目录
Matplotlib图表绘制
准备工作
import pandas as pd
anscombe = pd.read_csv('../data/e_anscombe.csv') # 资料中提供了这份数据
print(anscombe)
df1 = anscombe[anscombe['dataset']=='I']
df2 = anscombe[anscombe['dataset']=='II']
df3 = anscombe[anscombe['dataset']=='III']
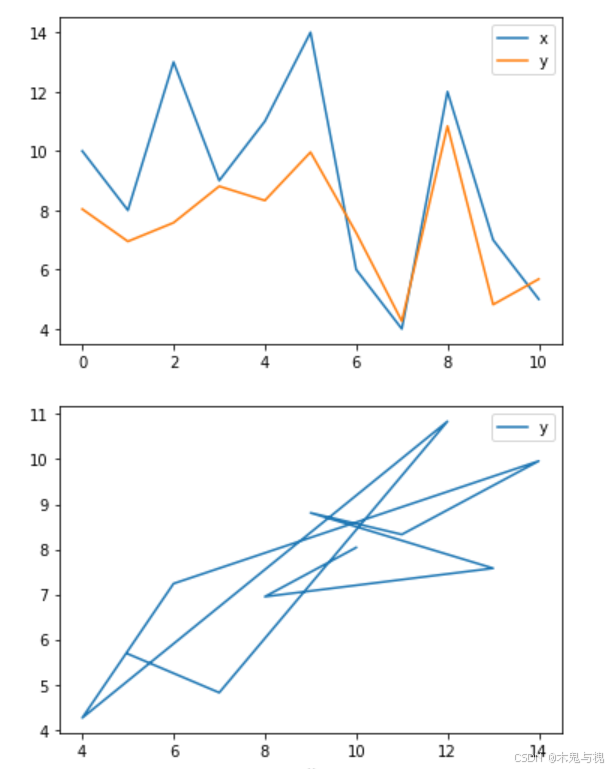
df4 = anscombe[anscombe['dataset']=='IV']折线图line
-
折线图适用于时间序列数据分析、不同变量变化趋势比较、科学研究实验数据分析以及趋势预测和未来规划等多个场景。
df1.plot() # 默认折线图
#df1.plot(kind='line') # 结果与df1.plot()
#df1.plot.line() # 结果与df1.plot()x轴是索引值,y轴是各列的具体值
也可以通过参数指定xy轴对应的列名
df1.plot.line(x='x', y='y')
plt.show()
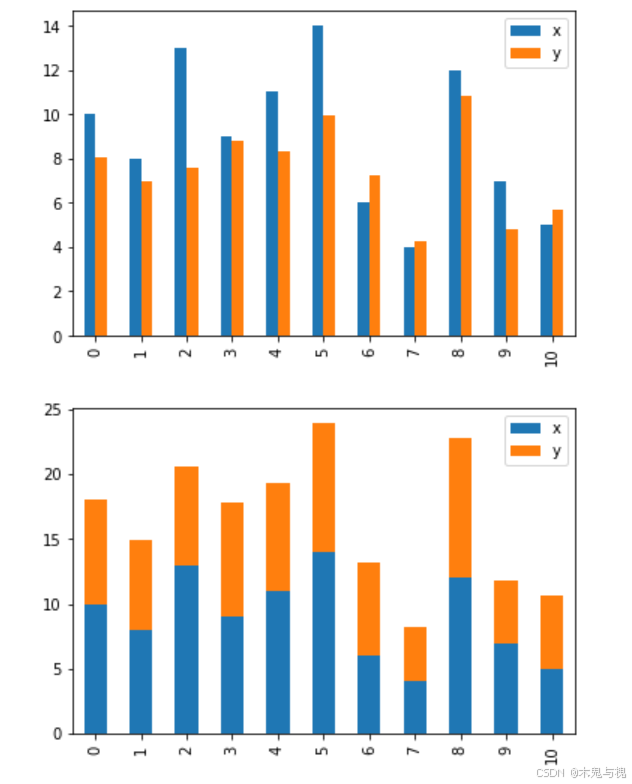
柱状图bar
-
柱状图可应用于销售和市场分析、人口统计、学术研究、项目管理等场景,直观展示不同类别数据大小差异及分布情况,方便比较和分析。
df1.plot.bar() # 柱状图
df1.plot.bar(stacked=True) # 柱状堆积也可以通过参数指定xy轴对应的列名
df1.plot.bar(x='x', y='y')
plt.show()
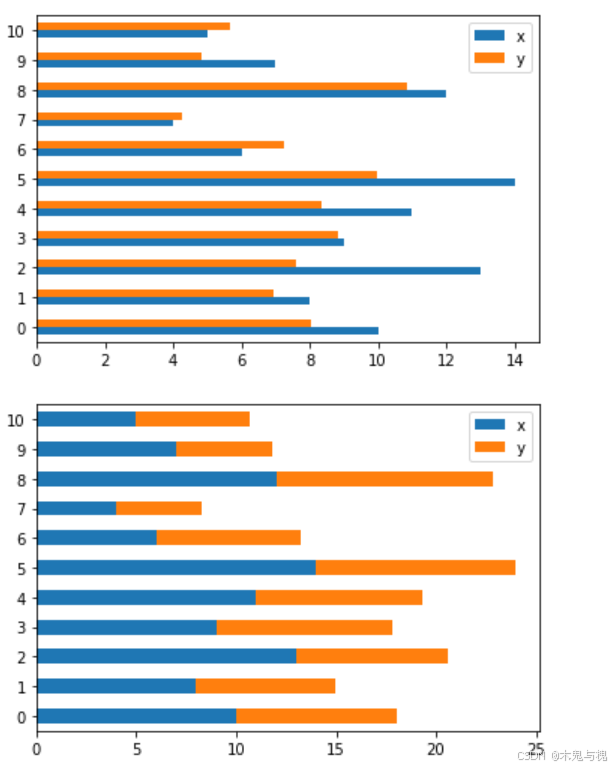
水平条形图barh
-
条形柱状图适用于销售业绩对比、人口统计分布展示、学术研究成果呈现、项目进度管理等众多场景,以直观的方式展现不同类别数据的大小差异,便于比较和分析各类数据的分布情况。
df1.plot.barh() # 水平条形图
df1.plot.barh(stacked=True) # 水平条形堆积图也可以通过参数指定xy轴对应的列名
df1.plot.barh(x='x', y='y')
plt.show()
饼图pie
-
饼图主要应用于展示各部分占总体的比例关系,常见于市场份额分析、财务报表展示、人口构成统计等场景,能让人直观地看出不同部分在整体中的相对重要程度。
饼图,只能展示一维数据
参数y指定列名
参数autopct='%.2f%%'指定显示百分比 %.2f%%表示保留2位小数
参数radius=0.9 指定饼图直径的比例,最大为1
参数figsize=(16, 8) 设定图片大小
df1.plot.pie(y='x', autopct='%.2f%%', radius=0.9, figsize=(16, 8))
plt.show()
散点图scatter
-
散点图适用于展示两个变量之间的关系,可用于科学研究中分析变量相关性、金融领域判断资产价格关系、市场调研中探索因素关联等场景。
指定xy轴,grid=True开启背景辅助线
df1.plot.scatter(x='x', y='y', grid=True)
plt.show()
气泡图csatter
-
气泡图通常用于展示三个变量之间的关系,在市场分析中呈现不同产品的多个指标关系、科学研究中展示数据的多维特征等场景有广泛应用。
参数s表示每个点的大小,与普通散点图相比能够描述三维数据
df1.plot.scatter(x='x', y='y', grid=True, s=df1['x']*100)
