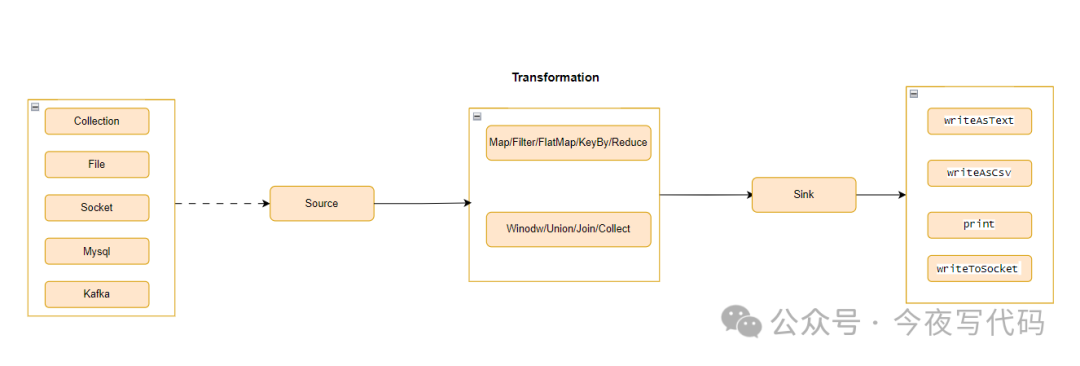
Flink数据流结构
DataStream 转换
通常我们需要分析的业务数据可能存在如下问题:
-
数据中包含一些我们不需要的数据
-
数据格式不方面分析
因此我们需要对原始数据流进行加工,比如过滤、转换等操作才可以进行数据分析。
"
Flink DataStream 转换主要作用:
对输入的数据流(DataStream)经过各种转换操作以生成新的数据流
操作分类
-
单条记录操作
- 比如 Map 、 Fliter
-
基于窗口 (Window)操作
- 窗口根据某些特征(例如,过去 5 秒内到达的数据)对所有流事件进行分组
-
合并数据流
- union 、join、connect 可以将多个DataStream 合并为一个DataStream 进行分析处理
-
拆分数据流
- 将数据流拆分为多个数据流分别对每个数据流进行分析
基本操作
| 操作 | 描述 | 备注 |
|---|---|---|
| Map | 将数据流中每个元素转换为新的元素 | 类似 Java 中 stream.map 操作 |
| Filter | 筛选只保留符合条件的数据 | 类似 Java 中 stream.filter 操作 |
| FlatMap | 将一个输入"展开"为多个元素 | |
| KeyBy | 将流逻辑划分为不相交的分区。所有具有相同键的记录都分配到同一个分区。 | |
| Reduce | 对具有相同键的元素进行规约操作,如求和、求最大值 |
使用示例
Map
"
将数据流中每个元素转换为新的元素
使用场景很多,主要对原始数据进行加工转换,Java 8 中 stream().map 操作相信大家不陌生, Flink中map 操作类似。
以下展示对数据流中数字取绝对值例子。
java
DataStream<Integer> dataStream = //...
dataStream.map(new MapFunction<Integer, Integer>() {
@Override
public Integer map(Integer value) throws Exception {
return value >=0 ? value : -value;
}
});Filter
筛选出数据流中符合条件的数据,进行分析, 该操作同样与Java 8 中 stream().filter 类型。
以下代码 保留数据流中正数。
java
dataStream.filter(new FilterFunction<Integer>() {
@Override
public boolean filter(Integer value) throws Exception {
return value > 0;
}
});FlatMap
该操作将一个输入"展开"为多个元素,简单来说一个对象,变成一个List。
典型例子,将句子拆分为单词
java
dataStream.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String value, Collector<String> out)
throws Exception {
for(String word: value.split(" ")){
out.collect(word);
}
}
});Reduce 操作
对具有相同键的元素进行规约操作,如求和、求最大值。单词统计能够很好的展示 Flink 基本操作,包括reduce操作。
数据源进行KeyBy 后, Reduce 操作即 数据流按Key 分组聚合
java
public class WordCount {
public static void main(String[] args) throws Exception {
// 设置执行环境
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 从文件中读取文本数据
DataStream<String> text = env.readTextFile("your file");
// 使用 flatMap 将文本分割成单词
DataStream<Tuple2<String, Integer>> counts = text
.flatMap(new Tokenizer())
// 使用 keyBy 分组,然后使用 reduce 进行聚合
.keyBy(value->value.f0)
.reduce(new ReduceFunction<Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> reduce(Tuple2<String, Integer> value1, Tuple2<String, Integer> value2) {
return new Tuple2<>(value1.f0, value1.f1 + value2.f1);
}
});
// 打印结果
counts.print();
// 执行程序
env.execute("Flink Word Count Example");
}
// 自定义 Tokenizer 用于分割文本
public static final class Tokenizer implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) {
// 使用空格分割字符串
for (String word : value.toLowerCase().split("\\s+")) {
if (word.length() > 0) {
out.collect(new Tuple2<>(word, 1));
}
}
}
}
}总结
本文介绍了Flink 数据流基本操作Map/Filter/FlatMap/KeyBy/Reduce 的用法以及使用场景,并通过一个完整的例子展示 这些基本操作同时使用,完成数据分析过程。
对于Flink 一些其他高级操作,会持续更新中。