效
// println!("s1 = {}", s1); // 错误!
println!("调用函数后 - s2 = {}", s2); // 正确!
println!("所有权完成了一次往返旅行");
}借用------不用交出所有权的"租借"
fn calculate_length(s: &String) -> usize {
s.len()
// 这里s离开作用域,但因为它是引用,不会drop实际数据
}
fn main() {
println!("=== 引用:所有权的租借 ===");
let s1 = String::from("hello");
println!("s1 = {}", s1);
// 传递引用,不转移所有权
let len = calculate_length(&s1);
// s1仍然有效!
println!("'{}' 的长度是 {}", s1, len);
println!("看,s1 还在!我们只是'借'给了函数");
}可变引用
fn change(s: &mut String) {
s.push_str(", world");
}
fn main() {
println!("=== 可变引用 ===");
let mut s = String::from("hello");
println!("修改前: {}", s);
change(&mut s);
println!("修改后: {}", s);
println!("我们成功修改了字符串,但没有转移所有权!");
}引用规则------防止数据竞争
fn main() {
println!("=== 引用规则演示 ===");
let mut s = String::from("hello");
// 规则1:可以有多个不可变引用
let r1 = &s;
let r2 = &s;
println!("r1 = {}, r2 = {}", r1, r2);
// 规则2:只能有一个可变引用
let r3 = &mut s;
// let r4 = &mut s; // 错误!不能同时有两个可变引用
r3.push_str(" world");
println!("r3 = {}", r3);
// 规则3:不能同时有可变和不可变引用
// let r5 = &s; // 错误!这里已经有可变引用在使用
// println!("{}", r5);
println!("这些规则在编译期防止了数据竞争!");
}引用规则的内存安全保证:
- 多个读取者:安全,不会冲突
- 单个写入者:安全,没有竞争
- 读写混合:不安全,被禁止
实战示例------理解所有权的价值
fn create_and_destroy() {
let s = String::from("临时字符串");
println!("在函数中创建: {}", s);
// 函数结束,s自动被释放
}
// 这行会报错!无法返回局部变量的引用
// fn dangerous_operation() -> &String {
// let s = String::from("局部字符串");
// &s // 返回局部变量的引用 - 悬空指针!
// }
fn main() {
println!("=== 所有权的实战价值 ===");
// 示例1:自动内存管理
create_and_destroy();
println!("函数调用完成,内存自动清理");
// 示例2:防止悬空指针
// 取消注释下面的调用会看到编译错误
// let dangling_ref = dangerous_operation();
println!("Rust在编译期就阻止了我们创建悬空指针!");
// 对比其他语言可能发生的情况:
println!("在C++中,类似的代码可能导致:");
println!("1. 悬空指针");
println!("2. 内存泄漏");
println!("3. 段错误");
println!("但在Rust中,这些在编译期就被阻止了!");
}综合练习
fn first_word(s: &String) -> &str {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return &s[0..i];
}
}
&s[..]
}
fn main() {
println!("=== 所有权综合练习 ===");
// 场景1:所有权转移
let s1 = String::from("Rust");
let s2 = s1;
// s1 不能再使用
// 场景2:克隆
let s3 = String::from("所有权");
let s4 = s3.clone();
// s3 和 s4 都可以使用
// 场景3:引用
let s5 = String::from("hello world");
let word = first_word(&s5);
// s5 仍然可用
println!("s2 = {}", s2);
println!("s3 = {}, s4 = {}", s3, s4);
println!("s5 = '{}', 第一个单词是 '{}'", s5, word);
// 场景4:可变引用
let mut s6 = String::from("hello");
{
let r1 = &mut s6;
r1.push_str(" rust");
} // r1离开作用域,现在可以创建新的引用
let r2 = &s6;
println!("s6 = {}", r2);
println!("\n=== 所有权规则总结 ===");
println!("✓ 每个值都有唯一所有者");
println!("✓ 所有权可以转移(移动)");
println!("✓ 可以使用clone进行深度复制");
println!("✓ 引用允许借用而不取得所有权");
println!("✓ 编译期保证内存安全");
}在VSCode中体验编译器帮助
Rust编译器的错误信息非常友好!尝试以下操作:
- 故意制造错误:在代码中故意违反所有权规则
- 查看错误提示:rust-analyzer会实时显示错误
- 阅读错误信息:Rust的错误信息会详细解释问题,甚至建议修复方法
例如,尝试这个有问题的代码:
fn main() {
let s1 = String::from("hello");
let s2 = s1;
println!("{}", s1); // 错误!
}在VSCode中,你会看到红色波浪线,鼠标悬停会显示详细错误信息。
利用编译器学习:
- 阅读完整的错误信息,理解问题根源
- 按照编译器的建议修复代码
- 通过错误信息学习所有权规则
第二部分:没有抽象==没有中间商
想象一下这样的场景:你想从农场直接购买新鲜牛奶,但现实中却要经过层层中间商------收购商、批发商、零售商,每个环节都加价,最终你支付了高价,却得到了不新鲜的牛奶。这正是传统高级编程语言中抽象层带来的问题。
在编程世界中,抽象就像中间商,它们承诺让开发更简单,却暗中消耗着性能和资源。Java的JVM、Python的解释器、JavaScript的引擎------这些都是编程世界的"中间商",它们站在你的代码和硬件之间,收取着性能"佣金"。
而Rust选择了一条不同的道路:零成本抽象。就像直接从农场购买牛奶,没有中间商赚差价,新鲜直达,价格实惠。
情景一:内存管理的真相------GC vs 所有权系统
Java的垃圾回收:24小时营业的清洁公司
// Java中的内存管理
public class MemoryDemo {
public void processData() {
// 创建大量临时对象
for (int i = 0; i < 100000; i++) {
String temp = new String("Object " + i);
process(temp);
}
// 垃圾回收器在不确定的时间清理这些对象
}
private void process(String data) {
// 处理数据
}
}深入分析Java GC的工作机制:
在Java中,垃圾回收器就像一个24小时营业的清洁公司,它不知疲倦地在后台工作,但你永远不知道它什么时候会来打扫。这种不确定性带来了几个严重问题:
首先,GC的"全权代理"模式意味着你失去了对内存管理的直接控制。当GC决定进行垃圾回收时,它会暂停所有应用线程(Stop-The-World),这种暂停在实时系统中可能是致命的。
其次,GC的内存占用是巨大的隐性成本。为了高效运行,JVM需要预留大量的堆内存,通常远超过实际数据所需。
第三,GC的算法复杂度本身就会消耗大量CPU资源。标记-清除、复制、分代收集等算法都需要计算资源来跟踪对象引用关系。
最重要的是,GC破坏了程序的局部性原理。对象在堆中分散分配,访问模式难以预测,导致缓存命中率下降。
Rust的所有权系统:精准的即时清理工
// Rust中的内存管理
fn process_data() {
// 在栈上分配,极速创建和销毁
for i in 0..100000 {
let temp = format!("Object {}", i);
process(&temp);
// temp在这里立即被丢弃,无需等待GC
}
}
fn process(data: &str) {
// 处理数据
}
// 或者使用更高效的方式
fn efficient_process_data() {
let mut buffer = String::with_capacity(1024);
for i in 0..100000 {
buffer.clear();
write!(&mut buffer, "Object {}", i).unwrap();
process(&buffer);
}
}Rust所有权系统的深度优势:
Rust的所有权系统就像一个有洁癖的精准清理工,它不在后台运行,而是在编译时就已经规划好了每个对象的生命周期。
编译时的确定性是所有权系统最强大的特性。Rust编译器在编译阶段就分析出每个变量的作用域,精确知道何时该分配内存、何时该释放内存。
零运行时开销是所有权系统的另一个核心优势。由于所有内存管理决策都在编译时做出,运行时不需要额外的GC线程、引用计数更新或复杂的可达性分析。
内存安全无需运行时检查是Rust的革命性突破。传统系统编程语言如C++通过程序员 discipline 来保证内存安全,但人类总会犯错。托管语言如Java通过运行时检查来保证安全,但付出了性能代价。
缓存友好性是经常被忽视但极其重要的优势。Rust鼓励栈分配和连续内存布局,这显著提高了缓存局部性。
情景二:函数调用与内联优化
Java的虚方法表:绕远路的电话转接员
// Java中的多态调用
abstract class Animal {
abstract void makeSound();
}
class Dog extends Animal {
void makeSound() {
System.out.println("Woof");
}
}
class Cat extends Animal {
void makeSound() {
System.out.println("Meow");
}
}
public class PolymorphismDemo {
public void processAnimals(List<Animal> animals) {
for (Animal animal : animals) {
animal.makeSound(); // 虚方法调用 - 性能开销!
