本书接下来的章节将讨论网络浏览器。没有浏览器,就没有 JavaScript;即使有,也不会有人关注它。
网络技术从一开始就是分散的,这不仅体现在技术上,也体现在其发展方式上。不同的浏览器供应商以临时的、有时考虑不周的方式增加新的功能,然后(有时)被其他厂商采用,最后形成标准。这既是好事,也是坏事。一方面,没有中央控制的系统,而是由各方在松散的合作(或偶尔公开的敌意)中进行改进,这是很有力量的。另一方面,网络开发的草率方式也意味着,由此产生的系统并不完全是内部一致性的光辉典范。它的某些部分简直令人困惑,设计也很糟糕。
网络和互联网
计算机网络早在 20 世纪 50 年代就已出现。如果在两台或多台计算机之间铺设电缆,让它们通过这些电缆来回发送数据,就可以实现各种奇妙的事情。
如果把同一栋楼里的两台机器连接起来就能做很多奇妙的事情,那么把地球上所有的机器连接起来应该会更好。实现这一愿景的技术始于 20 世纪 80 年代,由此产生的网络被称为互联网。它实现了自己的诺言。一台计算机可以利用这个网络向另一台计算机发送比特。要想通过比特射击进行有效通信,两端的计算机必须知道比特代表的含义。任何特定比特序列的含义完全取决于它所要表达的事物类型和所使用的编码机制。
网络协议描述了一种网络通信方式。有发送电子邮件的协议、获取电子邮件的协议、共享文件的协议,甚至还有控制被恶意软件感染的计算机的协议。超文本传输协议(HTTP)是一种用于检索命名资源(信息块,如网页或图片)的协议。该协议规定,发出请求的一方应以这样一行开头,命名资源和试图使用的协议版本:

关于请求者在请求中包含更多信息的方式,以及返回资源的另一方打包其内容的方式,还有更多规则。我们将在第 18 章详细介绍 HTTP。
大多数协议都建立在其他协议之上。HTTP 将网络视为一个流式设备,你可以将比特放入其中,并让它们以正确的顺序到达正确的目的地。在网络提供的原始数据发送基础上提供这些保证已经是一个相当棘手的问题。传输控制协议(TCP)就是解决这一问题的协议。所有与互联网连接的设备都 "使用 "它,互联网上的大部分通信都建立在它的基础之上。
TCP 连接的工作原理如下:一台计算机必须等待或监听其他计算机开始与它对话。为了能在一台机器上同时监听不同类型的通信,每个监听器都有一个与之相关的号码(称为端口)。大多数协议都指定了默认使用的端口。例如,当我们想使用 SMTP 协议发送电子邮件时,我们发送邮件的机器应该监听 25 端口。另一台计算机可以使用正确的端口号连接到目标计算机,从而建立连接。如果目标计算机可以连接到,并且正在监听该端口,则连接成功建立。监听的计算机称为服务器,连接的计算机称为客户端。
这种连接就像一个双向管道,比特可以在其中流动--两端的机器都可以向其中输入数据。一旦比特成功传输,另一端的机器就可以再次读出这些比特。这是一个方便的模型。可以说,TCP 提供了一个网络抽象。
网络
万维网(World Wide Web,不要与整个互联网混淆)是一套允许我们在浏览器中访问网页的协议和格式。网络一词指的是这些网页可以很容易地相互链接,从而连接成一个巨大的网状结构,用户可以在其中穿行。要成为网络的一部分,你只需将一台机器连接到互联网,让它通过 HTTP 协议监听 80 端口,这样其他计算机就可以向它请求文档。
网络上的每份文档都以统一资源定位符(URL)命名,看起来就像这样:

第一部分告诉我们该 URL 使用 HTTP 协议(而不是加密 HTTP 协议,例如 https://)。然后是标识我们从哪个服务器请求文档的部分。最后是一个路径字符串,用于标识我们感兴趣的文档(或资源)。
连接到互联网的机器会得到一个 IP 地址,这是一个可以用来向该机器发送信息的数字,看起来像 149.210.142.219 或 2001:4860:4860::8888。由于一串或多或少随机的数字很难记住,输入起来也很别扭,因此您可以为一个地址或一组地址注册一个域名。我注册了 eloquentjavascript.net,指向我控制的一台机器的 IP 地址,因此可以使用该域名服务网页。如果你在浏览器的地址栏中输入这个 URL,浏览器就会尝试检索并显示该 URL 上的文档。首先,浏览器必须找出 eloquentjavascript.net 指向的地址。然后,浏览器将使用 HTTP 协议与该地址的服务器建立连接,并请求 /13_browser.html 资源。如果一切顺利,服务器就会发回一个文档,然后浏览器就会在屏幕上显示该文档。
HTML
HTML 是超文本标记语言(HyperText Markup Language)的缩写,是网页使用的文档格式。HTML 文档包含文本以及赋予文本结构的标记,如链接、段落和标题。
一个简短的 HTML 文档可能是这样的:

标签用尖括号(<和>,表示小于和大于)包裹,提供有关文档结构的信息。其他文本只是普通文本。
文档以 <!doctype html> 开始,这告诉浏览器将页面解释为现代 HTML,而不是过去使用的过时样式。HTML 文档分为头部和主体。头部包含有关文档的信息,主体包含文档的内容。在这个例子中,头部声明该文档的标题为"我的主页",并使用 UTF-8 编码,这是一种将 Unicode 文本编码为二进制数据的方式。文档的主体包含一个标题(<h1>,表示"标题 1",<h2> 到 <h6> 用于生成子标题)和两个段落(<p>)。
标签有几种形式。元素,例如主体、段落或链接,由一个开标签(如 <p>)开始,并由一个闭标签(如 </p>)结束。一些开标签,例如链接的标签(<a>),包含以 name="value" 对形式的额外信息,这些称为属性。在这个例子中,链接的目标通过 href="http://eloquentjavascript.net" 指示,其中 href 代表"超文本引用"。
某些类型的标签不包围任何内容,因此不需要关闭。元数据标签 <meta charset="utf-8"> 就是一个例子。为了能够在文档的文本中包含尖括号,即使它们在 HTML 中有特殊含义,必须引入另一种特殊符号表示法。普通的开尖括号写作 <("小于"),闭尖括号写作 >("大于")。在 HTML 中,一个与名称或字符代码及分号(;)相结合的和符号(&)称为实体,将被替换为它所编码的字符。这与反斜杠在 JavaScript 字符串中的使用类似。由于此机制赋予了和符号特殊含义,因此它们需要被转义为 &。在用双引号包裹的属性值中,可以使用 " 来插入字面量引号字符。
HTML 的解析容错能力极强。如果缺少应有的标记,浏览器会自动添加。这种方式已经标准化,所有现代浏览器都能以相同的方式完成。
以下文档的处理方式与之前显示的文档相同:
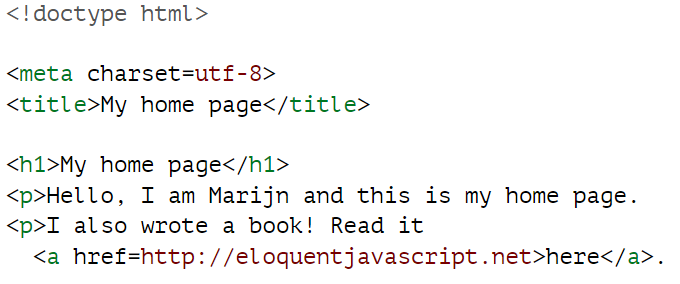
<html>、<head> 和 <body> 标签完全消失了。浏览器知道 <meta> 和 <title> 属于头部,而 <h1> 表示主体已经开始。此外,我不再显式地关闭段落,因为打开一个新段落或结束文档会隐式地关闭它们。属性值周围的引号也消失了。
本书通常会省略示例中的 <html>、<head> 和 <body> 标签,以保持简洁和清晰。不过,我会关闭标签并在属性周围添加引号。我还通常会省略文档类型和字符集声明。不要因此而认为可以在 HTML 文档中去掉这些内容。如果你忘记了这些,浏览器往往会做出荒谬的事情。请将文档类型和字符集元数据视为在示例中隐式存在,即使它们在文本中并没有实际显示。
HTML和JavaScript
在本书中,最重要的 HTML 标记是 <script>,它允许我们在文档中包含一段 JavaScript。

在浏览器读取 HTML 代码时,一旦遇到 <script> 标记,脚本就会立即运行。该页面打开时会弹出一个对话框--警报功能与提示功能类似,都是弹出一个小窗口,但只显示信息而不要求输入。在 HTML 文档中直接包含大型程序往往不切实际。可以给 <script> 标签加上 src 属性,以便从 URL 获取脚本文件(包含 JavaScript 程序的文本文件)。

