0.1 环境配置
首先点击左上角图标,打开Terminal,运行如下脚本创建虚拟环境:
# 创建虚拟环境 conda create -n langgpt python=3.10 -y
运行下面的命令,激活虚拟环境:
conda activate langgpt
之后的操作都要在这个环境下进行。激活环境后,安装必要的Python包,依次运行下面的命令:
# 安装一些必要的库 conda install pytorch==2.1.2 torchvision==0.16.2 torchaudio==2.1.2 pytorch-cuda=12.1 -c pytorch -c nvidia -y # 安装其他依赖 pip install transformers==4.43.3 pip install streamlit==1.37.0 pip install huggingface_hub==0.24.3 pip install openai==1.37.1 pip install lmdeploy==0.5.2
0.2 创建项目路径
运行如下命令创建并打开项目路径:
## 创建路径 mkdir langgpt ## 进入项目路径 cd langgpt
0.3 安装必要软件
运行下面的命令安装必要的软件:
apt-get install tmux
tmux 主要有以下几个重要作用:
一、实现多窗口管理
在终端操作中,你可以使用 tmux 创建多个窗口,每个窗口可以运行不同的任务。比如,你可以在一个窗口中进行代码编译,在另一个窗口中查看日志文件,在第三个窗口中运行服务器等。这样可以大大提高工作效率,避免频繁切换不同的终端窗口。
二、会话持久化
即使你关闭了终端连接,tmux 中的会话仍然会在后台运行。当你再次打开终端并连接到 tmux 时,可以恢复到之前的会话状态,所有正在运行的任务都不会被中断。这对于长时间运行的任务或者需要在不同时间继续进行的工作非常有用。
三、分屏功能
tmux 可以将一个窗口分割成多个窗格,每个窗格可以独立显示不同的内容。你可以根据自己的需要进行水平或垂直分屏,方便同时查看和操作多个任务。例如,你可以在一个屏幕上同时查看代码文件和命令输出。
四、远程协作
在多人协作的场景中,tmux 可以让多个用户连接到同一个会话,共同操作和查看任务进度。这对于团队合作开发或者远程技术支持非常有帮助。
总之,tmux 是一个强大的终端复用工具,可以帮助你更好地管理终端任务,提高工作效率,并且提供了很多灵活的功能来满足不同的需求。
1. 模型部署
这部分基于LMDeploy将开源的InternLM2-chat-1_8b模型部署为OpenAI格式的通用接口。
1.1 获取模型
-
如果使用intern-studio开发机,可以直接在路径
/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b下找到模型 -
如果不使用开发机,可以从huggingface上获取模型,地址为:https://huggingface.co/internlm/internlm2-chat-1_8b
可以使用如下脚本下载模型:
from huggingface_hub import login, snapshot_download import os os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com' login(token=“your_access_token") models = ["internlm/internlm2-chat-1_8b"] for model in models: try: snapshot_download(repo_id=model,local_dir="langgpt/internlm2-chat-1_8b") except Exception as e: print(e) pass
1.2 部署模型为OpenAI server
由于服务需要持续运行,需要将进程维持在后台,所以这里使用tmux软件创建新的命令窗口。运行如下命令创建窗口:
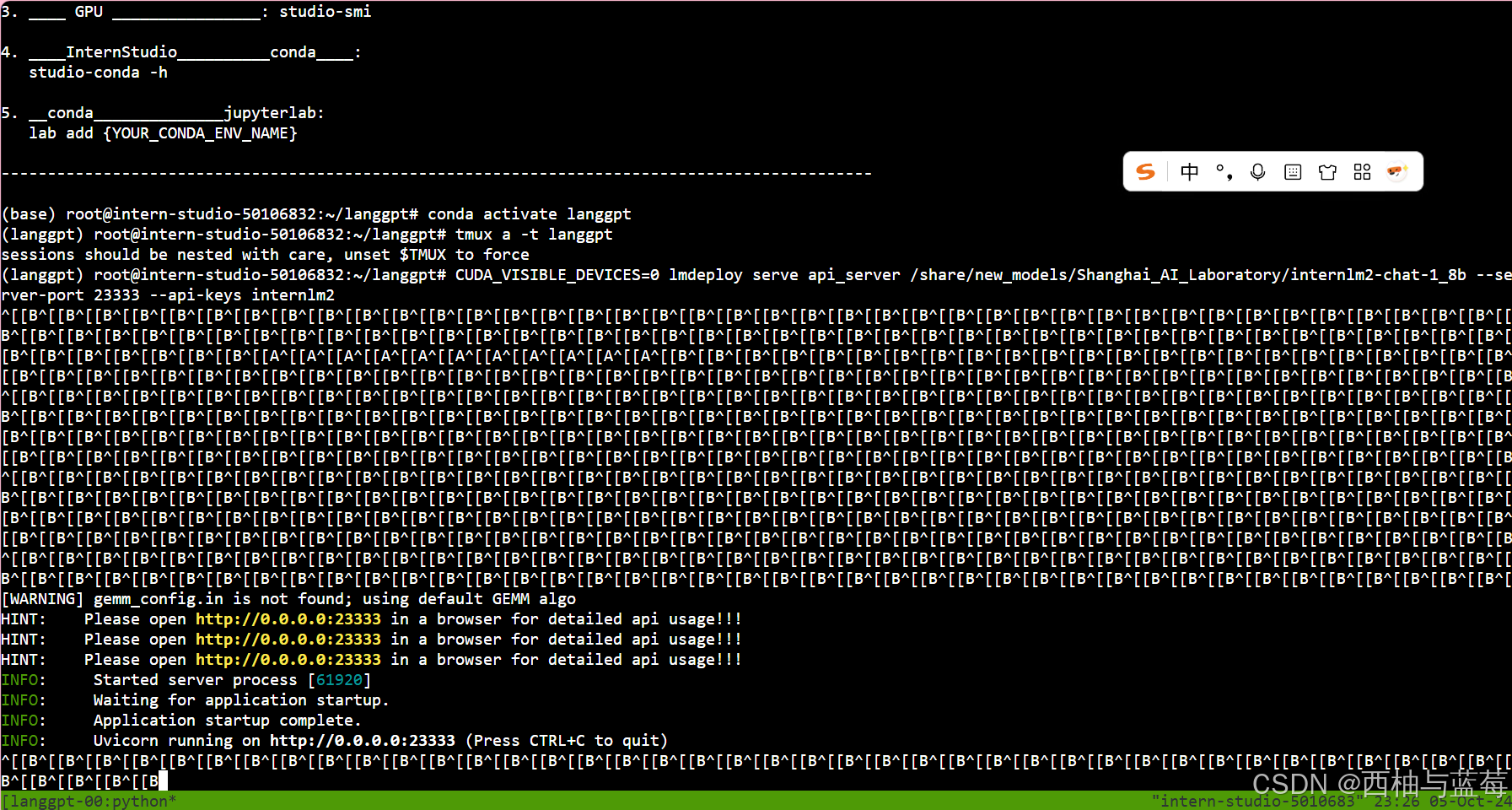
tmux new -t langgpt
创建完成后,运行下面的命令进入新的命令窗口(首次创建自动进入,之后需要连接):
tmux a -t langgpt"tmux a" 通常是指连接(attach)到一个现存的 tmux 会话。
"-t langgpt" 表示指定要连接的会话名称为 "langgpt"。
所以整体意思就是连接到名为 "langgpt" 的 tmux 会话中,以便继续在这个会话中进行操作和查看该会话中正在运行的任务等。
进入命令窗口后,需要在新窗口中再次激活环境,命令参考0.1节。然后,使用LMDeploy进行部署,参考如下命令:
使用LMDeploy进行部署,参考如下命令:
CUDA_VISIBLE_DEVICES=0 lmdeploy serve api_server /share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b --server-port 23333 --api-keys internlm2
更多设置,可以参考:Welcome to LMDeploy's tutorials! --- lmdeploy
部署成功后,可以利用如下脚本调用部署的InternLM2-chat-1_8b模型并测试是否部署成功。
from openai import OpenAI client = OpenAI( api_key = "internlm2", base_url = "http://0.0.0.0:23333/v1" ) response = client.chat.completions.create( model=client.models.list().data[0].id, messages=[ {"role": "system", "content": "请介绍一下你自己"} ] ) print(response.choices[0].message.content)
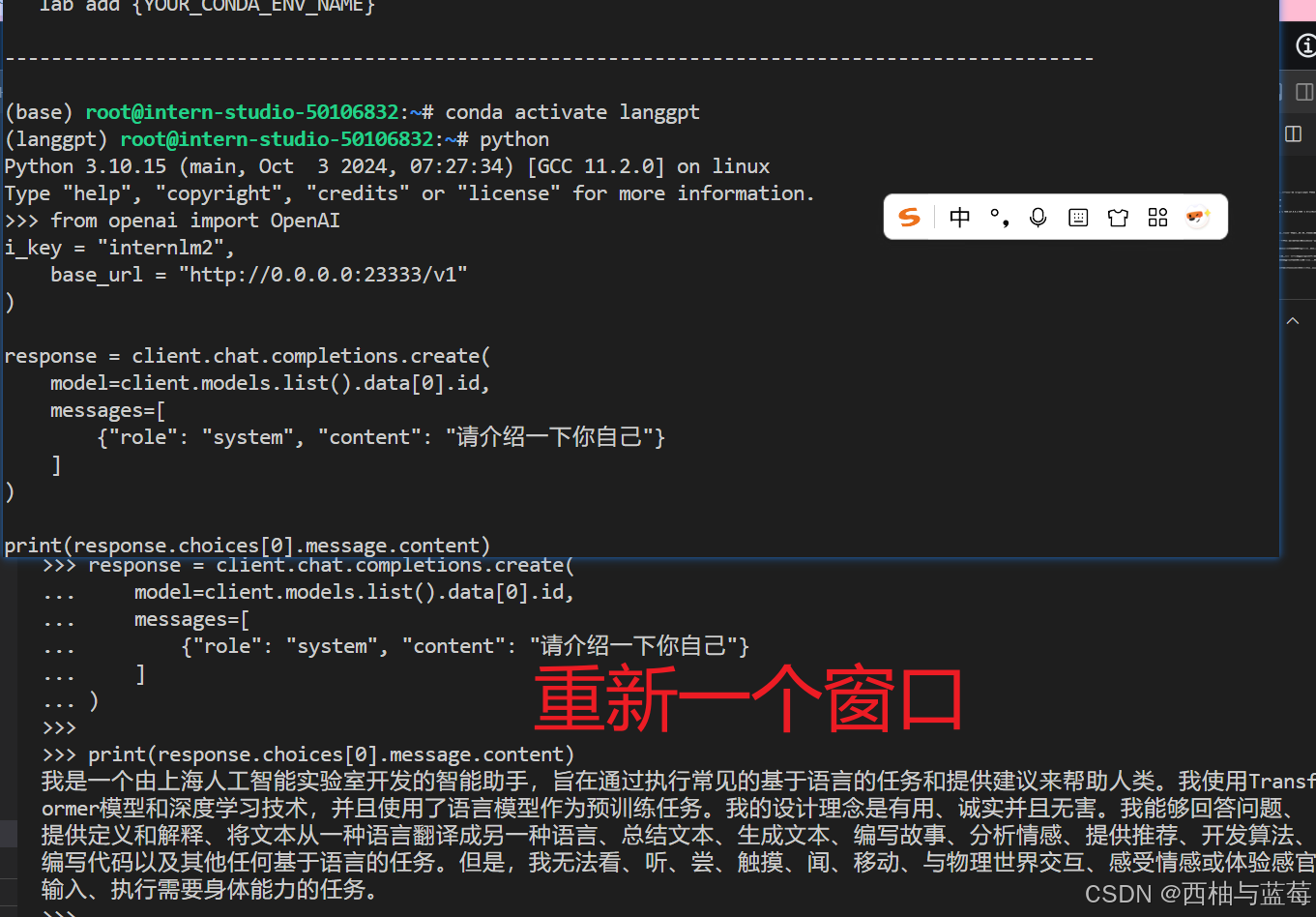
服务启动完成后,可以按Ctrl+B进入tmux的控制模式,然后按D退出窗口连接,更多操作参考。
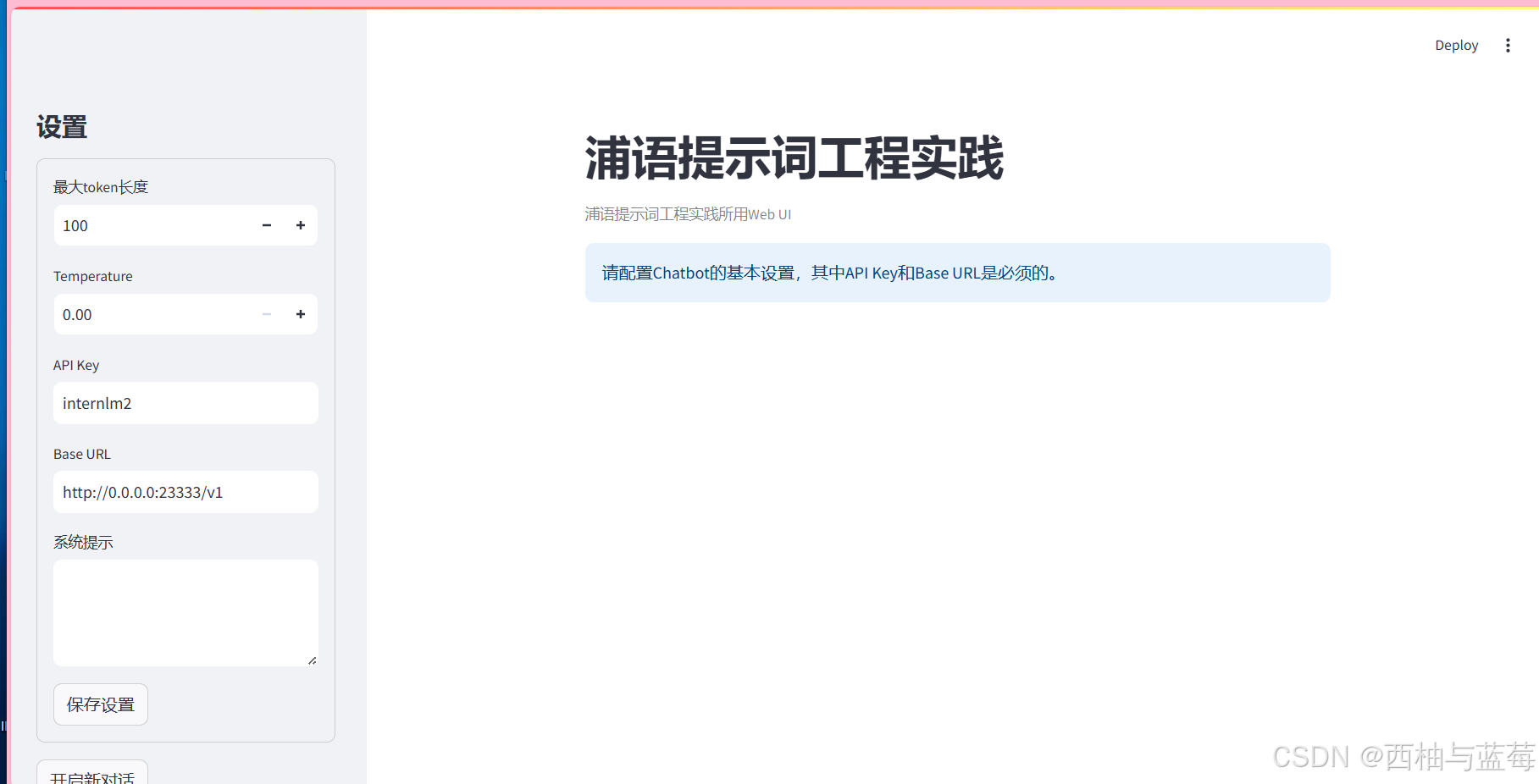
1.3 图形化界面调用
InternLM部署完成后,可利用提供的chat_ui.py创建图形化界面,在实战营项目的tools项目中。
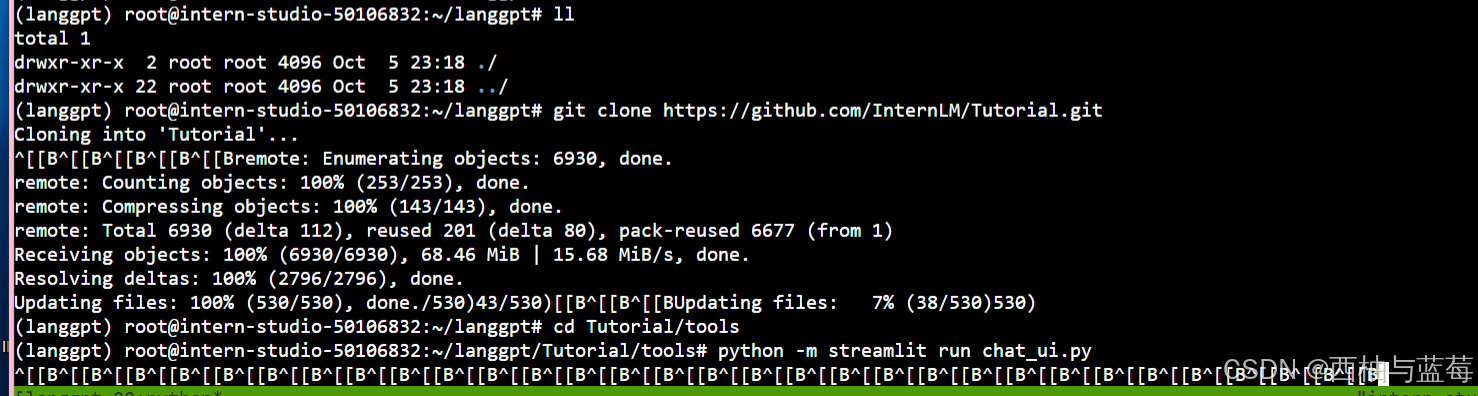
首先,从Github获取项目,运行如下命令:
git clone https://github.com/InternLM/Tutorial.git
下载完成后,运行如下命令进入项目所在的路径:
cd Tutorial/tools
进入正确路径后,运行如下脚本运行项目:
python -m streamlit run chat_ui.py
参考L0/Linux的2.3部分进行端口映射,在本地终端中输入映射命令,可以参考如下命令:
ssh -p {ssh端口,从InternStudio获取} root@ssh.intern-ai.org.cn -CNg -L 7860:127.0.0.1:8501 -o StrictHostKeyChecking=no
ssh -p 49726 root@ssh.intern-ai.org.cn -CNg -L 7860:127.0.0.1:7860 -o StrictHostKeyChecking=no
如果未配置开发机公钥,还需要输入密码,从InternStudio获取。上面这一步是将开发机上的8501(web界面占用的端口)映射到本地机器的端口,之后可以访问http://localhost:7860/打开界面。
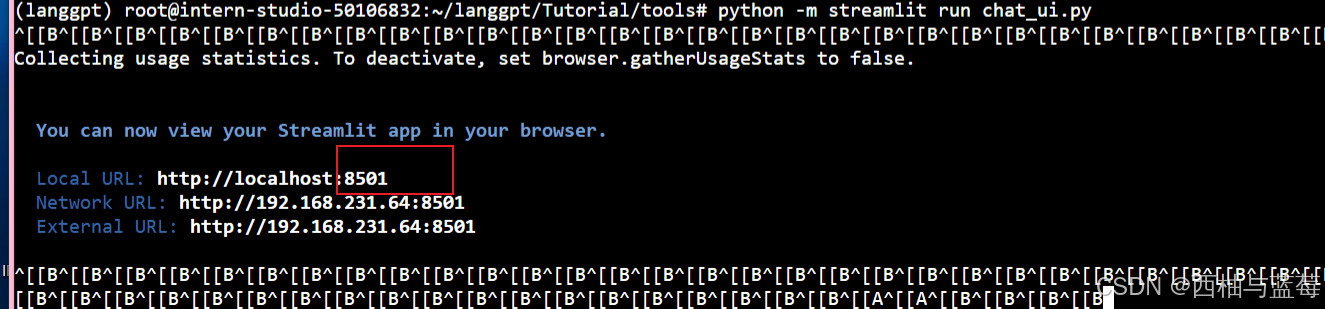

启动后界面如下: