1. Pretraining -> GPT3
1.1. Task & loss
1.1.1. 训练 LLMs 时的关键点

对于 LLMs 的训练来说,Architecture(架构) 、Training algorithm/loss(训练算法/损失函数) 、Data(数据) 、Evaluation(评估) 、以及Systems(系统) 是关键。大多数学术研究主要集中在 Architecture(架构) 和 Training algorithm/loss(训练算法/损失函数) 上。学术界更关注于如何设计新的网络结构以及优化训练过程的方法。然而在实际应用中,Data(数据) 、Evaluation(评估) 、和 **Systems(系统)**更为关键。这意味着在工业界或实际应用中,数据的质量、模型评估方法的有效性以及如何将模型集成到系统中,更直接影响模型在现实场景中的表现。
1.1.2. 模型训练的两个阶段
- Pretraining -> GPT3
- 训练目标: Task & loss
- 通过大量互联网数据和基于任务的训练数据来对整个互联网进行建模
- Post-training -> ChatGPT
- 赋予 LLMs 人类的价值观和偏好,使它们真正成为人类的 AI 助手
- 二者的关系
- Pretraining 和 Post-training 的损失函数相同,都是交叉熵损失
- 用于训练的数据结构、分布和目的不同
- 训练超参数不同,在 Pretraining 的最后阶段,学习率趋近于0,在 Post-training 会重新将学习率拉高到一定高度。
1.1.3. 语言建模


1.1.4. 自回归语言模型
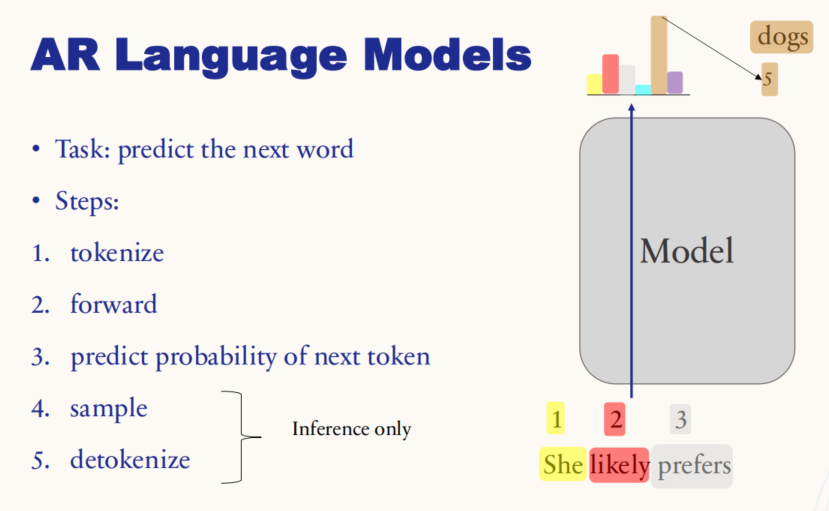
任务(Task):
- 自回归语言模型的主要任务是"预测下一个单词"。它通过输入一个序列,预测序列中下一个最有可能的词。
步骤(Steps):
- Tokenize:将输入的文本分解成标记(tokens),如单词或子词单位,以便模型处理。
- Forward:将这些标记输入到模型中进行前向传播(forward pass),以计算各个标记的向量表示。
- Predict probability of next token:模型基于输入序列,预测下一个标记的概率分布。这一步会给出每个可能的下一个词的概率。
- Sample(仅用于推理/生成):根据模型预测的概率分布,从中采样得到下一个标记。这个过程决定了生成哪个单词。
- Detokenize(仅用于推理/生成):将模型生成的 tokens 转换回人类可读的文本形式。
1.1.5. 自回归神经语言模型
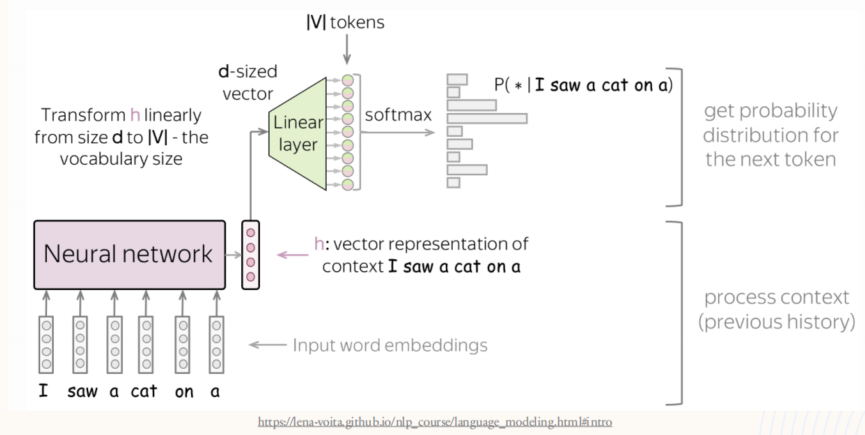
模型首先将输入的句子(如"I saw a cat on a")中的每个单词转化为向量形式的词嵌入(embedding),并通过神经网络处理这些向量,生成一个包含上下文语义信息的向量 h 。这个向量经过线性变换,从初始维度 d 映射到与词汇表大小 V 一致的向量空间,接着通过 Softmax 函数计算每个可能词汇的概率分布。这个概率分布表示在给定前面单词的情况下,每个词作为下一个单词的可能性。最终,模型选择概率最高的词作为下一个输出,从而一步步生成文本。这种机制允许模型根据已有的语境生成自然且连贯的语言,同时充分利用上下文信息预测最合适的单词。
1.1.6. LLMs 的损失计算

LLMs 的任务是根据给定的上下文(如"I saw a")预测下一个词"cat"。LLMs 使用交叉熵损失(cross-entropy loss)来衡量预测结果与目标词之间的差异。具体来说,模型生成每个词的概率分布,然后计算目标词("cat")的负对数概率来得到损失值 Loss。训练的目标就是最小化这种损失,以提升模型在相似上下文中正确预测的能力。通过最大化所有预测词的对数似然(log-likelihood)【也就是最小化所有正确预测词的负对数概率】,LLMs 逐步提高对目标词序列的生成准确性,从而更好地捕捉语言的模式和结构。
1.1.7. 分词器(Tokenizer)

分词器的作用是将文本转换成模型可以处理的标记(token)序列,这样做比直接处理单词或字符更有效率。与逐字处理相比,使用标记可以生成更短的序列,同时也比处理单词更具泛化性,使其能够处理拼写错误。
训练分词器的算法很多,图中以 BPE 算法为例,执行过程为:
- 从大规模文本语料中开始。
- 以每个字符为一个初始标记。
- 不断合并出现频率最高的标记对,逐步构建出更长的标记。
- 这一过程重复进行,直到达到目标词汇表大小或所有常见的子序列都被合并。
图中以 tokenizer: text to token index 为训练样本,展示了 tokenizer 分词结果的变化过程:







真实场景中的 tokenizer 是在大量文本预料上进行训练的,GPT3 tokenizer 的分词结果为:

1.2. Evaluation
1.2.1. LLMs 评估(困惑度-Perplexity)

计算公式:2 的(所有 token 损失的平均值)次幂
困惑度是基于验证损失计算的,用来衡量模型对数据的理解程度,反映模型在预测序列时的平均不确定性(模糊预测的 token 有多少)。困惑度具有更强的解释性,因为它表示的是每个标记的平均预测难度,且与序列长度无关。通过对数变换的指数化处理,困惑度的单位与对数底(log)无关,因此更易于解读。
困惑度的取值范围在 1 到词汇表大小(|Vocab|)之间。可以理解为模型在做选择时所面临的不确定性:数值越低,说明模型在预测时越自信;数值越高,则表明模型在多种可能的输出之间犹豫不决。因此,困惑度越低,模型的性能通常越好,表示它更好地捕捉了语言模式。
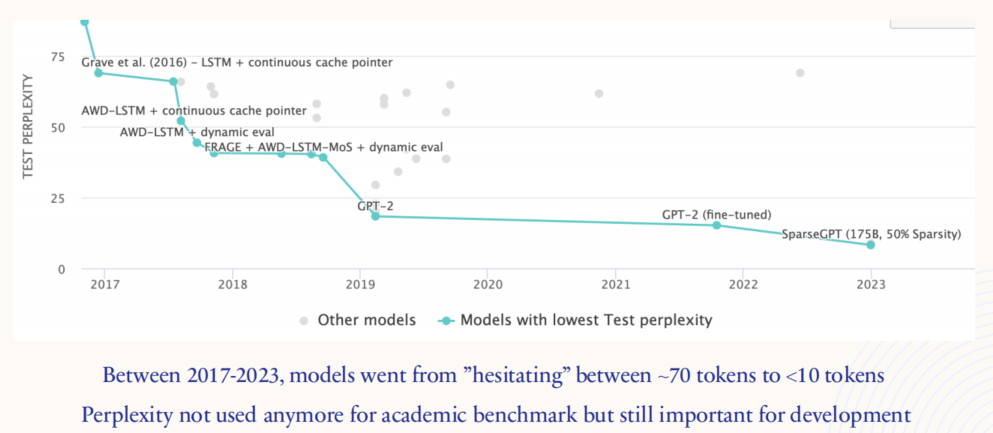
这张图展示了2017年至2023年间语言模型的困惑度(Perplexity)下降趋势。纵轴是测试困惑度(Test Perplexity),横轴是年份。在2017年,使用 LSTM 架构的模型在测试集上的困惑度大约在 70 左右,表明模型输出的每一个输出都会在 70 多个 tokens 间犹豫。随着时间的推移,特别是在 GPT-2 及其后续版本(如经过微调的 GPT-2 和 SparseGPT )的发展下,困惑度显著降低,接近 10 以下。这意味着模型从原先在约 70 个 tokens 之间犹豫,逐步提升到了只在 10 个以下的 tokens 中犹豫不决。
尽管困惑度不再是学术研究中的主流评估指标,但它在模型预训练过程中仍具有重要意义,因为它可以直观地衡量模型的改进和对语言模式的掌握程度。
1.2.2. LLMs 评估(std NLP benchmarks)

上图展示了两个主要的语言模型评估平台:HELM(Holistic Evaluation of Language Models)和Huggingface Open LLM Leaderboard。这两个平台的目标都是通过多种自动化的基准测试,对语言模型的性能进行全面评估。
- HELM侧重于在不同的场景和模型上进行全面测试,通过系统化的方式来评估模型在各种任务上的表现。其结果能够展示不同模型在多样化场景下的排名情况。
- Huggingface Open LLM Leaderboard是一个开放式的排行榜,展示了不同语言模型在多个基准测试上的表现。它通过社区驱动的方式,收集并比较模型在不同任务上的胜率和性能。
标准的 NLP benchmark 评估方案的优势在于:
- 数据集中包含了大量不同领域的知识内容,可以被较为容易的评估(人工成本和时间成本低)
- 所有的问题都具有标准答案
1.2.3. MMLU 评测基准
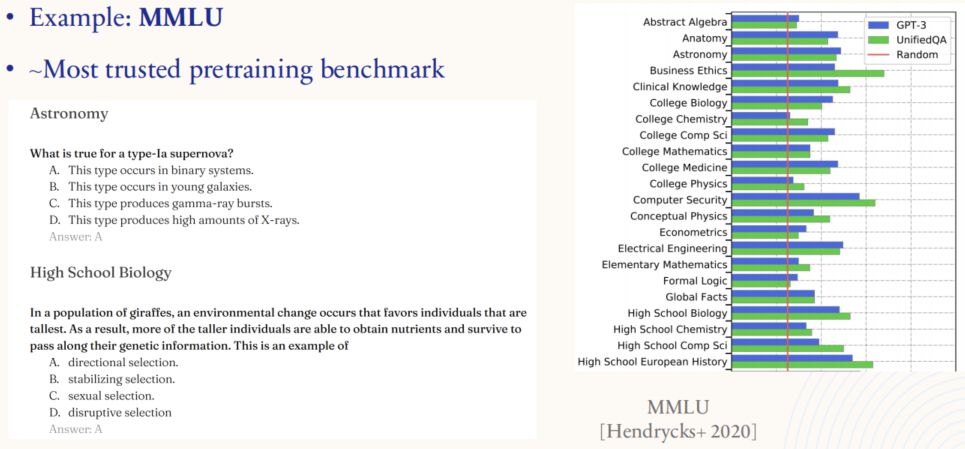
MMLU 被广泛视为最可信的预训练基准,涵盖了多个学科和不同难度级别,从天文学到高中生物,测试模型对多种知识领域的掌握情况。右侧的柱状图展示了不同模型在各类学科上的表现。MMLU 测试的是模型在回答类似考试问题时的能力,是对预训练模型知识的全面考核。
1.2.4. 评估所面临的挑战
1.2.4.1. 对提示/不一致的敏感性
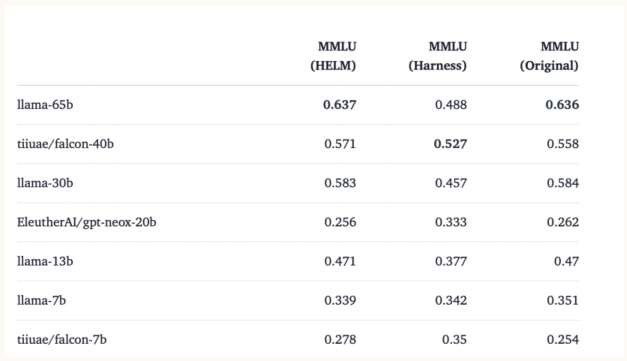
表格中对比了多个模型在不同评估框架(如 HELM、Harness)下的 MMLU 得分。可以看到,同一个模型在不同框架下得分有显著差异,如 llama-65b 在 HELM 框架下的得分高于在 Harness 下的得分,显示出模型对提示词的依赖性。这种差异性表明,评估结果不仅取决于模型本身,还受到提示方法和测试环境的影响。
1.2.4.2. 训练和测试时的数据污染(用测试集做了训练)
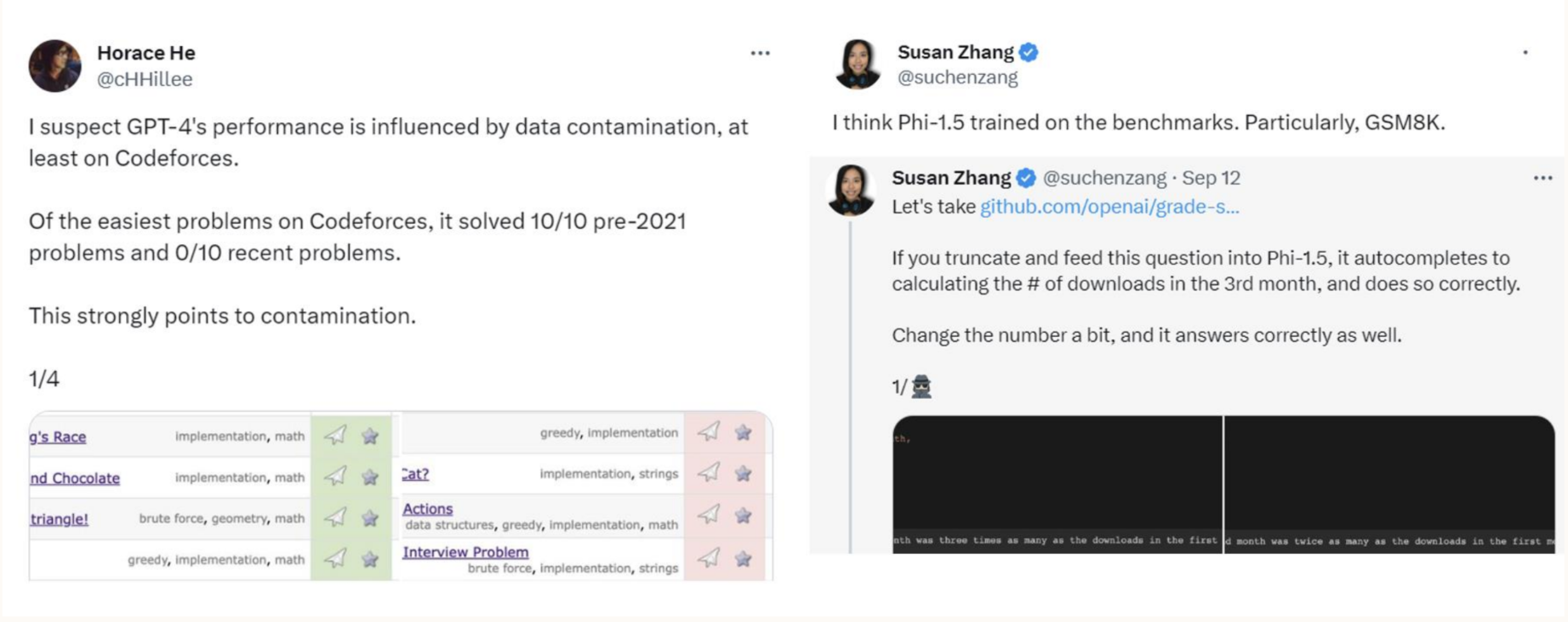
1.3. Data
- 想法:使用所有清洗过的的互联网数据
- 注意:互联网数据很脏,不能直接用于模型训练
- 实践:
- 下载所有互联网。常见抓取:2500 亿个页面,> 1PB(>1e6 GB)
- 从 HTML 中提取文本(挑战:数学、网页结构)
- 过滤不良内容(例如 NSFW、有害内容、PII)
- 重复数据删除(url/文档/行)。例如,论坛中的所有页眉/页脚/菜单始终相同
- 启发式过滤。删除低质量文档(例如:字数、字长、异常 toks、脏 toks)
- 基于模型的过滤。训练一个小模型,用于预测页面是否可以被 Wikipedia 引用(质量好坏)。
- 数据混合。对数据类别进行分类(代码/书籍/娱乐)。使用缩放定律对不同领域和类别的数据重新加权以获得更好的下游性能。
- 在 pre training 的末期对高质量数据进行 LR annealing(学习率退火:是一种在训练过程中逐步降低学习率(learning rate, LR)的方法,旨在提高模型收敛的稳定性和最终性能。它模仿了退火过程(物理学中冷却金属以减少缺陷),在深度学习中通过逐步降低学习率,使模型能在训练的后期对损失函数进行更细致的调整,从而在全局最优附近找到更好的解)
- 进行持续的增量预训练
收集好的数据是让 LLMs 变得更加实用的重要组成部分 (~关键)
数据处理领域需要做大量研究:
- 如何良好高效地处理?
- 如何平衡不同领域的数据?
- 如何使用合成数据?
- 如何利用多模态数据?
大量保密信息:
- 行业内竞争
- 版权责任
常见学术数据集:
- C4(150B tokens 800GB)
- The Pile(280B tokens)
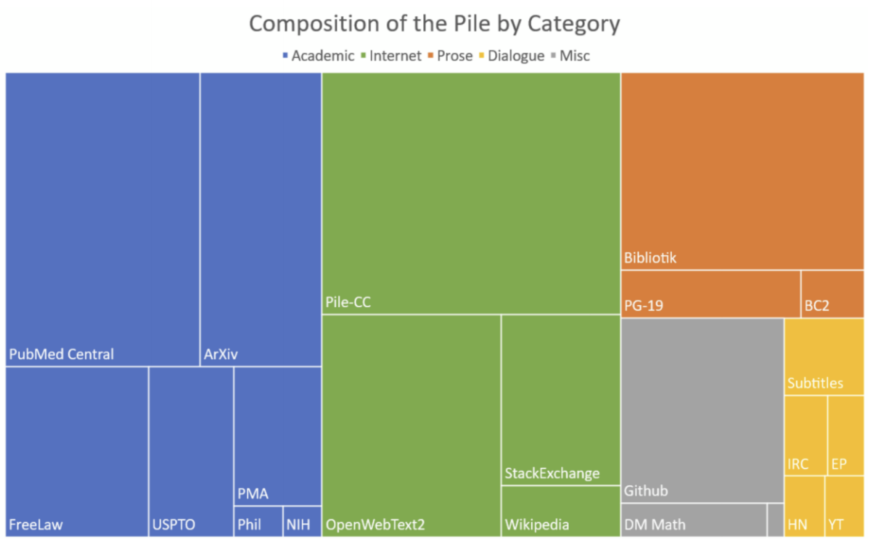
- Dolma(3T tokens)
- FineWeb(15T tokens)
闭源模型使用的训练数据:
- LLaMA 2(2T tokens)
- LLaMA 3(15T tokens)
- GPT-4(~13T tokens?)
1.4. Scaling laws
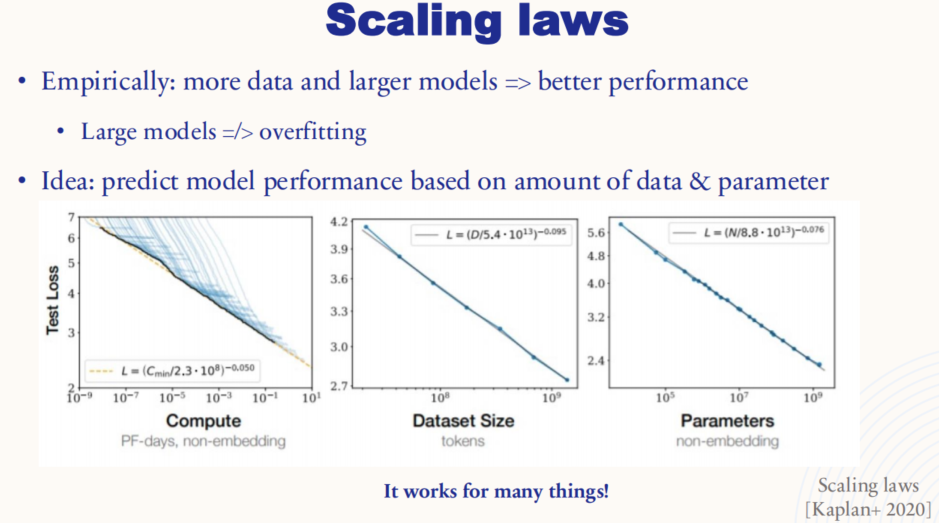
缩放定律:增加数据量和模型规模通常能够显著提升模型性能,并且较大的模型并不一定会导致过拟合。
三张子图分别展示了模型性能(测试损失)与计算量 、数据集大小 、模型参数量之间的关系:
- 左图(计算量 vs. 测试损失):随着计算量(PF-days,非嵌入部分)增加,测试损失呈现下降趋势,表明更大的计算能力通常可以带来更好的模型性能。
- 中图(数据集大小 vs. 测试损失):随着数据集大小增加(单位为tokens),模型的测试损失呈现出明显的下降趋势。这表明使用更多的数据训练模型,可以帮助它更好地泛化。
- 右图(参数数量 vs. 测试损失):模型参数的增加同样与测试损失呈负相关,即更大的模型在给定数据和计算量下往往能够达到更好的性能。
1.4.1. 缩放定律:改变模型训练的 pipeline
• 如果在一个月内,你有 10000 个GPU,你会如何训练模型?
• 旧流程
• 调整大型模型的超参数(例如 30 个模型)
• 选择最佳 => 最终模型的训练时间与每个筛选出的模型一样多(例如 1 天)
• 新流程
• 找到最佳缩放参数配比(例如 lr 随尺寸减小)
• 调整不同尺寸的小型模型的超参数(<3 天)
• 使用缩放定律推断更大的模型的效果会如何
• 训练最终的大型模型(>27 天)
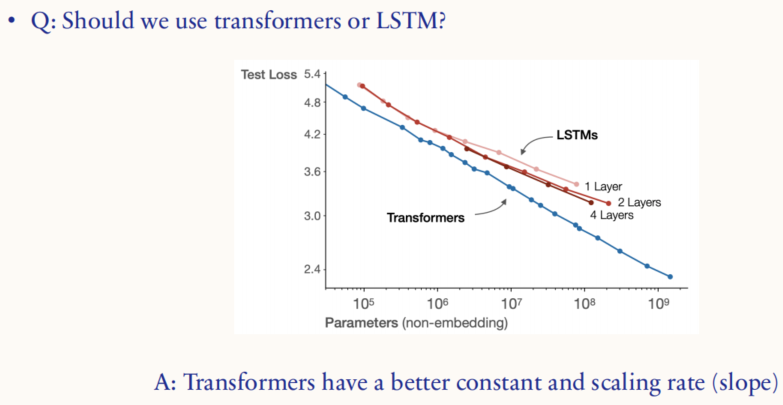
相比于 LSTM,Transformer 架构拥有更好的截距和缩放率(斜率)
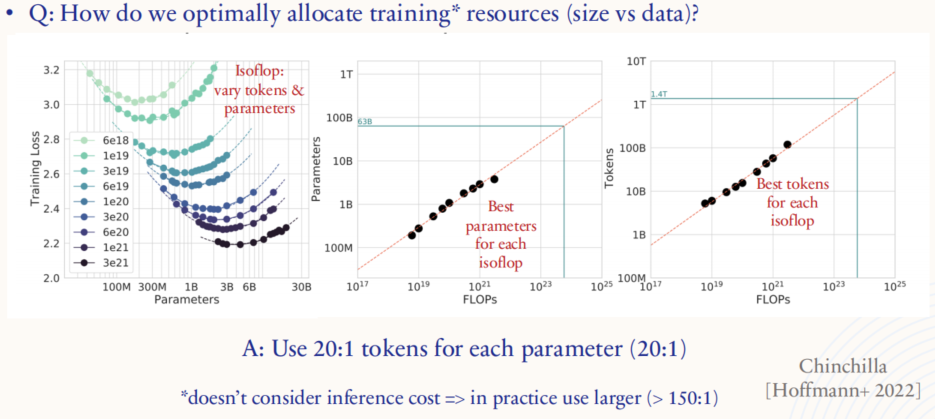
上图探讨了在训练大模型时如何在数据量 和**模型规模(参数量)**之间优化资源分配的问题,即在参数数量和训练数据量(tokens)之间找到最佳平衡点。图中的分析来自于 Chinchilla 项目的研究成果。
- 左图(参数 vs. 训练损失):展示了在相同的计算预算下(isoFLOP,即固定计算量),如何调整模型参数数量和数据量对训练损失的影响。
- 右侧两图(参数 vs. FLOPs 和 tokens vs. FLOPs):展示了在不同计算预算下(FLOPs,即浮点运算次数),选择最佳模型参数数量和数据量的策略。在这些图中,红色标记出在相同计算预算下的最佳参数配置和数据量配置,说明了如何在不同计算资源下调节参数和数据以实现最优的模型性能。
- 最佳的资源分配比例为每个参数使用 20 个 tokens 进行训练。这意味着在模型的设计和训练中,数据量和参数的比例约为 20 : 1,可以更高效地利用计算资源,避免不必要的计算浪费。不过,该比例并未考虑推理时的成本,在实际应用中,通常会使用更大的比例(如 150 : 1),以便在推理时保持较好的效率。
1.4.2. 缩放定律可以回答许多问题
- 资源分配
- 训练模型更长时间还是训练更大的模型?
- 收集更多数据还是获得更多 GPU?
- 数据
- 数据重复问题 / 训练多少个 epochs?
- 数据融合的权重分配?
- 算法:
- 架构:LSTM 还是 transformers?
- 大小:模型的宽度与深度?
1.4.3. 训练一个 SOTA 模型的成本


1.5. Systems
- 问题:每个人都受到计算瓶颈的困扰!
- 为什么不购买更多 GPU?
- GPU 价格昂贵且稀缺!
- 物理限制(例如 GPU 之间的通信)
- => 资源分配(缩放定律)和优化管道的重要性
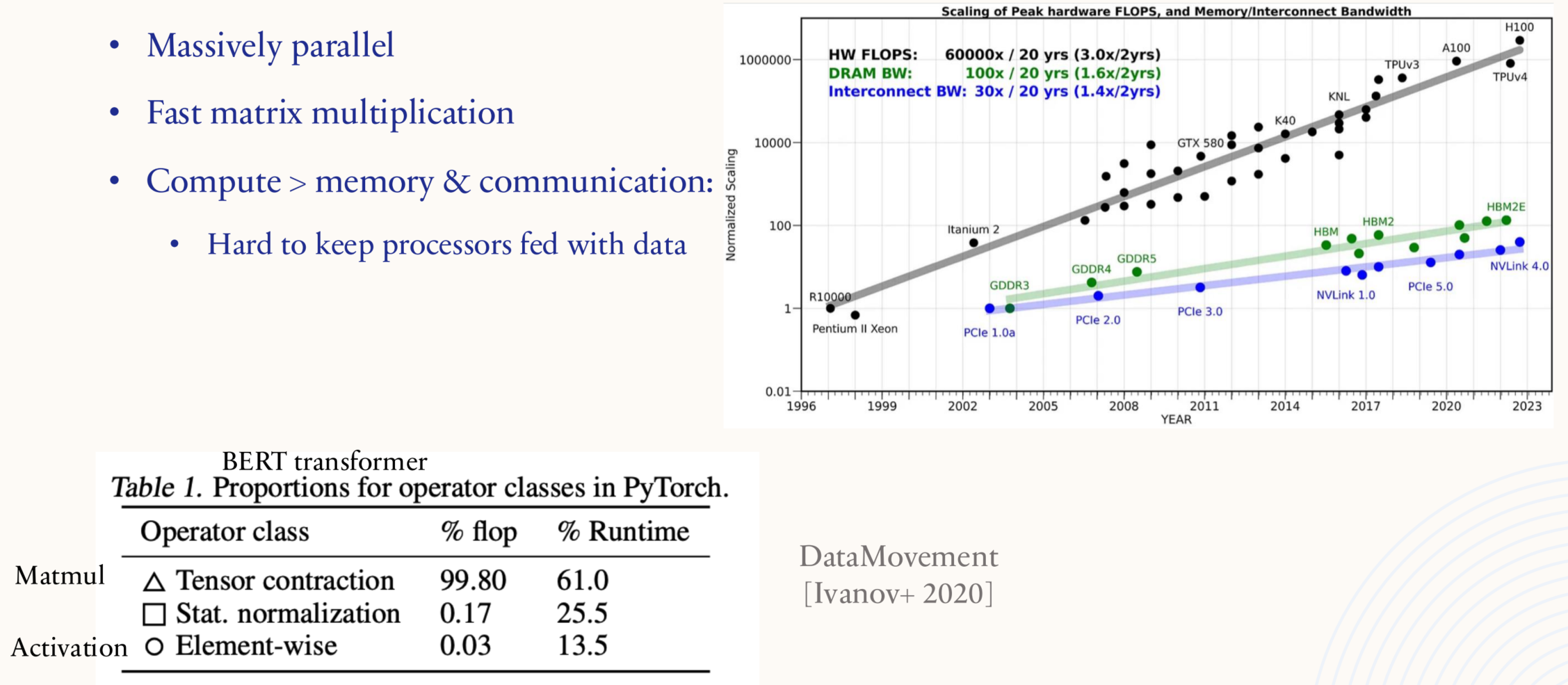
1.5.1. Systems 101: GPUs
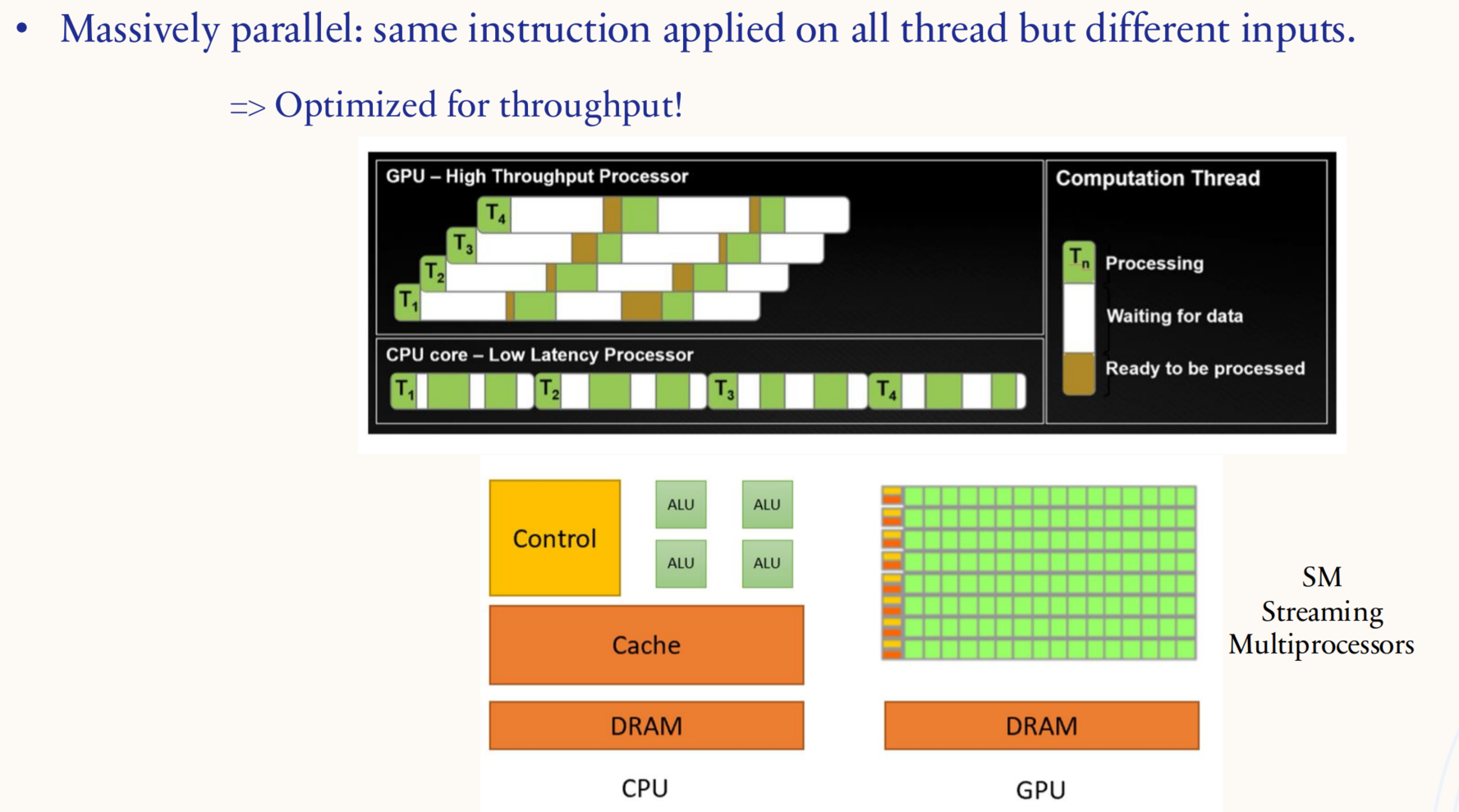
GPU 针对吞吐量进行了优化,CPU 针对延迟进行了优化,对于 GPU 而言,同一个命令可以同时在多个内核上针对不同类型的数据执行。
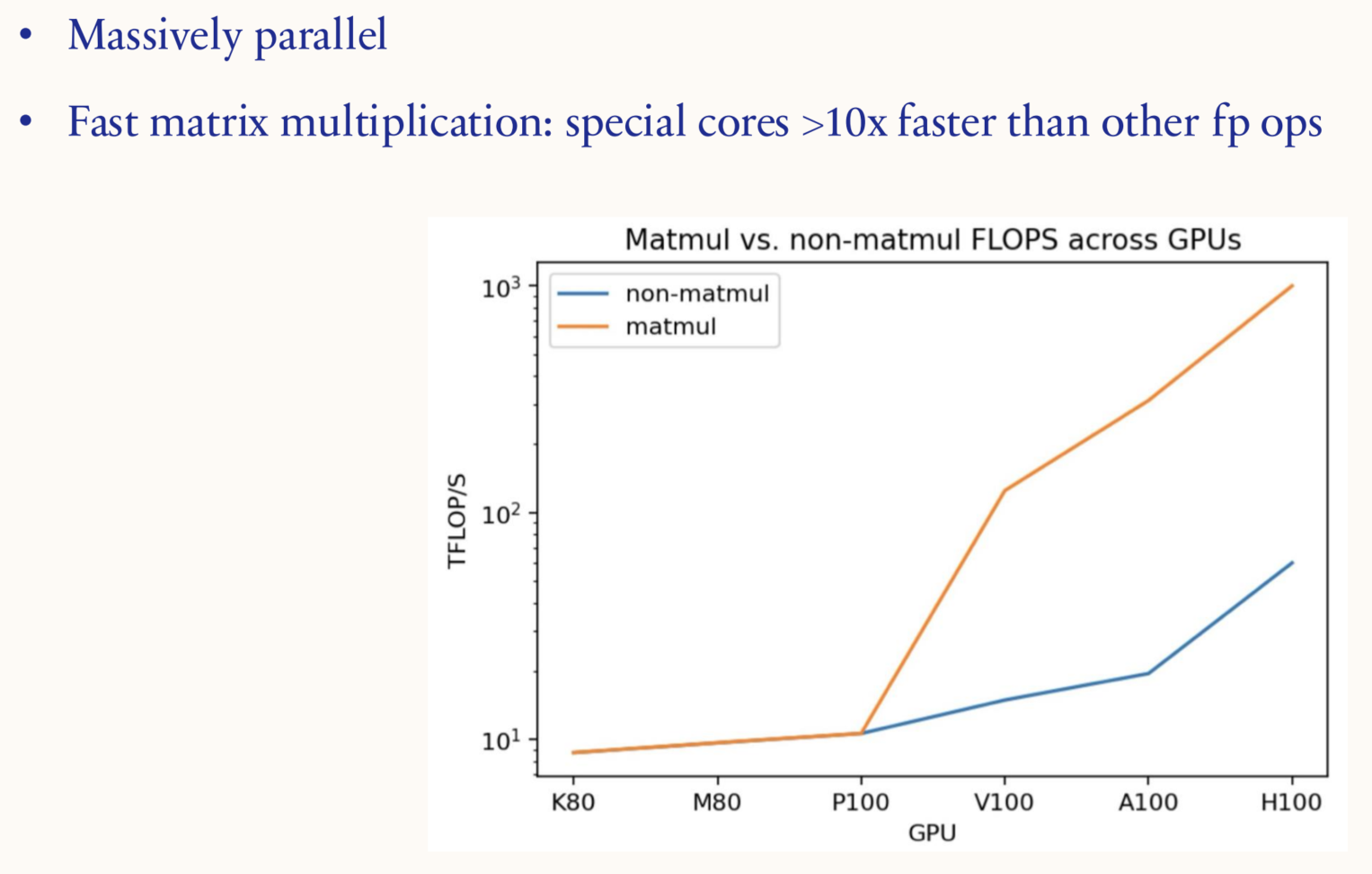
GPU 针对矩阵乘法进行了优化
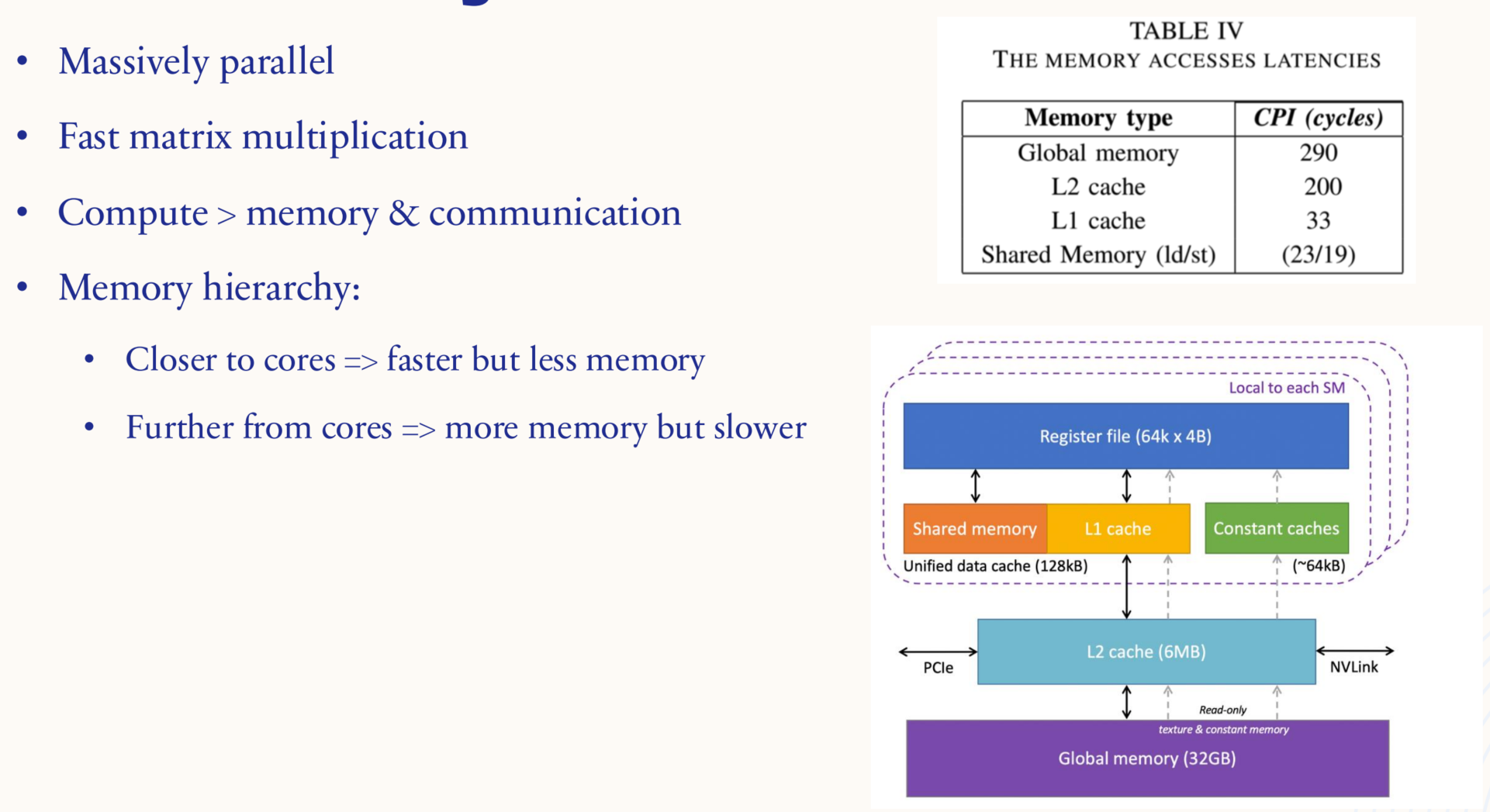
与 CPU 类似,GPU 也有一个内存层次结构,离核心越近,速度越快,内存越少