plt.show()
箱线图boxplot
-
箱线图用于显示多种统计信息:最小值,1/4分位,中位数,3/4分位,最大值,以及离群值(如果有)
-
箱线图主要应用于显示数据的分布情况,可用于质量控制中监测生产数据的稳定性、统计分析中比较多组数据的分布差异、金融领域分析股票收益的波动等场景。
df1.boxplot()
df1.plot.boxplot() # 报错
plt.show()
直方图hist
-
直方图适用于展示数据的分布形态,常见于质量控制中分析产品指标分布、统计研究中判断数据集中趋势和离散程度、市场调研中了解消费者特征分布等场景。
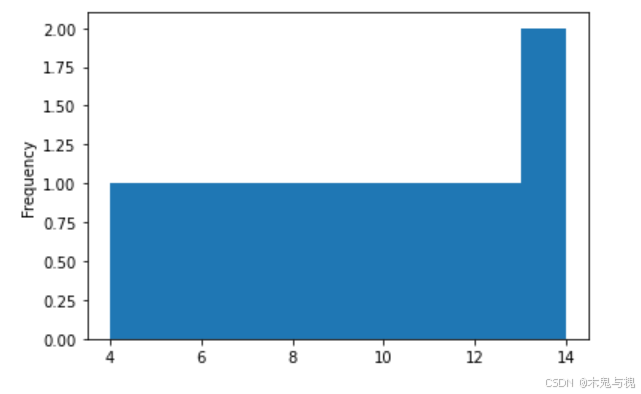
描述数据出现的次数
df1['x'].plot.hist()
plt.show()
蜂巢图hexbin
-
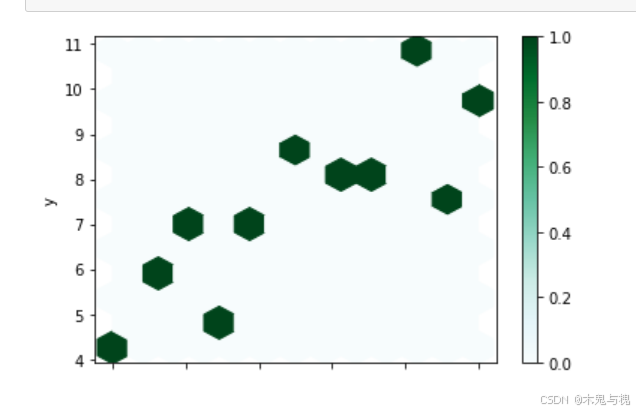
蜂巢图主要应用于复杂数据的可视化展示,可在社交网络分析中呈现关系结构、生物信息学中展示基因网络、物流网络规划中展示节点连接关系等场景。
gridsize=12设定蜂箱格子的大小,数字越小格子越大
df1.plot.hexbin(x='x', y='y', gridsize=12)
plt.show()
Seaborn图表绘制
准备数据
# 导包
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns # Anaconda内置,无需额外安装
# 加载数据
tips_df = pd.read_csv('../data/f_tips.csv')
print(tips_df)关系散点图scatterplot
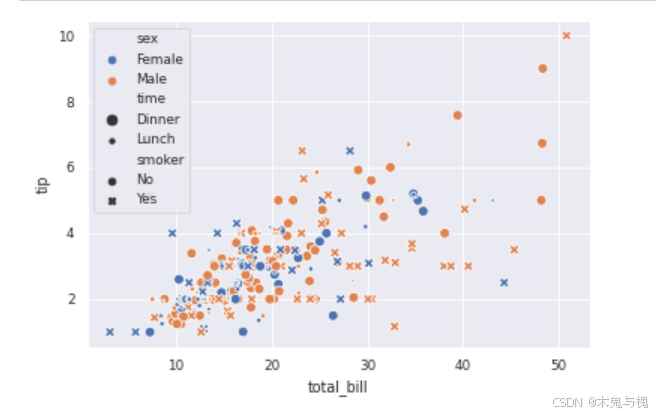
