文章目录
- 前言
- [7 分区和副本机制](#7 分区和副本机制)
-
- [7.1 生产者分区写入策略](#7.1 生产者分区写入策略)
-
- [7.1.1 轮询分区策略](#7.1.1 轮询分区策略)
- [7.1.2 随机分区策略](#7.1.2 随机分区策略)
- [7.1.3 按key分区分配策略](#7.1.3 按key分区分配策略)
- [7.1.4 自定义分区策略](#7.1.4 自定义分区策略)
-
- [7.1.4.1 实现`Partitioner`接口](#7.1.4.1 实现
Partitioner接口) - [7.1.4.2 实现分区逻辑](#7.1.4.2 实现分区逻辑)
- [7.1.4.3 配置使用自定义分区器](#7.1.4.3 配置使用自定义分区器)
- [7.1.4.4 分区测试](#7.1.4.4 分区测试)
- [7.1.4.1 实现`Partitioner`接口](#7.1.4.1 实现
- [7.2 消费者分区分配策略](#7.2 消费者分区分配策略)
-
- [7.2.1 RangeAssignor(范围分配策略)](#7.2.1 RangeAssignor(范围分配策略))
- [7.2.2 RoundRobinAssignor(轮询分配策略)](#7.2.2 RoundRobinAssignor(轮询分配策略))
- [7.2.3 StickyAssignor(粘性分配策略)](#7.2.3 StickyAssignor(粘性分配策略))
- [7.2.4 消费者组的Reblance机制](#7.2.4 消费者组的Reblance机制)
- [7.3 副本机制](#7.3 副本机制)
-
- [7.3.1 生产者的`acks`参数](#7.3.1 生产者的
acks参数) - [7.3.2 `acks`参数配置为0](#7.3.2
acks参数配置为0) - [7.3.2 `acks`参数配置为1](#7.3.2
acks参数配置为1) - [7.3.3 `acks`参数配置为-1或all](#7.3.3
acks参数配置为-1或all) - [7.3.4 基准测试](#7.3.4 基准测试)
- [7.3.1 生产者的`acks`参数](#7.3.1 生产者的
- [7.4 消费指定分区数据](#7.4 消费指定分区数据)
前言
Kafka学习笔记(一)Linux环境基于Zookeeper搭建Kafka集群、Kafka的架构
Kafka学习笔记(二)Kafka基准测试、幂等性和事务、Java编程操作Kafka
7 分区和副本机制
7.1 生产者分区写入策略
生产者写入消息到Topic,Kafka将依据不同的策略将数据分配到不同的分区中,主要有以下策略:
7.1.1 轮询分区策略
默认 的策略,也是使用最多的策略,可以最大限度保证所有消息平均分配到一个分区。
7.1.2 随机分区策略
每次都随机地将消息分配到每个分区。在较早的版本,默认的分区策略就是随机策略,也是为了将消息均衡地写入到每个分区,但后续轮询策略表现更佳,所以基本上很少会使用随机策略。
7.1.3 按key分区分配策略
根据key值,通过一定的算法将消费分配到不同分区。按key分配策略,有可能会出现「数据倾斜」,例如某个key包含了大量的数据,因为key值一样,所有所有的数据将都分配到这个分区中,造成该分区的消息数量远大于其他的分区。
7.1.4 自定义分区策略
轮询策略、随机策略都会导致一个问题,生产到Kafka中的数据是乱序存储的。而按key分区可以一定程度上实现数据有序存储(分区内局部有序),但这又可能会导致数据倾斜,所以在实际生产环境中要结合实际情况来做取舍。
7.1.4.1 实现Partitioner接口
在Java中,自定义分区需要实现org.apache.kafka.clients.producer.Partitioner接口,该接口定义了如下方法:

topic:针对特定Topic使用不同的分区规则。key、keyBytes:针对特定key值使用不同的分区规则。value、valueBytes:针对特定的消息内容使用不同的分区规则。cluster:Cluster对象提供了Topic的分区信息,可以据此动态调整分区策略。
7.1.4.2 实现分区逻辑
重写partition()方法,实现分区逻辑。例如:
java
/**
* 自定义分区器
*/
public class MyKafkaPartitioner implements Partitioner {
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
if(key != null) {
String keyString = (String) key;
// key 以 animal 开头时分配到分区 0
if(keyString.startsWith("animal")) {
return 0;
}
// key 以 food 开头时分配到分区 1
if(keyString.startsWith("food")) {
return 1;
}
}
// 默认分配到分区 0
return 0;
}
@Override
public void configure(Map<String, ?> configs) {
}
@Override
public void close() {
}
}7.1.4.3 配置使用自定义分区器
在Kafka生产者配置中,使用自定义分区器的类名:
java
props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, MyKafkaPartitioner.class.getName());7.1.4.4 分区测试
向3分区1副本的Topic`topic_3_1`发送key值为animal_rabbit的消息:

执行结果如下:

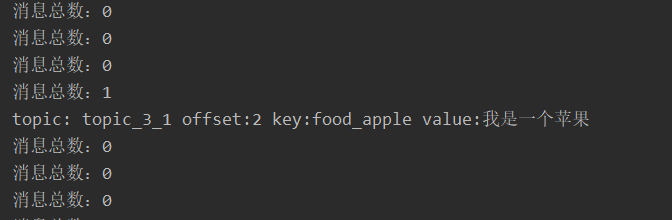
将key值修改为food_apple,则分配的分区是1:

7.2 消费者分区分配策略
通过消费者组(Consumer Group),Kafka允许多个消费者共同处理某个Topic的消息,但生产者已经将消息写入了Topic的不同分区,因此首先要解决哪个消费者消费哪个分区的数据的问题,即消费者分区分配策略问题。
在Java中,ConsumerPartitionAssignor接口用来定制消费者的分区分配策略,该接口的3个子类实现分别对应3种消费者分区分配策略。

7.2.1 RangeAssignor(范围分配策略)
范围分配策略是Kafka默认的分配策略 ,它可以确保每个消费者消费的分区数量是均衡的。
注意:范围分配策略是针对每个Topic的。
范围分配策略有两个算法公式:
- n = 分区数量 / 消费者数量
- m = 分区数量 % 消费者数量
策略结果是:前m个消费者消费n+1个分区,剩余消费者消费n个分区。如图:


7.2.2 RoundRobinAssignor(轮询分配策略)
轮询分配策略是将消费者组内所有消费者 以及消费者所订阅的所有Topic的分区按照字典序排序(Topic和分区的hashcode进行排序),然后通过轮询方式逐个将分区分配给每个消费者。
注意:轮询分配策略不局限于单个Topic。

如上图所示,3个消费者共订阅了2个Topic,共8个分区,将8个分区按照字典序排序后,开始轮询:
- TopicA p0 → consumer0
- TopicA p1 → consumer1
- TopicA p2 → consumer2
- TopicA p3 → consumer0
- TopicB p0 → consumer1
- TopicB p1 → consumer2
- TopicB p2 → consumer0
- TopicB p3 → consumer1
- Topica p0 → consumer2
- ...
7.2.3 StickyAssignor(粘性分配策略)
从Kafka 0.11.x版本开始,引入此类分配策略。其主要目的在于使分区分配尽可能均匀,同时在Topic或消费者发送变动需要重新分配时,分区的分配尽可能与上一次分配保持相同。
粘性分配策略主要作用在需要重新分配的情况,而不需要重新分配时和轮询分配策略类似。如图:

如果consumer2崩溃了,此时需要进行重新分配。而粘性分配策略会保留重新分配之前的分配结果,只是将原先consumer2负责的两个分区再均匀分配给consumer0、consumer1。

