当Hugging Face遇上GitHub:预训练语言模型的跨平台同步难题与解决方案
论文信息
- 原标题:On the synchronization between Hugging Face pre-trained language models and their upstream GitHub repository
- 主要作者:Ajibode Adekunle(Queen's University)、Abdul Ali Bangash(Lahore University of Management Sciences)、Bram Adams(Queen's University)、Ahmed E. Hassan(Queen's University)
- APA引文格式 :Adekunle, A., Bangash, A. A., Adams, B., & Hassan, A. E. (2025). On the synchronization between Hugging Face pre-trained language models and their upstream GitHub repository. arXiv preprint arXiv:2508.10157v1.
- 发布信息:arXiv:2508.10157v1 cs.SE 13 Aug 2025
一段话总结
该研究通过分析325个预训练语言模型(PTLM)家族的904个Hugging Face(HF)变体,揭示了上游GitHub(GH)与下游HF平台在提交活动上的差异与同步模式。研究发现,GH聚焦模型结构和训练基础设施优化,而HF侧重文档和部署配置;两者存在八种同步模式,其中"分散同步"占比39.4%,反映出跨平台协作的结构性脱节,最终提出改善模型发布流程的实践建议。
研究背景
预训练语言模型(PTLMs)已成为NLP领域的"基础设施",从文本生成到翻译,无处不在。但这些模型的开发和分发依赖两个核心平台:GitHub(GH)作为"上游",存储训练代码、脚本和配置;Hugging Face(HF)作为"下游",负责模型分发、部署工具和文档。
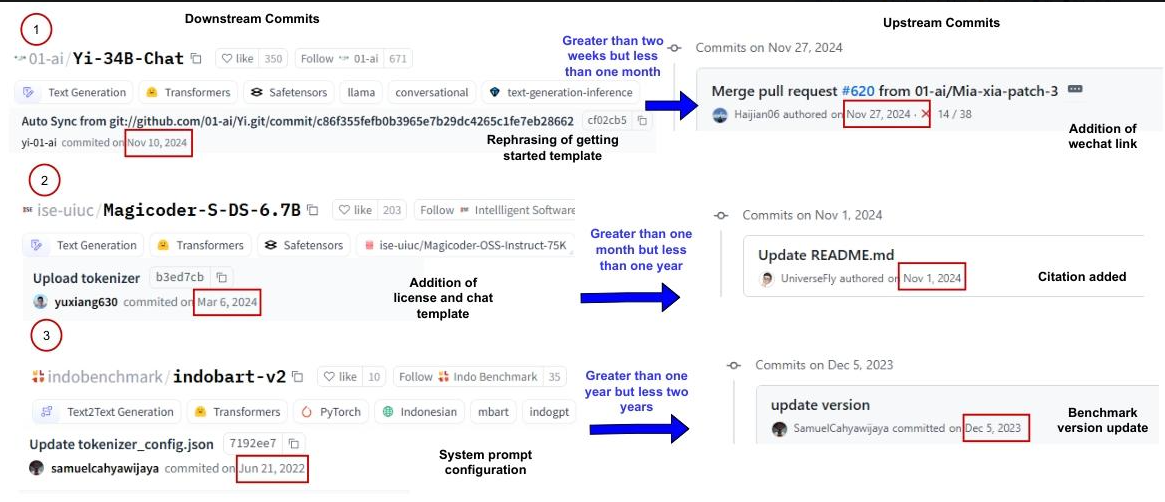
这就像软件开发中"代码仓库"与"应用商店"的关系------本应无缝协作,却常出问题。例如,模型cahya/bert-base-indonesian-522M的GH仓库在2020年7-8月多次更新(如修正模型名称、添加训练脚本),但HF平台直到9月才更新,且仅同步了部分配置,导致用户获取的模型信息过时。
更普遍的问题包括:版本号不一致、功能更新不同步、文档与代码脱节。这些不仅影响开发者协作,更让用户面临"用旧模型跑新任务"的风险。为何两个平台会"各自为政"?这正是研究要解答的核心。
创新点
- 首次聚焦跨平台同步:以往研究多单独分析GH或HF,而该研究首次系统对比两者的协作模式。
- 三维度模式分类:从"滞后时间"(谁先更新)、"同步类型"(是否重叠)、"强度"(更新频率)三个维度,提炼出8种典型同步模式,而非简单的"同步/不同步"二分法。
- 混合方法研究:结合手动标注(1600条提交)、LLM自动分类(Gemini-1.5 Flash)和统计分析,兼顾精度与规模。
- 关联模型成熟度:发现同步模式随模型生命周期变化,成熟模型反而更易出现滞后。
研究方法和思路
- 数据筛选:从HF提取726,094个模型,经多轮过滤(保留NLP模型、关联GH仓库、下载量≥10,000),最终聚焦325个PTLM家族(904个HF变体)。
- 提交分类 :
- 手动标注1600条提交(800条来自GH,800条来自HF),使用15类 taxonomy(如模型结构、预处理、依赖管理)。
- 用Gemini-1.5 Flash自动标注剩余155,200条提交,通过Cohen's Kappa验证一致性(GH:0.79,HF:0.72)。
- 同步模式识别 :
- 计算"滞后":GH先更新、HF先更新或同步更新。
- 定义"同步类型":完全同步、部分同步、无同步等。
- 评估"强度":更新频率(罕见、零星、频繁)。
- 组合三维度,得到8种模式(如"分散同步"指部分重叠且延迟长)。
- 统计分析:用卡方检验、Jaccard相似度等方法,分析模式分布与模型成熟度、贡献者数量的关系。
主要贡献
| 研究问题 | 核心发现 | 价值 |
|---|---|---|
| RQ1:平台提交差异 | GH侧重模型结构(29.7%)、训练基础设施(9.0%);HF侧重外部文档(38.8%)、预处理(16.6%) | 明确分工,指导开发者针对性更新 |
| RQ2:同步模式 | 8种模式,如"分散同步"(39.4%,部分重叠+长延迟)、"频繁同步"(2.5%,持续重叠) | 帮助识别协作瓶颈 |
| RQ3:模式分布 | 成熟模型更易"分散同步",平均滞后15.82天;多贡献者未必提升同步质量 | 为不同阶段模型提供优化方向 |
- 开源资源:数据集和代码见 replication package(Adekunle, 2025)。
- 实践意义:开发者可通过自动化脚本(如同步文档、版本号)改善协作;用户需交叉验证两平台信息避免使用过时模型🔶1-611。
关键问题
-
Q:GitHub和Hugging Face在PTLM开发中分别扮演什么角色?
A:GH是"实验室",负责模型代码、训练脚本和基础设施优化;HF是"商店",专注模型分发、文档和部署工具。
-
Q:为什么跨平台同步会出问题?
A:两者关注的提交类型差异大(GH改代码vs HF改文档),且缺乏自动化同步工具,依赖人工协调。
-
Q:最常见的同步模式是什么?有何风险?
A:"分散同步"(39.4%),表现为部分更新重叠、多数更新独立,可能导致用户获取过时模型。
-
Q:模型越成熟,同步越顺畅吗?
A:相反,成熟模型平均滞后15.82天,可能因维护者精力分散或优先级变化。
总结
该研究通过大规模数据分析,揭示了PTLM在GH和HF平台的协作现状:分工明确但同步薄弱,8种模式中"分散同步"占比最高,反映出跨平台协作的结构性挑战。研究不仅为开发者提供了优化同步流程的方向(如自动化工具、明确分工),也提醒用户警惕平台信息不一致的风险。其提出的同步模式分类和开源数据集,为后续研究奠定了基础。