在我的设计框架业务中,字典大类、部门机构、系统菜单等这些表,都存在id、pid的字段,主要是作为自引用关系,实现树形列表数据的处理的,因为这样可以实现无限层级的树形列表。在实际使用Pydantic和SqlAlchemy来直接处理嵌套关系的时候,总是出现数据在Pydantic的对象转换验证上,爬坑一段时间才发现是模型定义使用上的问题,本篇随笔介绍使用Pydantic和SqlAlchemy实现树形列表数据(自引用表关系)的处理,以及递归方式处理数据差异。
1、使用Pydantic和SqlAlchemy实现树形列表数据(自引用表关系)的处理
默认的机构表的sqlalchemy的模型定义如下所示。
class Ou(Base):
"""机构(部门)信息-表模型"""
__tablename__ = "t_acl_ou"
id = Column(Integer, primary_key=True, comment="主键", autoincrement=True)
pid = Column(Integer, ForeignKey("t_acl_ou.id"), comment="父级机构ID")
****其他信息
# 定义 parent 关系
parent = relationship(
"Ou", remote_side=[id], back_populates="children")
# 定义 children 关系
children = relationship("Ou", back_populates="parent")然后对应的DTO(Schema)数据类定义如下。
class OuDto(BaseModel):
id: Optional[int] = None
pid: Optional[int] = None
***其他信息
class OuNodeDto(OuDto):
"""部门机构节点对象"""
children: Optional[List["OuNodeDto"]] = None # 这里使用 Optional
class Config:
orm_mode = True # 启用 orm_mod
from_attributes = True
extra = "allow"然后我在机构的Crud类里面定义了一个get_children的函数,如下所示
async def get_children(self, db: AsyncSession, id: int) -> Ou:
"""
获取子列表
:param db:
:param id:
:return:
"""
result = await db.execute(
select(Ou).options(selectinload(Ou.children)).where(Ou.id == id)
)
result = result.scalar_one_or_none()
return result这里通过 selectinload 的加载方式,可以再数据检索的时候,同时获得子列表的处理。
为了验证数据能够再CRUD中正常的检索出来,我对CRUD类的接口进行测试,并查询获得其中的children集合,代码如下所示
async def test_list_ou():
async with async_session() as db:
ou = await ou_crud.get_children(db, "3")
print(vars(ou))
for o in ou.children:
print(vars(o))
await db.close()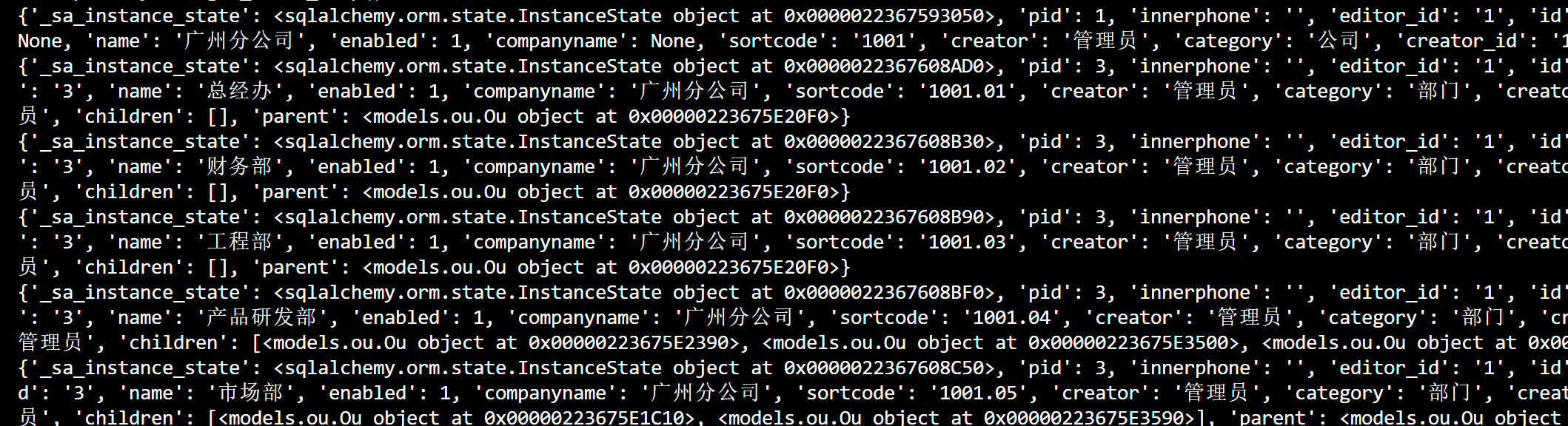
其中机构id为3的,是广州分公司,它把该公司下属所有的机构都能正常读取出来,因此底层没有问题。
但是利用FastAPI的接口处理,通过pydantic的数据转换就是不能正常获得,如下是FastAPI的路由接口实现。
@router.get(
"/get-children",
response_model=AjaxResponse[OuNodeDto | None],
summary="根据名称获取客户",
dependencies=[DependsJwtAuth],
)
async def get_children(
id: Annotated[int | None, Query()] = None,
db: AsyncSession = Depends(get_db),
):
ou = await ou_crud.get_children(db, id)
try:
result = OuNodeDto.model_validate(ou)
except Exception as e:
print(e.json())
return AjaxResponse(
success=False, result=None, errorInfo=ErrorInfo(message=str(e))
)
return AjaxResponse(result)这里注意,我使用 OuNodeDto.model_validate(ou) 对嵌套列表对象进行转换的,出错就是在这里。
具体我们可以再Swagger界面中调试获得错误信息。
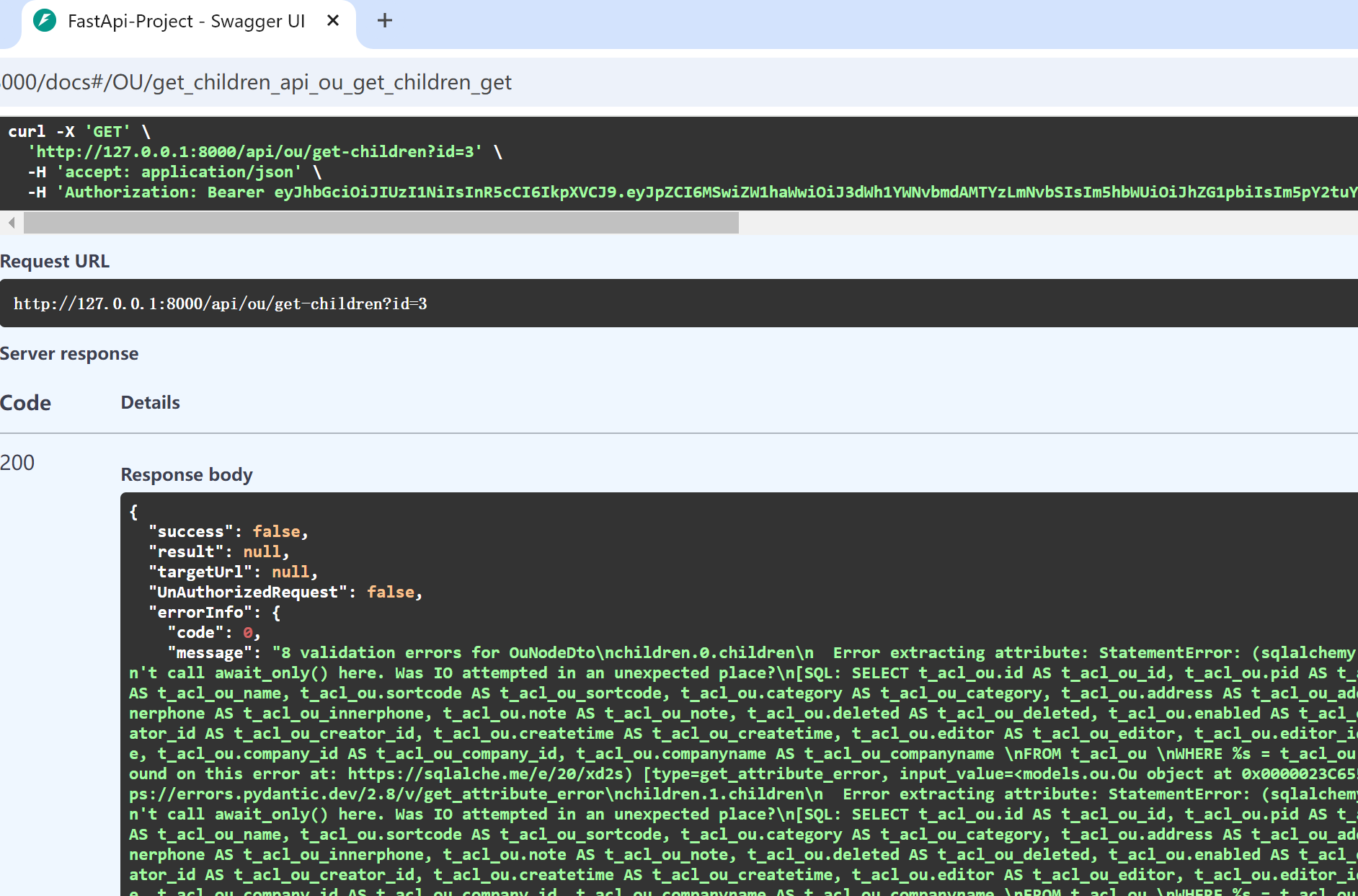
我反复核对模型Model和Schema的对象都是一一对应的,错误不是字段名称的问题,因此可能是数据处理上的问题,但是很难从其中获得更多有用的信息。在Chatgpt中获得的错误提示如下所示。
为什么我的嵌套列表可以查询出来,而通过Schema的model_validate转换的时候,就提示validation errors?
你遇到的这个问题可能是因为 Pydantic 的模型验证过程中遇到了与嵌套数据结构相关的不一致性或问题。以下是一些常见的原因及其解决方法:
1)嵌套结构不匹配
确保你的嵌套数据结构与 Pydantic 模型定义一致。如果你的模型预期的是一个嵌套的列表,但数据库查询返回的结果中缺少某些字段或类型不匹配,可能会导致验证失败。
解决方法 :
- 检查从数据库查询出来的数据结构,确保它与 Pydantic 模型中的嵌套定义一致。
2)前向引用 (Forward References)
如果你的 Pydantic 模型有自引用或互相引用的情况,确保你正确使用了 update_forward_refs()。如果在嵌套引用中没有正确处理前向引用,可能会导致验证失败。
解决方法:
确保你在 Pydantic 模型定义之后调用了 update_forward_refs(),pydantic新版使用model_rebuild,特别是当模型包含递归引用时。
3)使用from_attributes 选项
如果你的数据来自 ORM 对象(或任何非字典的对象),而你使用的是 Pydantic v2,可以尝试使用 **from_attributes**属性。
解决方法:
- 在
Config中启用from_attributes选项以确保 Pydantic 模型能够从属性中提取数据。
4) 数据库返回的数据类型问题
确保从数据库返回的数据类型(特别是 children 字段)是你预期的类型。如果 children 返回的不是一个列表或是一个包含子对象的对象,则会导致验证失败。
解决方法:
检查你的查询逻辑,确保 children 字段返回的是一个列表,并且列表中的每个项符合 OuNodeDto模型的要求。
5)未正确处理关系加载
在使用 SQLAlchemy 时,确保相关数据(如 children)已被正确加载。如果尝试访问未加载的关系,可能会抛出 StatementError。
result = await db.execute(
select(Ou).options(selectinload(Ou.children)).where(Ou.id == id)
)最后发现这些我都已经做了,我的pydantic模型定义如下所示,还是会出错。
class OuNodeDto(OuDto):
"""部门机构节点对象"""
children: Optional[List["OuNodeDto"]] = None # 这里使用 Optional
class Config:
orm_mode = True # 启用 orm_mod
from_attributes = True
extra = "allow"
# 更新前向引用
OuNodeDto.model_rebuild(force=True)如果记录返回的对象是正常的,但在使用 OuNodeDto.model_validate(ou) 转换时出现错误,可能的问题出在 Pydantic 模型的定义或对象结构与 Pydantic 模型预期的格式不完全匹配。
最后发现是 relationship 的 lazy 参数的加载策略的影响。
lazy 加载策略的概述
在 SQLAlchemy 中,relationship 的 lazy 参数决定了如何和何时加载相关的对象。常见的 lazy 加载策略有:
-
lazy="immediate":- 定义:这种策略会在加载父对象时立即加载相关的子对象。即,父对象和它的子对象会在同一个查询中加载。
- 为什么有效 :因为
lazy="immediate"会立即加载所有相关的对象,当你使用 Pydantic 的model_validate进行数据验证时,相关对象已经被加载并可供访问。
-
lazy="select":- 定义:这种策略会在访问关系时通过单独的查询来加载相关对象。即,只有当你访问子对象时,SQLAlchemy 才会发起额外的查询来获取这些对象。
- 为什么可能无效 :由于子对象是在访问时才加载的,因此在你进行
model_validate验证时,可能子对象还没有被加载,导致验证失败。
-
lazy="dynamic":- 定义:这种策略返回一个查询对象而不是实际的子对象。你需要显式地执行这个查询来获取相关的子对象。
- 为什么可能无效 :
lazy="dynamic"返回的是查询对象而不是实际的对象实例。因此,Pydantic 的model_validate无法直接处理这些查询对象,必须先执行查询来获取实际的对象。
使用 lazy="immediate"
class Ou(Base):
__tablename__ = "t_acl_ou"
id = Column(Integer, primary_key=True)
pid = Column(Integer, ForeignKey("t_acl_ou.id"))
name = Column(String)
parent = relationship("Ou", remote_side=[id], back_populates="children", lazy="immediate")
children = relationship("Ou", back_populates="parent", lazy="immediate")在这种情况下,当你查询一个 Ou 对象时,children 已经被立即加载,可以直接用于 Pydantic 的 model_validate。
使用 lazy="select"
class Ou(Base):
__tablename__ = "t_acl_ou"
id = Column(Integer, primary_key=True)
pid = Column(Integer, ForeignKey("t_acl_ou.id"))
name = Column(String)
parent = relationship("Ou", remote_side=[id], back_populates="children", lazy="select")
children = relationship("Ou", back_populates="parent", lazy="select")在这种策略下,children 只有在访问时才会被加载,这可能导致在进行 model_validate 验证时 children 尚未加载完成。
使用 lazy="dynamic"
class Ou(Base):
__tablename__ = "t_acl_ou"
id = Column(Integer, primary_key=True)
pid = Column(Integer, ForeignKey("t_acl_ou.id"))
name = Column(String)
parent = relationship("Ou", remote_side=[id], back_populates="children", lazy="dynamic")
children = relationship("Ou", back_populates="parent", lazy="dynamic")lazy="dynamic" 返回的是一个查询对象,而不是实际的 children 对象。为了使用 Pydantic 进行验证,你必须先执行这个查询来获取实际的对象。
lazy 加载策略总结
lazy="immediate": 立即加载相关对象,使其在 Pydantic 的model_validate中可用。lazy="select": 需要在访问时加载相关对象,可能在验证时尚未加载。lazy="dynamic": 返回查询对象,需要额外的查询步骤,model_validate无法直接处理。
在 SQLAlchemy 中,lazy 模式是模型定义的一部分,决定了如何加载相关的对象。
为了确保 model_validate 正常工作,通常建议使用 lazy="immediate" 以确保所有相关数据在进行验证时已经被完全加载。
最后修改为**lazy="immediate" **后,工作正常,顺利进行列表的转换了。
2、递归方式处理树形列表数据
为了确保 Pydantic 的 model_validate 能正确处理嵌套关系,推荐使用 lazy="immediate" 策略。这样可以保证在 Pydantic 进行数据验证时,所有相关数据已经完整加载。
除了这样对树形列表进行处理外,还有什么好办法处理?
处理树形列表(或树形结构)的常见方法包括以下几种,除了直接使用 SQLAlchemy 的 relationship 和 lazy="immediate" 加载策略外,还可以采用其他一些技术和工具来处理和操作树形数据结构。
下面介绍使用递归检索方式进行列表数据的处理。在 Python 中,递归处理树形列表的常见方法是使用递归函数遍历树结构。
假设你有一个部门(Ou)模型,每个部门可以有多个子部门(树形结构)。你想要使用递归方法遍历并填充树形结构中的每个节点。
通过 Pydantic 的 BaseModel 类进行遍历填充,可以结合递归和 Pydantic 的模型来处理树形结构的数据。以下是一个详细的示例,展示如何使用 Pydantic 的 BaseModel 类进行递归遍历和填充树形结构。
首先,定义一个 Pydantic 模型,用于表示树形结构中的节点。为了处理嵌套的子节点,可以在模型中使用递归类型注解。
from typing import List, Optional
from pydantic import BaseModel
class OuNodeDto(BaseModel):
id: int
name: str
children: Optional[List['OuNodeDto']] = None # 递归类型注解
class Config:
orm_mode = True假设我们有一组嵌套的字典数据,表示树形结构:
ou_data = [
{
"id": 1,
"name": "Root Department",
"children": [
{
"id": 2,
"name": "Child Department 1",
"children": [
{"id": 4, "name": "Grandchild Department 1"},
{"id": 5, "name": "Grandchild Department 2"}
]
},
{"id": 3, "name": "Child Department 2"}
]
}
]通过 Pydantic 的 BaseModel,你可以直接进行递归填充。假设 ou_data 是从数据库或者其他外部来源获取的字典列表,你可以通过递归构造 OuNodeDto 实例。
def build_tree(data: List[dict]) -> List[OuNodeDto]:
"""
递归遍历并构建 Pydantic 模型树。
:param data: 包含树结构的字典列表
:return: 填充后的 Pydantic 模型列表
"""
tree = []
for node_data in data:
# 处理子节点递归填充
children = build_tree(node_data.get("children", []))
# 使用 Pydantic 的模型验证和创建对象
node = OuNodeDto(
id=node_data["id"],
name=node_data["name"],
children=children if children else None
)
tree.append(node)
return tree使用上面的 build_tree 函数,你可以递归地遍历数据,并使用 Pydantic 模型来构建整个树形结构。
ou_tree = build_tree(ou_data)
# 输出树形结构的Pydantic模型
for node in ou_tree:
print(node)运行上面的代码后,输出将是一个 Pydantic 模型的树形结构列表,已填充好所有数据。
OuNodeDto(id=1, name='Root Department', children=[
OuNodeDto(id=2, name='Child Department 1', children=[
OuNodeDto(id=4, name='Grandchild Department 1', children=None),
OuNodeDto(id=5, name='Grandchild Department 2', children=None)
]),
OuNodeDto(id=3, name='Child Department 2', children=None)
])通过这种方式,你可以使用 Pydantic 的 BaseModel 结合递归函数来处理树形结构的数据填充和验证。Pydantic 提供了强大的数据验证和解析能力,使得处理复杂的嵌套结构变得更加容易。
如果是从数据库中检索获得的SqlAlchemy的模型类,应该如何递归遍历?
要从数据库中检索并递归遍历 SQLAlchemy 的模型类,然后将其转换为 Pydantic 的模型类,可以按照以下步骤进行操作。假设你已经定义了 SQLAlchemy 模型类和对应的 Pydantic 模型类,接下来将展示如何递归遍历和填充这些数据。
首先,我们定义一个包含自引用关系的 SQLAlchemy 模型。
from sqlalchemy import Column, Integer, String, ForeignKey
from sqlalchemy.orm import relationship, declarative_base
Base = declarative_base()
class Ou(Base):
__tablename__ = "t_acl_ou"
id = Column(Integer, primary_key=True, autoincrement=True)
pid = Column(Integer, ForeignKey("t_acl_ou.id"))
name = Column(String)
# 自引用关系
parent = relationship("Ou", remote_side=[id], back_populates="children")
children = relationship("Ou", back_populates="parent")然后定义一个对应的 Pydantic 模型,支持嵌套的子节点。
from typing import List, Optional
from pydantic import BaseModel
class OuNodeDto(BaseModel):
id: int
name: str
children: Optional[List['OuNodeDto']] = None # 递归类型注解
class Config:
orm_mode = True # 允许从 ORM 对象转换使用 SQLAlchemy 的查询从数据库中获取组织结构数据。为了处理嵌套的关系,你可以使用 selectinload 或其他类似的加载策略来预先加载子节点。
from sqlalchemy.future import select
from sqlalchemy.orm import selectinload, sessionmaker
from sqlalchemy.ext.asyncio import AsyncSession, create_async_engine
# 假设使用异步引擎
engine = create_async_engine('sqlite+aiosqlite:///./test.db')
Session = sessionmaker(engine, class_=AsyncSession, expire_on_commit=False)
async def get_ou_tree_by_id(ou_id: int):
async with Session() as session:
# 使用 selectinload 预先加载子节点
result = await session.execute(
select(Ou).options(selectinload(Ou.children)).filter_by(id=ou_id)
)
ou = result.scalars().first()
return ou编写一个递归函数,将 SQLAlchemy 的 ORM 对象转换为 Pydantic 模型对象。
def build_tree(node: Ou) -> OuNodeDto:
"""
递归遍历 SQLAlchemy 模型,并转换为 Pydantic 模型。
:param node: SQLAlchemy 模型实例
:return: 填充后的 Pydantic 模型实例
"""
# 使用 Pydantic 模型验证和创建对象
node_dto = OuNodeDto(
id=node.id,
name=node.name,
# 递归填充子节点
children=[build_tree(child) for child in node.children] if node.children else None
)
return node_dto结合以上步骤,从数据库中获取数据并构建树形结构。
import asyncio
async def main():
# 获取指定 ID 的组织结构树
ou = await get_ou_tree_by_id(1)
# 递归构建树形结构的 Pydantic 模型
ou_tree = build_tree(ou)
# 输出树形结构
print(ou_tree)
# 运行异步任务
asyncio.run(main())执行上述代码后,ou_tree 将是一个包含组织结构树的 Pydantic 模型对象,所有嵌套的子节点将被递归地转换和填充。
使用 Pydantic 的 model_validate 处理并且relationship加载策略lazy=immediate 和通过递归SqlAlchemy的模型类填充,哪个性能更好?
在比较使用 Pydantic 的 model_validate 与通过递归手动填充 SQLAlchemy 模型类的性能时,主要考量点是数据加载策略和模型转换方式的效率。以下是两者的详细分析:
1) Pydantic 的 model_validate + lazy="immediate"
-
工作原理:
- 使用
lazy="immediate"会在 SQLAlchemy 实例化对象时立即加载关联的子对象。这意味着在访问主对象时,子对象已经完全加载,不需要再发起额外的数据库查询。 - 使用 Pydantic 的
model_validate可以将 SQLAlchemy 的 ORM 对象直接转换为 Pydantic 模型。
- 使用
-
性能考虑:
- 数据加载 :
lazy="immediate"会在访问对象时自动加载相关数据,适合需要立即访问完整数据结构的场景,但它可能会导致不必要的加载,尤其是在不需要所有子对象的情况下。 - 转换开销 :
model_validate是一个单步操作,自动处理复杂嵌套对象的转换。虽然方便,但它的开销取决于对象的复杂性和嵌套深度。对于深度嵌套的大量对象,转换的时间可能较长。
- 数据加载 :
-
优点:
- 简洁:减少了手动编写递归代码的需要。
- 自动化:能够自动处理嵌套关系的转换。
-
缺点:
- 可能会导致不必要的数据加载。
- 对于大规模嵌套对象,性能可能下降。
2)递归手动填充 SQLAlchemy 模型类
-
工作原理:
- 手动编写递归函数来遍历 SQLAlchemy 的 ORM 对象并转换为 Pydantic 模型。
- 可以灵活地选择何时加载子对象(通过
selectinload,joinedload等),从而在需要时再加载数据。
-
性能考虑:
- 数据加载 : 手动控制数据加载策略,可以优化查询性能,避免不必要的数据加载。只在需要时加载数据,避免了
lazy="immediate"带来的过度加载。 - 转换开销: 手动递归通常只处理当前节点及其直接子节点,相对高效。你可以通过优化递归逻辑,减少不必要的对象创建和转换。
- 数据加载 : 手动控制数据加载策略,可以优化查询性能,避免不必要的数据加载。只在需要时加载数据,避免了
-
优点:
- 性能优化:可以根据需要优化加载策略和递归处理,避免不必要的计算和数据加载。
- 灵活性:更灵活地控制对象的转换和数据访问。
-
缺点:
- 需要手动编写递归逻辑,增加了代码复杂性。
- 不如
model_validate自动化,容易出错。
3)总结与选择
-
数据规模和复杂性较小时 :
model_validate+lazy="immediate"更方便,且性能影响不大,可以快速实现自动化的 Pydantic 模型转换。 -
数据规模大且嵌套深度较高时: 手动递归填充可能会更高效,尤其是在你需要精细控制数据加载策略时。这样可以避免过度加载,并且优化性能。
结论 :如果你的应用场景对性能要求较高,并且数据结构较为复杂,手动递归可能更优。如果优先考虑代码的简洁性和开发效率,且数据规模不大,那么 model_validate 配合 lazy="immediate" 是更好的选择。