}
}
}Java虚方法调用的深度分析:
Java的虚方法调用就像一个大公司的电话总机,每次调用都要经过转接员(虚方法表)转发,而不是直接拨打到目标部门。
首先,虚方法表(vtable)查找是一个内存访问密集型操作。
其次,虚方法调用阻碍了内联优化。内联是编译器最重要的优化手段之一,但对于虚方法,编译器在编译时无法确定具体调用哪个实现,因此无法进行内联。
第三,虚方法调用破坏了CPU的指令缓存局部性。
Rust的trait与单态化:直达专线
// Rust中的零成本抽象
trait Animal {
fn make_sound(&self);
}
struct Dog;
impl Animal for Dog {
fn make_sound(&self) {
println!("Woof");
}
}
struct Cat;
impl Animal for Cat {
fn make_sound(&self) {
println!("Meow");
}
}
// 方式1:静态分发 - 编译时生成特化版本
fn process_animals_static<T: Animal>(animals: &[T]) {
for animal in animals {
animal.make_sound(); // 直接调用,可能被内联!
}
}
// 方式2:动态分发 - 显式选择运行时多态
fn process_animals_dynamic(animals: &[&dyn Animal]) {
for animal in animals {
animal.make_sound(); // 通过vtable调用,但显式标注
}
}Rust单态化技术的革命性优势:
Rust的单态化(monomorphization)就像为每个调用场景建立了直达专线,完全避免了转接开销。
编译时特化是单态化的核心机制。对于每个具体类型参数,Rust编译器都会生成一个特化版本的函数。
极致的内联优化可能性是单态化的直接结果。由于编译器知道具体的类型,它可以安全地将小函数内联到调用处。
无运行时开销的多态是Rust的独特优势。程序员可以享受泛型编程的表达力,同时获得与手写特化代码相同的性能。
显式的动态分发让性能特性透明化。当确实需要运行时多态时,Rust要求程序员显式使用dyn关键字。
情景三:集合与迭代器
Java的Stream API:豪华包装的代价
// Java Stream的隐藏开销
public class StreamDemo {
public void processData(List<String> data) {
List<String> result = data.stream()
.filter(s -> s.length() > 5) // 中间操作 - 创建新Stream
.map(s -> s.toUpperCase()) // 中间操作 - 再创建新Stream
.sorted() // 状态ful操作 - 可能分配数组
.collect(Collectors.toList()); // 终端操作 - 分配结果列表
// 看似一行代码,背后可能分配了多个临时对象
}
// 更糟糕的例子 - 装箱开销
public int sumLengths(List<String> data) {
return data.stream()
.map(String::length) // 产生Integer对象,不是int!
.reduce(0, Integer::sum); // 拆箱求和
}
}Java Stream API的隐性成本深度分析:
Java的Stream API就像把简单购物变成了豪华礼盒包装,每个环节都增加了不必要的包装和拆包装成本。
首先,Stream的惰性求值机制本身就有开销。
其次,自动装箱是性能的隐形杀手。当处理基本类型时,Stream API被迫使用包装类型(Integer、Long等),这导致了大量的对象分配。
第三,收集器的通用性代价高昂。
Rust的迭代器:零开销的数据流水线
// Rust迭代器的零成本抽象
fn process_data(data: &[String]) -> Vec<String> {
data.iter()
.filter(|s| s.len() > 5) // 无分配 - 只是迭代器适配器
.map(|s| s.to_uppercase()) // 可能分配新String,但明确可见
.collect() // 一次分配结果向量
}
// 基本类型无装箱开销
fn sum_lengths(data: &[String]) -> usize {
data.iter()
.map(|s| s.len()) // 直接返回usize,不是装箱类型
.sum() // 直接在栈上计算
}
// 更高效的原地处理
fn process_data_in_place(data: &mut [String]) {
for item in data.iter_mut() {
if item.len() > 5 {
*item = item.to_uppercase(); // 原地修改,避免额外分配
}
}
}Rust迭代器组合器的零成本特性:
Rust的迭代器就像精心设计的工业流水线,每个环节都直接衔接,没有多余的包装和转运。
编译时特化是迭代器性能的关键。Rust编译器为每个迭代器组合器链生成特化的代码,完全消除了虚方法调用和动态分发。
无装箱的基本类型处理让数值计算极其高效。Rust的泛型系统可以特化到具体类型,对于usize、i32等基本类型,迭代器直接在栈上操作。
内存预分配和容量提示优化了集合操作。collect()方法可以基于迭代器的size_hint预分配足够容量的集合。
内联和循环融合创造了极致的性能。Rust编译器能够将相邻的迭代器适配器融合成单个操作。
情景四:错误处理
Java的异常机制:昂贵的保险政策
// Java异常处理的隐藏成本
public class ExceptionDemo {
public void processFile(String filename) {
try {
BufferedReader reader = new BufferedReader(
new FileReader(filename));
