我自己的原文哦~ https://blog.51cto.com/whaosoft/11668984
一、 CV确定对象的方向
介绍如何使用OpenCV确定对象的方向(即旋转角度,以度为单位)。

先决条件 安装Python3.7或者更高版本。可以参考下文链接: https://automaticaddison.com/how-to-set-up-anaconda-for-windows-10/ 或者自行下载安装:https://www.python.org/getit/相关包安装与设置 在我们开始之前,让我们确保我们已经安装了所有的软件包。检查您的机器上是否安装了OpenCV 。如果你使用 Anaconda,你可以输入:conda install -c conda-forge opencv或者使用pip安装,指令:pip install opencv-python安装科学计算库 Numpy:pip install numpy准备测试图像 找一张图片。我的输入图像宽度为 1200 像素,高度为 900 像素。我的输入图像的文件名是input_img.jpg。编写代码 这是代码。它接受一个名为input_img.jpg的图像并输出一个名为output_img.jpg的带注释的图像。部分代码来自官方 OpenCV 实现:https://docs.opencv.org/4.x/d1/dee/tutorial_introduction_to_pca.html
import cv2 as cv
from math import atan2, cos, sin, sqrt, pi
import numpy as np
def drawAxis(img, p_, q_, color, scale):
p = list(p_)
q = list(q_)
## [visualization1]
angle = atan2(p[1] - q[1], p[0] - q[0]) # angle in radians
hypotenuse = sqrt((p[1] - q[1]) * (p[1] - q[1]) + (p[0] - q[0]) * (p[0] - q[0]))
# Here we lengthen the arrow by a factor of scale
q[0] = p[0] - scale * hypotenuse * cos(angle)
q[1] = p[1] - scale * hypotenuse * sin(angle)
cv.line(img, (int(p[0]), int(p[1])), (int(q[0]), int(q[1])), color, 3, cv.LINE_AA)
# create the arrow hooks
p[0] = q[0] + 9 * cos(angle + pi / 4)
p[1] = q[1] + 9 * sin(angle + pi / 4)
cv.line(img, (int(p[0]), int(p[1])), (int(q[0]), int(q[1])), color, 3, cv.LINE_AA)
p[0] = q[0] + 9 * cos(angle - pi / 4)
p[1] = q[1] + 9 * sin(angle - pi / 4)
cv.line(img, (int(p[0]), int(p[1])), (int(q[0]), int(q[1])), color, 3, cv.LINE_AA)
## [visualization1]
def getOrientation(pts, img):
## [pca]
# Construct a buffer used by the pca analysis
sz = len(pts)
data_pts = np.empty((sz, 2), dtype=np.float64)
for i in range(data_pts.shape[0]):
data_pts[i,0] = pts[i,0,0]
data_pts[i,1] = pts[i,0,1]
# Perform PCA analysis
mean = np.empty((0))
mean, eigenvectors, eigenvalues = cv.PCACompute2(data_pts, mean)
# Store the center of the object
cntr = (int(mean[0,0]), int(mean[0,1]))
## [pca]
## [visualization]
# Draw the principal components
cv.circle(img, cntr, 3, (255, 0, 255), 2)
p1 = (cntr[0] + 0.02 * eigenvectors[0,0] * eigenvalues[0,0], cntr[1] + 0.02 * eigenvectors[0,1] * eigenvalues[0,0])
p2 = (cntr[0] - 0.02 * eigenvectors[1,0] * eigenvalues[1,0], cntr[1] - 0.02 * eigenvectors[1,1] * eigenvalues[1,0])
drawAxis(img, cntr, p1, (255, 255, 0), 1)
drawAxis(img, cntr, p2, (0, 0, 255), 5)
angle = atan2(eigenvectors[0,1], eigenvectors[0,0]) # orientation in radians
## [visualization]
# Label with the rotation angle
label = " Rotation Angle: " + str(-int(np.rad2deg(angle)) - 90) + " degrees"
textbox = cv.rectangle(img, (cntr[0], cntr[1]-25), (cntr[0] + 250, cntr[1] + 10), (255,255,255), -1)
cv.putText(img, label, (cntr[0], cntr[1]), cv.FONT_HERSHEY_SIMPLEX, 0.5, (0,0,0), 1, cv.LINE_AA)
return angle
# Load the image
img = cv.imread("input_img.jpg")
# Was the image there?
if img is None:
print("Error: File not found")
exit(0)
cv.imshow('Input Image', img)
# Convert image to grayscale
gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
# Convert image to binary
_, bw = cv.threshold(gray, 50, 255, cv.THRESH_BINARY | cv.THRESH_OTSU)
# Find all the contours in the thresholded image
contours, _ = cv.findContours(bw, cv.RETR_LIST, cv.CHAIN_APPROX_NONE)
for i, c in enumerate(contours):
# Calculate the area of each contour
area = cv.contourArea(c)
# Ignore contours that are too small or too large
if area < 3700 or 100000 < area:
continue
# Draw each contour only for visualisation purposes
cv.drawContours(img, contours, i, (0, 0, 255), 2)
# Find the orientation of each shape
getOrientation(c, img)
cv.imshow('Output Image', img)
cv.waitKey(0)
cv.destroyAllWindows()
# Save the output image to the current directory
cv.imwrite("output_img.jpg", img)运行结果
使用PCA(主成分分析)方法获取物体的主方向,效果如下:
了解旋转轴
每个对象的正 x 轴是红线。每个对象的正 y 轴是蓝线。 全局正x 轴从左到右水平穿过图像。全局正z 轴指向此页外。全局正y 轴从图像底部垂直指向图像顶部。 使用右手定则测量旋转,将四根手指伸直(食指到小指)沿全局正 x 轴方向伸出。
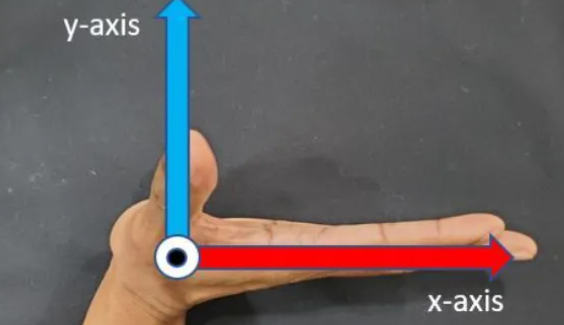
然后将四根手指逆时针旋转 90 度。您的指尖指向正 y 轴,而您的拇指指向页面外指向正 z 轴。

计算0~180°之间的方向
如果我们要计算对象的方向并确保结果始终在 0 到 180 度之间,我们可以使用以下代码:
# This programs calculates the orientation of an object.
# The input is an image, and the output is an annotated image
# with the angle of otientation for each object (0 to 180 degrees)
import cv2 as cv
from math import atan2, cos, sin, sqrt, pi
import numpy as np
# Load the image
img = cv.imread("input_img.jpg")
# Was the image there?
if img is None:
print("Error: File not found")
exit(0)
cv.imshow('Input Image', img)
# Convert image to grayscale
gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
# Convert image to binary
_, bw = cv.threshold(gray, 50, 255, cv.THRESH_BINARY | cv.THRESH_OTSU)
# Find all the contours in the thresholded image
contours, _ = cv.findContours(bw, cv.RETR_LIST, cv.CHAIN_APPROX_NONE)
for i, c in enumerate(contours):
# Calculate the area of each contour
area = cv.contourArea(c)
# Ignore contours that are too small or too large
if area < 3700 or 100000 < area:
continue
# cv.minAreaRect returns:
# (center(x, y), (width, height), angle of rotation) = cv2.minAreaRect(c)
rect = cv.minAreaRect(c)
box = cv.boxPoints(rect)
box = np.int0(box)
# Retrieve the key parameters of the rotated bounding box
center = (int(rect[0][0]),int(rect[0][1]))
width = int(rect[1][0])
height = int(rect[1][1])
angle = int(rect[2])
if width < height:
angle = 90 - angle
else:
angle = -angle
label = " Rotation Angle: " + str(angle) + " degrees"
textbox = cv.rectangle(img, (center[0]-35, center[1]-25),
(center[0] + 295, center[1] + 10), (255,255,255), -1)
cv.putText(img, label, (center[0]-50, center[1]),
cv.FONT_HERSHEY_SIMPLEX, 0.7, (0,0,0), 1, cv.LINE_AA)
cv.drawContours(img,[box],0,(0,0,255),2)
cv.imshow('Output Image', img)
cv.waitKey(0)
cv.destroyAllWindows()
# Save the output image to the current directory
cv.imwrite("min_area_rec_output.jpg", img)最终输出结果:
参考链接:https://automaticaddison.com/how-to-determine-the-orientation-of-an-object-using-opencv/
二、 汽车型号图片搜索
该项目将分两个阶段执行。首先,我们将收集数据并将其转换为矢量。在第二阶段,我们将使用该数据以及输入图像,使用Streamlit框架显示类似的图像。
配置环境
我们将使用ImageBind,这是 Meta 开发的开源库,用于将图像转换为矢量。
代码首先安装 ImageBind 库,该库需要从其 GitHub 存储库克隆才能正确集成和使用。
git clone https://github.com/facebookresearch/ImageBind.git
cd ImageBind
pip install -e 。此外,我们还需要一些其他库,包括ultralytics和qdrant-client,以确保项目正确高效地运行。
pip install ultralytics
pip install qdrant-client
pip install streamlit数据采集
我们收集了一系列代表各种类型汽车及其各自价格的图片。
请从这里访问数据集:
https://www.kaggle.com/datasets/vanshkhaneja/cars-prices/随后,将它们存储在列表中:一个用于存储名称,另一个用于存储各自的价格。
cars_img_list = [ "img01" , "img02" , "img03" , "img04" , "img05" , "img06" , "img07" , "img08" , "img09" , "img10" , "img11" , "img12" , "img13" , "img14" , "img15" ]
cars_cost_list = [ "6.49" , "3.99" , "6.66" , "6.65" , "7.04" , "5.65" , "61.85" , "11.00" , "11.63" , "11.56" , "11.86" , "46.05" , "75.90" , "13.59","13.99" ]导入库
现在让我们导入将图像转换为嵌入所需的所有必要库。
from ultralytics import YOLO
import cv2
import os
import torch
from imagebind import data
from imagebind.models import imagebind_model
from imagebind.models.imagebind_model import ModalityType图像分割
我们将使用YOLOv8算法裁剪掉汽车,从而从图像中去除不必要的噪音。
为了实现这一点,我们首先借助YOLOv8在汽车周围绘制一个边界框,然后使用OpenCV剪切出该区域,最后将图像保存在目录中。
model = YOLO('yolov8n.pt')
for im in cars_img_list:
img = cv2.imread("cars_imgs/"+im+".jpg")
img = cv2.resize(img,(320,245))
results = model(img,stream=True)
for r in results:
for box in r.boxes:
x1,y1,x2,y2 = box.xyxy[0]
x1,y1,x2,y2 = int(x1),int(y1),int(x2),int(y2)
cv2.rectangle(img,(int(x1),int(y1)),(int(x2),int(y2)),(255,0,0),1)
cv2.imwrite("cropped_imgs/"+im+"_cropped.jpg",img[y1:y2, x1:x2])图像转矢量
接下来,我们将使用ImageBind库将裁剪的图像转换为矢量嵌入,从而将其转换为数字格式。
注意:这是一个耗时的过程,因为它将从互联网上下载模型。
embedding_list = []
model_embed = imagebind_model.imagebind_huge(pretrained= True )
model_embed.eval( )
model_embed.to( "cpu" )
for i in range ( 1 , len (cars_img_list)):
img_path = "cropped_imgs/img" + str (i)+ "_cropped.jpg"
vision_data = data.load_and_transform_vision_data([img_path], device)
with torch.no_grad():
image_embeddings = model_embed({ModalityType.VISION: vision_data})
embedding_list.append(image_embeddings)为了减少处理时间,您可以设置pretrained=False,尽管这会降低模型的准确性。
让我们保存嵌入以供稍后在代码中使用。
import pickle
with open('embedded_data.pickle', 'wb') as file:
pickle.dump(embedding_list, file)相似图片搜索
进入代码的第二阶段,我们将继续以图像作为输入并识别最相似的图像。随后,我们将显示这些图像及其各自的价格。
导入库
除了先前导入的库之外,还需要以下附加库:
import streamlit as st
from PIL import Image
import base64
import os
from io import BytesIO
import numpy as np现在我们将通过启动ImageBind模型来启动代码,该模型会将上传的输入图像转换为矢量嵌入。
model_embed = imagebind_model.imagebind_huge(pretrained=True)
model_embed.eval()
model_embed.to("cpu")让我们继续打开保存的文件"embedded_data.pickle",其中包含我们的图像数据集的矢量数据。
with open('embedded_data.pickle', 'rb') as file:
embedding_list = pickle.load(file)存储矢量数据
我们将利用开源矢量数据库Qdrant来存储所有图像的嵌入并将其与输入图像进行比较。
client = QdrantClient(":memory:")
client.recreate_collection(
collection_name='vector_comparison',
vectors_cnotallow=VectorParams(size=1024, distance=Distance.COSINE)
)
client.upsert(
collection_name='vector_comparison',
points=[
PointStruct(id=i, vector=embedding_list[i]['vision'][0].tolist()) for i in range(15)
]
)比较图像
接下来,我们将把存储在Qdrant数据库中的每个向量嵌入与提供给程序的输入图像进行比较。
这将通过 3 个步骤完成:
- 从图像中裁剪汽车。
- 将裁剪的图像转换为矢量嵌入。
- 将该向量与其他图像的向量进行比较。
在这个过程中,我们采用余弦相似度来评估嵌入之间的相似度。
我们声明了一个函数,该函数以图像作为输入,并给出与输入图像最相似的 4 张图像的索引。
def image_to_similar_index(cv2Image):
img = cv2.resize(cv2Image,(320,245))
model = YOLO('yolov8n.pt')
results = model(img,stream=True)
results = model(img,stream=True)
for r in results:
for box in r.boxes:
x1,y1,x2,y2 = box.xyxy[0]
x1,y1,x2,y2 = int(x1),int(y1),int(x2),int(y2)
cv2.rectangle(img,(int(x1),int(y1)),(int(x2),int(y2)),(255,0,0),1)
cropped_img = img[y1:y2, x1:x2]
cv2.imwrite("test_cropped.jpg",cropped_img)
vision_data = data.load_and_transform_vision_data(["test_cropped.jpg"], device)
with torch.no_grad():
test_embeddings = model_embed({ModalityType.VISION: vision_data})
client.upsert(
collection_name='vector_comparison',
points=[
PointStruct(id=20, vector=test_embeddings['vision'][0].tolist()),
])
search_result = client.search(
collection_name='vector_comparison',
query_vector=test_embeddings['vision'][0].tolist(),
limit=20 # Retrieve top similar vectors (excluding the new vector itself)
)
return [search_result[1].id,search_result[2].id,search_result[3].id,search_result[4].id]部署模型
我们现在将继续为我们的模型开发前端 Web 应用程序,以增强交互性和用户友好性。
为了实现这一点,我们将利用Streamlit以简单有效的方式为我们的 Python 应用程序创建 Web 界面。
我们将首先配置页面并将文件上传器小部件集成到网页上。
st.set_page_config(layout="wide")
st.title('Similar Cars Finder')
st.markdown("""
<style>
.block-container {
padding-top: 3rem;
padding-bottom: 0rem;
padding-left: 5rem;
padding-right: 5rem;
}
</style>
""", unsafe_allow_html=True)
uploaded_file = st.file_uploader("Upload an image of a car", type=["jpg", "jpeg", "png"])现在我们将创建一个函数来显示带有适当填充和边距的图像以及价格。此函数将图像和价格表作为输入,并以格式化的方式将其显示在网页上。
def display_images_with_padding_and_price(images, prices, width, padding, gap):
cols = st.columns(len(images))
for col, img, price in zip(cols, images, prices):
with col:
col.markdown(
f"""
<div style="margin-right: {0}px; text-align: center;">
<img src="data:image/jpeg;base64,{img}" width="{250}px;margin-right: {50}px; ">
<p style="font-size: 20px;">₹{price} Lakhs</p>
</div>
""",
unsafe_allow_html=True,
)最后,我们将读取上传的图像作为输入,将其转换为NumPy数组,并将其作为输入提供给image_to_similar_index我们之前定义的函数,该函数将返回与输入最相似的图像的索引。
然后,我们将检索与返回的索引相对应的图像和价格,并将它们提供给函数display_images_with_padding_and_price,该函数将格式化图像并将其显示在网页上。
if uploaded_file is not None:
car_image = Image.open(uploaded_file)
img_array = np.array(car_image)
st.image(car_image, captinotallow='Uploaded Car Image', use_column_width=False, width=300)
results = image_to_similar_index(img_array)
if os.path.exists("cars_imgs"):
car_images = [os.path.join(car_images_dir, img) for img in os.listdir(car_images_dir) if img.endswith(('jpg', 'jpeg', 'png'))]
print(car_images)
else:
st.error(f"Directory {car_images_dir} does not exist")
car_images = []
if len(car_images) < 4:
st.error("Not enough car images in the local storage")
else:
car_imagess = []
for i in results:
car_imagess.append(car_images[i])
car_prices = [cars_cost_list[a] for a in results]
car_images_pil = []
for img_path in car_imagess:
try:
img = Image.open(img_path)
buffered = BytesIO()
img.save(buffered, format="JPEG")
img_str = base64.b64encode(buffered.getvalue()).decode()
car_images_pil.append(img_str)
except Exception as e:
st.error(f"Error processing image {img_path}: {e}")
if car_images_pil:
st.subheader('Similar Cars with Prices')
display_images_with_padding_and_price(car_images_pil, car_prices, width=200, padding=10, gap=20)最终输出
将图片上传到网页后,ImageBind模型会开始加载,这可能需要一点时间。但是,一旦模型完全加载,图片就会转换为嵌入,并与其他图片进行比较,以找出最相似的图片。随后,相似的图片就会显示在网页上。天皓智联 开发板商城 视觉等相关设备
完整代码:
https://github.com/vansh-khaneja/Car-Similarity-Search三、 计算回形针方向
Halcon中有一个计算回形针方向的实例clip.hdev,可以在例程中找到。原图如下:
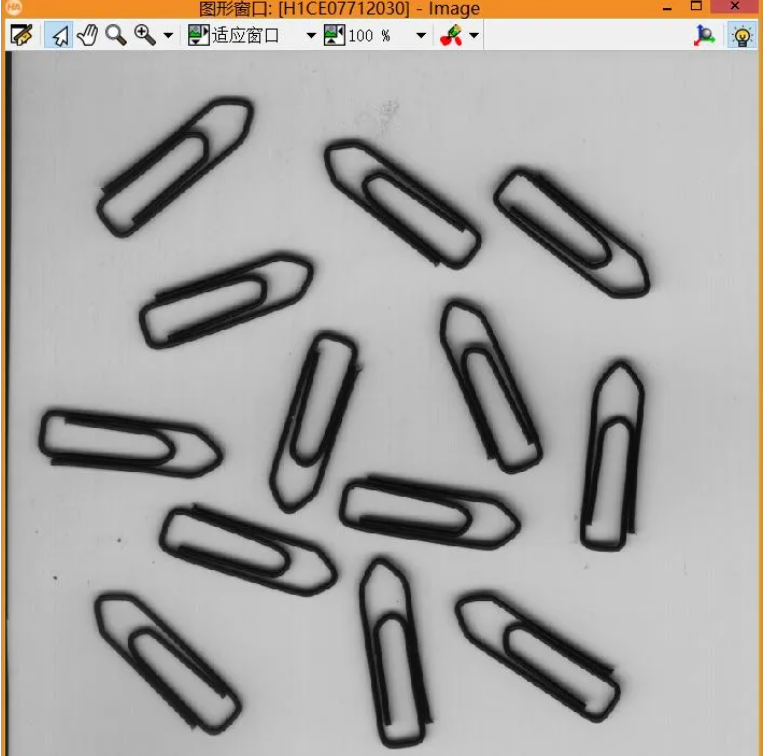
处理后的结果图:

代码整理之后,核心部分如下:
dev_close_window ()
dev_open_window (0, 0, 700, 700, 'black', WindowHandle)
dev_clear_window ()
dev_set_color ('green')
read_image(Image, 'clip')
threshold(Image, Region, 0, 56)
connection(Region, ConnectedRegions)
select_shape (ConnectedRegions, SelectedRegions, 'area', 'and', 3161.4, 6315.4)
orientation_region(SelectedRegions, Phi)
area_center(SelectedRegions, Area, Row, Column)
query_font (WindowHandle, Font)
*FontWithSize := Font[0]+'-18'
*set_font(WindowHandle, FontWithSize)
set_display_font (WindowHandle, 15, 'mono', 'true', 'true')
Length := 80
for index := 0 to |Phi|-1 by 1
set_tposition(WindowHandle, Row[index], Column[index])
dev_set_color ('black')
write_string(WindowHandle, deg(Phi[index])$'3.1f' + 'deg')
dev_set_color ('blue')
dev_set_line_width(3)
disp_arrow(WindowHandle, Row[index], Column[index],Row[index]-Length*sin(Phi[index]), Column[index]+Length*cos(Phi[index]), 4)
endfor思路步骤:
① 读取图像
② 二值化
③ 根据面积剔除非回形针的region
④ 计算每个region的方向和中心
⑤ 结果输出
转到OpenCV时,主要有几个小问题需要理清:
① 轮廓的方向怎么计算?直线拟合?还是计算轮廓中心和回形针端点来算角度?
② 回形针的端点坐标如何计算?
③ 绘制箭头?
如下是OpenCV实现的部分代码和效果图 :
void drawArrow(cv::Mat& img, cv::Point pStart, cv::Point pEnd, int len, int alpha, cv::Scalar& color, int thickness, int lineType)
{
//const double PI = 3.1415926;
Point arrow;
//计算 θ 角(最简单的一种情况在下面图示中已经展示,关键在于 atan2 函数,详情见下面)
double angle = atan2((double)(pStart.y - pEnd.y), (double)(pStart.x - pEnd.x));
line(img, pStart, pEnd, color, thickness, lineType);
//计算箭角边的另一端的端点位置(上面的还是下面的要看箭头的指向,也就是pStart和pEnd的位置)
arrow.x = pEnd.x + len * cos(angle + PI * alpha / 180);
arrow.y = pEnd.y + len * sin(angle + PI * alpha / 180);
line(img, pEnd, arrow, color, thickness, lineType);
arrow.x = pEnd.x + len * cos(angle - PI * alpha / 180);
arrow.y = pEnd.y + len * sin(angle - PI * alpha / 180);
line(img, pEnd, arrow, color, thickness, lineType);
}
double CalLineAngle(Point &ptStart, Point &ptEnd)
{
double angle = 0.0;
if (ptStart.x == ptEnd.x)
angle = 90;
else if (ptStart.y == ptEnd.y)
angle = 0;
else
{
angle = atan(double(ptEnd.y - ptStart.y) / (ptEnd.x - ptStart.x)) * (180 / PI);
if (angle < 0)
angle = abs(angle);
else if (angle > 0)
angle = 180 - angle;
if (ptEnd.y - ptStart.y > 0 && ptEnd.x - ptStart.x)
angle = angle - 180;
}
return angle;
}
int main()
{
Mat img = imread("./clip.png");
if (img.empty())
{
cout << "Read image error, please check again!" << endl;
return 1;
}
imshow("src", img);
Mat gray;
cvtColor(img, gray, CV_BGR2GRAY);
threshold(gray, gray, 85, 255, CV_THRESH_BINARY_INV); //二值化
imshow("threshold", gray);
vector<vector<Point>> contours;
vector<Vec4i> hierarcy;
findContours(gray, contours, hierarcy, CV_RETR_EXTERNAL, CV_CHAIN_APPROX_NONE);
cout << "num=" << contours.size() << endl;
vector<Rect> boundRect(contours.size()); //定义外接矩形集合
vector<RotatedRect> box(contours.size()); //定义最小外接矩形集合
Point2f rect[4];
for (int i = 0; i<contours.size(); i++)
{
box[i] = minAreaRect(Mat(contours[i])); //计算每个轮廓最小外接矩形
//boundRect[i] = boundingRect(Mat(contours[i]));
if (box[i].size.width < 50 || box[i].size.height < 50)
continue;
......
}二值化效果:

结果图:

四、 基于轻量化重构网络~表面缺陷视觉检测
基于深度学习的方法在某些工业产品的表面缺陷识别和分类方面表现出优异的性能, 然而大多数工业产品缺陷样本稀缺, 而且特征差异大, 导致这类需要大量缺陷样本训练的检测方法难以适用. 提出一种基于重构网络的无监督缺陷检测算法, 仅使用容易大量获得的无缺陷样本数据实现对异常缺陷的检测. 提出的算法包括两个阶段: 图像重构网络训练阶段和表面缺陷区域检测阶段. 训练阶段通过一种轻量化结构的全卷积自编码器设计重构网络, 仅使用少量正常样本进行训练, 使得重构网络能够生成无缺陷重构图像, 进一步提出一种结合结构性损失和L1损失的函数作为重构网络的损失函数, 解决自编码器检测算法对不规则纹理表面缺陷检测效果较差的问题; 缺陷检测阶段以重构图像与待测图像的残差作为缺陷的可能区域, 通过常规图像操作即可实现缺陷的定位. 对所提出的重构网络的无监督缺陷检测算法的网络结构、训练像素块大小、损失函数系数等影响因素进行了详细的实验分析, 并在多个缺陷图像样本集上与其他同类算法做了对比, 结果表明重构网络的无监督缺陷检测算法有较强的鲁棒性和准确性. 由于重构网络的无监督缺陷检测算法的轻量化结构, 检测1024 × 1024像素图像仅仅耗时2.82 ms, 适合工业在线检测.
关键词
缺陷检测 / 深度学习 / 小样本 / 全卷积自编码器 / 损失函数
传统的机器学习方法可以有效解决多种工业产品质量检测问题, 比如轴承1、手机屏2、卷材3、钢轨4、钢梁5等, 这类方法通过人为设计特征提取器来适应特定产品图像样本数据集, 将特征输入分类器和支持向量机6、神经网络7来判别产品是否有缺陷. 但当被检测产品的表面缺陷出现诸如复杂背景纹理(包括规则的和非规则的)、缺陷特征尺度变化大、缺陷区域特征和背景特征相似等问题时(如图1所示), 传统的机器学习方法依赖人工特征对产品图像样本的表示能力, 不适应这类复杂的检测需求. 图1(a)为暗缺陷, 图1(b)为明缺陷. 图1(c) 为覆盖图像的大尺度缺陷. 图1(d)为微小缺陷. 图1(e)为色差小的缺陷. 图1(f) ~ (g)为与纹理相似的缺陷. 图1(h)为模糊缺陷.
图 1 各种表面缺陷
Fig. 1 Various surface defects
自从AlexNet8被提出后, 以卷积神经网络(Convolutional neural network, CNN)为基础的深度学习方法成为表面缺陷检测领域的主流方法9-12. 卷积神经网络不仅可以自动学习图像特征, 而且通过多个卷积层的叠加, 可以抽取更抽象的图像特征, 相对人工设计的特征提取算法具有更好的特征表示能力. 根据网络输出的结果, 以深度学习方法做缺陷检测的算法可以分为缺陷分类方法、缺陷识别方法和缺陷分割方法.
基于缺陷分类的算法通常使用一些经典的分类网络算法对待检测样本进行训练, 学习后的模型可以对缺陷和非缺陷类别进行分类. Wang等13提出使用2个CNN网络对6类图像进行缺陷检测; Xu等14提出一种融合视觉几何(Visual geometry group, VGG) 和残差网络的CNN分类网络, 用来检测和分类轧辊的表面缺陷; Paolo等15和Weimer等16亦借助CNN的图像特征表示能力来判别缺陷. 这类方法通常不涉及缺陷区域的定位.
为了实现对缺陷区域的准确定位, 一些研究者将计算机视觉目标识别任务中表现优异的网络改进并应用于表面缺陷检测, 这类算法多基于区域卷积神经网络17、单激发多盒探测器18、一眼识别(You only look once, YOLO)19等网络. Chen等20将深度卷积神经网络应用于紧固件缺陷检测. Cha等21在建筑领域中使用区域卷积神经网络(Region-CNN, R-CNN)做结构视觉检测.
为了实现像素级检测精度, 一些研究者使用了分割网络, 例如Huang等22用U型网络(U-Net)构建的检测网络将缺陷检测任务转化为语义分割任务, 提高了磁瓦表面检测的准确率. Qiu等23采用全卷积网络(Full convolutional network, FCN)对缺陷区域进行检测.
这类方法都依赖一定数量的训练数据. 在许多工业场合中, 产品缺陷类型是不可预测的, 并且只发生在生产过程中, 很难收集到大量的缺陷样本. 针对这些问题, 研究者开始关注小样本或无监督学习方法, 如Yu等24利用YOLO V3网络在少量缺陷样本训练条件下, 实现较高准确率的检测结果. 在自编码器基础上进行改进的多种方法被用到表面缺陷检测, 例如卷积自编码器(Convolutional autoencoder, CAE)25, 基于Fisher准则的堆叠式降噪自编码器26, 鲁棒自编码器27, 融合梯度差信息的稀疏去噪自编码网络28等. Mei等29提出多尺度卷积去噪自编码器网络(Multi-scale convolutional denoising autoencoder network, MSCDAE)重构图像, 利用重构残差生成检测结果, 相比较于传统的无监督算法如纯相位变换(Phase only transform, PHOT)30、离散余弦变换31, MSCDAE在模型评价指标上有较大的提升. Yang等32在MSCDAE基础上使用特征聚类提升了纹理背景的重构精度. 以上重构网络均采用加入正则项的均方误差(Mean square error, MSE)损失函数, 数据样本多为规则表面纹理.
除自编码器外, 生成对抗网络33也应用于无监督缺陷检测. 生成对抗网络通过学习大量正常图像样本, 让网络中的生成器能够学习出正常样本图像的数据分布. Zhao等34结合生成对抗网络和自编码器, 对无缺陷样本制作缺陷, 训练生成对抗网络使之具有恢复图像的能力. He等35使用半监督生成对抗网络和自编码器训练未标记的钢材表面缺陷数据, 抽取图像细粒度特征并进行分类. Schlegl等36提出异常检测生成对抗网络网络解决无监督条件下的病变图像的异常检测. 在实际应用中, 生成对抗网络亦存在性能不稳定、难以训练等问题37.
考虑到工业应用场景缺陷样本的复杂性和稀缺性, 本文提出一种基于重构网络的缺陷检测方法(Reconstituted network detection, ReNet-D), 该方法以少量无缺陷样本作为网络模型学习的对象, 对样本图像进行重构训练, 使得网络具备对正样本的重构能力, 当输入异常样本时, 训练后的网络模型可以检测出样本图像的异常区域. 本文对ReNet-D方法的网络结构、训练块大小、损失函数系数等影响因素进行详细的实验分析和评价, 以同时适应规则纹理和不规则纹理的检测需求, 并与其他经典算法进行对比实验.
1. ReNet-D方法
在实际的工业应用中, 存在缺陷样本稀缺、特征差异大和未知缺陷偶然出现等因素, 导致以大量数据样本驱动的监督算法难以适用. 本文提出的无监督算法, 解决缺少缺陷样本数据可供模型学习的问题. 算法分为图像重构网络训练阶段和表面缺陷区域检测阶段2个训练阶段. 通过全卷积自编码器设计重构网络, 仅使用少量正常样本进行训练, 使得重构网络能够生成无缺陷重构图像; 缺陷检测阶段以重构图像与待测图像的残差作为缺陷的可能区域, 通过常规图像操作获得最终检测结果. ReNet-D算法模型如图2所示.

图 2 ReNet-D算法模型
Fig. 2 ReNet-D algorithm model
1.1 重构网络
工业产品表面缺陷存在多尺度、与背景纹理相似、形状复杂等特性, 对检测算法的准确率和运行耗时要求较高. 因此重构网络设计有3个要求: 1)网络能够适应不同尺度大小的缺陷区域; 2)网络需要辨识出样本区域是否存在缺陷特征; 3)重构网络模型的参数量尽可能少.
重构过程通常分解为编码变换φ 和解码变换 γ, 定义如下:
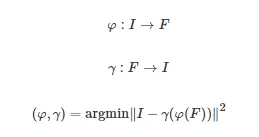
(1)
式中, I∈RW×H表示图像样本的空间域, 通过函数φ 映射到隐层空间, F表示隐层空间中对应的图像样本特征, 函数φ 由编码模块实现. 函数γ 将隐层空间对应的图像样本特征F再映射回原图像样本的空间域, 该函数由解码模块实现.
令z = φ (I) ∈ F, 编码和解码过程分别描述为:
式中, I'表示重构图像, ∘ 表示卷积, σ表示激活函数, W和W'分别表示编码卷积核和解码卷积核, b和b'分别表示编码偏差和解码偏差.
ReNet-D的网络结构如图3所示, 为适应较大图像, 将原图划分成若干图像块, 通常大小为16 × 16、32 × 32和64 × 64作为网络的输入. ReNet-D利用1 × 1、3 × 3和5 × 5三种卷积核来获得多尺度特征, 并将多尺度特征输入编码模块, 解码模块输出的结果再输入3个不同尺度的反卷积层, 获得最终的重构图像, 相比于MSCDAE29的高斯金字塔采样模型, 同样可以得到多尺度特征, 但降低了计算成本. ReNet-D的CAE模块包含4个卷积模块和4个反卷积模块. 每一个卷积模块包含一个卷积层、一个批标准化(Batch normalization, BN)层38和非线性激活层, 前3个卷积模块还包含能够改变图像尺度的池化层. 激活函数采用Relu. 前3个卷积层使用5 × 5卷积核, 最后一层使用3 × 3卷积核.
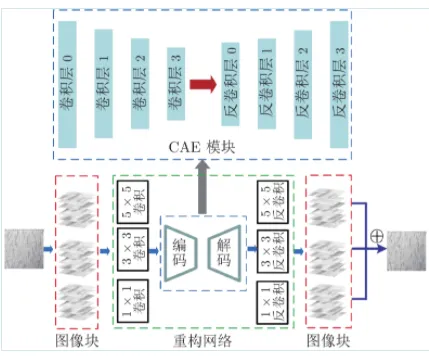
图 3 ReNet-D网络结构
Fig. 3 ReNet-D network structure
自编码器用于缺陷检测的机理在于: 基于对无缺陷背景的高敏感性完成对无缺陷背景的重建, 以及对有缺陷区域的低敏感性完成不完善的重建, 以此实现对缺陷的检测. 自编码器是一个输入和学习目标相同的神经网络, 网络层次的深浅也决定了自编码器对输入图像的复现能力, 若采用网络结构复杂的模型, 可以提高对样本特征复现能力, 但是同时也造成了对于缺陷区域复现能力的提高, 进行残差操作时, 会导致因缺陷部位差异不够明显而检测失败. ReNet-D采用轻量化的结构设计, 轻量的模型重建能力有限, 但通过多尺度特征和损失函数的设计, 既能使网络能充分学习到正常纹理的特征, 又能对缺陷区域不完善的重建获取缺陷部位的信息.
1.2 损失函数
在ReNet-D的训练阶段, 以原始图像和重构图像之间的重构误差作为损失函数, 促进网络收敛. 以下分析并改进现有的评估重构误差的损失函数.
1)均方误差损失
均方误差损失是评估算法模型的重构图像和原图之间差异的常用损失函数, 定义为L2:

(3)
式中, Isrc表示输入的原图, Irec表示模型重构的图像, ω表示重构网络中的权重矩阵集, λ 表示正则化项的惩罚因子, 0<λ<1 . 以MSE为损失函数的重构算法模型适用于规则纹理背景的图像样本, 比如纺织品29, 32.
2)平均绝对误差损失
大多数工业产品的纹理背景并不规则, 异常特征易融入纹理背景, 且异常特征和正常纹理背景特征差异较小. 定义L1为平均绝对误差损失:
与L1损失相比, L2损失对异常值更敏感, 会过度惩罚较大的损失误差, 如MSCDAE29方法, 因而ReNet-D引入L1损失来优化网络训练.
3)结构损失
在评价重构网络模型的效果时, L1损失和L2损失采用逐像素比较差异方式, 并没有考虑图像的区域结构等特征. 对于一些非规则纹理图像样本的检测, ReNet-D引入结构相似性因子(Structural similarity index, SSIM)39-40构建损失函数, 使网络能适用复杂多变的纹理背景样本, 重构出更好的效果. SSIM 损失函数从亮度、对比度和结构3个指标对模型进行优化41, 结果比L1或L2损失函数更能反映图像细节. 对于模型输入和输出的图像对(x,y)(x,y), SSIM定义为:

(5)
式中, α > 0, β > 0, γ > 0, l(x, y)表示亮度比较, c(x, y)表示对比度比较, s(x, y)表示结构比较. μx和μy分别是x 和y 的平均值, σx 和σy 是x和y的标准差. σxy 是x和y的协方差. C1、C2、C3是非0常数, 通常α=β=γ = 1, C3 = C2/2.
SSIM的损失函数定义为:

(6)
重构网络用SSIM损失函数评价最后一层的输出结果和原图的差异, 还可以抽取多个不同尺度的反卷积层结果与对应的卷积层结果同时使用SSIM损失函数, 从而构建多尺度SSIM42 (Multi-scale SSIM, MS_SSIM). 对于M个尺度, MS_SSIM损失函数定义为:

(7)
4) ReNet-D使用的损失函数
L1损失与MSE损失相比, 对像素级误差的惩罚更弱, 适合不规则纹理样本, 而LSSIMLSSIM可以训练重构网络去关注样本图像的亮度改变和颜色偏差, 从而保留图像的高频信息即图像边缘和细节. 为同时解决规则和无规则纹理图像样本缺陷的检测问题, 本文设计L1损失和LSSIMLSSIM结合的损失函数作为ReNet-D网络模型的损失函数, 如下:
式中, α 是权重因子, 取值范围为(0, 1), 用来平衡L1损失和LSSIM 的比重, 本文将通过实验比较不同权重因子和损失函数对ReNet-D检测结果的影响.
1.3 缺陷区域定位
在检测阶段, 缺陷图像输入训练好的重构网络后, 网络会输出近似无缺陷图像, 即重构网络将有缺陷的区域"修复"成正常区域, 而保持无缺陷的区域, 根据这一特性, 对输出图像与输入图像的像素级差异, 经过常规图像处理技术, 便能精确的定位缺陷区域, 处理流程如下:
1)残差图获取
将输入图像(如图4(a)所示)与ReNet-D重构图像(如图4(b)所示)利用式(9)做差影, 得到重构网络对缺陷区域的重构误差, 获得的残差图如图4(c)所示, 图中包含了异常区域的位置信息. 其中, 图4(a) 为输入模型的原图, 图4(b)为ReNet-D重构图, 图4(c) 为由式(9)得到的残差图vv, (i,j)(i,j)为像素位置. 图4(d)为残差图滤波, 图4(e)为缺陷定位.
图 4 残差图处理流程
Fig. 4 The residual graph processing flow location

(9)
2)去噪处理
残差图图4(c)呈现出很多噪点, 形成伪缺陷, 影响对真实缺陷区域的判断, 使用均值滤波做去噪处理得到图4(d).
3)阈值化分割与缺陷定位
4)使用自适应阈值法得到最终结果图4(e).
2. 实验
本文对提出的检测算法ReNet-D在工业产品的表面数据上进行广泛的评价. 首先介绍实验所用的数据集, 其次介绍模型评估的关键指标, 然后通过对ReNet-D算法检测效果的影响因素包括损失函数、网络结构、图像块, 以及对于同类材料的不同类型缺陷的检测效果等方面做了详细的实验分析. 最后, 对提出的检测算法和其他同类无监督算法做比较.
2.1 数据集介绍
为了客观评估所提出的检测算法, 本实验建立了由多种材料的纹理样本组成的验证数据集, 如图5所示, 其中图5(a)来源于AITEX43数据集, 该数据集来源于纺织业, 样本为规则纹理, 正负样本数149/5, 图5(b) ~ (e)样本来源于DAGM200744数据集, 该数据集有纹理不规则和缺陷区域与图片尺度对比大两个特点, 缺陷隐藏在纹理中并且结构与纹理很相似, 其中图5(b)的正负样本数100/29, 图5(c)的正负样本数100/6, 图5(d)的正负样本数101/6. 图5(f)样本来源于Kylberg Sintorn数据集45, 正负样本数50/5. 除图5所示的数据集外, 还增加了MVtech无监督数据集37的样本做比较实验.