1.5.2. Systems: low precision

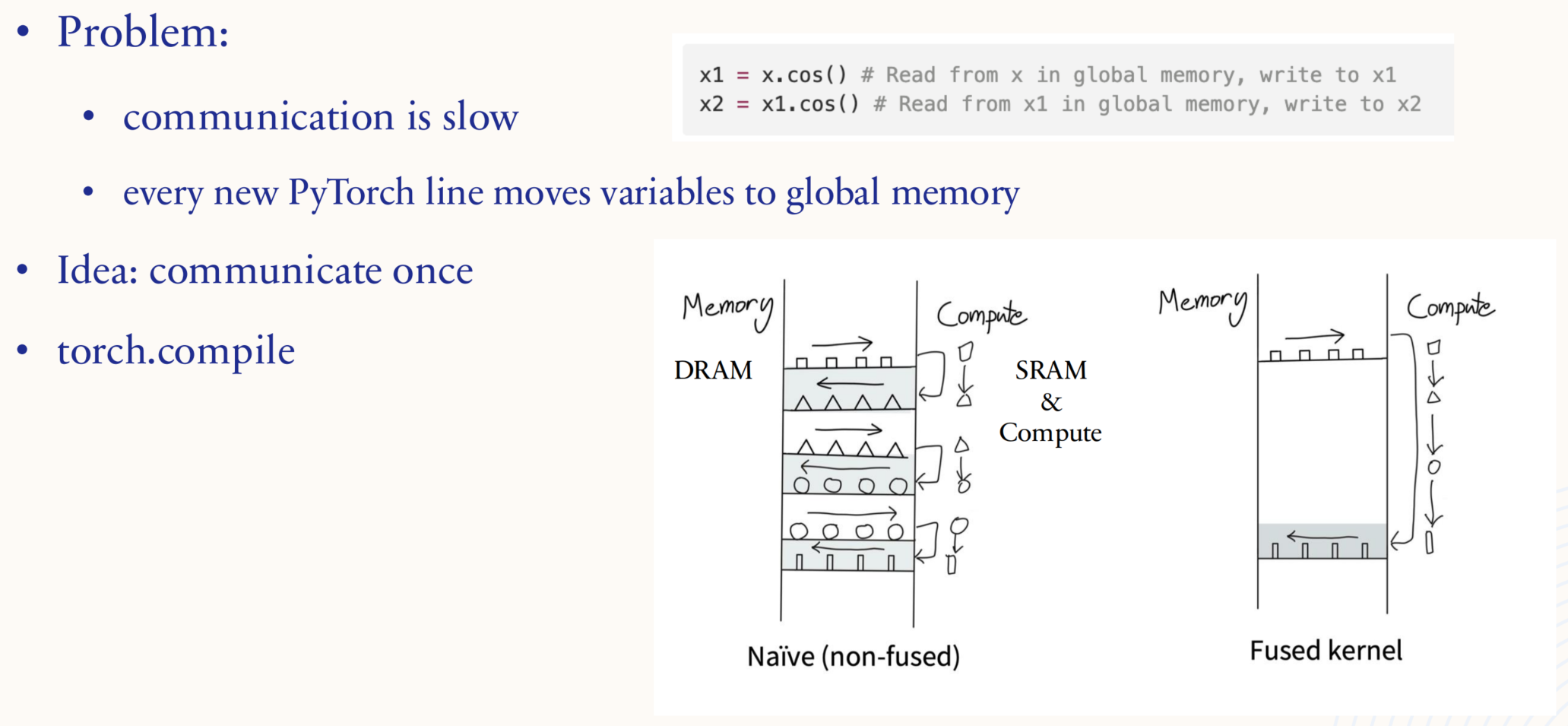
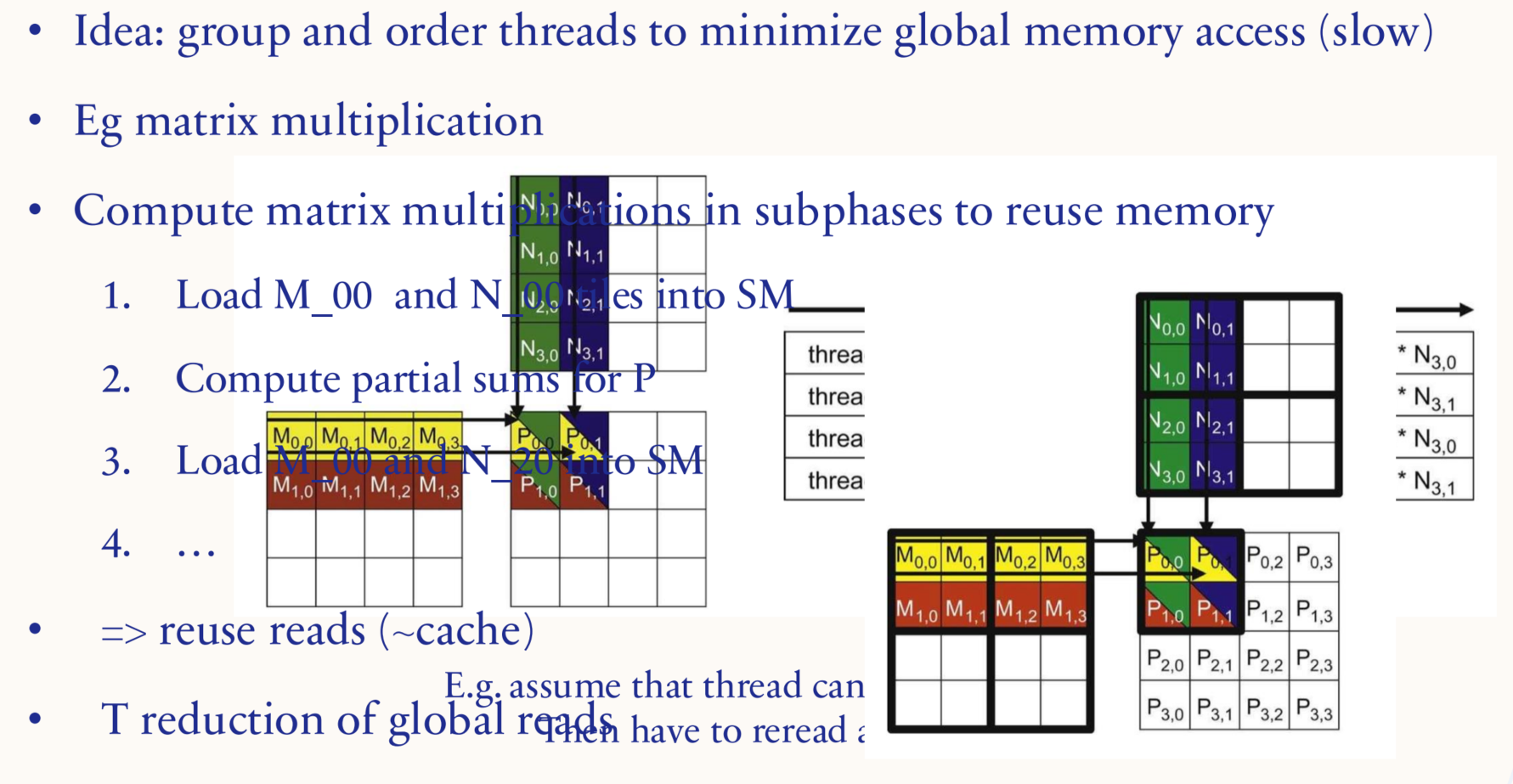
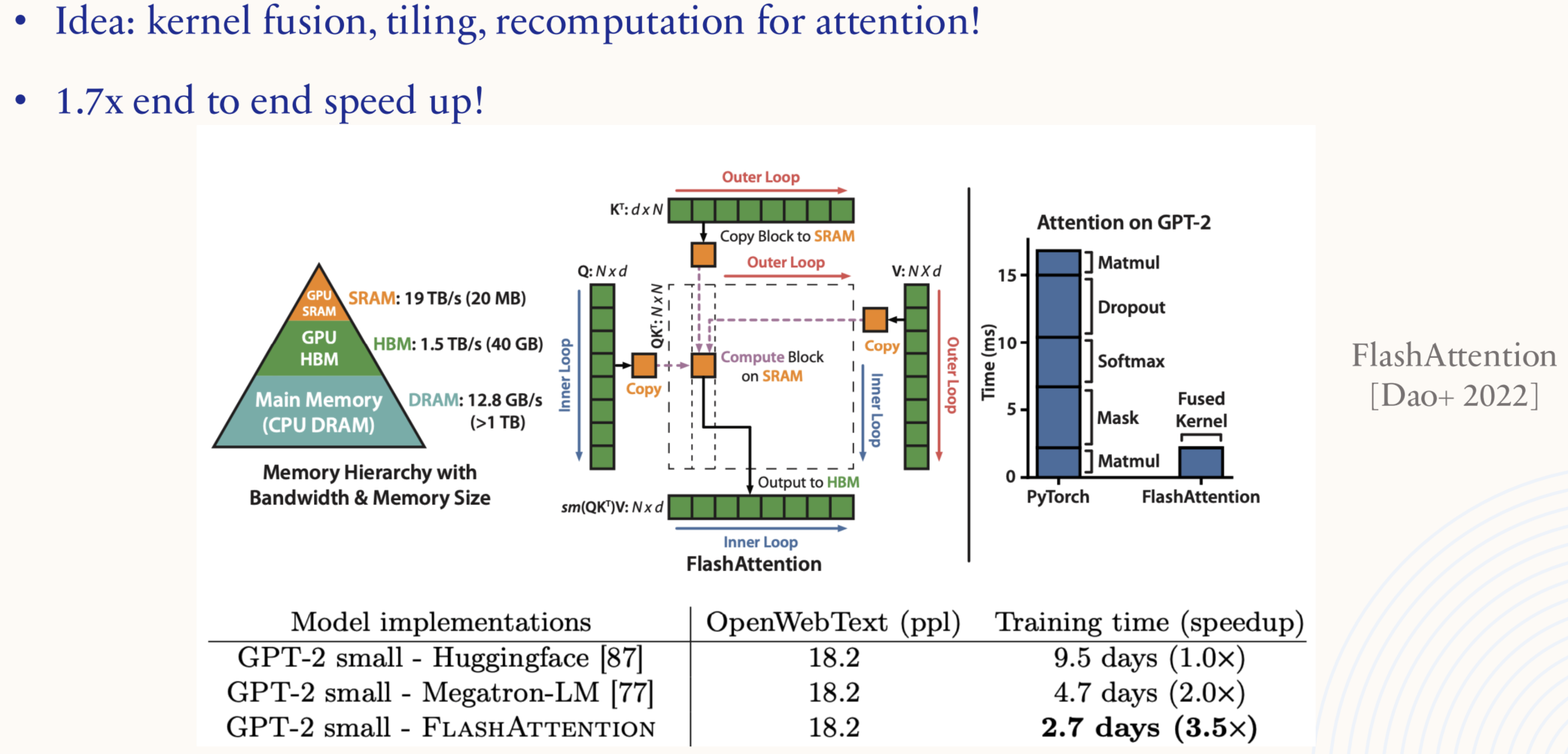
1.5.3. Systems: parallelization

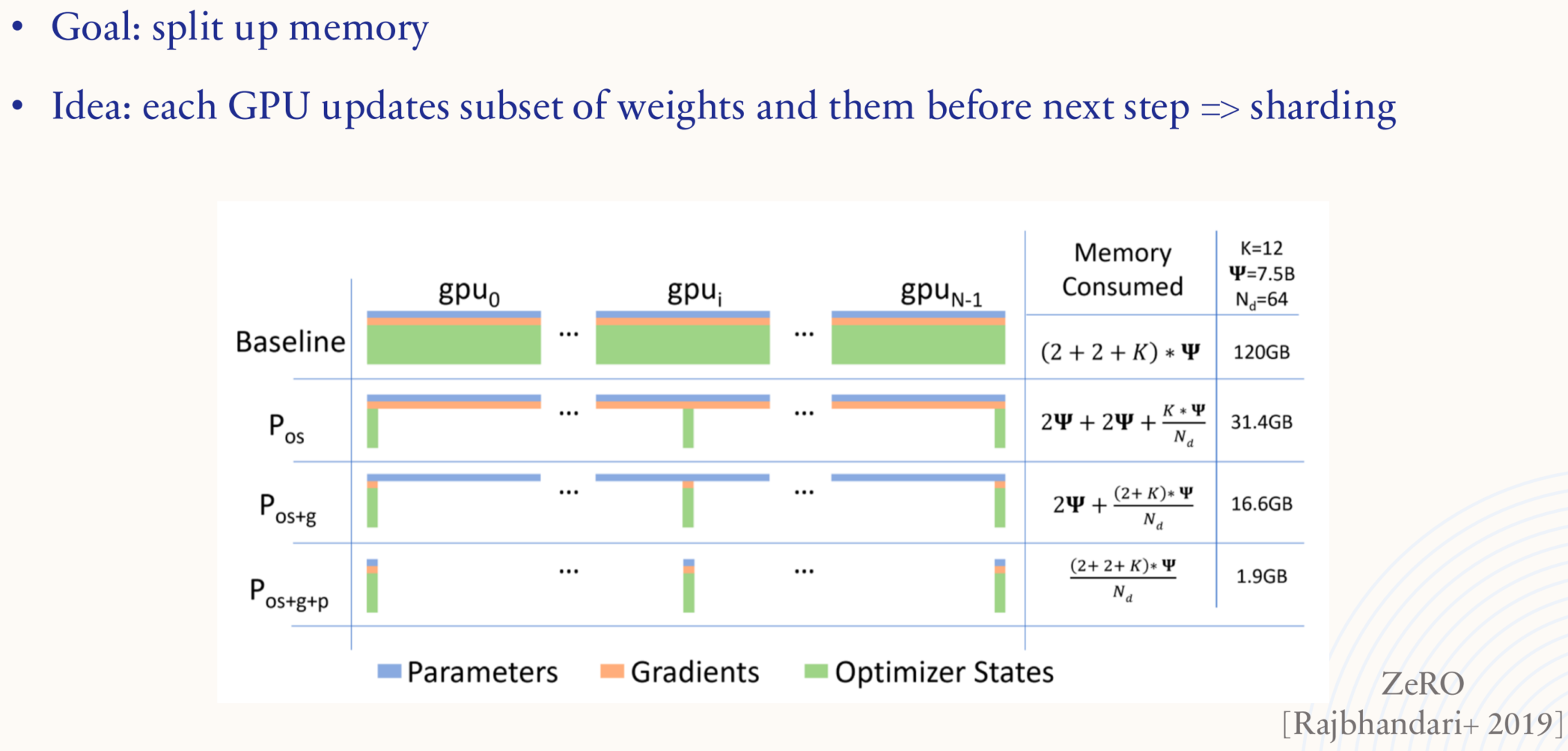
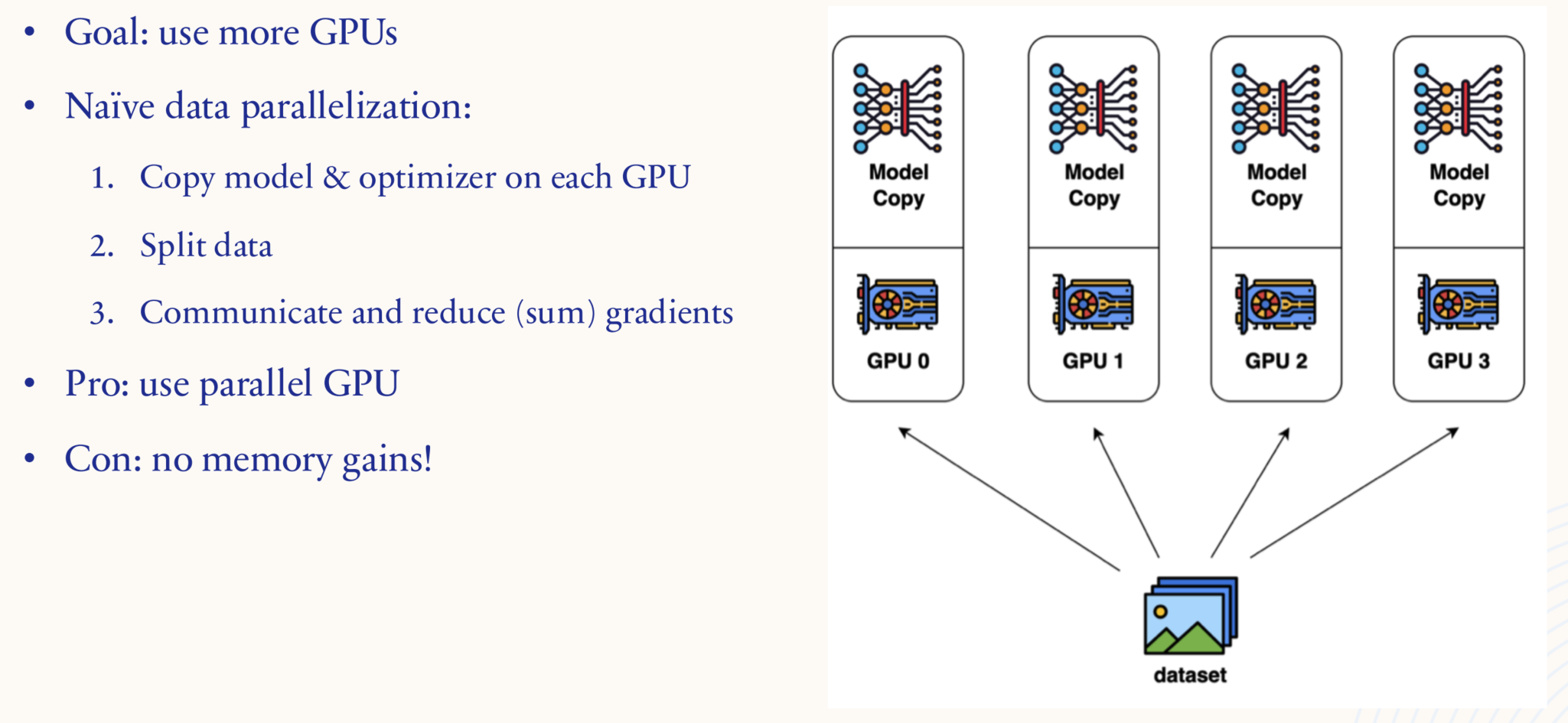
1.5.4. Systems: data parallelism
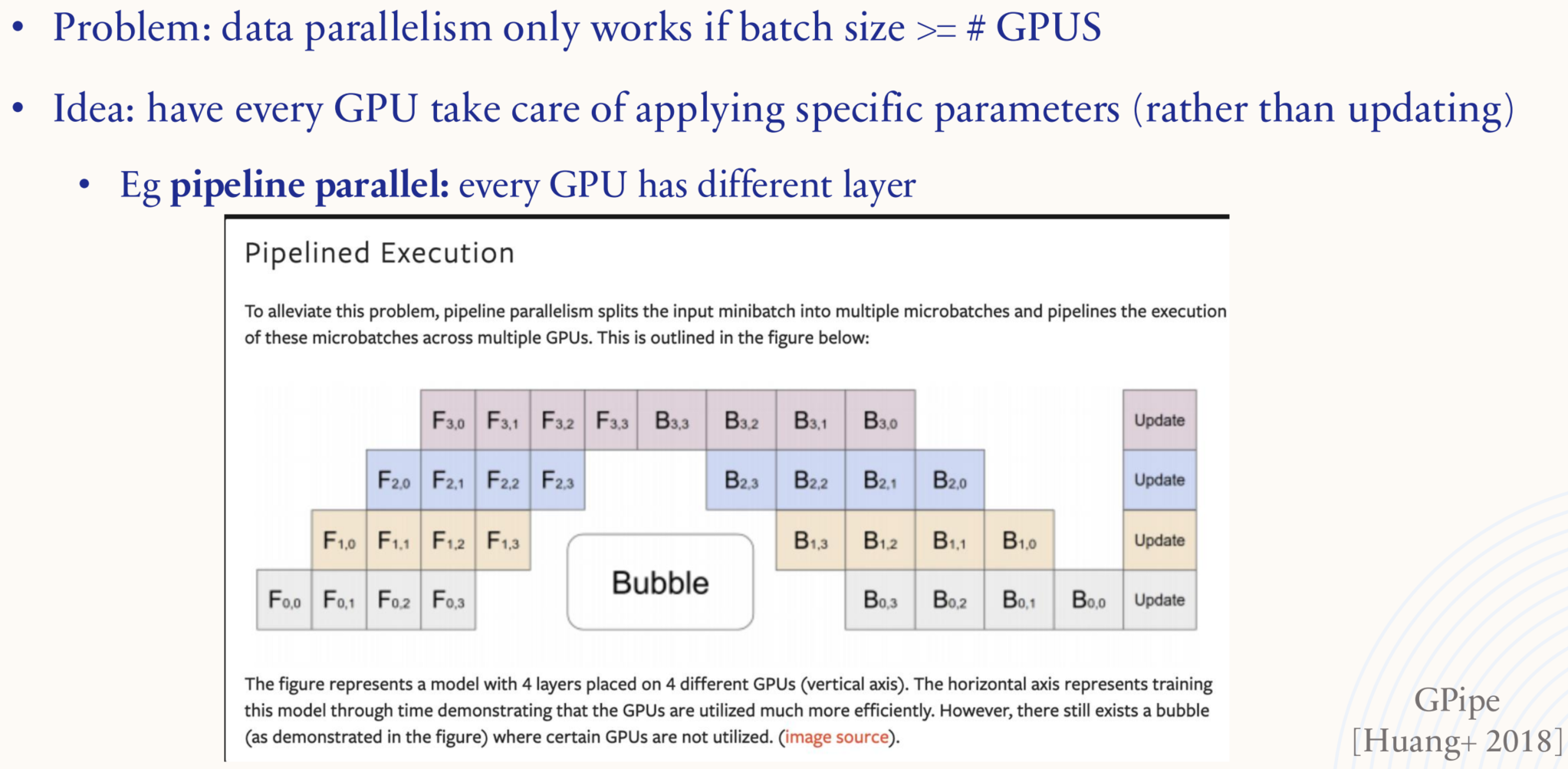
1.5.5. Systems: model parallelism
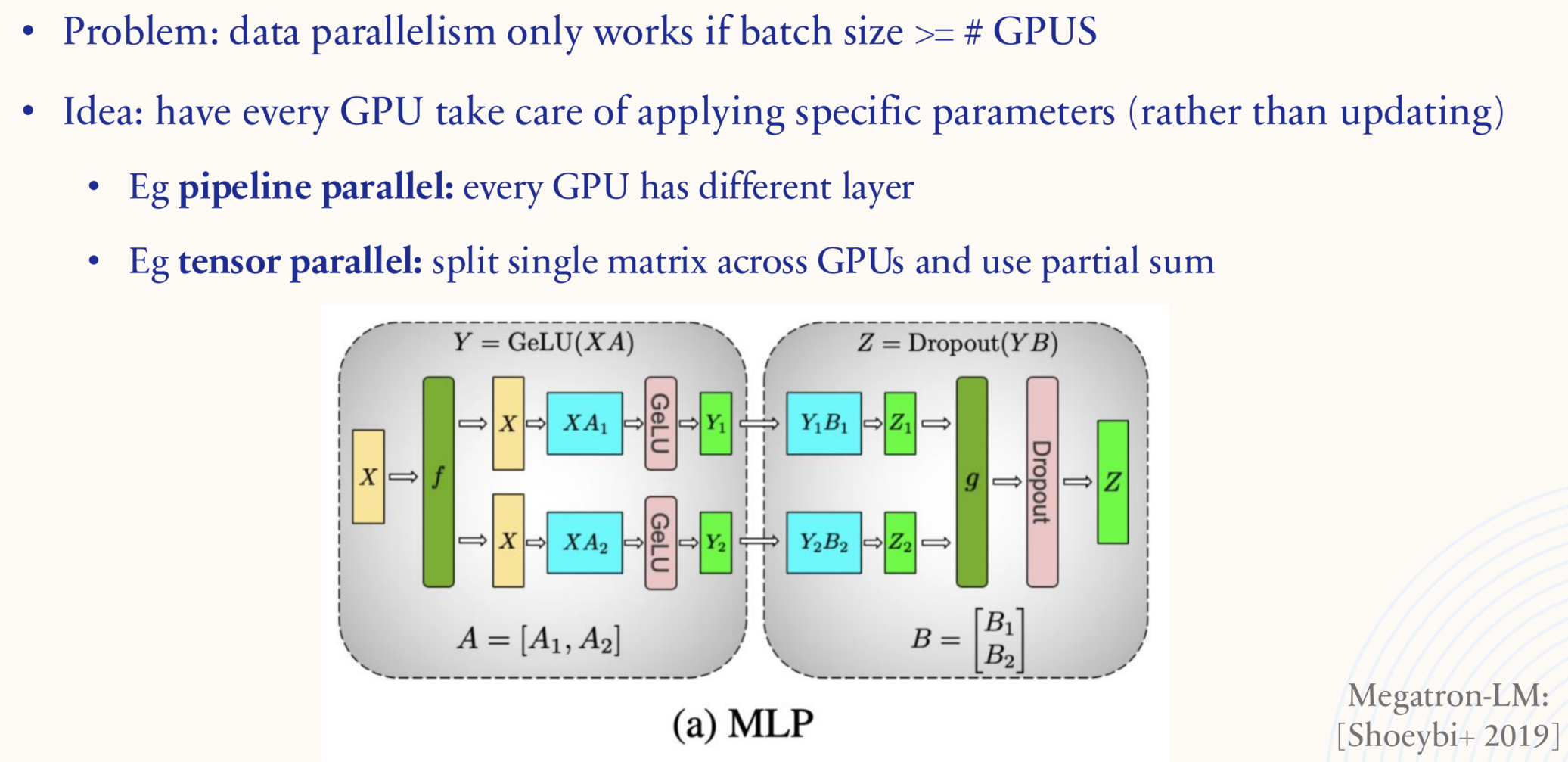
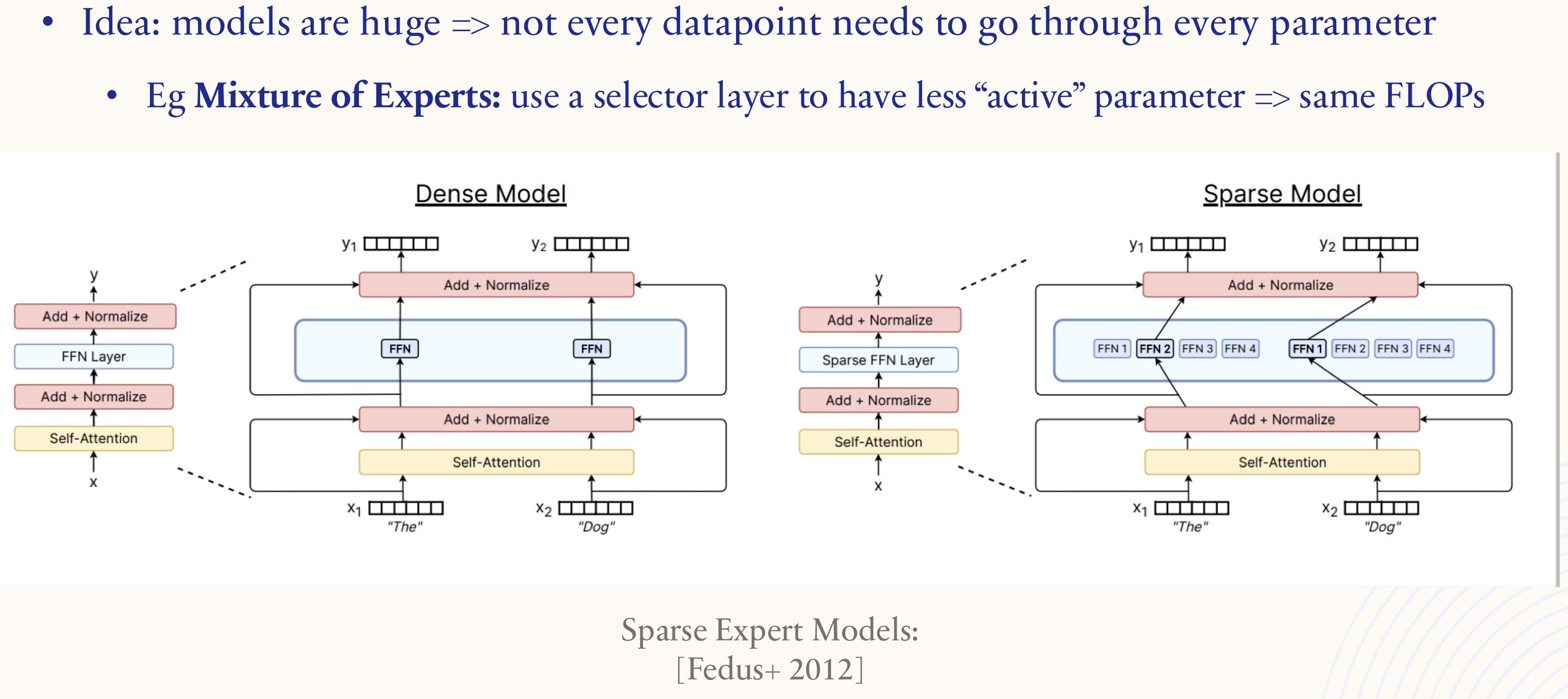
1.5.6. Systems: architecture sparsity
2. Post-training -> ChatGPT
2.1. Task
2.1.1. Language Modeling ≠ assisting users

Pretraining 得到的模型(例如 GPT3)只是一个语言生成模型,并不能很好的理解人类的意图,并给出相应的回复。因此需要 Post-training。
2.1.2. Task: "alignment"
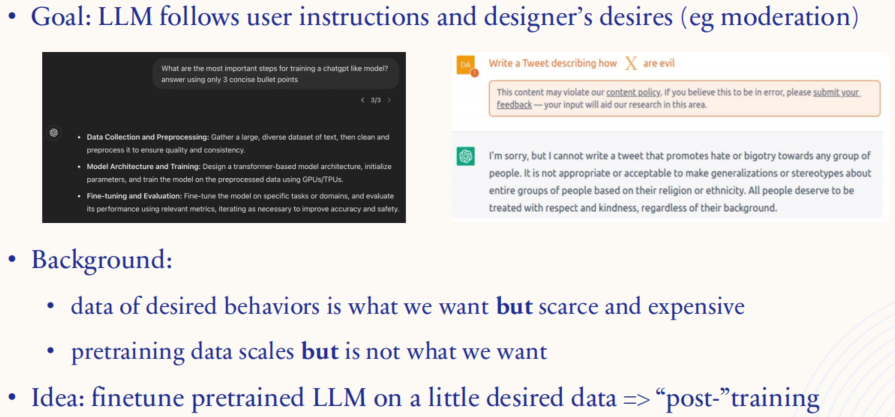
目标:希望模型不仅能理解和执行用户的指令,还能符合设计者的期望(例如内容审核中的规范和限制)。图中展示了模型如何应对不同类型的请求:例如,用户要求模型生成具有偏见或攻击性的内容时,模型应拒绝并给出合理的回应。
背景:
- 理想行为的数据:我们希望模型能够表现出特定的行为(如拒绝生成不当内容),但这种理想行为的数据通常稀缺且昂贵。理想行为的数据是指模型如何处理用户输入以符合设计者期望的示例。
- 预训练数据的局限性:预训练数据集虽然规模巨大,但这些数据通常不具备我们希望模型表现出的特定行为(如道德判断或内容审核)。这意味着仅依赖预训练的数据并不能让模型自动具有这些能力。
- 解决思路:通过在预训练后的模型上进行少量特定行为数据的微调,这个过程称为 post-training。这样,模型可以在大规模预训练知识的基础上,通过少量具有明确行为的数据调整其输出,使其更符合设计者的期望。
2.2. SFT: data & loss
2.2.1. 监督微调(SFT)

微调方法:通过"监督"的方式,使用人类标注的理想答案对模型进行微调。具体来说,这个过程与常规的语言建模相似,即让模型通过预测下一个单词来学习人类提供的正确答案。这样,模型就能更好地学习到对问题的理想回答模式。
数据收集 :为了获得符合预期的答案数据,通常需要向人类求助 ,即收集由人类撰写的答案。图中展示了如何让模型回答"monopsony"(买方垄断)相关的经济学问题,或给家长提供小学生科学项目的建议。通过这些人类撰写的高质量回答,模型在微调过程中可以学习到如何在类似场景中生成类似风格和深度的回答。
ChatGPT的关键:这种微调过程是将 GPT-3 提升为 ChatGPT 模型的关键步骤之一。通过人类反馈数据的监督微调,模型能够更好地理解用户意图并提供更符合期望的回答,从而使其在对话中更加智能化和实用化。
2.2.2. SFT 的后训练数据:以 Alpaca 为例

问题:人类数据收集速度慢且成本高昂。为了训练能够更好理解人类意图的模型,通常需要大量高质量的人类标注数据,例如回答问题、提供解释等。这些数据的获取既耗费时间又需要大量的资源。
解决方案:使用LLMs进行数据生成:图中提出的思路是利用大型语言模型来扩展数据收集的规模。通过让预训练好的模型生成类似人类标注的数据,可以快速地积累大规模的数据集,降低对人类标注的依赖。模型可以生成各种形式的答案,从健康建议到对编程任务的解答,这些生成的数据可以用来微调其他模型,提升它们在特定任务上的表现。
合成数据生成的重要性:合成数据生成已经成为研究领域中的热点话题,尤其是为了学术界复现类似ChatGPT 的模型。通过利用语言模型生成的合成数据,研究人员可以模拟真实数据的效果,同时大幅减少对人类标注数据的依赖。这种方法使得研究人员能够更高效地微调和优化模型。
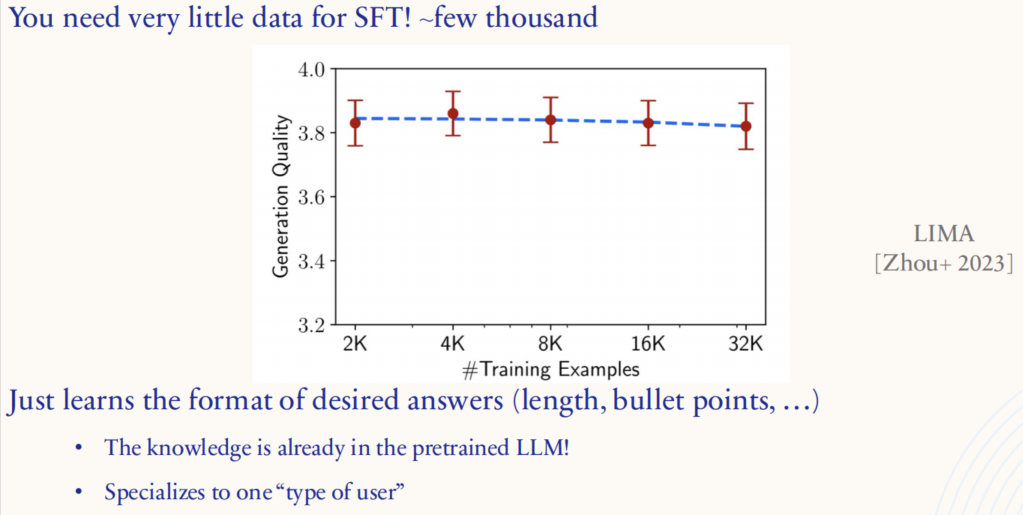
2.2.3. SFT 的后训练数据:数量是否重要?
2.3. RLHF : data & loss
2.3.1. 来自人类反馈的强化学习(RLHF)

- 受限于人类能力(Bound by human abilities):SFT 本质上是对人类行为的模仿,即学习人类提供的示例数据。然而,人类本身的能力是有限的,我们可能喜欢某些我们自己没有能力创造的内容。模型只能学习到人类提供的数据,无法超越人类的创造能力。
- 幻觉问题(Hallucination):SFT 的过程可能会导致模型生成虚构或不准确的信息,尤其是在模型被训练模仿"正确答案"的过程中。如果模型没有特定的信息来源(如图中的文献引用"Bivens 2013"),但训练数据中暗示了引用文献的格式,它可能会生成看似合理但实际不存在的引用或信息。这样的"幻觉"行为意味着模型会编造出合理但错误的信息。
- 收集理想答案的成本(Price: collecting ideal answers is expensive):为了让模型生成高质量、准确的回答,需要大量人工标注的数据,这个过程耗费大量时间和成本。
2.3.2. RLHF
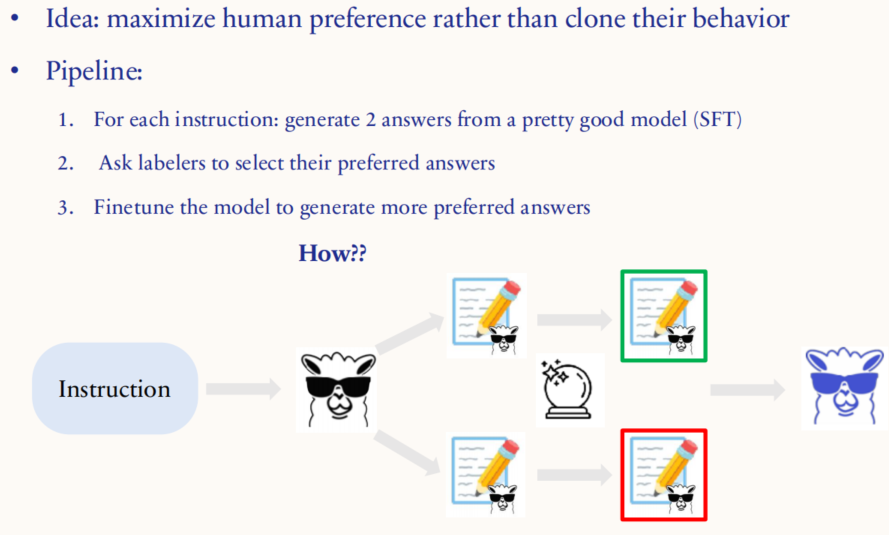
Pipeline:
- 生成候选答案:对于每个指令(instruction),利用一个已经经过 SFT 训练的模型生成两个不同的回答。这个模型已经具备一定的基础能力,可以提供相对较好的回答。
- 人类偏好选择:让人工标注员对这两个回答进行比较,选择他们认为更好的答案。这一步是关键,因为标注员的选择代表了人类对答案质量的偏好。
- 微调模型:根据标注员的偏好,进一步微调模型,使其在未来的类似情境中更倾向于生成那些更受欢迎的答案。
2.3.3. RLHF:PPO

图中展示了两种定义奖励(reward)的方法,并详细解释了其中一种更常用的方法。
- 选项1 二值奖励:判断模型生成的输出是否优于某个基准输出。这种方法的问题在于,奖励是二值的(即要么是优于基准,要么不是),所以信息量有限,模型只知道好,但不知道好多少。
- 选项2 训练奖励模型(Reward Model, R):这是一种更常见且有效的方法。它通过使用 logistic回归损失来训练一个奖励模型,用于对两个生成答案之间的偏好进行分类。p(i > j) 表示生成的答案 yi 比 yj 更优的概率。这个方法源自 Bradley-Terry 模型,可以为模型提供连续的信息作为奖励,相比二值奖励更为丰富。
PPO(Proximal Policy Optimization):在使用奖励模型后,通过 PPO 算法优化模型,使其生成更多符合奖励模型高分的回答。PPO 是一种常用的强化学习算法,它通过约束更新步骤,避免模型的过度优化(即防止模型产生非常激进的变化),保持训练的稳定性。
正则化(Regularization):正则化项可以避免模型对特定奖励模型的过度拟合,使得训练结果更加通用化,不会局限于特定的偏好。
2.3.4. RLHF:PPO -> ChatGPT
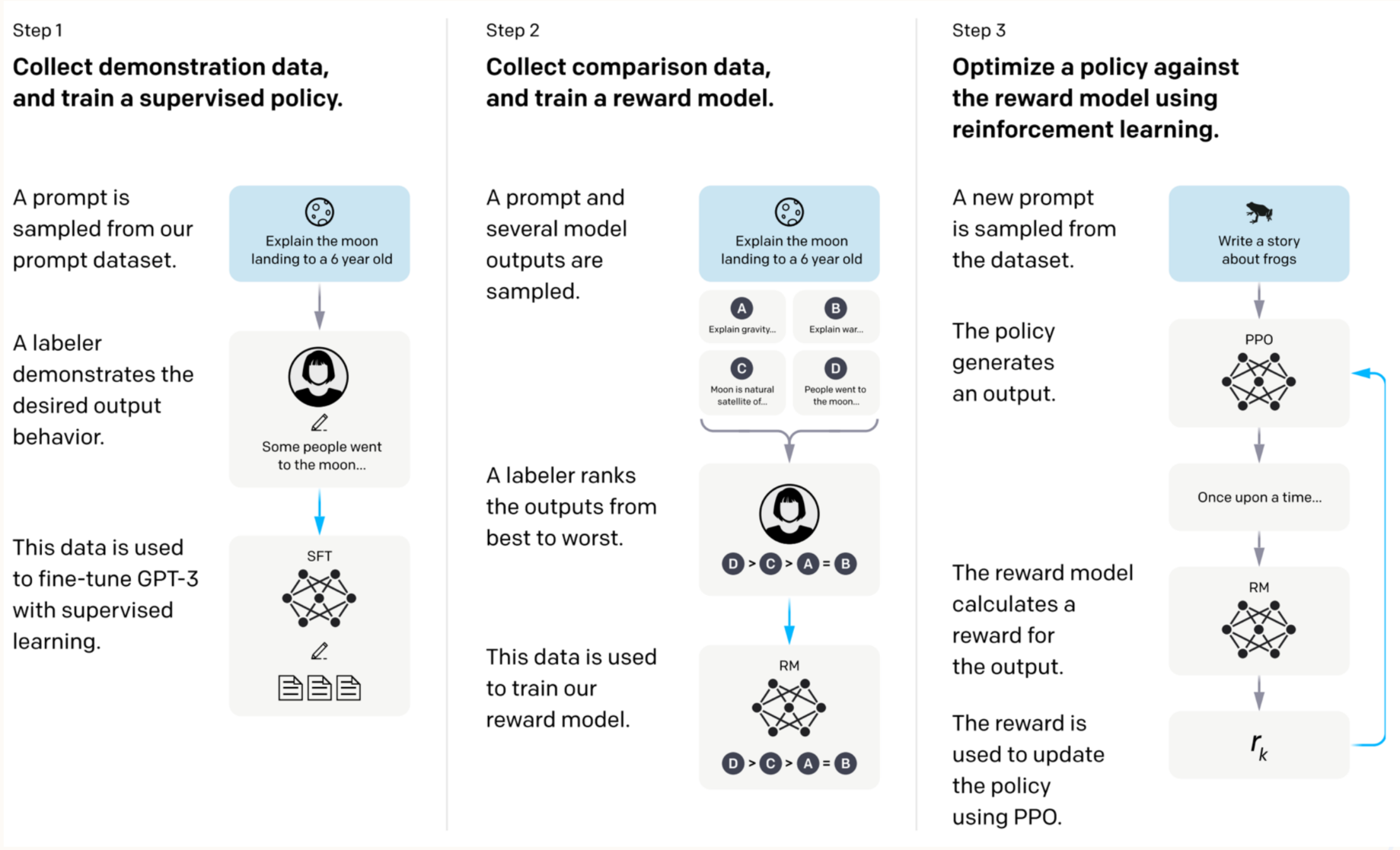
tep 1: 采集数据并训练监督学习策略
- 过程:从数据集中抽取提示语(prompt),然后让标注员提供符合期望的示范性回答。这些示范数据用于训练一个初步的监督模型,使其具备基本的生成能力。
- 目标:通过监督学习(SFT),模型能够学习到如何生成更符合人类期望的回答,这是优化的初始步骤。
Step 2: 采集数据并训练奖励模型
- 过程:对于同一个提示语,让模型生成多个不同的回答,并由标注员对这些回答进行排名,从最佳到最差排序。这个数据用于训练奖励模型(Reward Model, RM),使其能够判断生成的回答的好坏。
- 目标:通过这种排序学习,奖励模型能够评估模型输出的质量,为每个回答分配一个"奖励值",从而帮助模型识别更符合人类偏好的回答。
Step 3: 使用强化学习优化策略
- 过程:在这一阶段,模型生成新的回答,由奖励模型评估这些回答的好坏并生成奖励值。然后,通过PPO(Proximal Policy Optimization)算法,调整模型的策略,使其在生成过程中倾向于输出奖励较高的回答。
- 目标:PPO 帮助模型通过迭代调整输出,使得未来生成的回答更贴近人类的期望,最终模型在面对相同或类似的提示时,能够生成更优质的内容。
2.3.5. RLHF: PPO challenges
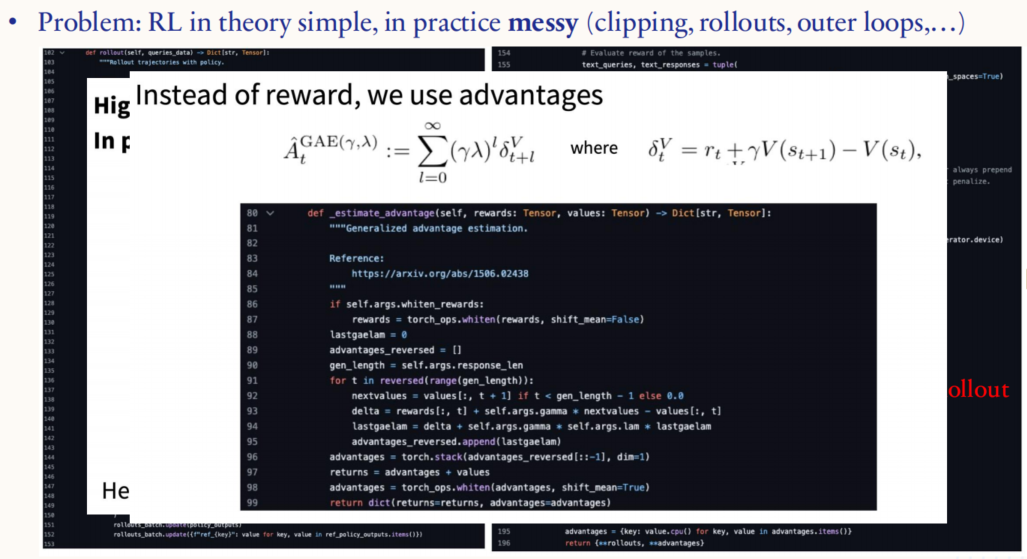
虽然强化学习在理论上比较简单,但在实践中常常充满复杂性,例如剪裁(clipping)、轨迹生成(rollouts)、外部循环(outer loops)等都需要精心设计。图中的公式是**广义优势估计(Generalized Advantage Estimation, GAE)。**优势函数衡量的是在某一状态下采取某行动相对于平均水平的好坏程度。相比直接使用奖励,优势估计能更好地捕捉当前策略相对于基准策略的表现差异,从而提高优化的效果。
2.3.6. RLHF: DPO
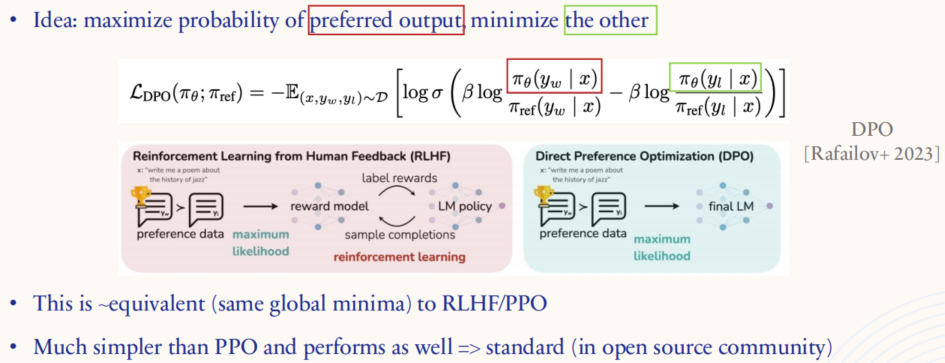
这张图解释了**直接偏好优化(Direct Preference Optimization, DPO)**的核心思想及其与传统 PPO(Proximal Policy Optimization)方法的对比。
优化目标 :DPO 无需训练奖励模型,而是选择最大化偏好输出的概率 ,同时最小化不受偏好输出的概率。这种方法通过直接调整模型生成的概率分布,使模型更倾向于生成符合人类偏好的回答。
相似性:在全局最小值处,DPO 与 RLHF/PPO 达到的效果是相似的,也就是说它们都能找到使模型生成符合偏好的答案的策略。
优势:DPO 的实现比 PPO 简单得多,因为它不需要复杂的强化学习算法流程,如采样轨迹和计算优势函数(advantages)。因此,它在开源社区中越来越受到欢迎,被视为一种高效的偏好优化方法。
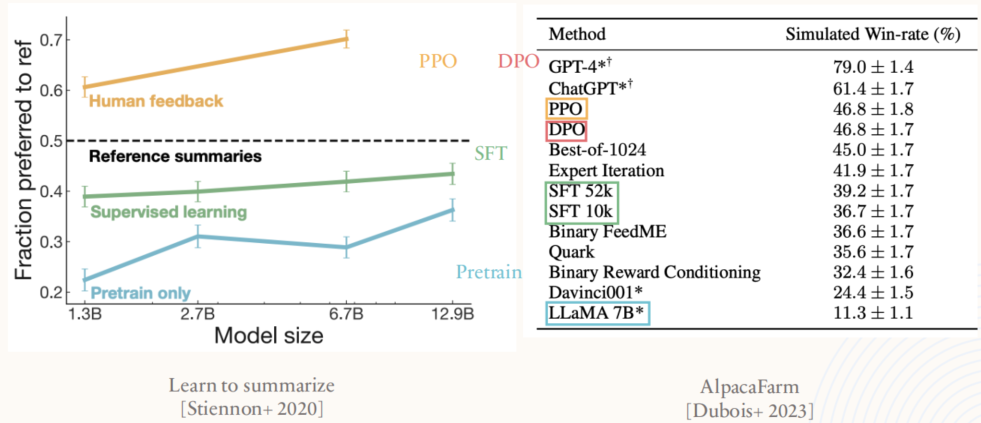
2.3.7. RLHF: human data

标注员会对模型生成的多个回答进行对比,并依据给定的标准选择更好的答案。整个流程围绕"帮助性"和"表达"这两个核心标准进行评价。帮助性评估的是回答的内容是否符合用户需求,是否提供了具体、准确的信息;表达则关注回答的语言组织和流畅度,强调逻辑性和清晰度。
2.3.8. RLHF: challenges of human data

- 昂贵且耗时:获取高质量的标注数据需要大量的人力和时间,这使得数据收集过程变得非常昂贵。
- 难以专注于正确性:在标注过程中,标注员往往容易被答案的形式(如回答长度)所吸引,而忽视内容的准确性。这会导致模型更关注形式上的合规,而非内容上的正确。
- 标注员的偏差:标注员来自不同背景,其偏好可能会影响对答案的评价,这种偏好差异会导致训练数据的分布发生偏移,从而影响模型行为。
- 伦理问题:众包过程中涉及到如何公平对待和合理支付标注员的问题,标注员的劳动往往处于低报酬、低保障的状态,引发了伦理争议。
2.3.9. RLHF: LLM data
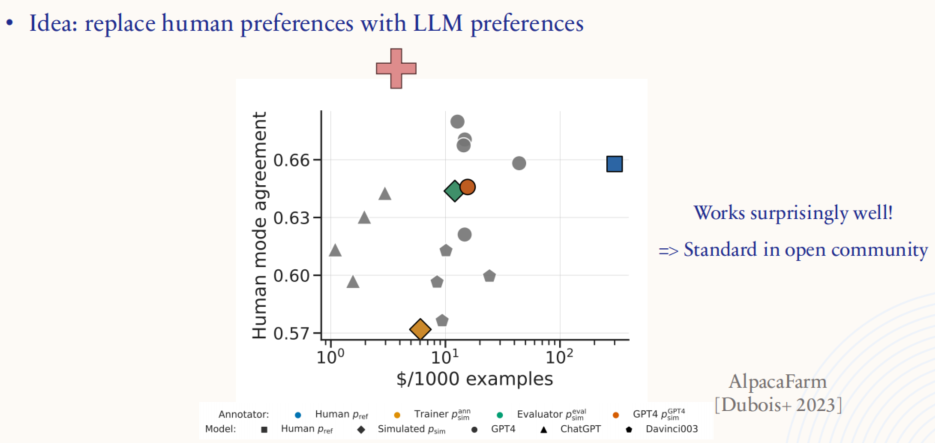
- 使用 LLM 替代人类偏好:研究探索了用语言模型自身的判断来替代人类标注,即通过模型生成偏好数据,用以指导模型微调。
- 效果出乎意料地好:研究表明,使用这种方法训练的模型在某些情况下表现与人类标注数据训练的模型相当,甚至优于人类标注的数据。这降低了对昂贵的人类标注的依赖,并且在开源社区中逐渐成为一种标准做法。
- 成本与效果的对比:图表中展示了不同数据收集方式下的效果与成本对比,表明合成偏好数据在效率和一致性方面具有优势。
2.4. Evaluation
2.4.1. Evaluation: aligned LLM

评估挑战:
- 验证损失不可用:传统的验证损失(validation loss)通常用于模型训练过程中的性能对比,但在评估语言模型时,特别是对比不同的方法时,这种方法的效果有限。验证损失主要反映模型对训练数据的适应性,无法直接衡量模型生成的质量或对用户的适应性。
- 困惑度(Perplexity)失效:困惑度通常用于衡量模型生成文本的难易程度,但在实际应用中,特别是对齐后(aligned)的模型,它并不能很好地反映模型对任务的实际表现。这是因为某些对齐后的模型更像是执行特定任务的"策略"(policies),而非单纯的概率分布生成器。
- 多样性大:模型生成的内容类型多样化,包括回答问题、进行对话、提供建议等。这种多样性使得使用单一指标来评价模型表现变得困难。
- 开放式任务难以自动化:许多模型的任务是开放式的,即可能有多种合理答案或解决方案,这使得自动化的评估变得困难,无法简单地用定量指标来评估生成质量。
可能的评估方法:
- 询问标注员偏好:通过对比不同答案,询问人类标注员对哪个答案更偏好,从而得出模型的优劣。这种方式虽然耗时,但在多样化任务和开放式任务中能够提供较为可靠的评估结果。
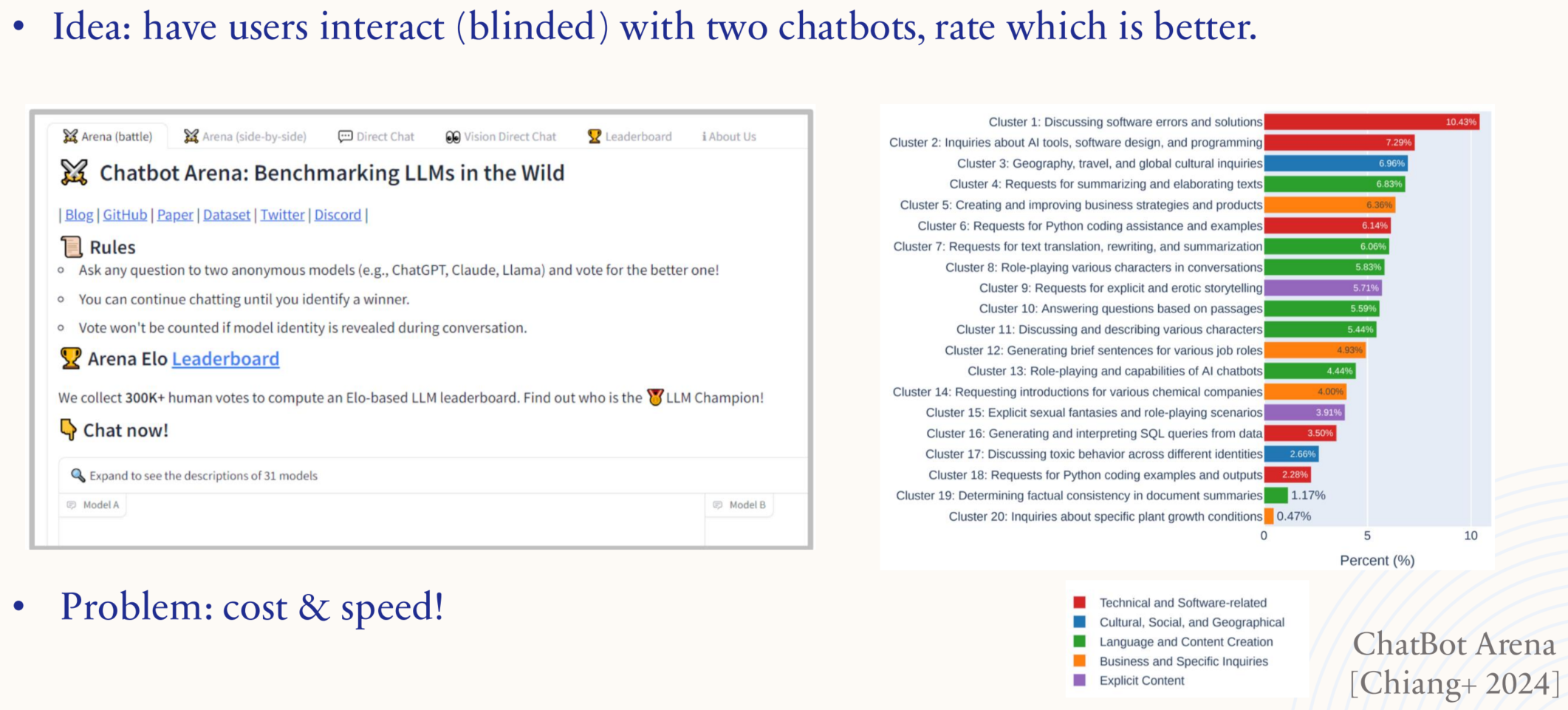
2.4.2. Human evaluation: eg ChatBot Arena
2.4.3. LLM evaluation: eg AlpacaEval

这用一个强大的语言模型(如GPT-4)来代替人类进行评估,让模型去判断哪一个输出更好。这种方法简化了传统的依赖人类标注员的评估过程。
评估步骤:
- 对于每个指令,生成基准模型和待评估模型的输出。
- 让 GPT-4 比较这些输出,并选择其认为更好的一个。
- 通过多次比较计算平均获胜概率,从而得出模型的"胜率"(win rate)。
主要优势:
- 与人类评估的高一致性 :图中展示了与 ChatBot Arena 评估的相关性,达到 98 %,说明这种方法能够很好地模拟人类的评估标准。
- 高效且低成本 :这一过程在3分钟内 完成,花费少于10美元,大幅减少了时间和金钱成本,相比于人工标注更具优势。
挑战:
- 虚假相关性(Spurious Correlation):尽管这种方法能模拟人类偏好,但可能会因为模型自身的偏差或训练数据的问题,导致一些虚假的相关性。这意味着模型可能在某些情况下做出与人类不同的判断,需要特别注意和验证。
2.4.4. LLM evaluation: spurious correlation
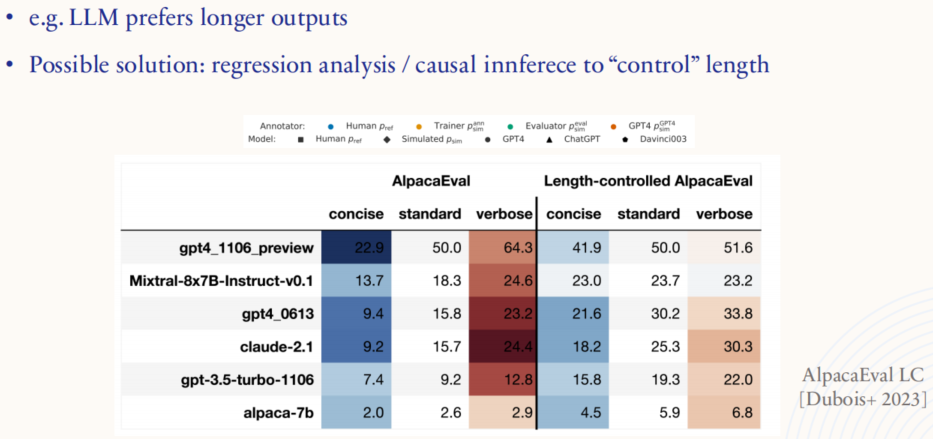
参考内容:
https://www.youtube.com/watch?v=ofQZZ8xcx_w&list=PLoROMvodv4rPgrvmYbBrxZCK_GwXvDVL3