String line;
while ((line = reader.readLine()) != null) {
processLine(line);
}
reader.close();
} catch (IOException e) {
// 异常处理 - 昂贵的栈遍历
System.err.println("Error processing file: " + e.getMessage());
e.printStackTrace(); // 更昂贵的栈跟踪生成
}
}
// 滥用异常的控制流
public int findIndex(List<String> list, String target) {
try {
for (int i = 0; i < list.size(); i++) {
if (list.get(i).equals(target)) {
throw new FoundException(i); // 极其低效!
}
}
return -1;
} catch (FoundException e) {
return e.getIndex();
}
}
private static class FoundException extends Exception {
private final int index;
public FoundException(int index) { this.index = index; }
public int getIndex() { return index; }
}
}Java异常机制的深度性能分析:
Java的异常处理就像购买全包保险,即使从不出险也要支付高昂保费,而出险时的理赔流程更是繁琐昂贵。
异常实例创建的固定成本是第一个开销来源。在Java中,每次抛出异常都需要创建新的异常对象。
栈展开的运行时开销是异常机制的另一个重负。当异常被抛出时,JVM需要逐帧展开栈,查找匹配的catch块。
异常对JIT编译的干扰经常被忽视。异常抛出路径是"冷"路径,很少被执行,因此JIT编译器可能不会优化这些代码。
滥用异常进行控制流是性能的灾难。
Rust的Result类型:编译时验证的轻量方案
use std::fs::File;
use std::io::{self, BufRead, BufReader};
// Rust的错误处理 - 零成本抽象
fn process_file(filename: &str) -> Result<(), io::Error> {
let file = File::open(filename)?; // ?运算符 - 编译时错误传播
let reader = BufReader::new(file);
for line in reader.lines() {
let line = line?; // 再次可能出错
process_line(&line);
}
Ok(()) // 明确返回成功
}
fn process_line(line: &str) {
println!("处理: {}", line);
}
// 高效的控制流,无异常开销
fn find_index(list: &[String], target: &str) -> Option<usize> {
for (i, item) in list.iter().enumerate() {
if item == target {
return Some(i); // 正常返回,无性能惩罚
}
}
None // 明确表示未找到
}
// 组合错误处理
fn complex_operation() -> Result<String, String> {
let config = "配置".to_string();
let data = process_data(&config).map_err(|_| "处理错误")?;
validate_data(&data).map_err(|_| "验证错误")?;
Ok(data)
}
fn process_data(config: &str) -> Result<String, ()> {
Ok(format!("处理后的: {}", config))
}
fn validate_data(data: &str) -> Result<(), ()> {
if data.len() > 0 { Ok(()) } else { Err(()) }
}Rust Result类型的零成本优势:
Rust的错误处理就像精心设计的交通信号系统,在编译时规划好所有可能路线,运行时只需按信号行驶,没有紧急刹车的成本。
基于返回值的错误处理完全消除了运行时开销。Rust的Result类型是一个简单的枚举(Ok(T)或Err(E)),在内存中通常优化为标签联合。
**问号运算符(?)**提供了语法糖而不损害性能。?运算符在编译时展开为match表达式,没有任何运行时开销。
显式的错误类型强制了错误处理的最佳实践。在Rust中,函数签名必须声明可能返回的错误类型,这强制调用者考虑错误情况。
错误转换的零成本组合让错误处理可组合。map_err等方法允许在错误类型之间转换,这些操作在编译时被优化掉。
情景五:并发编程
Java的并发抽象:重量级的同步机制
// Java并发编程的典型开销
public class ConcurrentDemo {
private final Map<String, Integer> cache = new HashMap<>();
private final ReentrantLock lock = new ReentrantLock();
// 方式1: synchronized方法 - 简单但粗粒度
public synchronized void updateCache(String key, Integer value) {
cache.put(key, value);
}
// 方式2: 显式锁 - 更灵活但仍重
public void updateCacheWithLock(String key, Integer value) {
lock.lock();
try {
cache.put(key, value);
} finally {
lock.unlock();
}
}
// 方式3: ConcurrentHashMap - 更好的选择但仍非零成本
private final ConcurrentMap<String, Integer> concurrentCache =
new ConcurrentHashMap<>();
public void updateConcurrentCache(String key, Integer value) {
concurrentCache.put(key, value); // 仍有内部锁开销
}
// 原子变量的使用
private final AtomicInteger counter = new AtomicInteger(0);
public int increment() {
return counter.incrementAndGet(); // 较高效,但仍有内存屏障
}
}Java并发原语的深度开销分析:
Java的并发机制就像在繁忙路口设置交通警察,确实能防止事故,但每个车辆都要停下来接受指挥,通行效率大打折扣。
内置锁(synchronized)的monitor机制是重量级的。每个Java对象都有一个关联的monitor,用于实现内置锁。
内存屏障和缓存一致性协议带来隐性开销。Java的volatile变量和原子操作类使用内存屏障来保证可见性和有序性。
线程管理的开销不容忽视。创建和销毁线程是昂贵的操作,需要内核参与。
虚假共享是经常被忽视的性能杀手。当多个线程修改同一缓存行中的不同变量时,会引发缓存行在不同CPU核心间频繁传输。
Rust的并发哲学:编译时防止数据竞争
use std::sync::{Arc, Mutex};
use std::collections::HashMap;
use std::thread;
// 方式1: 基于所有权的线程创建
fn spawn_threads() {
let data = vec![1, 2, 3, 4];
// 移动语义确保数据安全转移到线程
let handle = thread::spawn(move || {
println!("在新线程中处理数据: {:?}", data);
// data在这里被独占访问,无数据竞争
});
handle.join().unwrap();
}
// 方式2: 智能指针共享
fn shared_state_concurrency() {
let counter = Arc::new(Mutex::new(0));
let mut handles = vec![];
for _ in 0..10 {
let counter = Arc::clone(&counter);
let handle = thread::spawn(move || {
let mut num = counter.lock().unwrap();
*num += 1;
});
handles.push(handle);
}
for handle in handles {
handle.join().unwrap();
}
println!("最终计数: {}", *counter.lock().unwrap());
}
// 方式3: 无锁编程 - 基于所有权的通道
use std::sync::mpsc;
fn channel_based_concurrency() {
let (tx, rx) = mpsc::channel();
thread::spawn(move || {
let val = String::from("hello");
tx.send(val).unwrap();
// 发送后失去所有权,防止后续使用
});
let received = rx.recv().unwrap();
println!("收到: {}", received);
}
// 方式4: 基于作用域的线程 - 避免Arc开销
fn scoped_threads() {
let mut data = vec![1, 2, 3, 4];
// 跨线程借用,但编译器验证安全性
thread::scope(|s| {
for i in 0..data.len() {
s.spawn(|| {
data[i] += 1; // 编译器确保安全并发访问
});
}
});
println!("处理后的数据: {:?}", data);
}Rust并发模型的革命性优势:
Rust的并发模型就像精心设计的单向交通系统,在建设时(编译时)就消除了撞车的可能性,而不是依赖运行时交通警察。
所有权系统在编译时防止数据竞争是Rust最独特的优势。Rust的借用检查器强制要求:要么多个不可变引用共存,要么单个可变引用独占。
Send和Sync trait提供了灵活的类型级并发安全。这些标记trait(零运行时开销)指示类型是否可以安全地跨线程传递或共享。
**轻量级线程(async/await)**重新定义了并发编程。Rust的异步编程模型基于生成器状态机,在编译时生成高效的状态转换代码。
无锁数据结构的编译时验证让高性能并发更安全。Rust的类型系统可以表达复杂的不变式,让无锁算法的实现既高效又安全。
情景六:泛型与类型擦除
Java的类型擦除:运行时失明的代价
// Java泛型的类型擦除问题
import java.util.ArrayList;
import java.util.List;
public class GenericsDemo {
// 编译后都变成List<Object> - 类型信息丢失
public void processStrings(List<String> strings) {
// 运行时不知道这是List<String>
for (String s : strings) {
System.out.println(s.length());
}
}
public void processIntegers(List<Integer> integers) {
// 运行时不知道这是List<Integer>
for (Integer i : integers) {
System.out.println(i.intValue()); // 装箱开销!
