缓存淘汰策略
生产上redis内存设置为多少
设置为最大内存的 3/4
redis 会占用物理机多少内存
默认大小是 0,64 位系统下表示不限制内存大小,32位系统表示 3G
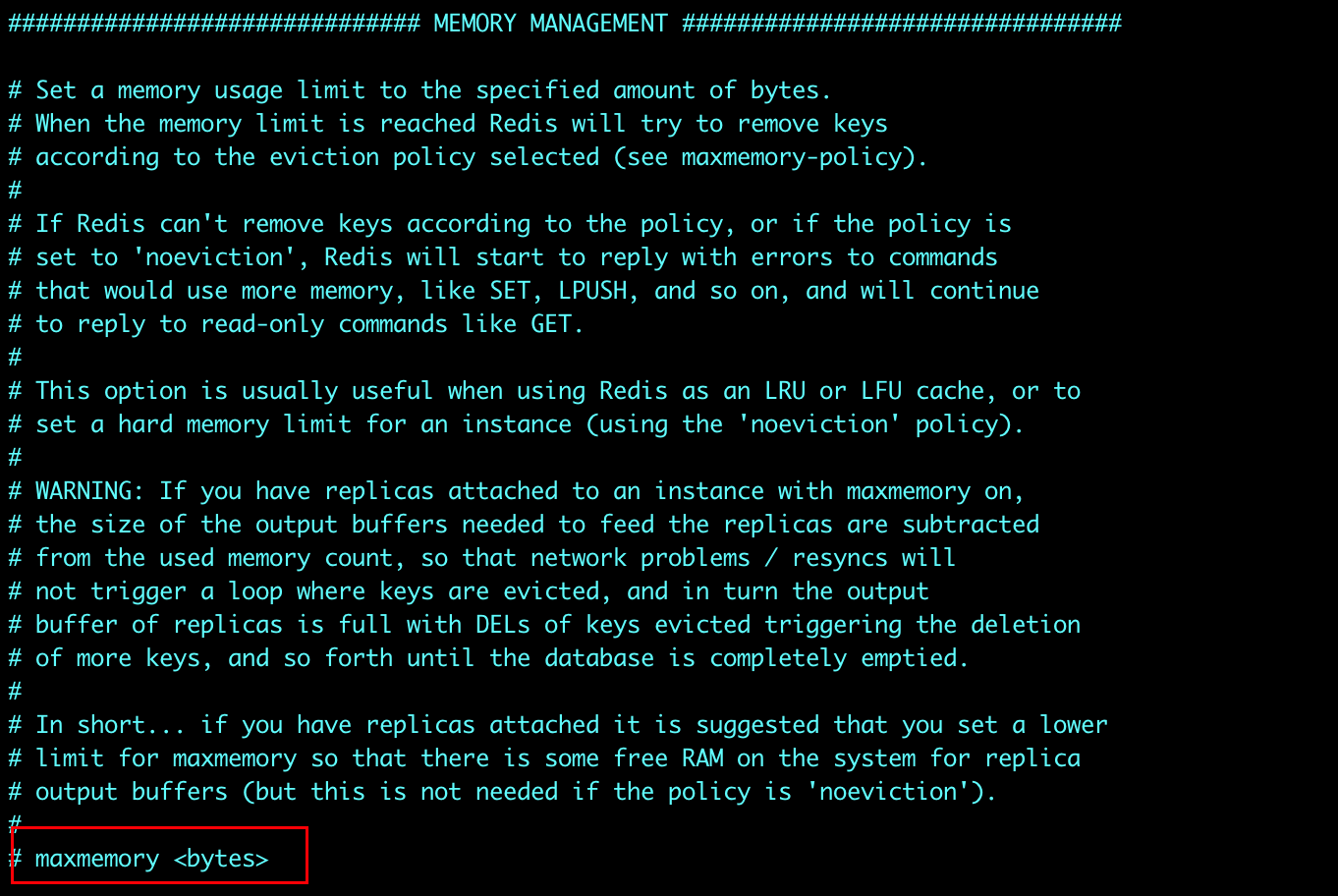
如何设置修改redis内存大小
- config get maxmemory 查看
- 修改方式
- 配置文件 单位是字节
