工业安全无小事。当 YOLO 家族最新成员 YOLO11 遇上工地安全监管,效率与精准度如何起飞?本文带你从零实现新类别目标检测训练!
Github:github.com/ultralytics...

安全第一:为什么我们需要 AI 监工?
在施工现场或工业生产中,正确佩戴安全帽是保命的第一道防线。然而,传统的靠人眼盯着监控看,不仅费时费力,还极易产生视觉疲劳导致漏检。
随着 Ultralytics YOLO11 的重磅发布,计算机视觉技术在处理此类"高精度、高实时性"任务时展现出了惊人的能力。今天,我们就来一场实战:用 YOLO11 打造一套自动化安全帽佩戴检测系统。
认识新王者:YOLO11 强在哪里?
作为 YOLO 家族的最新一代(2024年下半年发布),YOLO11 并不是简单的版本号递增,它在架构上进行了深度优化。
核心优点
-
极致的参数效率: YOLO11m 在达到比 YOLOv8m 更高精度的同时,参数量减少了约 22%。这意味着它在边缘计算设备(如摄像头、边缘盒子)上跑得更欢。
-
架构革新: 通过采用改进的 backbone 和 neck 架构,显著提升了特征提取的深度和广度,尤其是对遮挡物体和小目标的捕捉更加精准。
-
全能选手: 原生支持检测、分割、姿态估计、旋转框和分类,一个 API 搞定所有任务。
潜在不足
-
社区积累: 相比于久经沙场的 YOLOv5/v8,YOLO11 属于新锐,相关的第三方插件和现成的预训练权重库还在快速补充中。
-
训练门槛: 虽然官方 API 极简,但要发挥最高效能,对显卡驱动(CUDA 12+)和环境配置有一定要求。
实战:从零训练安全帽检测模型
-
数据集准备,可下载 YOLO 官方提供的数据集 github.com/ultralytics...
也可以自己使用 Label-Studio 重新标注"佩戴安全帽(helmet)"和"未佩戴(head)"两类标签的数据。
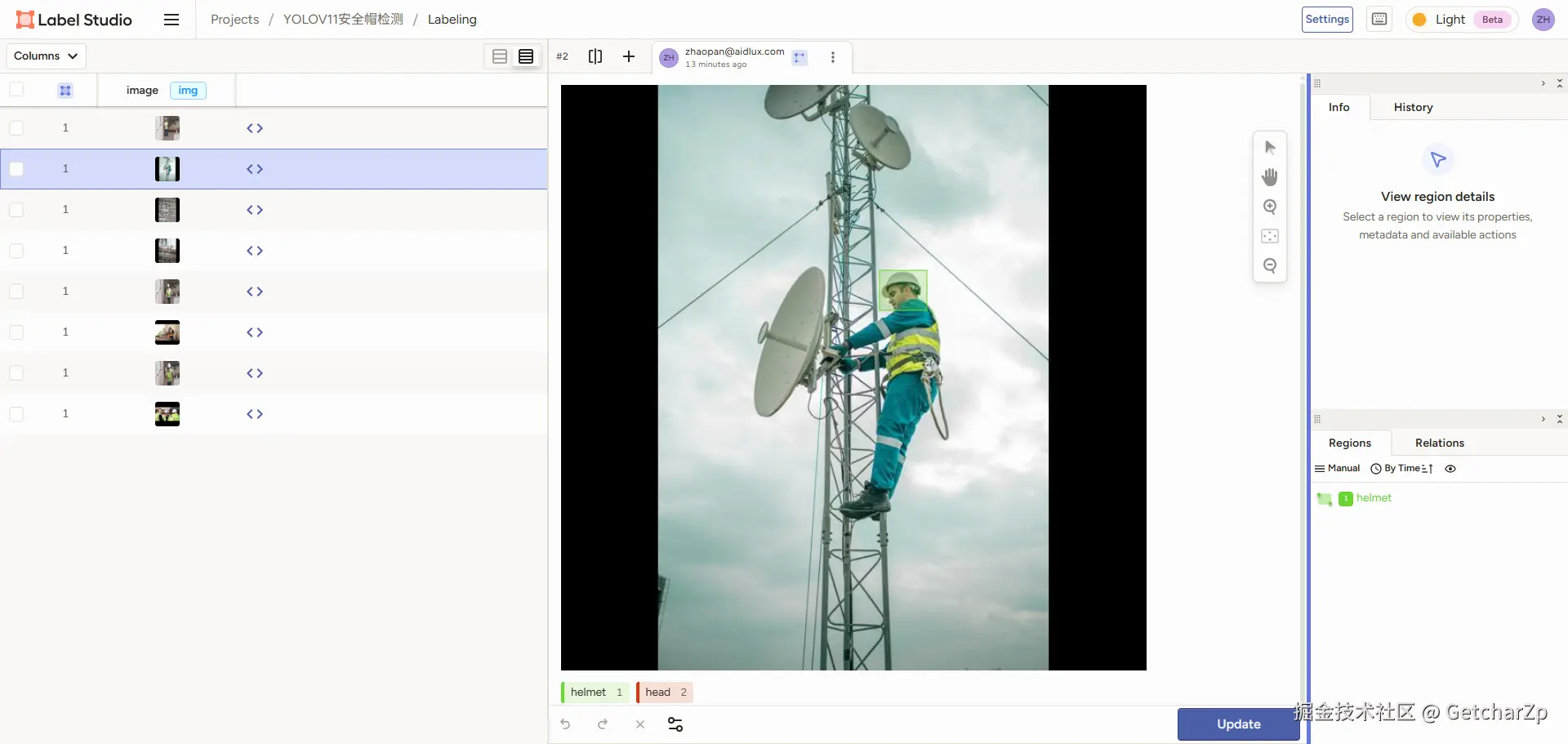
标注完成后,点击导出
YOLO with Images, 将能够导出 YOLO 格式(每张图片对应一个 .txt 标签,内容为:class_id x_center y_center width height,均为归一化数值)的数据。
目录结构:
bash
├─images
│ ├─test
│ ├─train # 训练集图片
│ └─val # 验证集图片
└─labels
├─test
├─train # 验证集标签
└─val # 验证集标签- 创建
helmet.yaml配置文件(PS:推荐用官方的construction-ppe.yaml进行快速验证)
在项目根目录新建该文件,告诉模型数据的路径和类别:
yaml
path: C:\Users\getcharzp\datasets\helmet_data # 数据根目录
train: images/train # 训练集图片
val: images/val # 验证集图片
test: images/test # 测试集图片
# Classes
names:
0: head
1: helmet- 模型训练
YOLO11 的 API 非常简洁,同时提供了相关的命令行,我们可以使用命令行快速进行模型的训练:
bash
# 安装 ultralytics
pip install -U ultralytics
# 模型训练
# 进入数据集根目录下,运行下述命令
yolo detect train data=helmet.yaml model=yolo11n.pt epochs=100 imgsz=640- 模型推理与使用
训练好后,我们可以用一行代码对图片进行检测,在数据集根目录创建 predict.py 文件并运行:
python
from ultralytics import YOLO
model = YOLO("runs/detect/train2/weights/best.pt") #
results = model.predict(source="test.jpg", save=True, conf=0.5)| 原图 | 预测图 |
|---|---|
 |
 |
避坑指南:那些你没想到的"重要细节"
在实际工业部署中,光有代码是不够的,你还需要考虑以下三个"深坑":
负样本(Background Images)的重要性
很多开发者只标注有安全帽的图。但在工地上,可能会有圆形的桶、灯具被误认为安全帽。
建议: 在训练集中加入 10% 左右不包含任何目标的"空图片",这能极大降低误报率。
多尺度检测(Small Objects)
塔吊上的摄像头离地面很远,人头在画面中可能只有几个像素。
建议: 训练时开启 augment=True,并考虑使用 SAHI(Slicing Aided Hyper Inference) 切片推理技术,将大图切割检测后再合并,避免小目标丢失。
光照与环境的鲁棒性
工地有强烈的背光或夜间补光。
建议: 充分利用 YOLO11 自带的数据增强功能,尤其是调整 hsv_v(亮度)和 blur(模糊)参数,模拟恶劣天气和光照条件。