家人们!十一假期第1天, OpenAI一年一度的开发者大会又来了惹!今年的开发者大会分成三部分分别在美国、英国、新加坡三个地点举办,刚刚结束的是第一场。
去年的OpenAI开发者大会公布了GPT-4 Turbo和GPTs,今年没有大更新,但主打实用。
发布了给开发者的一些福利,包括API的功能更新以及降价。下面一起盘一下吧!
视觉微调(Vision Fine-Tuning)
OpenAI今年在GPT-4o上引入了微调的功能,开发者们已经开始利用文本对模型进行微调以适应下游任务。
而此次开发者大会之际,OpenAI宣布将引入GPT-4o的视觉微调功能,允许开发者结合图像和文本来定制模型的视觉理解能力。
视觉微调的过程与文本微调相似,开发者需要按照指定的格式准备数据集并上传。开放视觉微调功能使得开发者能够增强模型在视觉搜索、生成和检测等核心能力方面的功能。

例如,东南亚的运输公司Grab通过仅使用100个样本对GPT-4o进行视觉微调,显著提高了其特定任务的图像理解能力。在车道计数的准确性上Grab实现了20%的提升,在限速标志的定位上提高了13%,这些成绩均超过了原始的GPT-4o模型。

所有付费用户均可使用视觉微调功能,而且从今天至本月31日,OpenAI将为每位开发者每天提供100万个免费训练token,用于对GPT-4o模型进行视觉微调。

真大方啊!OpenAI!
等到本月31号之后,视觉微调GPT-4o不再Free,定价是每 100 万个 token 25 美元,推理的费用是每100万个token 3.75 美元,每 100 万个输出 token 15 美元。
Sam Altman 也在X上发推文和大家得瑟他们把成本降低了:

实时 API(Realtime API)
在开发者大会上,OpenAI还宣布了要开放实时API的公测版,允许所有开发者在自己的应用程序中实现使用GPT的实时、低延时、多模态的功能。
实时API的公测版本支持开发者使用API目前支持的6种预设进行语音交互。

价格也挺美丽的,每分钟的音频输入每 100 万个 5 美元,每分钟音频输出 token 每 100 万个 20 美元。
而且,OpenAI还推出了聊天完成 API(Chat Completions API)功能,用于支持开发者不需要实时API的场景需求。
模型蒸馏(Model Distillation)
OpenAI还提出了一种用前沿、高级的模型的输出微调GPT-4o mini的模式,例如用o1-preview 和 GPT-4o 等高级模型的输出,微调GPT-4o mini这类的小模型,从而实现更高效模型的性能。

OpenAI提出的蒸馏套件包括三个部分:
存储完成
开发者可以通过自动捕获、存储API生成的输入、输出对,为蒸馏生成数据集。
自定义评估(beta)
开发者可以创建和运行自定义评估,使用存储完成的数据或上传现有数据集评测模型的表现。
完成后微调
存储完成、自定义评估结合在微调的服务中,开发者可以在微调中使用存储完成创建的数据集,并使用评估在微调模型上运行评测。
提示缓存(Prompt Caching)
OpenAI注意到许多开发者在构建AI应用程序时,常常会在多个API调用中重复使用相同的上下文,例如在编辑代码库或与聊天机器人进行长时间、多轮次的对话。
为了降低开发者的成本并减少在一些重复任务上的时间延迟,OpenAI推出了"提示缓存"(Prompt Caching)功能。该功能能够自动识别并缓存模型最近处理过的输入tokens,从而提高效率并减少不必要的重复处理,有效地为开发者节省时间和资源。
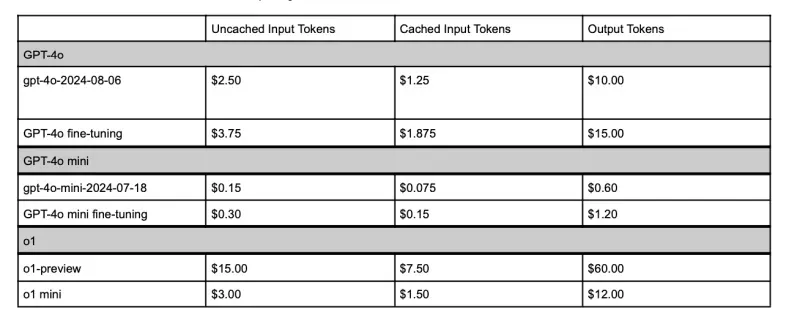
简单直接地说就是,系统会自动对模型最近见过的输入tokens统统打5折!

但是实际上!
类似的功能已经在Gemini、Claude以及Kimi等平台上线了~而OpenAI的区别在于它将这一过程自动化。
这意味着开发者无需手动配置或管理缓存,OpenAI的系统会智能地处理输入tokens的缓存和重用,从而提供更为便捷和高效的体验。

小结
奶茶看了开发者大会公布的更新内容,虽然没有像去年那样推出新产品,但更新内容也还算是令人眼前一亮,颇具实用性!
氮素!Sam Altman竟然宣称这次开发者大会使得通向AGI(通用人工智能)的道路前所未有的清晰:

嘿,咋回事,怎么又提到AGI了?这怎么就AGI了?

奶茶并没有感受到这一点,不知道大家怎么看呢?
后面还有两场开发者大会,大家如果感兴趣的话,可以在评论区告诉我们,奶茶可以蹲守第一时间给大家汇报~

