数据仓库
概念
数据仓库(Data Warehouse, DW)是一个面向主题的、集成的、相对稳定的、反映历史变化的数据集合。它是为满足企业决策分析需求而设计的。
-
面向主题:数据仓库围绕特定的主题组织数据,例如"销售"或"人力资源",通过整合各类数据提供全面的视角。
-
集成:数据仓库从多个异构数据源抽取数据,经过清理、转换和整合,消除数据冗余,保证数据一致性。
-
相对稳定:一旦数据进入数据仓库,便很少修改,主要是为了历史数据分析和未来趋势预测。
-
反映历史变化:数据仓库保存数据的历史状态,支持随时间维度的数据分析。
发展历程
数据仓库的发展经历了几个关键阶段:
-
萌芽阶段(1978-1988年):提出了将业务处理系统(OLTP)与业务分析系统(OLAP)分离的思想,早期的尝试集中在减少交易系统的负载以提高分析能力。
-
探索阶段(20世纪80年代中期):DEC公司建立了TA2规范,定义了分析系统由数据获取、访问目录和用户服务组成。这一时期,人们开始探索如何有效地存储和检索大量数据。
-
出行阶段(1988年):IBM提出信息仓库的概念,涵盖了数据的抽取、转换、有效性验证、加载、cube开发和图形化展示。这一阶段引入了更多视觉化工具来呈现数据分析的结果。
-
确立阶段(1991年):Bill Inmon出版了《数据仓库》一书,提出了数据仓库的奠基原则,包括面向主题、集成、包含历史、不可更新、面向决策支持、面向全企业、最明细数据存储和快照式数据获取。
-
合并阶段(1998年):Inmon提出的企业信息工厂(CF架构),结合范式建模和维度建模的优点,进行分层构建数据仓库,推动了数据仓库结构的进一步完善和标准化。
结构
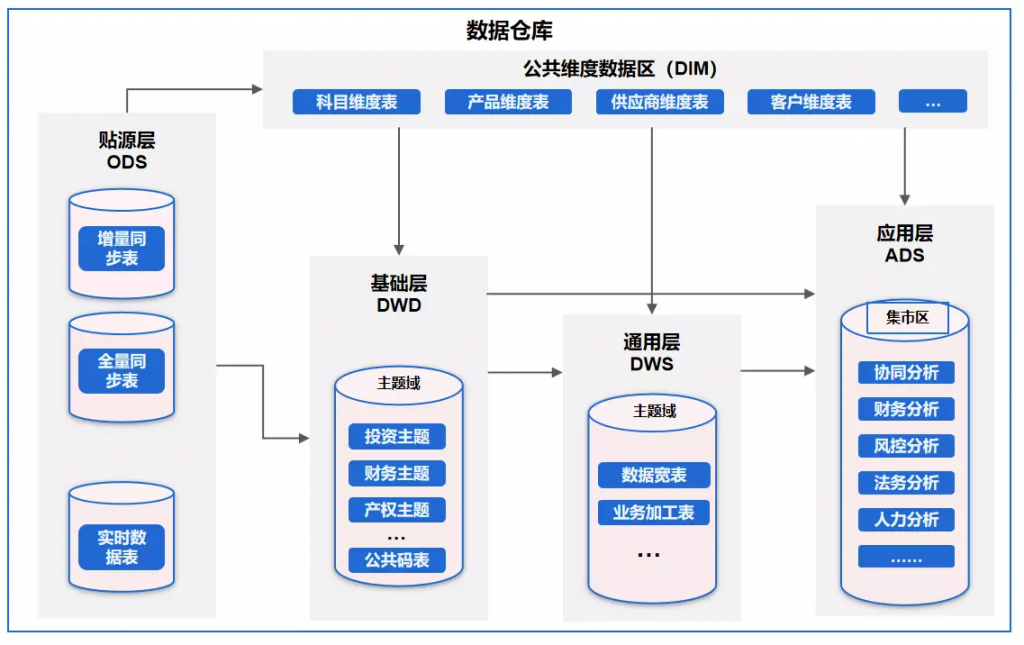
数据仓库的结构通常分为以下几层:
- 数据引入层(ODS:Operational Data Store) :
这一层的数据结构与源系统保持一致,通常是增量或全量数据的临时存储区。ODS层的主要目的是保存原始数据,便于后续的数据核对和处理。
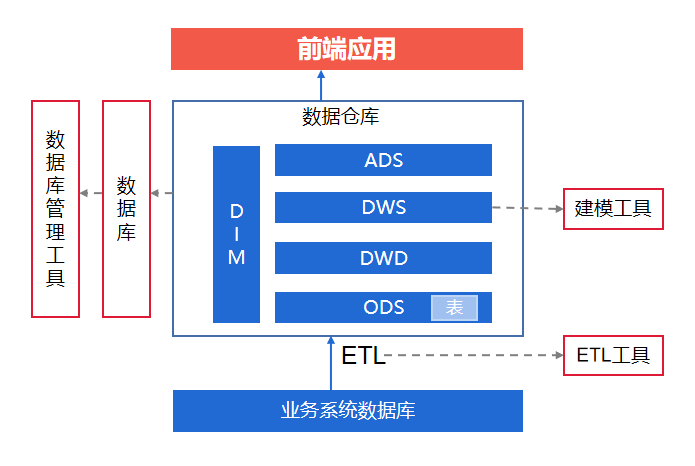
- 数据明细层(DWD:Data Warehouse Detail) :
在这一层,对ODS层的数据进行清洗、转换,以业务过程为核心构建最细粒度的明细事实表。基于具体业务的特点,DWD层的表通常会做一些适当的冗余处理,形成宽表以提高查询性能和数据的可用性。
- 汇总数据层(DWS:Data Warehouse Summary) :
此层基于明细层的数据进行初步汇总,构建汇总事实表。这些表通常是宽表形式,提供公共的统计指标,为上层数据分析提供基础。
- 公共维度层(DIM:Dimension) :
维度层包含所有数据分析所需的维度表,确保数据口径的一致性,方便多角度、多层次的数据分析。
- 应用数据服务层(ADS:Application Data Service) :
最高层面向具体应用场景,对汇总数据进行进一步加工,直接服务于前端BI工具或决策支持系统。
维度建模
概念
维度建模是由Ralph Kimball提出的一种专门用于数据仓库环境的建模方法。它采用反范式化设计,不严格遵循传统的数据库规范化标准,更加注重查询的性能和数据的易用性。
核心组件
维度建模的核心组件包括事实表和维度表:
-
事实表(Fact Table):
-
粒度:事实表中的每一条记录代表一个具体的业务事件,比如一笔销售记录或一次财务交易。粒度决定了这条记录所包含的业务细节的程度。
-
度量:事实表中的数据元素通常是数值型的,如销售金额、数量、利润等。度量可以分为可加性、半可加性和不可加性。
-
类型:事实表可分为事务事实表、周期快照事实表和累积快照事实表。事务事实表记录具体的业务事件,而快照事实表则定期捕获某一时刻的状态。
-
-
维度表(Dimension Table):
-
维度:维度是用于描述和分类事实的环境。例如,在销售数据中,"时间"、"地点"、"产品"和"客户"都是典型的维度。
-
属性:每一个维度表由若干属性列组成,这些属性用于过滤、分组和标记数据。例如,产品维度表可能包含产品名称、类别、价格等属性。
-
退化维度:有时候,维度表中的某些属性也会存入事实表中,这样的列被称为退化维度。
-
模型类型
维度建模常见的模型类型有星型模型、雪花模型和星座模型:
-
星型模型(Star Schema):
- 由一张中央事实表和若干外围维度表组成,结构清晰,查询简便,适合新手和中级数据仓库用户。
-
雪花模型(Snowflake Schema):
- 对星型模型进行扩展,将维度表进一步层次化,形成树枝状结构。这样可以减少表的宽度和冗余,但也增加了查询的复杂性。
-
星座模型(Galaxy Schema):
- 包含多张事实表,共享一组公共维度表。适用于复杂业务场景,每张事实表可以代表一个不同的业务过程。
应用
维度建模的目标是满足业务分析和决策的需求,使数据仓库的数据易于理解和查询。通过合理设计事实表和维度表,可以快速响应业务查询,提供高效的分析性能。例如,在电商行业中,维度建模可用于销售数据分析,通过构建"时间"、"地域"、"产品类别"和"顾客"等多个维度表,围绕"销售事实表"进行组织,可以轻松实现多角度、多层次的销售数据透视和分析。
总结
数据仓库和维度建模是现代企业数据分析不可或缺的部分。数据仓库通过整合、清洗和转换来自不同源系统的数据,为企业提供一致、可靠的历史数据,支持战略决策和未来趋势预测。维度建模作为一种反范式化的建模方法,通过设计合理的事实表和维度表,大大提高了数据查询和分析的效率,使数据仓库更能贴近业务需求,易于理解和使用。