代码/hello.js 文件包含相同的程序------alert("hello!")。当一个 HTML 页面引用其他 URL 作为其一部分时,例如图像文件或脚本,网页浏览器会立即检索它们并将其包含在页面中。
脚本标签必须始终用 </script> 关闭,即使它引用的是脚本文件并且不包含任何代码。如果你忘记这一点,页面的其余部分将被解释为脚本的一部分。
你可以通过为脚本标签添加 type="module" 属性在浏览器中加载 ES 模块(见第 10 章)。这样的模块可以通过在导入声明中使用相对于自身的 URL 作为模块名称来依赖其他模块。
某些属性也可以包含 JavaScript 程序。<button> 标签(显示为按钮)支持 onclick 属性。每当按钮被点击时,属性的值将被执行。

请注意,我必须为 onclick 属性中的字符串使用单引号,因为双引号已用于引用整个属性。我也可以使用 " 来转义内部引号。
在沙箱中
运行从互联网上下载的程序具有潜在危险。你不太了解你访问的大多数网站背后的人,他们也不一定是好意。运行恶意程序会让你的电脑感染病毒、数据被盗、账户被黑。然而,网络的魅力就在于,你可以浏览它,却不一定要相信你访问的所有网页。这就是浏览器严格限制 JavaScript 程序的原因:它不能查看计算机上的文件,也不能修改与其嵌入的网页无关的任何内容。
以这种方式隔离编程环境被称为沙盒,意思是程序在沙盒中无害地运行。不过,你应该把这种特殊的沙盒想象成一个笼子,笼子上有厚厚的钢筋,这样在里面玩的程序实际上就出不来了。沙盒设计的难点在于,既要让程序有足够的空间发挥作用,又要限制它们做任何危险的事情。很多有用的功能,如与其他服务器通信或读取复制粘贴剪贴板的内容,也可能被用于有问题的、侵犯隐私的目的。
每隔一段时间,就会有人想出新的办法来规避浏览器的限制,并做出一些有害的事情,从泄露小的私人信息到接管运行浏览器的整个机器。浏览器开发商会采取应对措施,修复漏洞,然后一切恢复正常--直到下一个问题被发现,而且希望是被公开,而不是被某些政府机构或犯罪组织秘密利用。
兼容性和浏览器大战
在网络的早期阶段,一种名为 Mosaic 的浏览器占据了市场的主导地位。几年后,市场的天平转移到了网景浏览器(Netscape),而网景浏览器又在很大程度上被微软的 Internet Explorer 所取代。在单一浏览器占据主导地位的任何时候,该浏览器的供应商都会觉得有权单方面为网络发明新功能。由于大多数用户使用的都是最流行的浏览器,因此网站只需开始使用这些功能,而无需理会其他浏览器。
这就是兼容性的黑暗时代,通常被称为浏览器大战。网络开发人员面临的不是一个统一的网络,而是两三个互不兼容的平台。更糟糕的是,2003 年前后使用的浏览器都充满了漏洞,当然每个浏览器的漏洞都不一样。对于编写网页的人来说,生活非常艰难。
Mozilla Firefox 是网景公司的一个非盈利分支,在 2000 年代末对 Internet Explorer 的地位提出了挑战。由于微软当时对保持竞争力并不特别感兴趣,火狐浏览器抢走了它的大量市场份额。大约在同一时期,谷歌推出了 Chrome 浏览器,苹果的 Safari 浏览器也大受欢迎,从而出现了四大而非一家的局面。
新的参与者对标准的态度更加认真,工程实践也更加完善,从而减少了不兼容性和错误。微软看到自己的市场份额一落千丈,于是在其取代 Internet Explorer 的 Edge 浏览器中采用了这些态度。如果你现在开始学习网络开发,那就应该感到幸运。最新版本的主要浏览器表现相当一致,错误也相对较少。
不幸的是,随着火狐浏览器的市场份额越来越小,Edge 浏览器在 2018 年成为 Chrome 浏览器的核心包装,这种统一性可能会再次以单一厂商--谷歌--的形式出现,这一次,谷歌对浏览器市场拥有足够的控制权,可以将自己的网络理念强加给世界其他地方。
无论如何,这一长串历史事件和意外事件造就了我们今天的网络平台。在接下来的章节中,我们将为它编写程序。