2. <font style="color:#000000;">临时修改,重启后失效 config set maxmemory 104857600</font>如果redis内存满了会怎么样
redis 将会报错:(error) OOM command not allowed when used memory > 'maxmemory'
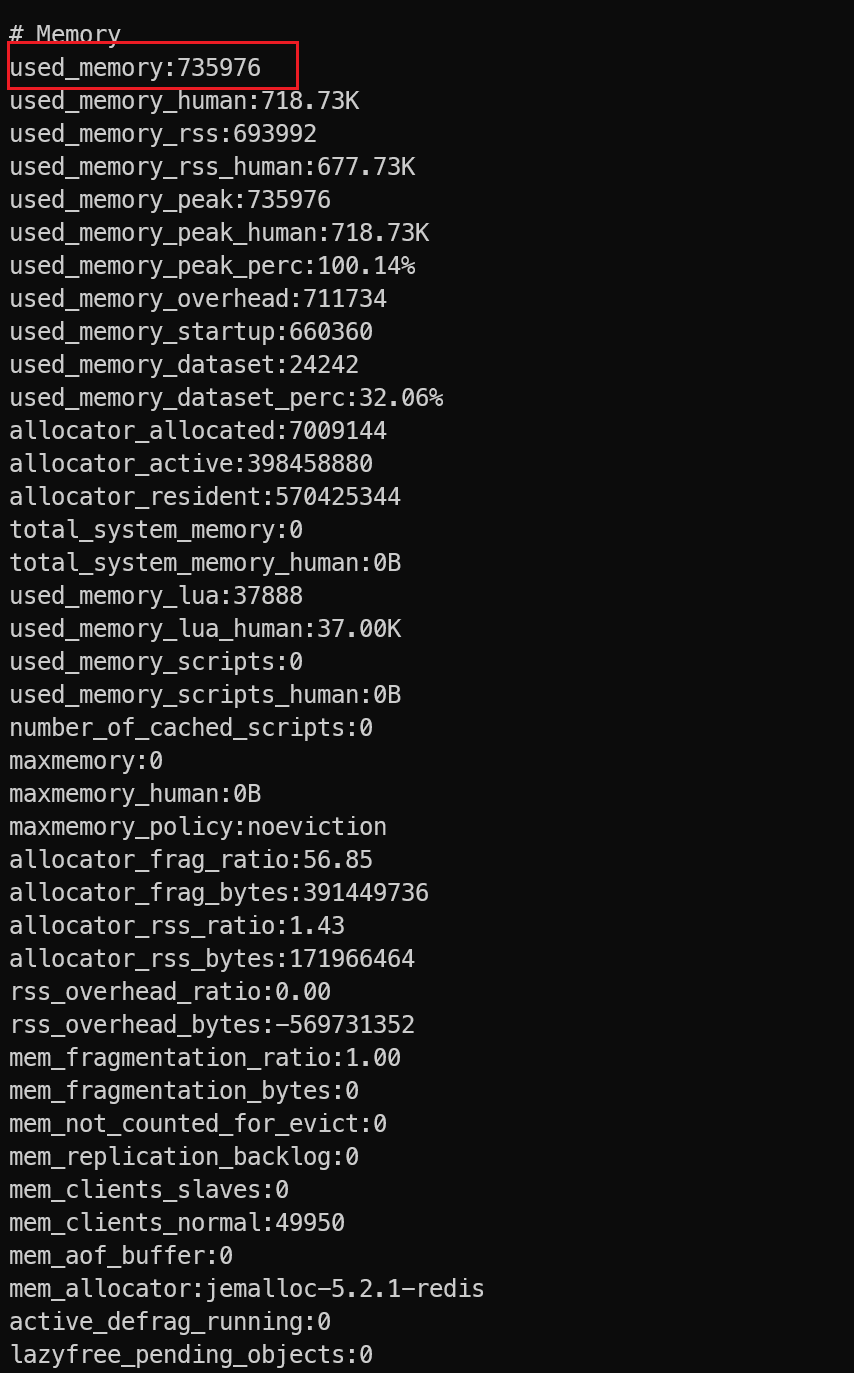
通过命令查看 redis 内存使用情况?
info memory
redis 对于过期 key 的三种不同删除策略
定时删除:创建kv的同时cpu会创建定时器,内存友好,cpu占用高
惰性删除:再次访问这个 key 的时候才会去检查过期时间,内存不友好

定时删除:每隔一段时间去抽样扫描一定(注意不是所有)数量的key是否过期,并可通过限制执行的频率和时长来控制对 cpu 的影响,折中,但可能存留较多过期key,并且需要根据具体情况合适的设置频率和时长
如果执行时间太长,退化成定时。太短则又会出现过期key太多
引出兜底方案,缓存淘汰策略
redis 缓存淘汰策略
8种内存淘汰策略
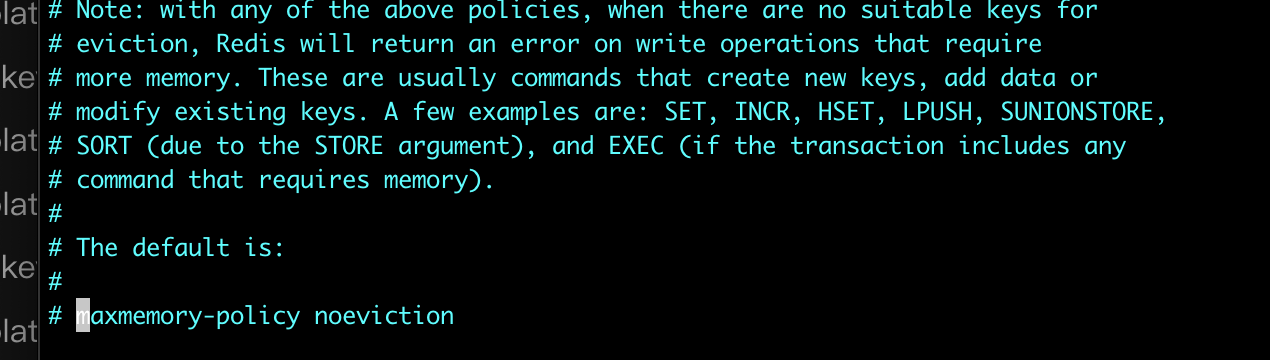
- noevition: 不操作 默认,看上面oom案例
- allkeys-lru: 对所有 key 使用 lru
- volatile-lru: 对所有设置了过期时间的key lru
- allkeys-random
- volatile-random
- volatile-ttl: 删除快要过期
- allkeys-lfu lfu
- volatile-lfu
修改 -> maxmemory-policy
总结记忆
- 2个维度
- 过期键中筛选 allkeys
- 所有键中筛选 volatile
- 4个方面
- lru 最少使用,最长时间未被使用
- lfu 最不常用,一段时间内使用次数最少
- random 随机
- ttl
用哪种

后两种都对业务有精确的要求,推荐 allkeys-lru
lru算法手写,最近最少使用算法
leetcode 146
哈希链表

基于 LinkedHashMap 的写法
java
public class LruCacheDemo<K,V> extends LinkedHashMap<K,V> {
private int capacity;
public LruCacheDemo(int capacity) {
super(capacity, 0.75f, false); // true = accessOrder false insertionOrder
this.capacity = capacity;
}
@Override
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
return super.size() > capacity;
}
public static void main(String[] args) {
LruCacheDemo lruCacheDemo = new LruCacheDemo(3);
lruCacheDemo.put(1, 1);
lruCacheDemo.put(2, 2);
lruCacheDemo.put(3, 3);
System.out.println(lruCacheDemo.keySet());
lruCacheDemo.put(4, 4);
System.out.println(lruCacheDemo.keySet());
lruCacheDemo.put(3, 3);
System.out.println(lruCacheDemo.keySet());
lruCacheDemo.put(3, 3);
System.out.println(lruCacheDemo.keySet());
lruCacheDemo.put(3, 3);
System.out.println(lruCacheDemo.keySet());
lruCacheDemo.put(5, 5);
System.out.println(lruCacheDemo.keySet());
}
}
/**
* true
* [1, 2, 3]
* [2, 3, 4]
* [2, 4, 3]
* [2, 4, 3]
* [2, 4, 3]
* [4, 3, 5]
*/
// false,只看插入顺序,不看访问顺序,多次插入3,3的位置不变
/**
* false
*[1, 2, 3]
* [2, 3, 4]
* [2, 3, 4]
* [2, 3, 4]
* [2, 3, 4]
* [3, 4, 5]
*/手写的案例
java
// 手写 LruCache
public class MyLruCacheDemo {
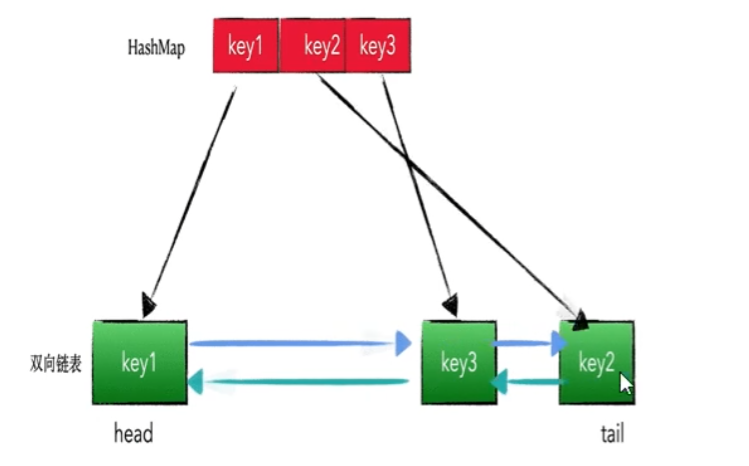
// map 负责查找,构建一个虚拟的双向链表,它里面安装的就是一个个Node节点,作为数据载体
// 1 构造一个 Node 作为数据载体
class Node<K, V> {
K key;
V value;
Node<K, V> prev;
Node<K, V> next;
public Node() {
this.prev = this.next = null;
}
}
//2 构建一个虚拟的双向链表,里面安放的就是我们的Node
class DoubleLinkedList<K, V> {
Node<K, V> head;
Node<K, V> tail;
// 2.1 构造方法
public DoubleLinkedList() {
head = new Node<K, V>();
tail = new Node<K, V>();
head.next = tail;
tail.prev = head;
}
//2.2 添加到头
public void addFirst(Node<K, V> node) {
node.next = head.next;
node.prev = head;
head.next.prev = node;
head.next = node;
}
//2.3 删除节点
public void remove(Node<K, V> node) {
node.prev.next = node.next;
node.next.prev = node.prev;
node.prev = null;
node.next = null;
}
//2.4 获得最后一个节点
public Node<K, V> getLast() {
return tail.prev;
}
}
private int cacheSize;
Map<Integer, Node<Integer, Integer>> map;
DoubleLinkedList<Integer, Integer> doubleLinkedList;
public MyLruCacheDemo(int cacheSize) {
this.cacheSize = cacheSize; // 坑位
map = new HashMap<>(); // 查找
doubleLinkedList = new DoubleLinkedList<>();
}
public int get(int key) {
if (!map.containsKey(key)) {
return -1;
}
Node<Integer, Integer> node = map.get(key);
doubleLinkedList.remove(node);
doubleLinkedList.addFirst(node);
return node.value;
}
// saveOrUpdate
public void put(int key, int value) {
if (map.containsKey(key)) { // update
Node<Integer, Integer> node = map.get(key);
node.value = value;
doubleLinkedList.remove(node);
doubleLinkedList.addFirst(node);
} else {
if (map.size() == cacheSize) { // 坑位满了
Node<Integer, Integer> last = doubleLinkedList.getLast();
map.remove(last.key);
doubleLinkedList.remove(last);
}
// 才是新增
Node<Integer, Integer> node = new Node<>();
node.key = key;
node.value = value;
map.put(key, node);
doubleLinkedList.addFirst(node);
}
}
public static void main(String[] args) {
MyLruCacheDemo lruCacheDemo = new MyLruCacheDemo(3);
lruCacheDemo.put(1, 1);
lruCacheDemo.put(2, 2);
lruCacheDemo.put(3, 3);
System.out.println(lruCacheDemo.map.keySet());
lruCacheDemo.put(4, 4);
System.out.println(lruCacheDemo.map.keySet());
lruCacheDemo.put(3, 3);
System.out.println(lruCacheDemo.map.keySet());
lruCacheDemo.put(3, 3);
System.out.println(lruCacheDemo.map.keySet());
lruCacheDemo.put(5, 5);
System.out.println(lruCacheDemo.map.keySet());
}
}