# 关系型散点图
# 指定数据集,指定x轴为消费订单金额,y轴为消费金额,
# 散点图通用的可选参数 hue='sex'通过颜色指定分组
# 散点图通用的可选参数 style='smoker' 通过形状指定分组
# 散点图通用的可选参数 size='time' 通过大小指定分组
sns.scatterplot(
data=tips_df,
x='total_bill',
y='tip',
hue='sex',
style='smoker',
size='time'
)
plt.show()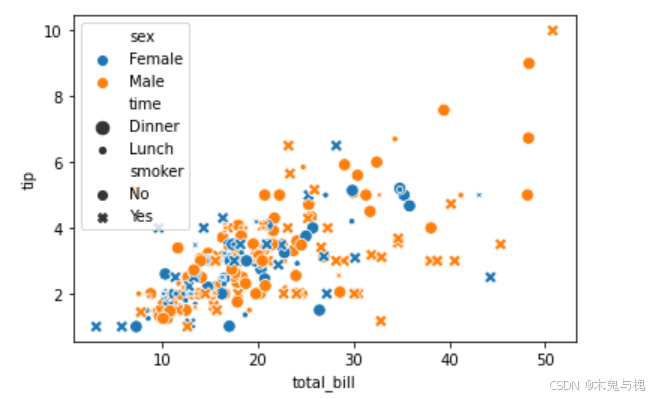
关系散点线形图replot
# replot关系散点图
sns.relplot(data=tips_df, x='total_bill', y='tip') # 默认 kind='scatter'
sns.relplot(data=tips_df, x='total_bill', y='tip', kind='line')
plt.show()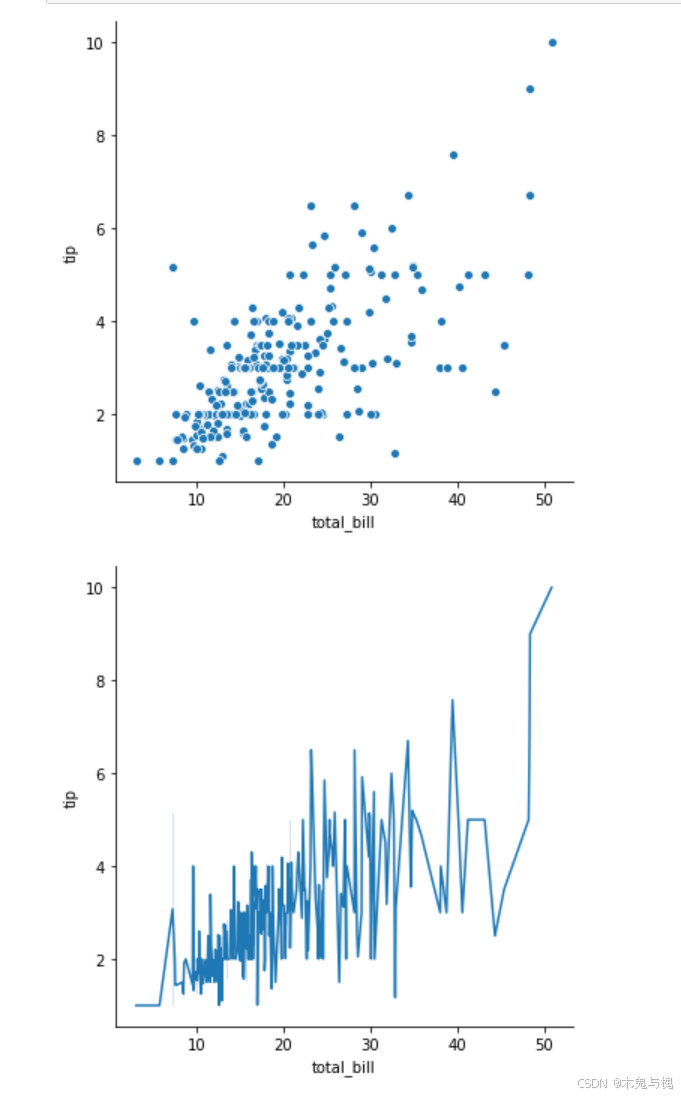
分类散点图stripplot
# stripplot分类散点图
f = plt.figure()
f.add_subplot(2,1,1)
# 按照x属性所对应的类别分别展示y属性的值,适用于分类数据
# 不同饭点的账单总金额的散点图
sns.stripplot(data=tips_df, x='time', y='total_bill')
f.add_subplot(2,1,2)
# hue通用参数按颜色划分
# jitter=True 当数据点重合较多时,尽量分散的展示数据点
# dodge=True 拆分分类
sns.stripplot(data=tips_df, x='time', y='total_bill', jitter=True, dodge=True, hue='day')
plt.show()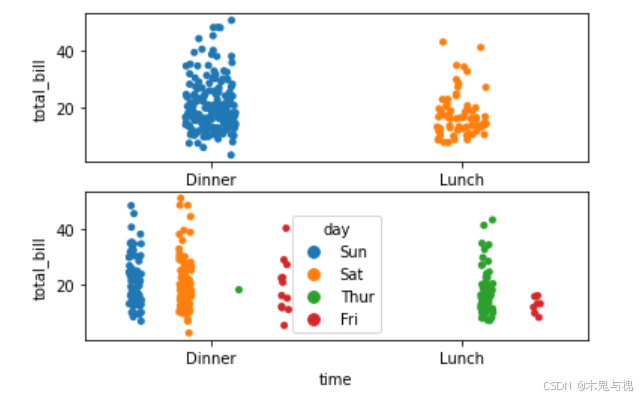
# 下边的代码只能输出一张图表
sns.stripplot(data=tips_df, x='time', y='total_bill')
sns.stripplot(data=tips_df, x='time', y='total_bill', jitter=True, dodge=True, hue='day')
plt.show()
# 所以我们使用下面的方法进行多图的输出
# f = plt.figure() # 创建画布
# f.add_subplot(2,1,1) # 在画布上申请图表空间,参数2,1,1表示2行1列中的第1个
# 图1 # sns.stripplot(data=tips_df, x='time', y='total_bill')
# f.add_subplot(2,1,2) # 在画布上申请图表空间,参数2,1,2表示2行1列中的第2个
# 图2 # sns.stripplot(data=tips_df, x='time', y='total_bill', jitter=True, dodge=True, hue='day')
# plt.show()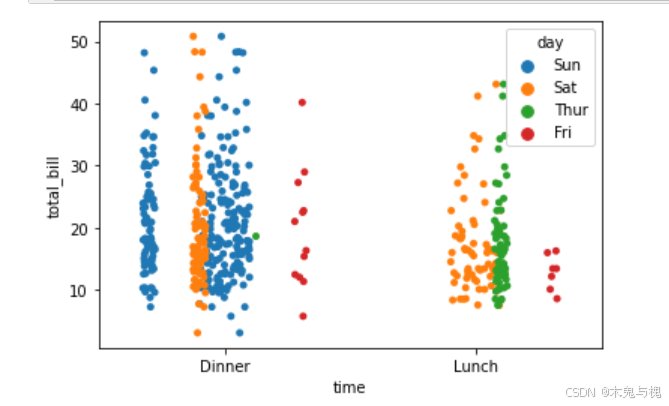
分类小提琴图violinplot
# violinplot分类小提琴
# 下图分别描述午餐账单、晚餐账单的最大值、最小值、三个四分位数,以及所有账单金额出现的次数(频率)
sns.violinplot(data=tips_df, x='time', y='total_bill')
plt.show()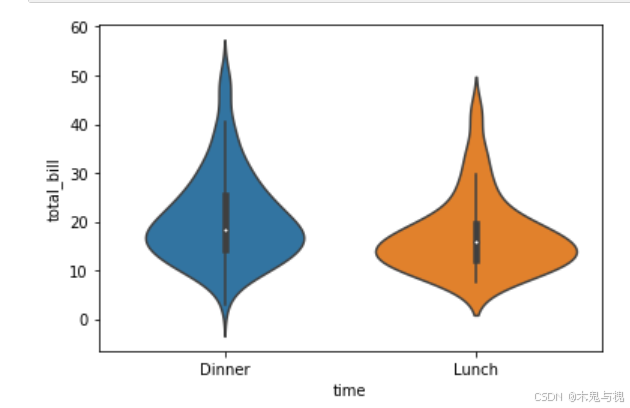
分类平均值分布图barplot
# 下图中黑色的粗线条展示了数据的分布(误差线), 线条越短, 数据分布越均匀
# 下图中每个柱的顶点就是该分类y指定列的平均值
sns.barplot(data=tips_df, x='day', y='total_bill')
plt.show()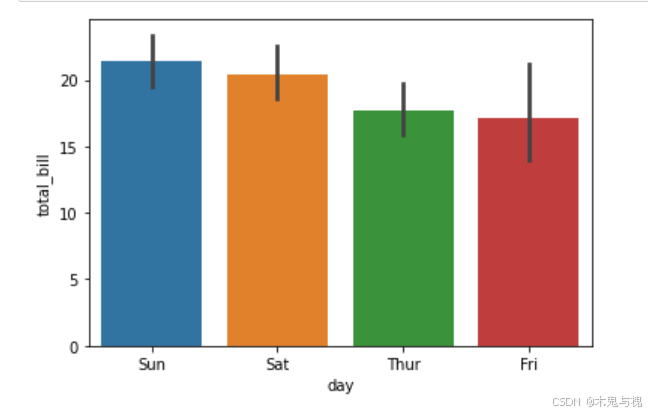
分类技计数图countplot
# 按x指定的列值分组统计出现次数
sns.countplot(data=tips_df, x='day')
plt.show()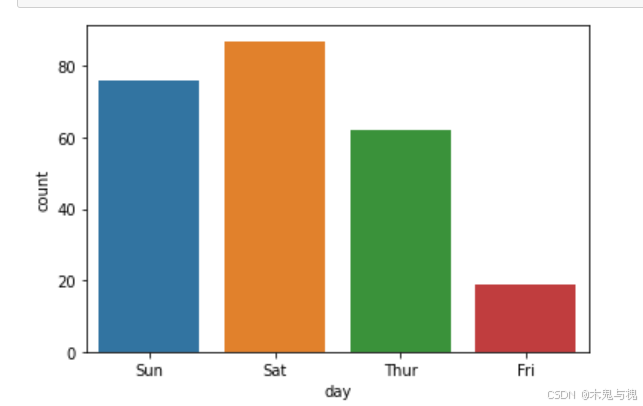
矩形热力图heatmap
# 热力图
# 男女在午餐晚餐的平均消费
new_df = tips_df.pivot_table(index='sex', columns='time', values='total_bill', aggfunc='mean')
print(new_df)
# 输出为热力图:男性在晚餐花费最多
sns.heatmap(data=new_df)
plt.show()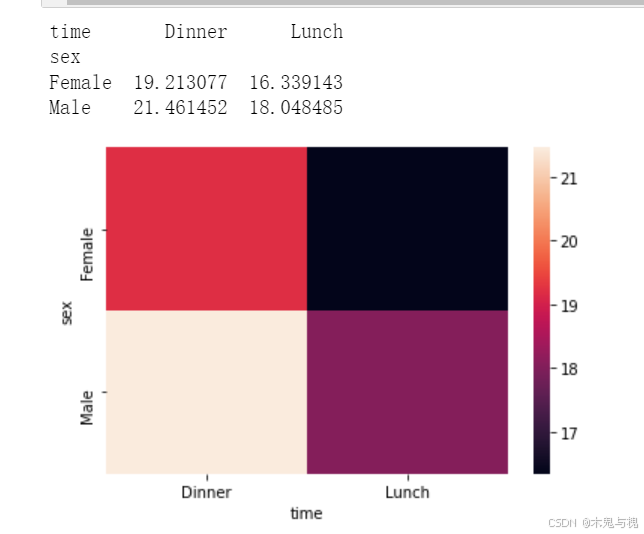
成对关系图pairplot
# pairplot成对比关系图
sns.pairplot(tips_df)
#sns.pairplot(df) # 全部数值列进行两两组合
#sns.pairplot(df, vars=['列名1', '列名2']) # 指定要组合展示的列名
plt.show()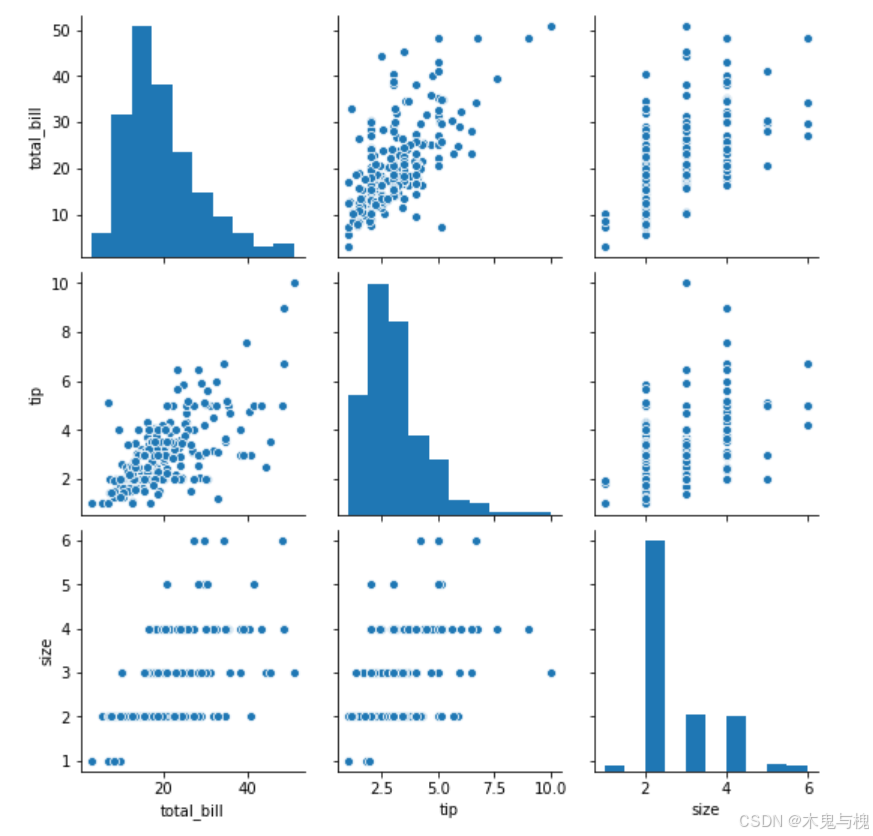
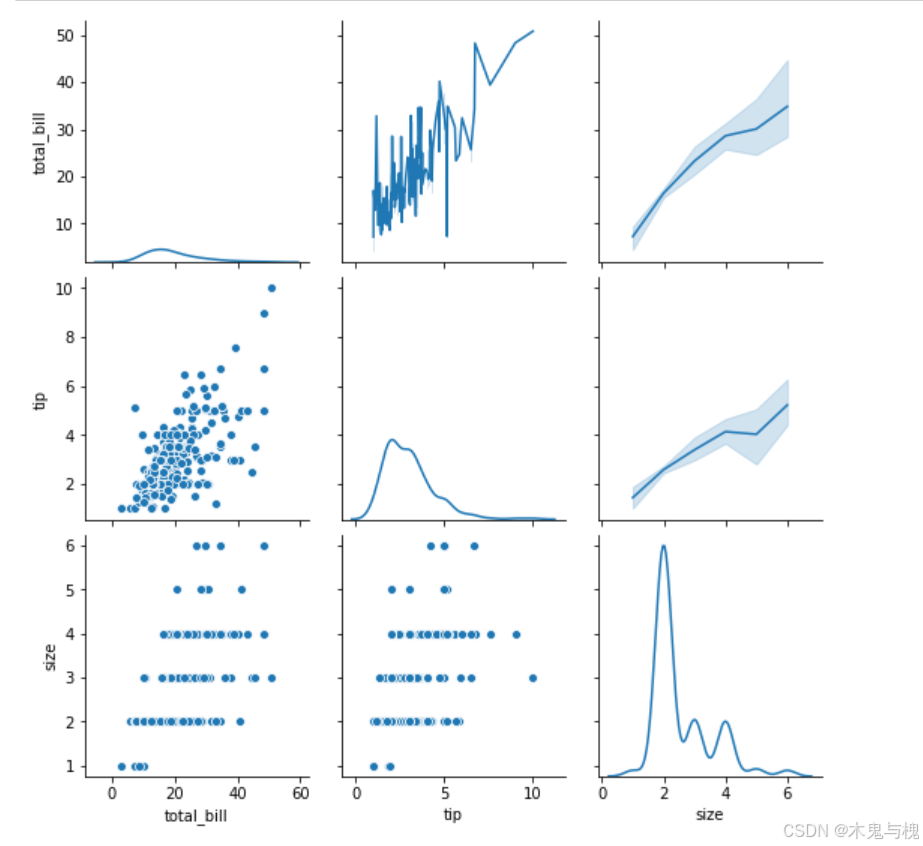
-
按右上、左下、中间轴线(左上至右下)的方式分别设置图表类型
pair_grid = sns.PairGrid(tips_df)
中间轴线上的图设为kdeplot
pair_grid.map_diag(sns.kdeplot)
右上设为lineplot
pair_grid.map_upper(sns.lineplot)
左下设为scatterplot
pair_grid.map_lower(sns.scatterplot)
plt.show()
-
将 Seaborn 提供的样式声明代码 sns.set() 放置在绘图前,就可以设置图像的样式
sns.set(
context='paper',
style='darkgrid',
palette='deep',
font='sans-serif',
font_scale=1
)context: 参数控制着默认的画幅大小,分别有 {paper, notebook, talk, poster} 四个值。其中,poster > talk > notebook > paper。
style:参数控制默认样式,分别有 {darkgrid, whitegrid, dark, white, ticks},你可以自行更改查看它们之间的不同。
palette:参数为预设的调色板。分别有 {deep, muted, bright, pastel, dark, colorblind} 等,你可以自行更改查看它们之间的不同。
font:用于设置字体
font_scale:设置字体大小
sns.scatterplot(data=tips_df, x='total_bill', y='tip', hue='sex', style='smoker', size='time')
plt.show()