图 5 实验采用的表面缺陷数据集
Fig. 5 Surface defect data set used in the experiment
2.2 模型评价指标
本文通过像素级度量来评估算法的性能, 采用了3个评价指标: 召回率(Recall)、精确率(Precision)和二者的加权调和平均(F1-Measure), 定义如下:

(10)
式中, TPp为前景中分割正确的缺陷区域比例, FPp为背景中分割错误的缺陷区域比例, FNp表示缺陷区域中未检测到的缺陷区域的比例. F1-Measure评估召回率和精确率. 所有测试都在一台配备图形处理器的计算机上进行的, 具体配置如表1所示.

表 1 计算机系统配置
2.3损失函数对比实验
ReNet-D分别选取损失函数MSE、L1、SSIM以及三者的组合做对比实验, 以评估式(8)所提出的损失函数在缺陷检测任务中的性能. 该实验中, ReNet-D网络参数设置如表2所示.

表 2 默认网络参数
图6(a)和图6(b)是两类不同的产品表面缺陷样本在多种损失函数下的实验结果, 其中图6(a)为不规则纹理样本, 图6(b) 规则纹理样本; 图6(c)为样本(a)在不同损失函数下的收敛测试, 图6(d)为样本(b)在不同损失函数下的收敛测试; 图6(a)采用不规则表面纹理的缺陷图像样本. 从残差结果对比可以看出, MSE作为算法损失函数得到的残差结果除真实缺陷区域外, 其他区域噪声点较多, 形成伪缺陷; 而单独使用SSIM作为损失函数, 检测出的缺陷区域略小于真实缺陷区域; 相比于其他损失函数, 结构损失函数SSIM和L1损失函数的组合获得了较好的效果.

图 6 不同损失函数下ReNet-D的检测结果
Fig. 6 ReNet-D detection results under different loss functions
图6(b)采用规则表面纹理的缺陷图像样本, 从残差结果对比可以看出, 使用MSE损失函数得到的缺陷区域的完整性较差, 与MSE + SSIM组合的检测结果相似. 结构损失函数SSIM和L1损失函数的组合获得了较好的效果, 而且检测结果与仅使用L1损失函数相似. 图6(c)和图6(d)为不同损失函数下ReNet-D的收敛趋势比较.
从表3中对比结果可以看出, 对图6(a)中的不规则表面纹理的缺陷样本, 结构损失函数SSIM和L1损失函数的组合在召回率以及加权调和平均获得了较好的效果, 在精确率上略次于损失函数SSIM; 对图6(b)所示的规则表面纹理的缺陷样本, 仅使用L1损失函数达到的召回率最高, SSIM和L1损失函数的组合其次; 仅使用结构损失函数SSIM达到的精确率最高, SSIM和L1损失函数的组合略次之; 对于加权调和平均, L1损失函数表现最好.

表 3 不同损失函数下检测结果的比较
进一步地, 通过对本研究采用的样本库的检测效果对比, 损失函数有如下规律:
- 对于规则表面纹理样本, 采用以上4种损失函数都能检出缺陷, 其中仅用MSE和MSE + SSIM损失函数的结果相对较差, 其他两种损失函数结果差别细微.
- 对于不规则表面纹理样本, 采用L1 + SSIM的组合损失函数获得的检测结果较好.
2.4 损失函数在不同权重系数下的对比实验
上述实验表明, ReNet-D模型使用L1 + SSIM组合损失函数, 能同时适用规则和不规则表面纹理的缺陷检测. 对于规则纹理样本, 仅使用L1损失, 即权重系数α=1 , 便可得到较理想的检测结果; 而对于非规则纹理样本, 不同权重系数会产生不同的检测效果. 本实验使用图6(a)中不规则纹理样本, 权重系数α 的范围从0到1, 步长设为0.1, 用于调节SSIM损失和L1损失的比重, 对比实验如图7所示, 其中图7(a)为残差热力图对比. 图7(b)为训练损失曲线比较.

图 7 不同权重系数下ReNet-D性能比较
Fig. 7 Comparison of ReNet-D performances under different weight coefficients
根据式(8), 当α 增大时, 结构性损失SSIM影响逐步减小, 由图7和表4可以看出, 残差图发生明显变化, 其中当α = 0.15时, 缺陷检测效果较好, 信噪比最低, 召回率和加权调和平均表现最好. 通过多个样本的实验, 本文给出的经验建议是: 对于规则纹理样本, 设置权重α = 1, 即只用L1损失作为训练模型的损失函数; 对于不规则纹理样本, 设置α = 0.15, 使结构损失影响权重偏大, 以获得最佳的结果.
表 4 不同权重系数下的检测结果比较
2.5 网络层结构对比实验
网络层的深度和类型影响重构网络的训练结果, 本研究将ReNet-D的特征提取网络CAE与经典网络如FCN46, U-Net47做对比实验, 实验结果如图8所示.

图 8 不同特征提取网络下ReNet-D的残差图对比
基于CAE网络的缺陷检测任务不同于其他低层像素视觉任务如图像超分和降噪, 降噪一般要求很深的网络如FCN和U-Net, 然而这类网络特征提取能力很强, 容易将缺陷区域仍重建为缺陷区域, 导致重构图和原图的残差几乎等于0, 无法检测缺陷. 采用轻量化结构设计重构网络时, 既能充分学习到正样本的纹理特征, 又能将缺陷区域重构为近似正常纹理, 形成明显的重构误差. 因此, ReNet-D无须过多的网络层数, 也无须使用构建网络的技巧, 比如全局残差学习48、亚像素层49、残差连接50.
2.6 图像块尺寸对比实验
输入图像的尺寸通常会对重建结果有较大影响. 在ReNet-D网络的训练阶段, 考虑到处理器的内存和处理速度, 将较大的图像训练样本划分为若干图像块, 本实验中, 图像块尺寸分别设置为16 × 16像素, 32 × 32像素, 64 × 64像素, 图9给出3种不同图像块大小下的检测结果, 其中图9(a)为不规则纹理样本, 图9(b)为规则纹理样本, 图9(c)为不规则纹理收敛趋势比较, 图9(d)为规则纹理收敛趋势比较.

图 9 不同图像块下ReNet-D的残差图和检测结果对比
对于如图9(a)所示的不规则背景纹理图像, 样本尺寸为512××512, 当图像块尺寸等于16××16时, 虽然缺陷区域检测效果较好, 但会产非缺陷噪点, 此时的召回率最好, 但精确率最低; 当图像块尺寸较大时取64××64时, 缺陷区域的有效检出尺寸变小, 缺陷检测的精确率会降低.
对于如图9(b)所示的规则背景纹理图像, 样本尺寸为256 × 256, 当图像块尺寸等于16 × 16时, 缺陷区域呈现块状化, 与理想收敛效果差别较大, 此时的召回率最高, 但是准确率很低; 而当图像块尺寸等于64 × 64时, 检测结果出现明显漏检现象, 检测的精确率下降.
如表5所示, 当图像块尺寸设置为32 × 32时,对于图9(a)和图9(b)对应的2种不同种类背景纹理的图像精确率与加权调和平均达到最高. 进一步地, 对数据集中多种规则和不规则纹理缺陷样本, 图像尺寸从256 × 256到1024 × 1024, 经测试, ReNet-D的图像块尺寸设置为32 × 32时检测结果最好.

表 5 不同尺寸像素块的检测结果比较
2.7 同种材料不同种类缺陷的检测实验
无监督数据集37中的表面纹理缺陷类包括皮革、木材、地毯、网格和瓷砖, 其中瓷砖类纹理最为杂乱, 其训练集包括了230张无缺陷的不规则纹理正常类型图像; 测试集包括了5类缺陷, 其中有17张破损类缺陷, 18张胶带类缺陷, 16张灰色涂抹类缺陷, 18张油污类缺陷, 15张磨痕类缺陷. 本文实验采用默认的网络参数对Tile数据集进行了训练, 并得到了5类缺陷的检测结果如图10所示.
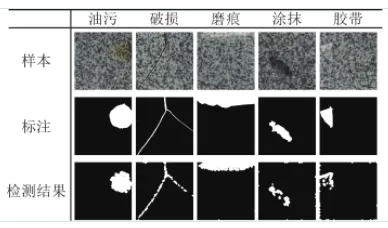
图 10 无监督样本的测试结果
如表6所示, ReNet-D方法能适应在Tile数据集中的不同种类的缺陷的检测, 其中油污、破损与磨痕类缺陷表现较好, 其检测精确率与召回率与加权调和平均较好, 但在检测涂抹和胶带类缺陷时, 能检出颜色及纹理与背景有差异的缺陷区域, 但生成的缺陷总体形状与理想检测结果有差异, 导致像素级的评价指标较低.
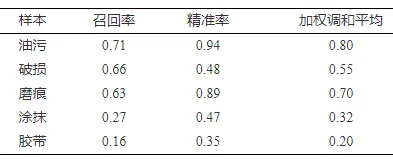
表 6 无监督样本的测试结果
ReNet-D的特性在于, 网络对于与背景相似的成分有较好的重建效果, 与背景不相似的成分则重建效果较差, 从而利用这种特性来检出与背景有差异的缺陷. 对涂抹与胶带缺陷的特征分析发现, 缺陷局部区域的颜色与纹理和背景非常接近, 甚至与之重合, 后果是这类区域重建效果较好, 造成了差影不明显, 但缺陷局部与背景差异较明显区域的检测效果则不受影响. 虽然在召回率等指标上不甚理想, 但在工业检测中, 局部检出可视为缺陷检出.
2.8 相关算法结果对比
本实验将ReNet-D方法的性能与传统无监督方法(曲率低通滤波分析(Low pass filtering with curvature analysis, LCA)51、PHOT30)和基于自编码方法的无监督方法(MSCDAE)29进行了比较, MSCDAE由文献32已证明性能优于其他自编码方法, 如异常检测自编码器9、鲁棒自编码器27. 实验采用了6类纹理样本, 包含1类规则纹理和5类不规则纹理, 每类纹理使用50张无缺陷样本进行训练, 并在相同数量的缺陷图像样本上进行测试. ReNet-D的网络参数对6类样本基本一样, 差别仅在损失函数的权重系数, 规则纹理取α=1 ; 非规则纹理取α=0.15 . 检测结果如图11所示.
6类样本在图11中按列从左到右依次为图11(a) ~ (f), 图11第1行是待测样本图像, 第2行是理想检测结果.

图 11 多种算法测试效果对比
如图11所示, LCA51方法能消除代表背景的高频部分, 同时保留代表缺陷的低频部分, 在简单纹理上获得了良好的检测效果, 如样本图11(a)和图11(f). 但LCA方法不适合检测频域较复杂的不规则纹理, 如样本图11(b) ~ (d).
对于PHOT30方法, 只有样本图11(b)检测的效果较好, 其他样本中和缺陷区域相似背景区域被当做噪点处理.
MSCDAE29方法能检测图11中所有样本的缺陷区域, 但是同时也把部分无缺陷区域当成疑似缺陷检出, 如样本图11(a) ~ (d).
本文ReNet-D方法, 无论在大尺度缺陷样本图11(d), 小尺度缺陷样本图11(e)和图11(f), 以及复杂纹理样本图11(c)和不规则纹理样本图11(b), 在所有类型的缺陷和纹理上获得较好的检测结果.
此外, 召回率、精准率和加权调和平均3个指标用于定量分析以上4种方法的检测效果, 如表7所示.

表 7 不同算法的检测效果比较
由表7可以看出, 本文提出的ReNet-D算法模型的3个指标, 几乎在所有类型样本上均优于其他算法模型, 适合规则纹理和非规则纹理样本的检测. 仅在样本图11(b)上的召回率稍逊于MSCDAE方法, 但从检测结果来看, MSCDAE方法会同时检出非缺陷区域, 产生伪缺陷.
本文对算法效率进行了比较. 实验采用1024××1024像素样本图像, 在相同的计算性能下, 对4种方法的处理耗时进行比较, 如表8所示. ReNet-D算法模型经过训练后的大小不到1 MB字节, 检测耗时平均为2.82 ms, 可以满足工业实时检测的要求. 其他方法耗时较大, 限制了其实际应用.

表 8 处理耗时的比较 (ms)
3. 结束语
本文提出了一种利用重构网络进行表面缺陷视觉检测的方法ReNet-D, 该方法采用轻量化结构的全卷积自编码器设计重构网络, 在训练阶段, 仅采用无缺陷样本进行训练, 可以解决工业环境中缺陷样本获取困难的问题; 在检测阶段, 利用训练好的模型对输入的缺陷样本做重构, 并通过常规图像处理算法即可实现缺陷区域的精确检测. 本文讨论了无监督算法中网络结构、损失函数、图像块尺寸等因素对表面缺陷检测任务的影响, 并且提出结合L1损失和结构损失的组合损失函数用于表面缺陷检测, 以同时适应规则纹理和非规则纹理样本的检测问题. 本文在多类样本数据上对提出的ReNet-D方法和其他无监督算法做了对比实验, 结果证明本文所提出的检测算法取得了较好的效果, 并适合移植到工业检测环境. 由于网络的轻量化特性, ReNet-D对于一些与背景纹理相似且颜色接近的缺陷的重构性能较好, 导致差影结果不明显, 生成的缺陷区域与理想检测结果相比有差异, 可以从成像角度做适当改进, 使缺陷对比度较为明显, 进而达到更好的检测效果.
五、钢管表面缺陷检测
钢管作为原材料,广泛应用于如石油、化工、电力、船舶、汽车等行业。近年来,经济全球化发展使企业对产品质量提出更高要求,钢管表面存在缺陷会严重影响其使用寿命,同时在设备某些重要位,使用劣质钢管会存在安全隐患,严重威胁人员生命,对企业造成产财产损失。
因此,为了控制钢管质量,相关企业会对其进行质量检测,但检测措施通常由人工实现,无法实现快速、精准检测缺陷。
在钢管生产的过程中,++由于原材料、轧制设备和加工工艺等多方面的原因,将导致其表面出现划痕、 辊痕、氧化铁皮、表面夹杂、孔洞、裂纹、麻面等不同类型的缺陷。++这些缺陷不仅严重影响产品的外观,还降低了产品的抗腐蚀性、耐磨性和疲劳强度等性能,给企业的发展带来不良影响,同时也增添以钢管为原材料的下游产品使用过程中的安全隐患。
表面缺陷区域具有应力集中、受力薄弱的特点,同时性能突变、疲劳损伤和锈蚀往往集中在此区域, 使得钢管在复杂恶劣环境下的工作性能大大降低。通过对钢管表面存在的缺陷区域进行检测,及时发现缺陷,为生产工艺的调整、设备状态改进提供依据具有重要意义。
目前,钢管的表面缺陷的检测大多通过人工方式实现,人工方式依赖于现场经验且效率低,受现场环境的影响,劳动强度大,易产生漏检和误检现象,不能全面反应钢管表面的质量,检测实时性差,检测种类少,检测效率低,缺乏对产品的表面质量的综合评估。随着计算机水平的发展和人工智能领域的兴起,机器视觉技术得到广泛的应用,采用机器视觉方法能有效弥补人工检测不足,且检测精度高、能进一步为智能制造提供数据平台。
01 钢管表面缺陷检测特点
国内外利用机器视觉方法检测冶金产品的对象主要为板材、带钢、钢条等,这些产品表面较平整、粗糙度低、材料反射率一致,只要保证入射光照角度合理,强度分布均匀,无论使用面阵或线阵相机均能获取较为理想的被检测材料表面缺陷图像,这也有效降低了后续图像处理算法的复杂程度;
如图平面材料表面缺陷检测的光照分布示意图,通常采用单个或多个面阵相机即可获得理想的光照结果;而采用线阵光源则更容易实现,因为被照射区域各点到达光源中心的距离是相等的。

平面材料表面缺陷检测的光照分布示意图
对于钢管而言,因其几何结构特点,当采用面阵光源时,弧形外表面使得光源中心与被照射区域各处之间距离相差过大,如图所示,与光源最短距离位置处表现为较高亮度,而在最短距离位置两测,光照亮度分布减弱,图像成像结果也表现类似特点,中间区域像素灰度分布较高而两侧区域像素灰度值较小。
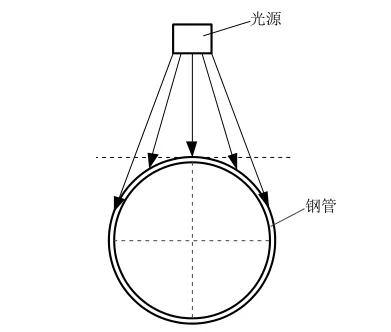
面阵光源光照分布(正视图)
另一情况如图所示,采用线阵相机和线阵光源实现钢管表面缺陷动态检测时,因振动、装配误差等因素,线阵光源中心线与线阵相机视野长度方向并非位于同一直线,相机视野方向通常与钢管回转中心所在直线一致;这种情况会降低照射区域与视野区域重合性,导致成像结果光照不均现象严重,进一步增加图像处理的困难度。

线阵光源光照分布(俯视图)
02 关键技术难点
钢管因其几何结构特点,易产生光照不均现象;为实现钢管圆弧表面动态实时检测,必然影响光源光照区域与相机视野的重合性,易造成光照分布不均,这种现象会覆盖掉缺陷区域的特征。当图像获取不理想时,会增加图像处理的难度。尽管相关学者在机器视觉检测领域已经作了很多工作,但国内对钢管的表面缺陷检测的研究较少, 主要存在如下难点:
**(1)**热轧无缝钢管与热轧带钢、重轨等类似,表面覆盖大量氧化铁皮,会导致各类伪缺陷的产生;
**(2)**钢管弧形外表面易产生光照不均现象;
**(3)**因光照不均的影响,缺陷灰度差异较大,使得漏检严重;
**(4)**受弯曲度、不圆度和表面凸起缺陷的影响,钢管在检测过程中产生振动,使得图像采集存在误差,特征不明显;
**(5)**实现动态检测时,光源照射区域与相机视野区域重合性会降低,进而造成光照分布不均。
03 成像光路设计
照明系统包括照明方式选择,相机与光源的位置关系确定。
钢管表面的照明方式可分为明场照明和暗场照明,本文选择明场照明方式,该方式有益于钢管表面缺陷和背景形成高对比度。由于采用单个线阵相机和线光源,其有效工作区为窄条,与其它冶金产品表面不同的是,热轧无缝钢管在成型过程中,因其工序工艺的特点,表面未经抛光处理,光照反射类型以漫反射为主。图为明场照明光路结构图。

根据图像采集原理,需要确定线阵相机、线光源等的位置,这有益于后续硬件选型中参数的确定。
为保证视野区域能够将不同长度的钢管表面覆盖,在光路设计中,使视野幅宽大于钢管长度。
04 硬件参数设计
(1)相机
线阵相机分为主要分为 CCD和CMOS两种类型。
由于工作原理,CCD 的表面上会因静电场存在导致表面吸吸附较多灰尘,这在实际工业检查中受到限制,而 CMOS 芯片内部集成性较高,对硬件设计的优化具有促进作用,具有图像捕捉灵活、灵敏度高、动态范围宽、分辨率高、低功耗及优良的系统集成等优点,同时在价格方面比 CCD 传感器更实惠。
基于图像采集方案, 设计检测精度要求为 0.5mm , 即能够检出最小缺陷尺寸为0.5mm*0.5mm, 视野幅宽H=300mm , 相机分辨率不能低于以下值:

(2)镜头
镜头与检测对象距离最近,其作用是将检测对象聚焦在相机光敏元件上,通常需要考虑镜头的相关参数,保证与相机的合理搭配,提高成像质量。镜头选型包括焦距、成像靶面尺寸等参数确定。
焦距为镜头重要参数,需由物距等因素确定,由成像原理可知焦距计算如下:

式中,s 为光敏芯片长度;H 是视野幅宽,即相机能拍摄到的视野范围;d 为物距。
(3) 光源
光源的合理选择能够对成像系统起到增益效果,例如提高对比度,降低无关信息对成像的干扰。根据钢管表面图像采集原理,需选择线阵光源实现照明,这样可保证在视野范围内,光照强度集中且均匀。
由于 LED 光源具有高效率、 低耗电量、 长寿命、 安全性高和可控性好等特点,本文以 LED 光源实现照明。
05 缺陷检测
钢管表面缺陷为凹坑、划伤、翘皮及辊痕 4 种缺陷,
图 (a)为凹坑缺陷, 其特征为点状或块状凹陷,因氧化皮或异物未清除在轧制过程中嵌入钢管表面再脱落形成;
图 (b)为翘皮缺陷,为附着在钢管外表面的金属层,在穿管深加工工序中,聚集夹杂物因管壁变薄而外漏,裂纹形成并延伸使表皮外翘;

图 (c)为划伤缺陷,钢管表面被外金属或硬物划削所致,通常呈细长尖锐沟纹或较浅凹坑;
图 (d)为辊痕缺陷,该缺陷是由于轧辊调整不当或表面损坏所造成, 呈周期性或连续性分布。

在提取钢管表面缺陷特征之前,需要确定那些特征是有效的,对于凹坑、翘皮、划伤和辊痕,需要选择具有良好区分度的特征构成特征向量;特征向量是缺陷特征数值化表征方式,特征提取通常遵循如下原则:
1) 图像中特征应该容易获取;
2) 所选择特征在数值上不受噪声和无关因素干扰;
3) 同种缺陷的特征具有紧致性, 不同种缺陷特征具有良好的区分度。
钢管表面缺陷分布和大小不具规律性,且形态复杂,因此需要选择能够准确描述缺陷的特征。
机器视觉技术将CCD相机拍摄到的目标图像实时转换成图像信号,然后将图像信号输入进嵌入式视觉图像处理系统。
根据图像饱和度、像素分布、目标图像边沿、亮度等信息转换成计算机识别的数字信号,利用先进的算法对图像进行特征识别,将特征识别出来的结果进行评价,输出最终的缺陷结果,包括缺陷、尺寸、角度、个数、合格与不合格、有无等,实现自动识别功能。

总而言之,钢管缺陷检测系统采用的机器视觉自动识别的要求,必须解决以下主要问题:
1.必须能在线检测钢管表面的瑕疵,如划痕、刮伤、孔洞、结疤、垫坑等表面异常。
2.能应对因钢管宽度、长度变化、以及钢管在移动过程中产生的扭曲或倾斜、表面有油污或水滴所造成的干扰。
3.瑕疵检测具备自学习、自适应功能适合于不同宽度、不同颜色、不同速度的要求,还必须应用模式识别、自动暴光、防抖动、瑕疵报警等功能,瑕疵检测和瑕疵报警是动态实时的。
4.必须具备精度高、故障点少等特点,需用工业级数字摄像机和工业级PC机相结合来完成系统任务。