}
}
// 类型擦除导致的问题
public void typeErasureIssues() {
List<String> strings = new ArrayList<>();
List<Integer> integers = new ArrayList<>();
// 编译时检查通过,但运行时类型相同
System.out.println(strings.getClass() == integers.getClass()); // true!
// 无法创建泛型数组
// List<String>[] array = new List<String>[10]; // 编译错误
// instanceof检查受限
if (strings instanceof List) { // 警告,只能检查到List
// 无法检查List<String>
}
}
// 反射绕开类型安全 - 危险但有时必要
@SuppressWarnings("unchecked")
public void unsafeOperation(List<String> strings) {
// 绕过编译时检查
List rawList = strings;
rawList.add(42); // 运行时才抛出ClassCastException!
}
}Java类型擦除的深度成本分析:
Java的类型擦除就像给所有货物使用相同的通用包装箱,虽然简化了物流,但失去了对具体内容的直接了解,需要额外开箱检查。
运行时类型信息丢失导致强制类型转换开销。由于泛型信息在运行时不可用,Java编译器在字节码中插入检查指令(checkcast)。
装箱操作对基本类型造成性能惩罚。Java泛型不支持基本类型,必须使用包装类。
反射和动态代理的运行时成本高昂。当需要运行时类型信息时(如序列化、依赖注入),Java必须依赖反射API。
无法特化导致内存布局低效。由于类型擦除,List和List在内存中使用相同的布局。
Rust的单态化:编译时特化的极致性能
// Rust泛型的单态化 - 零成本抽象
fn process_strings(strings: &[String]) {
// 编译器为每个具体类型生成特化代码
for s in strings {
println!("长度: {}", s.len()); // 直接方法调用,可能内联
}
}
fn process_integers(integers: &[i32]) {
// 基本类型特化 - 无装箱开销
for i in integers {
println!("值: {}", i); // 直接栈操作
}
}
// 泛型函数 - 编译时为每个调用类型生成特化版本
fn process<T: std::fmt::Display>(items: &[T]) {
for item in items {
println!("{}", item); // 静态分发调用
}
}
// 特化集合类型
fn specialized_collections() {
// Vec<i32> - 连续内存布局,无装箱
let numbers: Vec<i32> = vec![1, 2, 3, 4];
// HashMap<String, i32> - 键值对特化布局
let mut map: std::collections::HashMap<String, i32> =
std::collections::HashMap::new();
map.insert("key".to_string(), 42);
// 数组 - 栈分配,极致性能
let array: [f64; 4] = [1.0, 2.0, 3.0, 4.0];
}
// 编译时特化的威力
fn generic_algorithm<T: Copy + std::ops::Add<Output = T>>(a: T, b: T) -> T {
a + b // 为每个T生成特化代码
}
// 使用示例
fn demonstrate_monomorphization() {
// 为i32生成特化版本
let int_result = generic_algorithm(1, 2);
println!("整数结果: {}", int_result);
// 为f64生成另一个特化版本
let float_result = generic_algorithm(1.0, 2.0);
println!("浮点数结果: {}", float_result);
// 每个调用都是直接机器码,无运行时类型检查
}
fn main() {
demonstrate_monomorphization();
}Rust单态化技术的全面优势:
Rust的单态化就像为每种货物定制专用包装箱和搬运设备,虽然增加了前期准备(编译时间),但运行时效率达到极致。
编译时为每个具体类型生成特化代码消除了所有运行时开销。当调用泛型函数时,Rust编译器会为每个实际使用的类型参数生成专门的函数版本。
基本类型的直接支持让数值计算达到C级别的性能。Rust的泛型系统完全支持基本类型,Vec在内存中是连续的整数数组,没有任何装箱开销。
内存布局优化提升了缓存效率。由于编译器知道具体类型,它可以优化结构体字段排列、选择最佳的对齐方式、消除填充字节。
特化实现的灵活性支持性能优化。Rust允许为特定类型提供特化实现,这让库作者可以为常见类型提供高度优化的版本。
零成本的trait对象提供了运行时多态的选择。当确实需要运行时多态时,Rust提供trait对象机制,但要求显式使用dyn关键字。
第三部分:为什么选择Rust?全面优势总结
性能优势的累积效应
单个抽象层的开销可能看起来不大,但在现代软件系统中,这些开销会层层累积。一个典型的Web应用可能同时涉及:
- 数据序列化(类型处理)
- 业务逻辑(方法调用)
- 数据库访问(资源管理)
- 并发处理(同步机制)
每个环节的微小开销累积起来,可能造成数倍的性能差异。Rust的零成本抽象确保每个环节都达到最优性能。
资源效率的系统级影响
在云原生和边缘计算时代,资源效率直接影响成本和用户体验:
|------|---------------|---------------|
| 指标 | Java应用 | Rust应用 |
| 内存占用 | 需要大堆内存和复杂GC参数 | 精确控制内存使用 |
| 启动时间 | 较慢,需要JVM预热 | 快速启动,无需运行时初始化 |
| 部署密度 | 较低,资源占用大 | 较高,轻量级部署 |
开发效率的长期收益
虽然Rust的学习曲线较陡,但一旦掌握,其编译时保证实际上提高了长期开发效率:
编译时保证带来的好处:
- 大胆重构,编译器会捕获并发问题和内存错误
- 减少生产环境的运行时错误
- 更少的调试和维护成本
- 持续优化性能而不会引入回归
适合现代硬件架构
现代CPU的性能越来越依赖于:
- 缓存局部性:Rust的栈分配和连续内存布局提高缓存命中率
- 分支预测:静态分发优化分支预测
- 指令级并行:内联创造指令级并行机会
- 响应时间一致性:无GC暂停保证响应时间一致性
实践建议:何时选择Rust
基于以上分析,以下场景特别适合选择Rust:
- 基础设施软件:操作系统、数据库、网络栈等需要极致性能和可靠性的场景
- WebAssembly:需要小型、快速加载的客户端代码
- 游戏开发:需要直接控制硬件资源和保证帧率稳定性
- 嵌入式系统:资源受限环境,需要确定性内存管理
- 高性能Web服务:需要低延迟和高吞吐量的后端服务
- 命令行工具:需要快速启动和高效资源使用
- 加密和安全软件:需要避免时序攻击和内存安全漏洞
而对于快速原型开发、已有Java/.NET生态深度集成的企业应用、机器学习框架等场景,传统托管语言可能仍是更合适的选择。
结论:从内存管理到零成本抽象的完整旅程
Rust的所有权系统不仅仅是一个内存管理工具,它是实现零成本抽象的基石。通过编译时的严格检查,Rust实现了:
内存安全的革命:
- 编译期防止悬空指针、内存泄漏和数据竞争
- 无需垃圾回收的自动内存管理
- 确定性的资源生命周期
性能的极致追求:
- 零运行时开销的抽象
- 编译时特化生成的极致优化代码
- 对现代硬件架构的深度优化
开发体验的重新定义:
- 编译时错误检测而非运行时崩溃
- fearless并发编程
- 长期可维护性和性能稳定性
Rust的"没有抽象==没有中间商"哲学不是要取代所有语言,而是为性能敏感和可靠性关键的场景提供了更好的选择。正如现代物流中既需要高效的直达快递,也需要灵活的转运中心,编程语言生态也需要多样化的解决方案来满足不同需求。
掌握Rust意味着在工具链中增加了一个强大的性能利器,能够在需要时打破抽象层的限制,直接释放硬件的全部潜力。从内存管理的基础到零成本抽象的高级特性,Rust为我们展示了一条通向更安全、更高效编程的未来之路。
Rust说:请给我足够的Trust,我会让你的辉煌梦想变成Must!