Openai 上线语音模型whisper-large-v3-turbo

在本文中,我们将介绍 whisper-large-v3-turbo 以及 whisper-web(一个直接在浏览器中进行ML语音识别的开源项目)。

尽管近年来出现了许多音频和多模态模型,但Whisper 仍是生产级自动语音识别(ASR)的首选。
Whisper 是一种最先进的自动语音识别 (ASR) 和语音翻译模型,由 OpenAI 的 Alec Radford 等人在论文《 通过大规模弱监督实现稳健语音识别》中提出。
Whisper 模型有两种风格:纯英语和多语言。纯英语模型接受英语语音识别任务的训练。多语言模型同时进行多语言语音识别和语音翻译训练。对于语音识别,该模型会预测与音频相同语言的转录。对于语音翻译,该模型会预测转录为与音频不同的语言。
Whisper 检查点有五种不同型号尺寸的配置。最小的四种语言有纯英语和多语言版本。最大的检查站仅支持多种语言。Hugging Face Hub上提供了所有十个预先训练的检查点。下表总结了检查点:

新推出的 Whisper Turbo 模型是 OpenAI 开发的,经过约 500 万小时的标记数据训练,具有出色的泛化能力。
与其前身 Whisper 大型版本 3 相比,Turbo 版在解码层数上从 32 降至 4,运行速度更快,尽管质量略有下降,但差别非常小。
我们将通过 Hugging Face 本地安装该模型,尝试几个音频文件:
创建一个简单的虚拟环境

安装一些先决条件,包括 Torch、Transformers 等。

现在启动 Jupyter Notebook

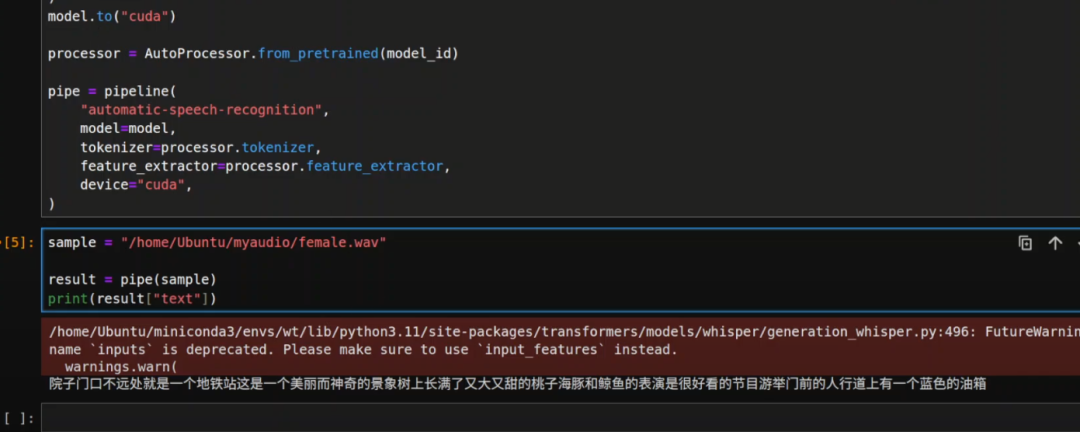
Jupyter Notebook 启动后,我们导入所有库,然后获取模型,我们选择 Whisper 大型版本 3 Turbo,然后下载模型并将其放入我们的 CUDA 设备(即 GPU),接着我会初始化这个自动语音识别的管道,提供模型、分词器,并指定我们的 CUDA 设备。

这个模型非常轻量级,不到 2GB。

下载完成后,你只需提供本地音频文件,或者你也可以加载来自 Hugging Face 的任何音频数据集,并进行处理。
正常work: