我自己的原文哦~https://blog.51cto.com/whaosoft/11638046
一、 搭建半自动标注工具
本文主要介绍的半自动标注工具为pyOpenAnnotate,此工具是基于Python和OpenCV实现,最新版本为0.4.0,可通过下面指令安装使用:
pip install pyOpenAnnotate详细介绍与使用步骤参考链接:
https://pypi.org/project/pyOpenAnnotate/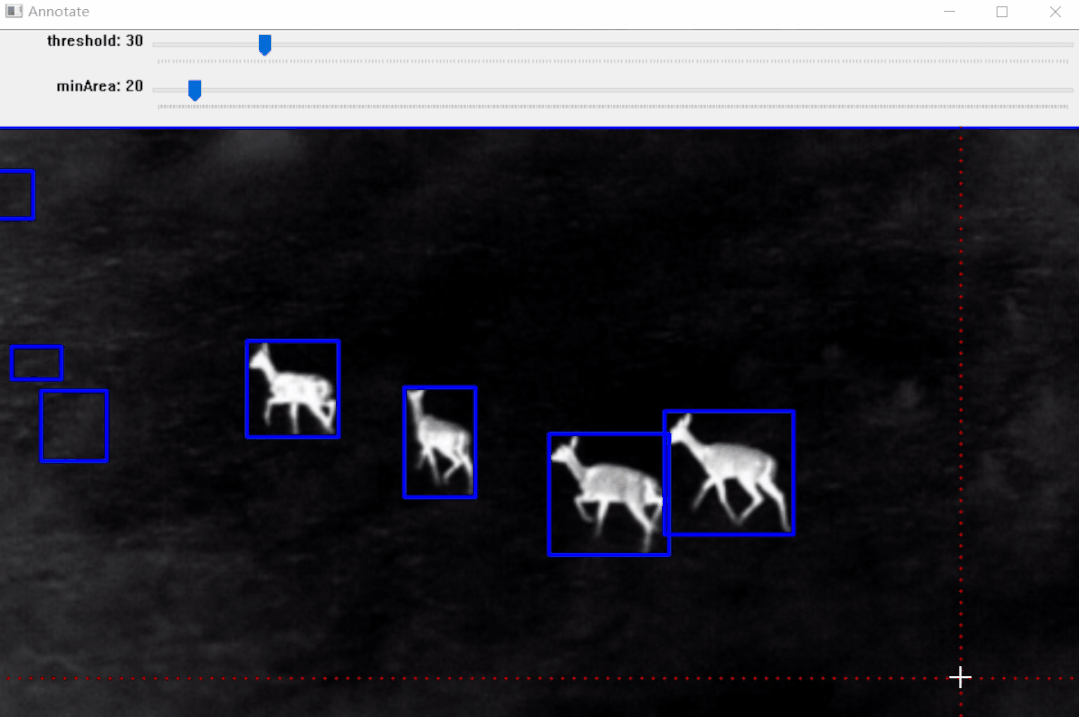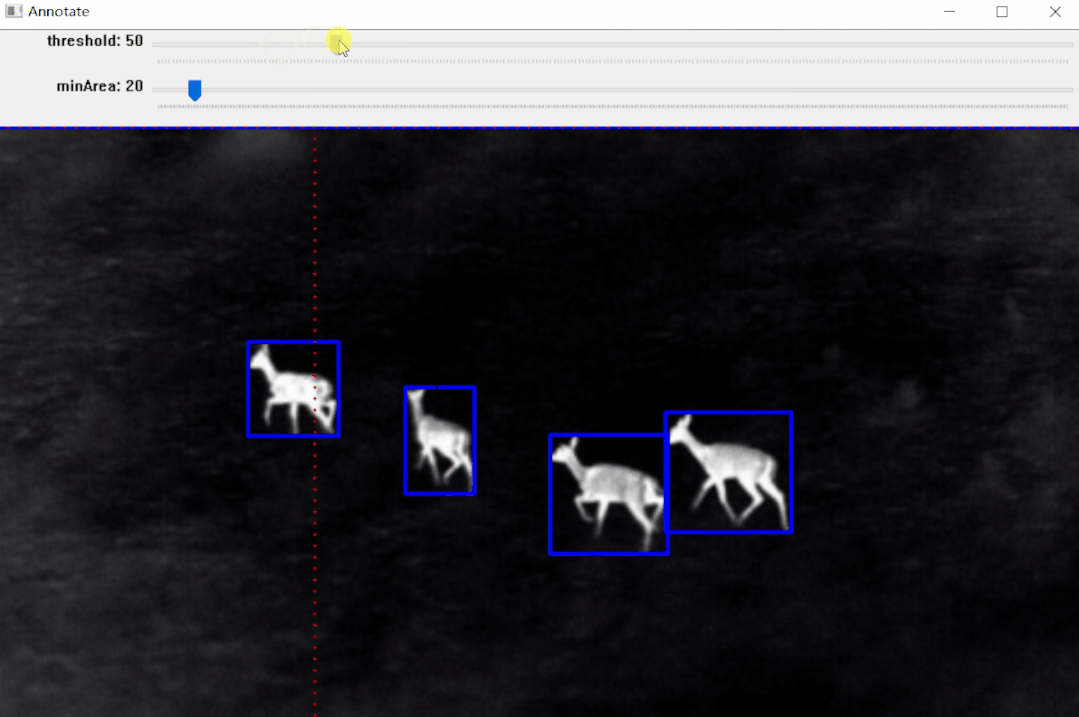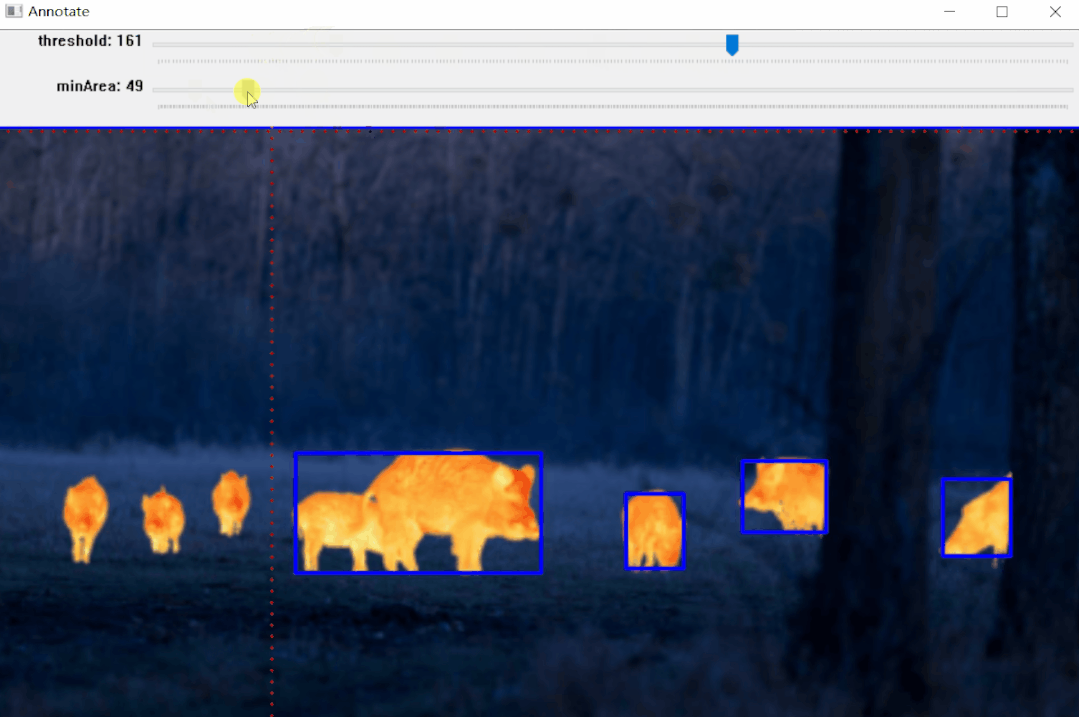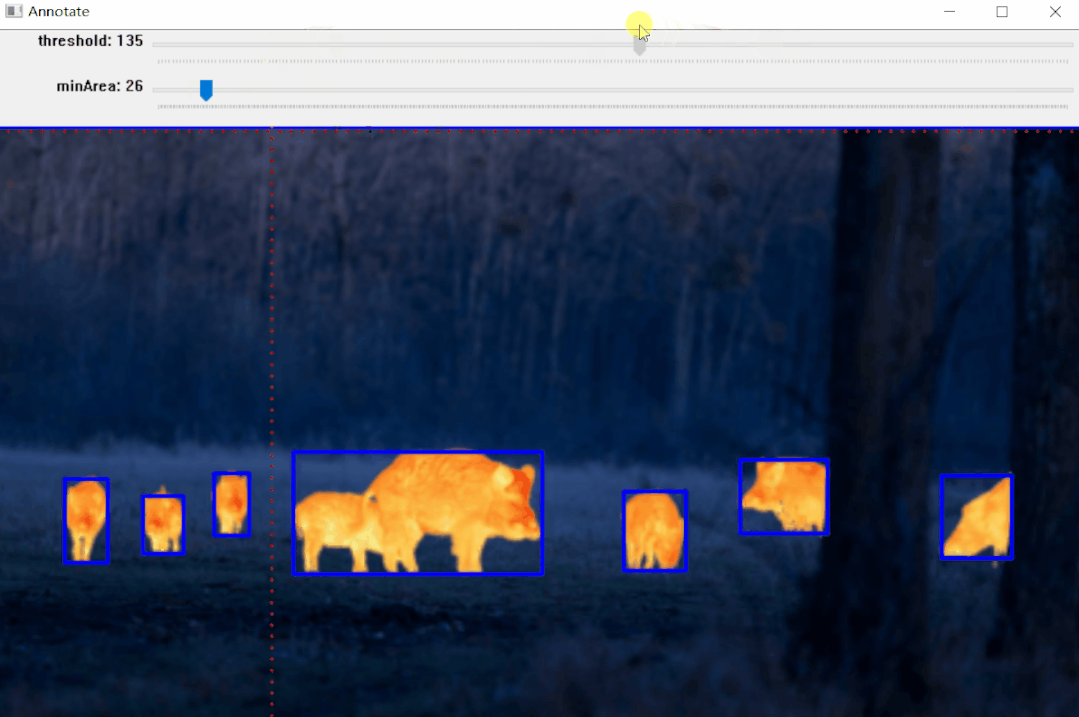
标注效果:
效果如上图所示,标注完成后可以生成标注文件,后面部分将详细介绍其实现步骤。
实现原理流程:
说明:
【1】Threshold(二值化)只接受单通道图像,但这里并不是直接使用灰度转换图来处理,而是从灰度图、R、G、B、H、S、V通道图像中找到对比度最高的图像来做二值化。
【2】二值化之后并不能保证总是得到我们需要的掩码,有时会有噪声、斑点、边缘的干扰,所以加入了膨胀、腐蚀等形态学处理。
【3】最后通过轮廓分析得到对象的边界框,也就是左上角和右下角坐标。
代码讲解与演示
首先需要导入所需库:
import cv2
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['image.cmap'] = 'gray'加载图像:
stags = cv2.imread('stags.jpg')
boars = cv2.imread('boar.jpg')
berries = cv2.imread('strawberries.jpg')
fishes = cv2.imread('fishes.jpg')
coins = cv2.imread('coins.png')
boxes = cv2.imread('boxes2.jpg')选择色彩空间(这里添加了 RGB和HSV,存储在字典中,方便验证使用):
def select_colorsp(img, colorsp='gray'):
# Convert to grayscale.
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# Split BGR.
red, green, blue = cv2.split(img)
# Convert to HSV.
im_hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
# Split HSV.
hue, sat, val = cv2.split(im_hsv)
# Store channels in a dict.
channels = {'gray':gray, 'red':red, 'green':green,
'blue':blue, 'hue':hue, 'sat':sat, 'val':val}
return channels[colorsp]显示 1×2 图像的实用函数(display()函数接受两个图像并并排绘制。可选参数是绘图的标题和图形大小):
def display(im_left, im_right, name_l='Left', name_r='Right', figsize=(10,7)):
# Flip channels for display if RGB as matplotlib requires RGB.
im_l_dis = im_left[...,::-1] if len(im_left.shape) > 2 else im_left
im_r_dis = im_right[...,::-1] if len(im_right.shape) > 2 else im_right
plt.figure(figsize=figsize)
plt.subplot(121); plt.imshow(im_l_dis);
plt.title(name_l); plt.axis(False);
plt.subplot(122); plt.imshow(im_r_dis);
plt.title(name_r); plt.axis(False);阈值处理(thresh()函数接受1通道灰度图像,默认阈值设置为 127。执行逆阈值处理,方便轮廓分析,它返回单通道阈值图像):
def threshold(img, thresh=127, mode='inverse'):
im = img.copy()
if mode == 'direct':
thresh_mode = cv2.THRESH_BINARY
else:
thresh_mode = cv2.THRESH_BINARY_INV
ret, thresh = cv2.threshold(im, thresh, 255, thresh_mode)
return thresh实例:雄鹿红外图像标注
整体实现步骤:
【1】选择色彩空间
# Select colorspace.
gray_stags = select_colorsp(stags)
# Perform thresholding.
thresh_stags = threshold(gray_stags, thresh=110)
# Display.
display(stags, thresh_stags,
name_l='Stags original infrared',
name_r='Thresholded Stags',
figsize=(20,14))【2】执行阈值
【3】执行形态学操作
def morph_op(img, mode='open', ksize=5, iteratinotallow=1):
im = img.copy()
kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE,(ksize, ksize))
if mode == 'open':
morphed = cv2.morphologyEx(im, cv2.MORPH_OPEN, kernel)
elif mode == 'close':
morphed = cv2.morphologyEx(im, cv2.MORPH_CLOSE, kernel)
elif mode == 'erode':
morphed = cv2.erode(im, kernel)
else:
morphed = cv2.dilate(im, kernel)
return morphed
# Perform morphological operation.
morphed_stags = morph_op(thresh_stags)
# Display.
display(thresh_stags, morphed_stags,
name_l='Thresholded Stags',
name_r='Morphological Operations Result',
figsize=(20,14))【4】轮廓分析以找到边界框
bboxes = get_bboxes(morphed_stags)
ann_morphed_stags = draw_annotations(stags, bboxes, thickness=5, color=(0,0,255))
# Display.
display(ann_stags, ann_morphed_stags,
name_l='Annotating Thresholded Stags',
name_r='Annotating Morphed Stags',
figsize=(20,14))【5】过滤不需要的轮廓
def get_filtered_bboxes(img, min_area_ratio=0.001):
contours, hierarchy = cv2.findContours(img, cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)
# Sort the contours according to area, larger to smaller.
sorted_cnt = sorted(contours, key=cv2.contourArea, reverse = True)
# Remove max area, outermost contour.
sorted_cnt.remove(sorted_cnt[0])
# Container to store filtered bboxes.
bboxes = []
# Image area.
im_area = img.shape[0] * img.shape[1]
for cnt in sorted_cnt:
x,y,w,h = cv2.boundingRect(cnt)
cnt_area = w * h
# Remove very small detections.
if cnt_area > min_area_ratio * im_area:
bboxes.append((x, y, x+w, y+h))
return bboxes【6】绘制边界框
bboxes = get_filtered_bboxes(thresh_stags, min_area_ratio=0.001)
filtered_ann_stags = draw_annotations(stags, bboxes, thickness=5, color=(0,0,255))
# Display.
display(ann_stags, filtered_ann_stags,
name_l='Annotating Thresholded Stags',
name_r='Annotation After Filtering Smaller Boxes',
figsize=(20,14))视频标注:

【7】以需要的格式保存
Pascal VOC、YOLO和COCO 是对象检测中使用的三种流行注释格式。让我们研究一下它们的结构。
I. Pascal VOC 以 XML 格式存储注释
II. YOLO标注结果保存在文本文件中。对于每个边界框,它看起来如下所示。这些值相对于图像的高度和宽度进行了归一化。
0 0.0123 0.2345 0.123 0.754
<object-class> <x_centre_norm> <y_centre_norm> <box_width_norm> <box_height_norm>让边界框的左上角和右下角坐标表示为(x1, y1)和(x2, y2)。然后:
III. MS COCO
这里以YOLO Darknet保存格式为例(当然,你可以保存其他格式):
def save_annotations(img, bboxes):
img_height = img.shape[0]
img_width = img.shape[1]
with open('image.txt', 'w') as f:
for box in boxes:
x1, y1 = box[0], box[1]
x2, y2 = box[2], box[3]
if x1 > x2:
x1, x2 = x2, x1
if y1 > y2:
y1, y2 = y2, y1
width = x2 - x1
height = y2 - y1
x_centre, y_centre = int(width/2), int(height/2)
norm_xc = x_centre/img_width
norm_yc = y_centre/img_height
norm_width = width/img_width
norm_height = height/img_height
yolo_annotations = ['0', ' ' + str(norm_xc),
' ' + str(norm_yc),
' ' + str(norm_width),
' ' + str(norm_height), '\n']
f.writelines(yolo_annotations)标注结果显示与保存:
简单演示: 天皓智联 开发板商城
二、 GAN~表面缺陷检测
缺陷检测是工业生产过程中的关键环节,其检测结果的好坏直接影响着产品的质量。而在现实场景中,但产品瑕疵率非常低,甚至是没有,缺陷样本的不充足使得需要深度学习缺陷检测模型准确率不高。如何在缺陷样本少的情况下实现高精度的检测呢?目前有两种方法,一种是小样本学习,另一种是用GAN。本文将介绍一种GAN用于无缺陷样本产品表面缺陷检测。
深度学习在计算机视觉主流领域已经应用的很成熟,但是在工业领域,比如产品表面缺陷检测,总感觉没有发挥深度学习的强大能力,近几年表面缺陷的 相关研究主要是集中在各种借鉴主流神经网络框架,从CNN到YOLO,SSD,甚至到语义分割的FCN相关论文,通过一些技术,对框架进行轻量化,对缺陷进行分类或检测。不过,逃不出一个问题:一定要有缺陷样本可供训练,而且数量不能太少!当然,也有一些课题组使用稀疏编码、字典学习、稀疏自编码等对表面缺陷进行检测,这类方法很有局限性,主要针对那些有周期性背景纹理的图像,比如丝织品,印刷品等。国内外很多课题组、工业软件公司都想开发出一些切合实际应用的算法软件,在缺陷检测领域,比较好的公司有:VIDI、Halcon等,听说海康威视也在搞工业产品方便的算法研究。
论文标题:A Surface Defect Detection Method Based on Positive Samples
论文链接:https://doi.org/10.1007/978-3-319-97310-4_54
作者提出只依据已有的正常表面图像样本,通过一定的技术手段对缺陷样本进行检测,很好的将最近研究火热的GAN应用于框架中,这一年,课题组的老师也一直讨论这种方法的可行性,缺陷的检测要不要有缺陷样本,从稀疏自编码,小样本学习再到计算机视觉研究热点之一的零样本学习,得出结论:大多数工业产品表面缺陷检测是需要缺陷样本或者人为制作的缺陷样本,论文虽然是没有直接使用生产线上的缺陷样本,但是通过算法人为的产生了缺陷样本,并很好的融合和GAN在图像修复领域的强大能力,整个框架的设计很巧妙。
**文章思路:**论文的整体思路就是GAN在图像修复和重建方便具有很强大的能力,通过人为的去在正常样本上"随意"添加一些缺陷,训练阶段让GAN去学习一个可以修复这些缺陷区域的网络,检测阶段时,输入一个真实缺陷样本,训练好的GAN会对其进行修复,再基于LBP可完成缺陷检测。整个算法框架不需要真实的缺陷样本和手工标签,但是在框架中,人为的去产生(比如PS)一些缺陷区域。
通俗说:
作者利用GAN在图像修复(重建)上的能力,在工业现场收集一些正常(无缺陷)样本,人工PS一些缺陷,比如线条、斑点等。
训练时,将PS的人工制作的缺陷图像和原图像做输入样本训练GAN,得到一个具有图像修复重建能力的网络。
测试时,直接使用训练好的GAN对采集到的图像进行重建修复,如果样本中中有缺陷区域,缺陷区域按照网络设计,肯定需要修复,将修复后的图像和原缺陷图像使用LBP找出显著差异区域即为缺陷区域。
01 主要内容
论文的主体框架思想是基于GAN网络的结构。GAN 主要包括了两个部分,即生成器 G与判别器 D。生成器主要用来学习真实图像分布从而让自身生成的图像更加真实,以"骗过"判别器。判别器则需要对接收的图片进行真假判别。在整个过程中,生成器努力地让生成的图像更加真实,而判别器则努力地去识别出图像的真假,这个过程相当于一个博弈过程,随着时间的推移,生成器和判别器在不断地进行对抗,最终两个网络达到了一个动态均衡:生成器生成的图像接近于真实图像分布,而判别器识别不出真假图像,对于给定图像的预测为真的概率基本接近 0.5(这段话从李宏毅老师那引用的,致敬李老师)。
- 训练阶段
在训练阶段,模型采用一些图像处理技术,人为的在正常样本图像上产生一些缺陷(示意图中的红色框模块),使用由自编码器构成的G模块进行缺陷修复学习,学习的目标是与正常样本之间的L1范数最小,通过一定数量的样本训练可以获得有缺陷修复能力的G模块。GAN用于图像修复的一些资料可以参考34,当然也可以参考论文里的参考文献。
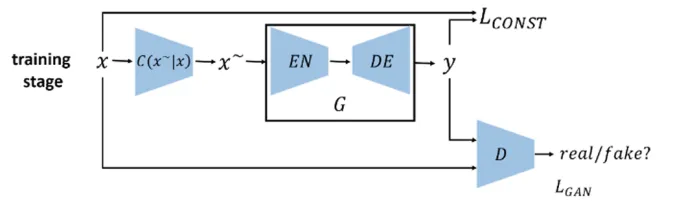
训练阶段
- 测试阶段
在测试阶段,将上步骤训练好的G模块作为测试阶段的图片修复模块,对于输出的图像样本,假如存在缺陷区域,通过修复模块G将得到修复后的图像,与原缺陷样本图像一起作为LBP算法的输入,通过LBP算法对其缺陷区域进行精确定位。
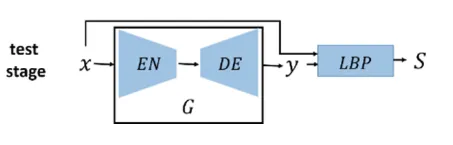
测试阶段
02 其他细节
2.1缺陷生成
在实际训练中,论文作者手工生成一些缺陷样本,如图3所示,训练网络自动修复缺陷。另外作者也通过一些技术进行了样本的扩充,比如加入高斯噪声、随机resize大小等。

缺陷生成
3.2缺陷图像重建
缺陷图像重建部分主要的作用是:缺陷图像重建后尽量和正常样本一样,作者在这部分在文献56基础上进行框架修改的,比如使用L1 distance作为衡量重建差异的目标函数。
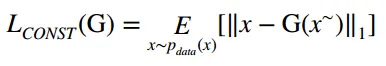
然后实验中作者又发现只使用L1不行,图像边缘等细节可能会衡量不准确,又加入GAN loss来提升网络的重建效果。
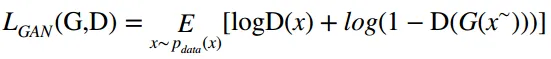
最后,得到了下面目标函数。
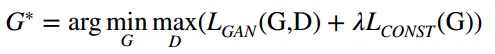
2.3缺陷检测
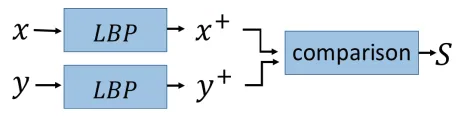
因为使用GAN修复后的图片和原始缺陷样本图片之间在像素级的细节上有一些差异,作者使用了前几年在人脸领域应用比较好的LBP算法进行缺陷区域的检测,这里不介绍算法的细节,示意图如下。
03 实验
文章对DAGM 2007数据集和织物密集图像进行了验证实验。实验表明,提出的GAN+LBP算法和有足够训练样本的监督训练算法具有较高的检测准确率。实验使用两种类型的数据集,4.1是印花纹表面,4.2是织物表面。
4.1Texture surface

测试样本
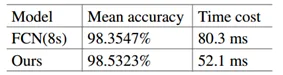
结果

a.原始图像,b.修复图像,c.论文方法,d. FCN方法,e.真实标签
3.2 Fabric Picture
实验中缺陷样本的类型有五种。实验样本按背景分有三类,每类包含5个缺陷样本,25个正常样本。

测试样本
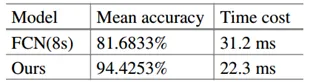
结果

a.原始图像,b.修复图像,c.论文方法,d. FCN方法,e.真实标签
三、 SAM2(Segment Anything Model 2)
新一代分割一切大模型
SAM 2: Segment Anything Model 2
**Segment Anything Model 2(SAM 2)**是由Meta公司发布的一个先进的图像和视频分割模型。它是Segment Anything Model(SAM)的升级版本,SAM是Meta的FAIR实验室发布的一款用于图像分割的基础模型,能够在给定提示的情况下生成高质量的对象掩模。
项目地址:
https://github.com/facebookresearch/segment-anything-2特点
- 准确性提升:SAM 2相比原始的SAM模型在分割精度上有所提高。
- 速度加快:SAM 2的处理速度提高了大约六倍,这意味着它可以更快地生成分割掩模。
- 支持视频分割:除了图像分割之外,SAM 2还支持视频中的对象分割。
- 实时处理:SAM 2可以实现实时处理,这使得它非常适合于需要快速响应的应用场景,如增强现实(AR)和虚拟现实(VR)应用。
- Zero-Shot泛化:SAM 2具有良好的zero-shot迁移能力,即可以在未见过的数据上工作而不需要额外的训练。
- 可提示的模型架构:SAM 2继承了SAM的特性,可以根据不同的提示(如点、框、甚至是文本)来生成分割结果。whaosoft开发板商城测试设备www.143ai.com
结构
- 编码器-解码器架构:SAM 2很可能会继续使用编码器-解码器架构,其中编码器负责提取特征,解码器则用于生成分割掩模。
- 高效网络设计:为了达到更高的处理速度,SAM 2可能采用了优化过的网络结构或计算效率更高的组件。
- 适应性强的分割头:模型可能包含了一个高度灵活的分割头,能够根据不同的提示生成相应的掩模。
- 多模态输入支持:除了传统的图像输入外,SAM 2还可能支持视频帧序列作为输入,以实现视频分割。
- 训练数据集:SAM 2的训练数据集可能包含了大量多样化的图像和视频样本,以确保模型的泛化能力和鲁棒性。
应用场景
- 增强现实(AR)和虚拟现实(VR):SAM 2可以用于实时分割用户周围的环境,从而增强用户体验。
- 自动驾驶:在自动驾驶系统中,SAM 2可以帮助车辆识别和理解道路场景中的不同元素。
- 医学影像分析:SAM 2可以用来自动分割医学影像中的器官或病变区域。
SAM 2使用步骤与代码演示
方法一:使用github项目
https://github.com/facebookresearch/segment-anything-2使用前需要先安装 SAM 2。代码需要python>=3.10,以及torch>=2.3.1和。请按照此处的torchvision>=0.18.1说明安装 PyTorch 和 TorchVision 依赖项。您可以使用以下方式在 GPU 机器上安装 SAM 2:
git clone https://github.com/facebookresearch/segment-anything-2.git
cd segment-anything-2; pip install -e .下载模型:

图像预测:
import torch
from sam2.build_sam import build_sam2
from sam2.sam2_image_predictor import SAM2ImagePredictor
checkpoint = "./checkpoints/sam2_hiera_large.pt"
model_cfg = "sam2_hiera_l.yaml"
predictor = SAM2ImagePredictor(build_sam2(model_cfg, checkpoint))
with torch.inference_mode(), torch.autocast("cuda", dtype=torch.bfloat16):
predictor.set_image(<your_image>)
masks, _, _ = predictor.predict(<input_prompts>)视频预测:
import torch
from sam2.build_sam import build_sam2_video_predictor
checkpoint = "./checkpoints/sam2_hiera_large.pt"
model_cfg = "sam2_hiera_l.yaml"
predictor = build_sam2_video_predictor(model_cfg, checkpoint)
with torch.inference_mode(), torch.autocast("cuda", dtype=torch.bfloat16):
state = predictor.init_state(<your_video>)
# add new prompts and instantly get the output on the same frame
frame_idx, object_ids, masks = predictor.add_new_points(state, <your_prompts>):
# propagate the prompts to get masklets throughout the video
for frame_idx, object_ids, masks in predictor.propagate_in_video(state):
...方法二:基于ultralytics包的封装来调用
【1】安装必要的包。安装ultralytics并确保其版本>=8.2.70,torch版本也需>=2.0或使用最新版本
pip install -U ultralytics【2】下载分割模型。下面网址中提供了4个模型,大家可以根据自己需要下载:
https://docs.ultralytics.com/models/sam-2/#how-can-i-use-sam-2-for-real-time-video-segmentation【3】全局目标分割。
from ultralytics import ASSETS, SAM
# Load a model
model = SAM("sam2_s.pt")
# Display model information (optional)
model.info()
# Segment image or video
results = model('d.jpg') # 图片推理
#results = model('d.jpg') # 视频推理
# Display results
for result in results:
result.show()图片推理效果:
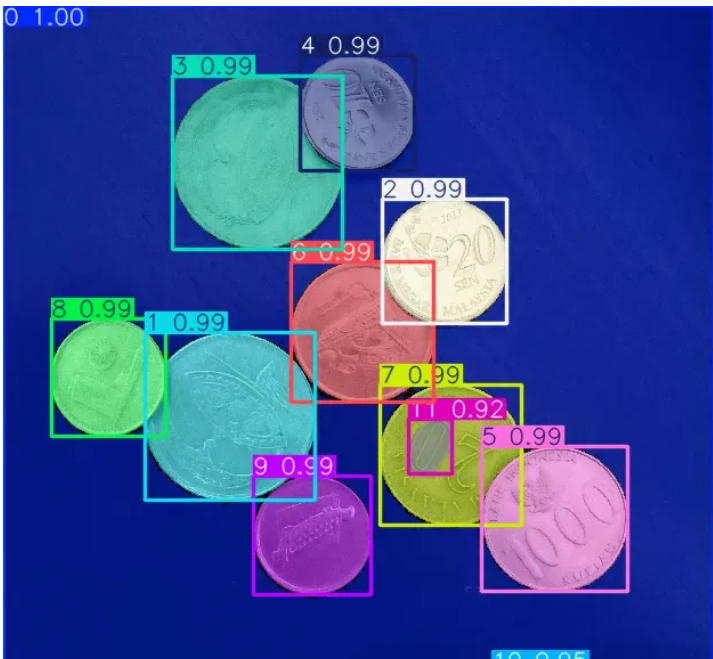
【4】引导分割制定目标(指定点或者矩形区域)。
from ultralytics import ASSETS, SAM
# Load a model
model = SAM("sam2_s.pt")
# Segment with point prompt
results = model("b.jpg", points=[120, 80], labels=[1], device="cpu")
# Display results
for result in results:
result.show()图片推理效果:
from ultralytics import ASSETS, SAM
# Load a model
model = SAM("sam2_s.pt")
# Segment with bounding box prompt
results = model("a.jpg", bboxes=[30, 10, 283, 267], labels=[1], device="cpu")
# Display results
for result in results:
result.show()视频推理效果:

最后附上SAM 2与YOLOv8 seg推理时间对比:
四、CV JPEG图像读取和解码速度
提升77%
Vladimir Iglovikov早前在它的博客(https://dev.to/viglovikov/jpeg2rgb-array-showdown-libjpeg-turbo-vs-kornia-rs-vs-tensorflow-vs-torchvision-2mnh)写到,OpenCV在JPEG图像读取和解码的基准测试(https://github.com/ternaus/imread_benchmark)中,是所有被测试库scikit-image, imageio, opencv, pillow, jpeg4py, torchvision, tensorflow和kornia里速度最慢的:
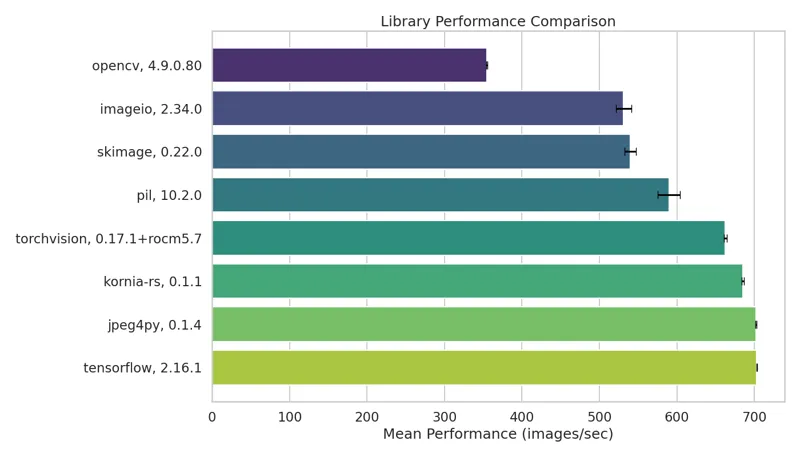
作者同时也把这一问题直接反馈给了OpenCV。OpenCV团队及时解决了这一问题,并在6月3日的4.10.0版本中发布。从4.10开始OpenCV对JPEG图像的读取和解码有了77%的速度提升🚀,超过了scikit-image, imageio和pillow。
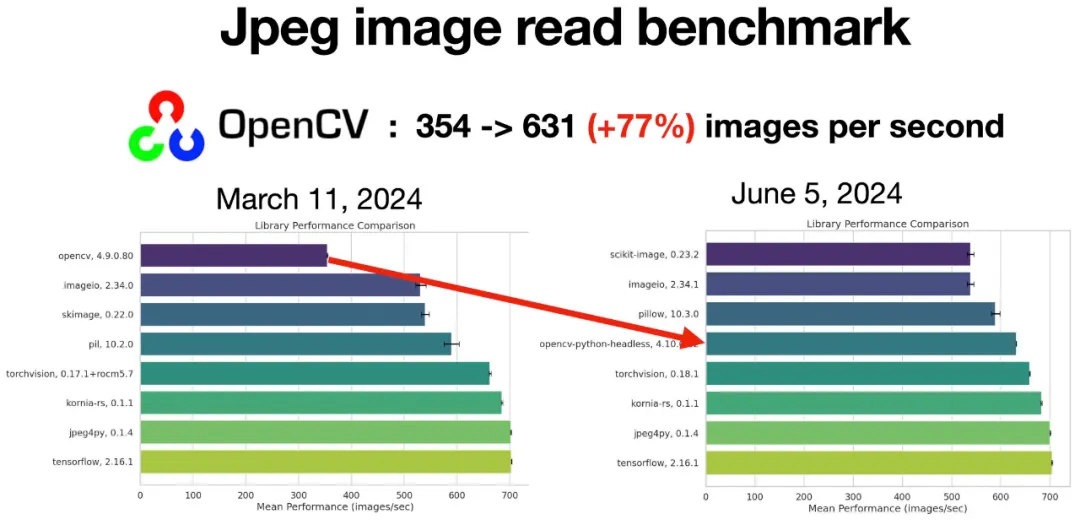
图像读取和解码的速度会显著影响神经网络训练批预处理的效率。如果批图像的预处理速度慢,GPU的利用率会下降,从而导致模型训练和推理成本增加。Vladimir表示现在他的公司基于OpenCV的图像压缩增强库也有了77%的速度提升,这是开源与合作的魅力。