点一下关注吧!!!非常感谢!!持续更新!!!
🚀 AI篇持续更新中!(长期更新)
AI炼丹日志-31- 千呼万唤始出来 GPT-5 发布!"快的模型 + 深度思考模型 + 实时路由",持续打造实用AI工具指南!📐🤖
💻 Java篇正式开启!(300篇)
目前2025年08月11日更新到: Java-94 深入浅出 MySQL EXPLAIN详解:索引分析与查询优化详解 MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解

章节内容
上节我们完成了如下内容:
- 物理存储 日志存储概述
- LogSegment
- 日志切分文件
- 索引切分过程
- 索引文件等等

索引文件
Kafka的消息存储采用分段存储机制,每个分区由多个Segment文件组成,主要包括以下三类文件:
-
日志文件(.log):
- 存储实际的消息内容,采用顺序追加写入方式
- 文件名基于文件中第一条消息的偏移量命名,如"00000000000000000000.log"
- 虽然Kafka理论上支持64位偏移量,但实践中采用20位数字(可表示约1百万TB数据)已足够
- 默认每个Segment文件大小上限为1GB(通过log.segment.bytes参数配置)
-
偏移量索引文件(.index):
- 采用稀疏索引结构,记录消息偏移量到物理位置的映射
- 索引条目包含两个字段:相对偏移量(4字节)和物理位置(4字节)
- 初始分配10MB空间,随着Segment滚动会修剪为实际使用大小
- 例如:偏移量索引可能记录"offset:500 → position:1024"这样的映射关系
-
时间戳索引文件(.timeindex):
- 记录时间戳与偏移量的对应关系
- 主要用于支持按时间戳查询消息的功能
- 同样初始分配10MB空间,后续会动态调整
- 索引格式为:时间戳(8字节)+ 相对偏移量(4字节)
文件管理机制:
- 新Segment创建时会同时生成.log、.index、.timeindex三个文件
- 文件命名保持一致性,如"00000000000000000000.log"、"00000000000000000000.index"、"00000000000000000000.timeindex"
- 当.log文件达到大小阈值时触发Segment滚动:
- 关闭当前文件组
- 创建新的文件组(基于新的起始偏移量命名)
- 对索引文件进行空间整理
应用场景示例:
- 消费者请求offset=500的消息时:
- 先查询.index文件找到最接近的索引点(如offset:400 → position:800)
- 从.log文件的800位置开始顺序扫描,直到找到offset=500的消息
- 管理员需要查询某时间点(如2023-01-01 00:00:00)之后的消息时:
- 查询.timeindex文件找到对应时间戳的偏移量
- 再通过.index文件定位物理位置
- 最后从.log文件读取实际消息内容
这种设计通过空间换时间的方式,在保证写入性能的同时,提供了高效的消息检索能力。
index 和 timeindex 内容如下: 
创建主题
shell
kafka-topics.sh --zookeeper h121.wzk.icu:2181 --create --topic wzk_test_demo_05 --partitions 1 --replication-factor 1 --config segment.bytes=104857600执行结果如下图: 
创建消息
shell
for i in `seq 10000000`; do echo "hello kangkang $i" >> test_data.txt; done生产消息
shell
kafka-console-producer.sh --broker-list h121.wzk.icu:9092 --topic wzk_test_demo_05 < test_data.txt运行结果如下图: 
查看存储
shell
cd /opt/kafka-logs
cd wzk_test_demo_05-0
ll运行结果如下图: 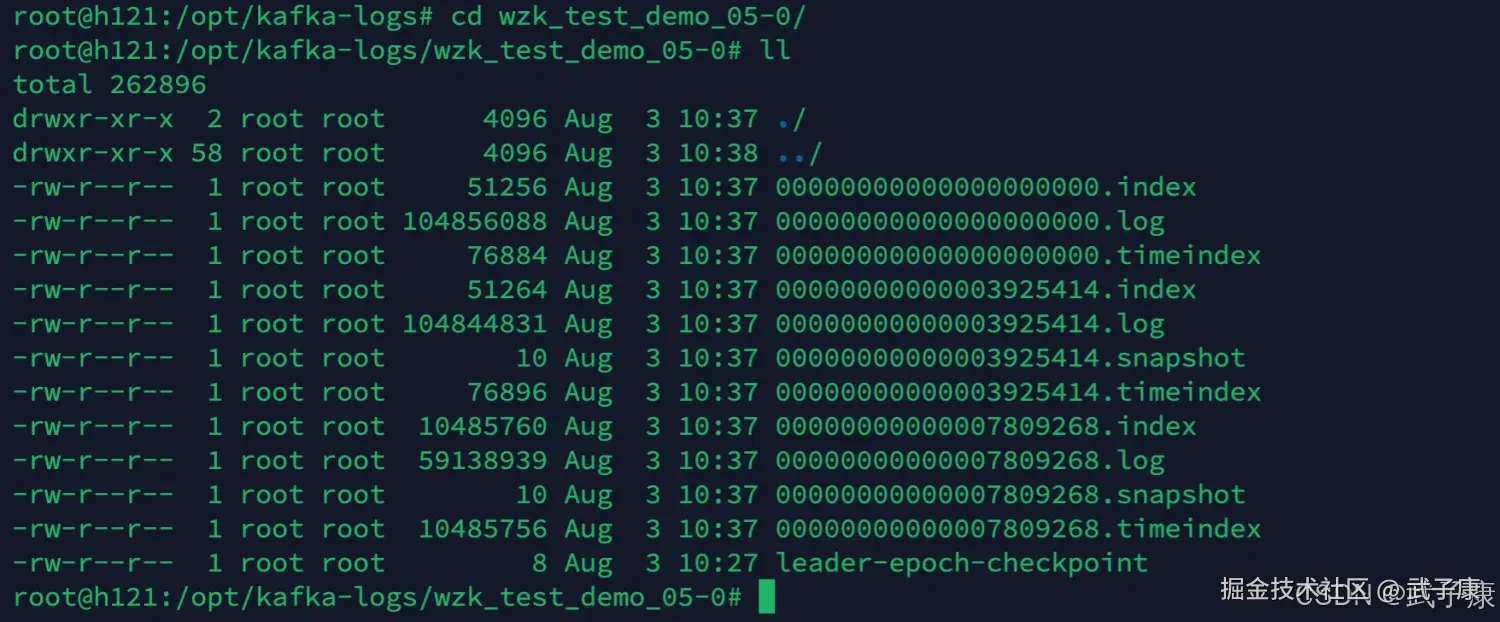
查看详细
如果想查看这些文件,可以使用Kafka提供的Shell工具来完成查看和操作。Kafka提供了多个Shell脚本,包括kafka-console-consumer.sh、kafka-run-class.sh等,可以用来查看和解析消息文件。以下是几个关键信息的详细说明:
-
Offset(偏移量):
- 是一个单调递增的整数,表示消息在分区中的唯一标识。
- 每个offset对应一条消息的位置,消费者通过跟踪offset来维护消费进度。
- 例如:offset=100表示这是该分区中的第100条消息。
-
Position(位置):
- 表示消息批(message batch)的字节数,用于计算消息在磁盘上的物理存储地址。
- 帮助Kafka快速定位消息在日志文件中的具体位置。
-
CreateTime(创建时间):
- 消息被生产者发送到Kafka的时间戳,格式为Unix时间戳(毫秒级)。
- 例如:CreateTime=1651234567890表示消息创建时间为2022年4月29日。
-
Magic(消息格式版本):
- 标识消息的格式版本:
- 0:代表V0版本(Kafka 0.10.0之前)
- 1:代表V1版本(Kafka 0.10.0-0.11.0)
- 2:代表V2版本(Kafka 0.11.0及之后)
- V2版本支持更高效的批量消息存储和压缩。
- 标识消息的格式版本:
-
Compresscodec(压缩编解码器):
- 表示消息采用的压缩算法:
- None(未压缩)
- 0:GZIP(高压缩比,但CPU消耗较大)
- 1:Snappy(快速压缩,适合低延迟场景)
- 2:LZ4(平衡压缩比和速度)
- 3:Zstandard(Kafka 2.1.0引入的高效压缩)
- 例如:Compresscodec=2表示使用Snappy压缩算法。
- 表示消息采用的压缩算法:
-
CRC(循环冗余校验):
- 对消息所有字段计算得到的32位校验值,用于检测消息在传输或存储过程中是否损坏。
- 如果CRC校验失败,Kafka会丢弃该消息。
使用示例:
bash
# 查看某个topic的消息内容及其元数据
bin/kafka-run-class.sh kafka.tools.DumpLogSegments --files 00000000000000000000.log --print-data-log输出示例会显示每条消息的offset、position、CreateTime等元数据信息,帮助开发者调试和分析消息内容。
shell
kafka-run-class.sh kafka.tools.DumpLogSegments --files 00000000000000000000.log --print-data-log | head执行结果如下图: 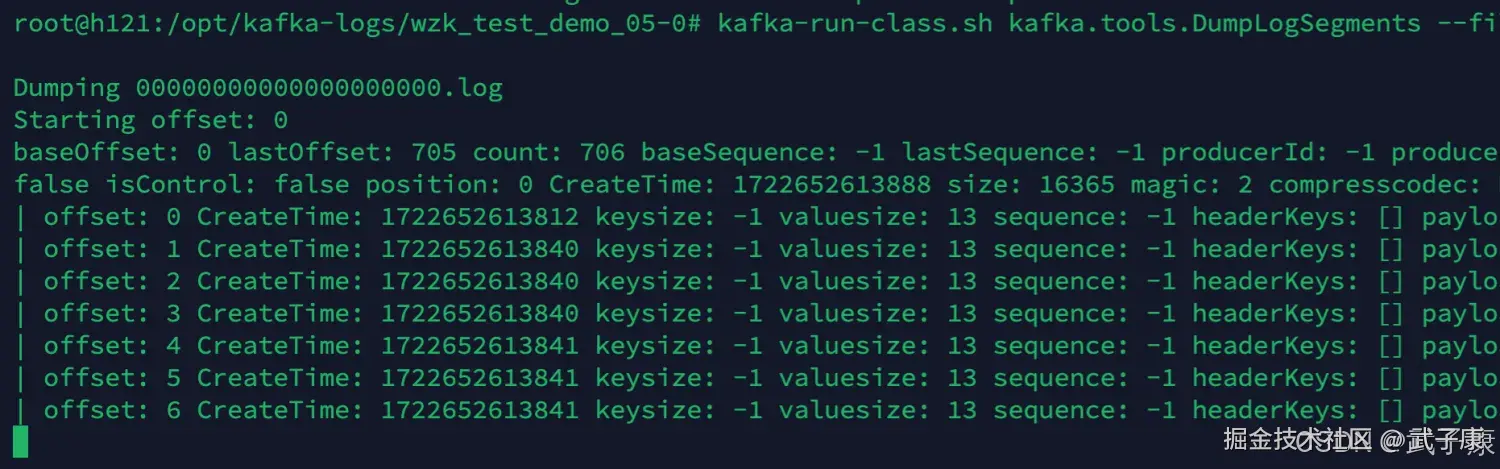
消息偏移
消息存储
- 消息内容保存在log日志文件中
- 消息封装为Record,追加到log日志文件末尾,采用的是顺序写模式。
- 一个topic的不同分区,可认为是queue,顺序写入接受到的消息
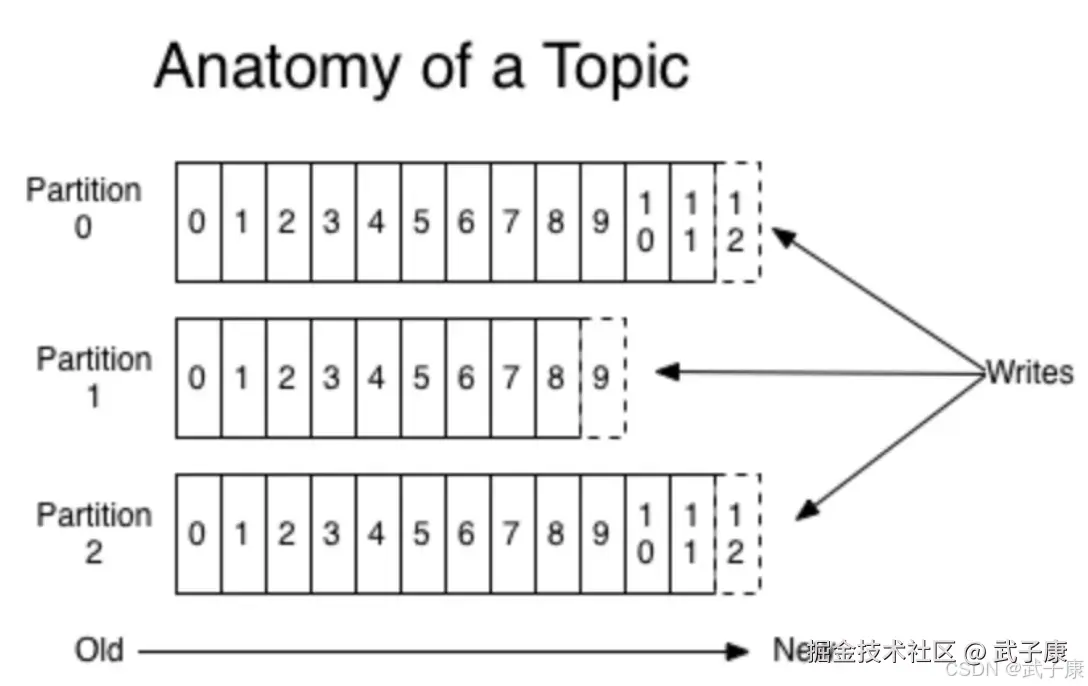 消费者有Offset,下图中,消费者A消费的Offset是9,消费者B消费的Offset是11,不同的消费者Offset是交给一个内部公共topic来记录的。
消费者有Offset,下图中,消费者A消费的Offset是9,消费者B消费的Offset是11,不同的消费者Offset是交给一个内部公共topic来记录的。
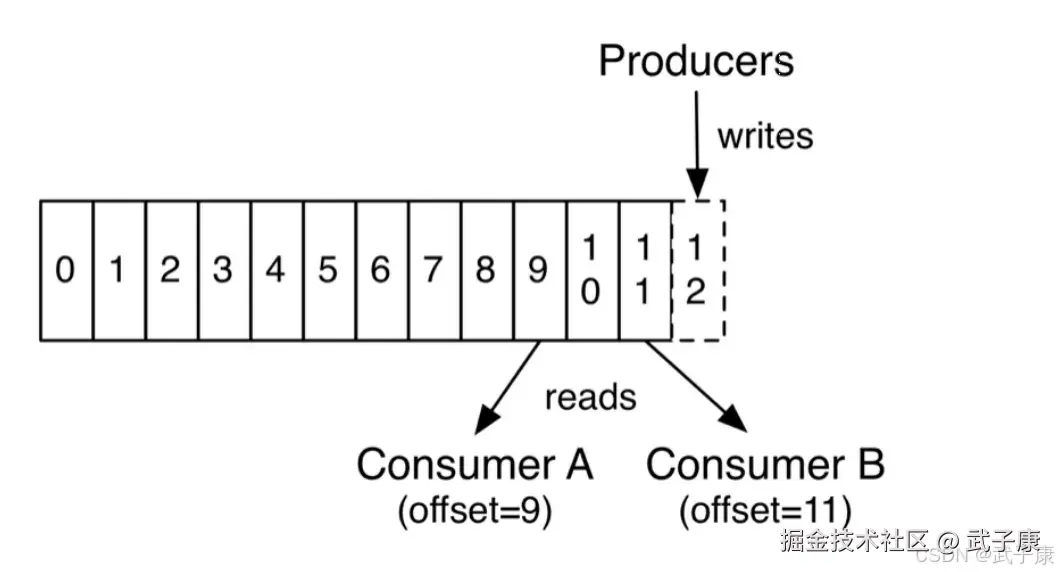 时间戳索引文件,它的作用是可以让用户查询某个时间段的内的消息,它一条数据的结构是时间戳(8 byte) + 相对Offset(4 byte)。如果要使用这个索引文件,首先需要通过时间范围,找到相对Offset,然后再去对应的Index文件中找到Position信息,然后才能遍历log文件,它也需要使用上面说的Index文件的。
时间戳索引文件,它的作用是可以让用户查询某个时间段的内的消息,它一条数据的结构是时间戳(8 byte) + 相对Offset(4 byte)。如果要使用这个索引文件,首先需要通过时间范围,找到相对Offset,然后再去对应的Index文件中找到Position信息,然后才能遍历log文件,它也需要使用上面说的Index文件的。
但是Producer生产消息可以指定消息的时间戳,这可能将导致消息的时间戳不一定有先后顺序,因为尽量不要生产消息时指定时间戳。
偏移量索引
-
索引文件存储位置与命名 :Kafka的索引信息保存在与日志文件同名的
.index文件中(例如topic-partition-0.index)。这些索引文件与对应的.log数据文件存放在同一目录下,共同组成一个完整的分区存储单元。 -
稀疏索引机制:
- 日志写入时默认每积累4KB数据(由
log.index.interval.bytes参数配置,可调整)才会生成一条索引记录 - 这种设计形成了稀疏索引结构,例如在1GB的日志文件中可能只包含约25万条索引(1GB/4KB),相比为每条消息建索引可减少99%以上的索引量
- 实际查询时需要通过二分查找定位最近的索引点,再顺序扫描找到目标消息
- 日志写入时默认每积累4KB数据(由
-
日志文件物理结构:
- 采用顺序追加写入 方式,每条记录包含:
- Message:实际的消息内容(含key/value/headers等)
- 绝对Offset:8字节长整型,表示消息在分区中的全局序列号
- Position:4字节整型,记录该消息在文件中的物理起始位置
- 示例:
[MessageA][offset=1000][position=0] → [MessageB][offset=1001][position=1024]
- 采用顺序追加写入 方式,每条记录包含:
-
索引文件优化设计:
- 采用紧凑的二进制结构,每条索引记录包含:
- 相对Offset:4字节(存储与当前segment第一条消息的offset差值)
- Position:4字节(对应消息在.log文件中的物理位置)
- 例如segment起始offset为1000时:
- 绝对offset 1005 → 存储为相对offset 5
- 节省50%存储空间(相比8字节绝对offset)
- 查询时自动完成相对/绝对offset转换,对客户端完全透明
- 采用紧凑的二进制结构,每条索引记录包含:
-
典型查询流程:
- 客户端请求offset=1005的消息
- 二分查找.index文件找到最近条目(相对offset=5)
- 根据position定位.log文件位置
- 顺序扫描找到绝对offset=1005的消息
稀疏索引的密度不高,但是Offset有序,二分查找的时间复杂度为O(LogN),如果从头遍历时间复杂度是O(N)如下图: 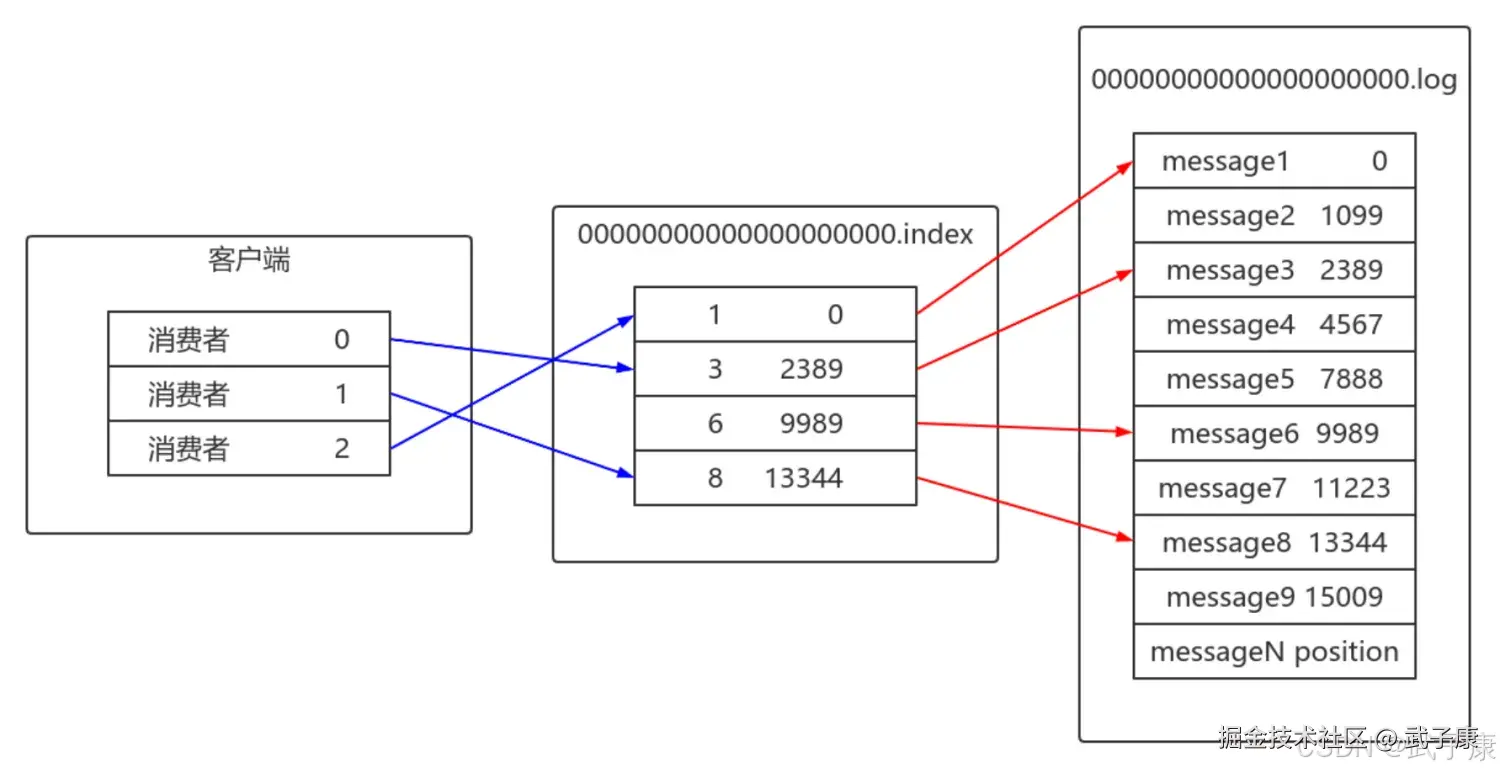 偏移量索引由相对偏移量和物理地址组成:
偏移量索引由相对偏移量和物理地址组成:  可以通过下面的命令解析 .index 文件:
可以通过下面的命令解析 .index 文件:
shell
kafka-run-class.sh kafka.tools.DumpLogSegments --files 00000000000000000000.index --print-data-log | head注意:Offset 与 Position 没有直接关系,因为会删除数据和清理日志 注意:Offset 与 Position 没有直接关系,因为会删除数据和清理日志 注意:Offset 与 Position 没有直接关系,因为会删除数据和清理日志
执行结果如下图所示: 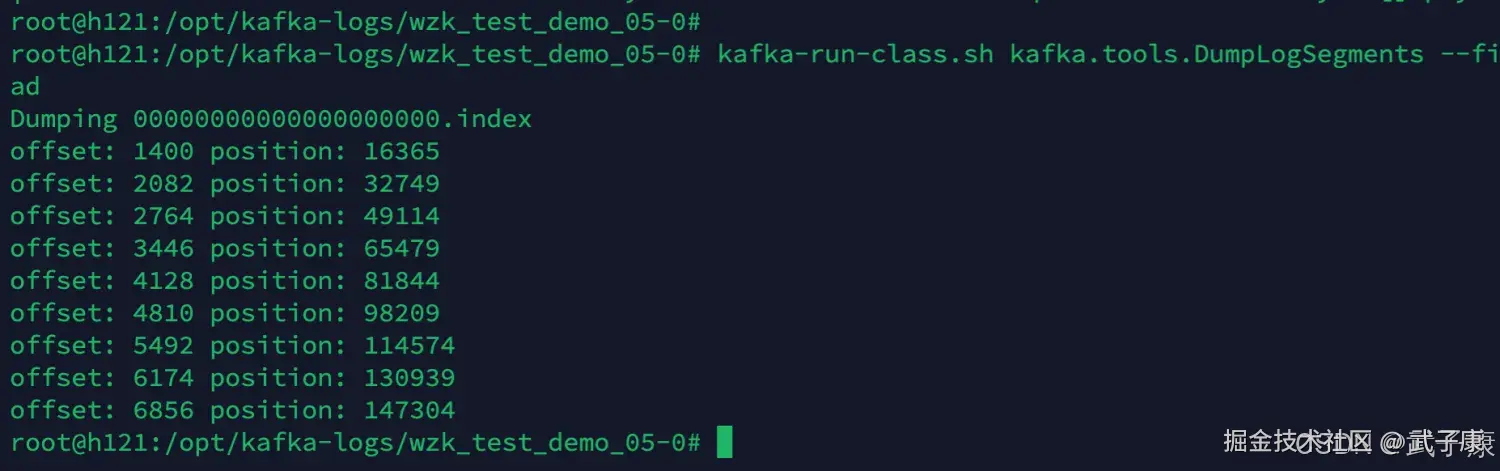
在偏移量索引文件索引中,索引数据都是顺序记录Offset,但时间戳索引文件中每个追加的索引时间戳必须大于之前追加的索引项,否则不予追加。在Kafka 0.11.0.0以后,消息元数据中存在若干的时间戳信息。 如果Broker端参数 log.message.timestamp.type 设置为 LogAppendTime,那么时间戳必定能保持单调增长。反之如果是CreateTime则无法保证顺序。
注意:timestamp文件中的Offset与Index文件中的relativeOffset不是一一对应的,因为数据的写入是各自追加的 注意:timestamp文件中的Offset与Index文件中的relativeOffset不是一一对应的,因为数据的写入是各自追加的 注意:timestamp文件中的Offset与Index文件中的relativeOffset不是一一对应的,因为数据的写入是各自追加的
思考: 如何查看偏移量为23的消息?
Kafka中存在一个 ConcurrentSkipListMap来保存在每个日志分段中,通过跳跃表方式,定位到00000000000000000000.index,通过二分法在偏移量索引文件中找到不大于23的最大索引项,即Offset 20那栏,然后从日志分段文件中的物理位置为320开始顺序查找偏移量为23的消息。
时间戳
在偏移量索引文件中,索引数据都是顺序记录Offset,但时间戳索引文件中每个追加的索引时间戳必须大于之前追加的索引项,否则不予追加。 在Kafka 0.11.0.0以后,消息信息中存在若干的时间戳消息。如果Broker端参数log.message.timestamp.type设置为LogAppendTime,那么时间戳必定能保持单调增长。反之如果是CreateTime则无法保证顺序。
通过时间戳方式进行查找消息,需要通过查找时间戳索引和偏移量索引两个文件。 时间戳索引格式:前八个字节表示时间戳,后四个字节表示偏移量。


思考: 查找指定时间戳开始的消息?
假设某个时间戳为A
- 查找时间戳A应该在哪个日志分段中,将A和每个日志分段中最大时间戳LargestTimestamp逐一对比,直到找到不小于A所对应的日志分段。
- 日志分段中的LargestTimeStamp的计算是:先查询该日志分段所对应时间戳索引文件,找到最后一条索引项,若最后一条索引项的时间戳字段值大于0,则取该值,否则取该日志分段的最近修改时间。
- 查找该日志分段的偏移量索引文件,查找该偏移量对应的物理地址。
- 日志文件中从320的物理位置开始查找小于A的数据。