例如:之前consumer0、consumer1正在消费某几个分区,但由于需要重新分配,导致consumer0、consumer1需要取消处理,之后重新消费之前正在处理的分区,导致不必要的系统开销。而粘性分配策略可以明显减少这样的系统资源浪费。
7.2.4 消费者组的Reblance机制
上面提到了消费者的分区重新分配,其实就是Kafka中的Rebalance机制,称之为再均衡。
Reblance机制是Kafka中确保消费者组下所有的consumer如何达成一致,分配订阅的Topic的每个分区的机制。
Rebalance触发的时机有:
-
1)消费者组中consumer的个数发生变化。例如:有新的consumer加入到消费者组,或者是某个consumer停止了。
-
2)订阅的Topic个数发生变化。消费者可以订阅多个主题,假设当前消费者组订阅了三个主题,但有一个主题突然被删除了,此时也需要发生再均衡。
-
3)订阅的Topic分区数发生变化。
当然,Reblance机制的不良影响也挺大的。发生Rebalance时,消费者组下的所有consumer都将停止工作,直到Rebalance完成。
7.3 副本机制
副本的目的就是冗余备份,当某个Broker上的分区数据丢失时,依然可以从其他备份上读取,保障数据可用。
7.3.1 生产者的acks参数
生产者配置的acks参数,表示当生产者生产消息时,写入到副本的要求严格程度。它决定了生产者如何在性能和可靠性之间做取舍。
例如,在之前的测试代码中有如下配置:
java
props.put("acks", "all");7.3.2 acks参数配置为0

acks参数配置为0,生产者不会等到Broker确认,而直接发送下一条数据。因此它的性能最高,但有可能会丢失数据。
7.3.2 acks参数配置为1

acks参数配置为1,生产者会等待leader副本确认接收后,才会发送下一条数据,性能中等。
7.3.3 acks参数配置为-1或all

acks参数配置为1,生产者会等待所有副本同步完成并确认接收后,才会发送下一条数据,性能最低。
7.3.4 基准测试
分别对不同的acks参数进行基准测试,acks参数为0时的命令如下,其余类推:
sh
bin/kafka-producer-perf-test.sh --topic topic_1_1 --num-records 5000000 --throughput -1 --record-size 1000 --producer-props bootstrap.servers=192.168.245.130:9092,192.168.245.131:9092,192.168.245.132:9092 acks=0基准测试结果如下:
| 指标(1分区1副本) | ack=0 | ack=1 | ack=-1/all |
|---|---|---|---|
| 吞吐量 | 18299.132255 records/sec | 19160.979049 records/sec | 13137.876761 records/sec |
| 吞吐速率 | 17.45 MB/sec | 18.27 MB/sec | 12.53 MB/sec |
| 平均延迟时间 | 1769.71 ms | 1692.25 ms | 2473.96 ms |
| 最大延迟时间 | 5490.00 ms | 4455.00 ms | 10434.00 ms |
由此可见,acks参数为0和1时性能相当,为-1/all时性能大幅下降。
7.4 消费指定分区数据

如上图所示的Kafka消费者代码,只需要指定Topic,就可以直接读取消息,而不需要管理分区、副本、offset等元数据,实现方便。
这是因为,Kafka的偏移量offset是由Zookeeper管理的,消费者会自动根据上一次在Zookeeper中保存的offset去接着获取数据。不同的消费者组,在Zookeeper中保存了不同的offset,这样不同消费者组读取同一个Topic就不会有任何影响。
但以上代码也有缺点,就是不能细化控制分区、副本、offset等,从而无法从指定位置读取数据。
如果想要手动指定消费分区,则不能再使用之前的subscribe()方法订阅主题,而是要用assign()方法:
java
// 3. 订阅要消费的主题
// 指定消费者从哪个topic中拉取数据
// kafkaConsumer.subscribe(Arrays.asList("my_topic"));
String topic = "topic_3_1";
TopicPartition partition0 = new TopicPartition(topic, 0);
TopicPartition partition1 = new TopicPartition(topic, 1);
TopicPartition partition2 = new TopicPartition(topic, 2);
// 手动指定只消费分区1的数据
kafkaConsumer.assign(Arrays.asList(partition1));利用自定义分区策略(详见7.1.4节),向Topictopic_3_1的分区0、分区1分别写入数据:

但消费者只消费了分区1的数据:
...
本节完,更多内容请查阅分类专栏:微服务学习笔记
感兴趣的读者还可以查阅我的另外几个专栏: