一、你是如何理解Count(*)和Count(1)的?
这两个并没有区别,不要觉得 count() 会查出全部字段,而 count(1) 不会。所以 count() 会更慢,你觉得 MySQL 作者会这么做吗?
可以很明确地告诉你们 count() 和 count(1) 是一样的,而正确有区别的是 count(字段)。如果你 count() 的是具体的字段,那么 MySQL 会判断某行记录中对应字段是否为 null,如果为 null 就不会进行统计了。因此 count(字段) 的结果可能会小于 count() 和 count(1)。
另外,直接执行 select (*) from t1; 时,也可以利用到索引的,并不一定是全表扫描,也可以扫描某个索引 B+ 树的叶子节点,从而得到总条数,因为不管是什么索引,主键索引还是辅助索引,实际上它们在叶子节点的数量是一样的,只不过字段数不一样,主键索引存了全部字段,而辅助索引只存了定义的索引字段 + 主键字段,所以通常辅助索引是更占用空间的,因此遍历起来也会更快,但是记录条数是一样的。
二、你是如何理解最左前缀原则的?
这个原则表明,只有在复合索引的左侧部分的列上,条件才能被优化。换句话说,当使用复合索引时,查询的条件应该从索引的最左侧列开始,才能最大化利用索引
我们创建一个简单的示例表,命名为employees,并在其上创建一个复合索引。表结构如下:
sql
CREATE TABLE employees (
id INT AUTO_INCREMENT PRIMARY KEY,
first_name VARCHAR(50),
last_name VARCHAR(50),
age INT,
department VARCHAR(50),
INDEX idx_name_age (last_name, first_name, age)
);接下来,我们插入一些实例数据
sql
INSERT INTO employees (first_name, last_name, age, department) VALUES
('John', 'Doe', 30, 'HR'),
('Jane', 'Doe', 25, 'IT'),
('Mary', 'Smith', 35, 'Finance'),
('Michael', 'Johnson', 40, 'IT'),
('Emily', 'Davis', 29, 'HR');符合最左前缀原则的查询SQL
sql
SELECT * FROM employees WHERE last_name = 'Doe' AND first_name = 'Jane' AND age=25;
SELECT * FROM employees WHERE first_name = 'Jane' AND last_name = 'Doe' AND age=30;
SELECT * FROM employees WHERE age=30 AND last_name = 'Doe' AND first_name = 'Jane';对于上面这些查询,MySQL会使用idx_name_age索引,从这能够看出,以上SQL都能走索引,和Where条件顺序没有关系
sql
+----+-------------+-----------+-------+---------------+---------+---------+------+-------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-----------+-------+---------------+---------+---------+------+-------+-------------+
| 1 | SIMPLE | employees | range | idx_name_age | idx_name_age | 100 | NULL | 2 | Using where |
+----+-------------+-----------+-------+---------------+---------+---------+------+-------+-------------+在这个执行计划中,我们看到type是range,说明MySQL正在使用idx_name_age索引,并且只检查了大约2行数据。
那如果把last_name去掉呢?
不符合最左前缀原则的查询
sql
SELECT * FROM employees WHERE first_name = 'Jane' AND age = 25;对于这个查询,MySQL不会使用复合索引idx_name_age,因为它没有从最左侧的列last_name开始。
通过Explain执行计划,查看索引执行情况
sql
+----+-------------+-----------+-------+---------------+------+---------+------+-------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-----------+-------+---------------+------+---------+------+-------+-------------+
| 1 | SIMPLE | employees | ALL | NULL | NULL | NULL | NULL | 5 | Using where |
+----+-------------+-----------+-------+---------------+------+---------+------+-------+-------------+在这个执行计划中,我们看到type是ALL,这意味着MySQL没有使用任何索引,而是进行了全表扫描,这样效率较低。
最近无意间获得一份阿里大佬写的刷题笔记,一下子打通了我的任督二脉,进大厂原来没那么难。这是大佬写的, 7701页的BAT大佬写的刷题笔记,让我offer拿到手软
总结
从这可以看出,所谓的最左前缀原则的"最左",并不是指where条件中的last_name一定要在最左边,而是指where条件中一定要给出定义联合索引的最左边字段,比如我们定义"last_name, first_name, age"联合索引的SQL为:
sql
INDEX idx_name_age (last_name, first_name, age)其中last_name字段是最左边的字段,因此如果想要走idx_name_age索引,那么SQL一定要给出last_name字段的条件,这才是"最左"的意思。
三、你是如何理解行锁、GAP锁、临健锁的?
1、行数
行锁是对具体数据行的锁定,允许多个事务并发操作不同行,只有在同一行上进行写入时才会阻塞其他事务
假设我们有如下表结构和数据:
sql
CREATE TABLE employees (
id INT AUTO_INCREMENT PRIMARY KEY,
first_name VARCHAR(50),
last_name VARCHAR(50),
age INT,
department VARCHAR(50)
);如果事务A更新了某个特定员工的信息:
sql
-- 事务A
START TRANSACTION;
UPDATE employees SET age = 31 WHERE last_name = 'Doe';在这个过程中,行锁会被加在last_name = 'Doe'所对应的行上(即John和Jane)。如果此时事务B尝试更新同一行:
sql
-- 事务B
START TRANSACTION;
UPDATE employees SET age = 29 WHERE last_name = 'Doe';事务B会被阻塞,直到事务A提交或回滚,因为事务A、事务B加的都是排它锁,也叫悲观锁。这样行锁确保了数据的一致性。
GAP锁
行锁锁的是某一行,而GAP锁锁的是行前面的间隙,注意只是行前面的间隙,你可能会问那表的最后一行前后都有间隙啊,最后一行后面的间隙不锁吗?
当然会锁了,只不,过是交给了一个叫做PAGE_NEW_SUPREMUM的记录来说,你可以理解为PAGE_NEW_SUPREMUM记录是InnoDB默认的,它固定作为最后一条记录,因此只要锁住PAGE_NEW_SUPREMUM前面的间隙,就相当于锁住了我们所理解的最后一行后面的间隙。
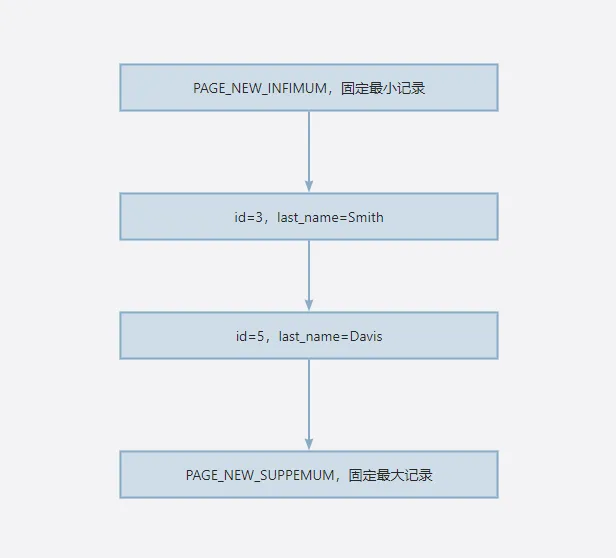
临健锁(Next-Key Lock)
临界锁是行锁和GAP锁的结合,锁定具体的数据行以及行之间的空隙。它用于确保在一个范围内的查询中,不仅防止了幻读,还能保护行数据
继续使用之前的例子,假设我们执行了如下操作:
sql
-- 事务D
START TRANSACTION;
SELECT * FROM employees WHERE last_name >= 'D' FOR UPDATE;在此查询中,MySQL会对所有last_name为'D'及其后的行加上行锁,同时对'D'之前的空隙加上GAP锁,这样可以防止在该范围内插入新的行。
四、你是如何理解MVCC的?
OCR识别结果出现了一些错误和混乱,导致内容不够清晰。虽然识别不是很理想,但我将根据我的理解和相关知识,概述该图片可能传达的内容。
如何理解MVCC?
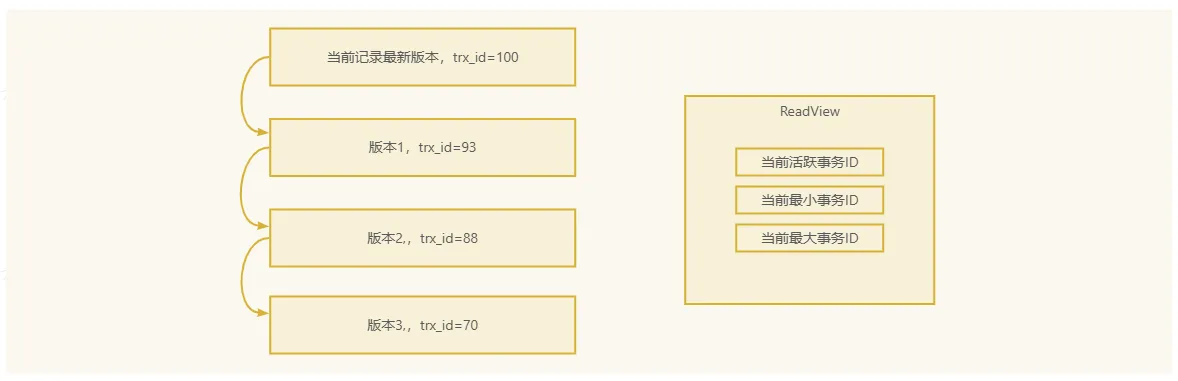
所谓MVCC就是多版本并发控制,MySQL为了实现可重复读这个隔离级别,而且为了不采用锁机制来实现可重复读,所以采用MVCC机制来实现。
主要概念
-
ReadView(读取视图):
- 当一个事务开始时,MVCC会创建一个
ReadView,该视图记录了当前可见的所有版本,包括哪些事务是活跃的,哪些事务已经提交。
- 当一个事务开始时,MVCC会创建一个
-
事务ID:
- 每个事务都有一个唯一的事务ID。在
ReadView中,会记录当前事务的ID、最小事务ID和最大事务ID。
- 每个事务都有一个唯一的事务ID。在
-
可见性规则:
- 如果一个事务的ID :
- 大于
ReadView中的最大事务ID:这个事务的更改对当前事务不可见。 - 属于
ReadView中的活跃事务:则该事务的更改不可见,因为该事务还在进行中。 - 小于
ReadView中的最小事务ID:该事务的更改是可见的,因为它已经提交。
- 大于
- 如果一个事务的ID :
MVCC的工作流程
-
创建 ReadView:
- 当事务开始时,MVCC会生成一个
ReadView。它会包含当前事务的ID、活跃事务的ID以及最大和最小事务ID。
- 当事务开始时,MVCC会生成一个
-
读取数据:
- 当事务读取数据时,它将参考
ReadView中的信息,以确定哪些版本的数据是可见的。
- 当事务读取数据时,它将参考
-
更新数据:
- 当事务更新数据时,MVCC不会直接覆盖原有的数据,而是创建一个新的版本。只有在所有引用该数据的事务完成后,才会清理旧版本。
总结
MVCC允许多个事务在不干扰彼此的情况下同时进行操作,这极大地提高了数据库的并发性能。通过维护数据的多个版本,MVCC保证了数据的一致性和隔离性,同时减少了锁的竞争。
最近无意间获得一份阿里大佬写的刷题笔记,一下子打通了我的任督二脉,进大厂原来没那么难。这是大佬写的, 7701页的BAT大佬写的刷题笔记,让我offer拿到手软
五、你是如何理解Online DDL的?
Online DDL 是指在不影响数据库服务的情况下,修改数据库表的结构。通俗点说,就是我们可以在数据库正常运作的同时,对表进行调整,比如新增列、修改字段类型、添加索引等,而不需要停机维护。
般的DDL操作,比如新增一个字段,会有以下几个步骤
1. 解析与检查
MySQL 首先会对 DDL 语句进行解析,确保语法正确。例如:
sql
ALTER TABLE users ADD COLUMN age INT;MySQL 会检查表 users 是否存在,新增的 age 字段是否与已有的字段冲突(比如字段名重复),数据类型是否支持等。
2. 表的元数据锁(metadata lock)
在进行任何表结构变更之前,MySQL 会对表加一个元数据锁(MDL)。元数据锁的作用是防止在变更结构的同时,其他 DDL 操作对表进行修改,保证表结构一致性。
类比:元数据锁就像在超市里装货架时,防止其他人也来同时更改货架位置,避免混乱。
3. 创建临时表
当我们执行 ALTER TABLE 语句时,MySQL 会创建一个临时表。这个临时表是现有表的一个复制品,并且会按照我们的要求增加新的字段。
临时表的步骤:
- 复制原表结构 :MySQL 会复制原表的结构到一个临时表中,并加上我们新增的字段,比如
age。 - 复制数据:MySQL 将原表中的所有数据行逐行复制到临时表中,同时为每一行填充新增加字段的默认值(如果有)。
类比:这就像超市货架升级时,先在仓库里搭建一个新的货架模型,放置相同的商品,同时增加新的商品存放区。
4. 切换表
当 MySQL 完成了数据复制后,它会将原表和临时表进行替换。此时,临时表变成了正式的表,包含了新字段。
- 在这个过程中,所有的 DML(增删改查)操作都会暂时被挂起,直到替换完成。这段时间很短暂,对服务的影响非常小。
类比:就像仓库里的新货架搭建好后,把它搬进超市,同时替换掉旧货架。顾客几乎不会察觉到这个过程。
5. 删除旧表
原始的表被新表替换后,MySQL 会自动删除旧表的元数据,释放空间。这一步在后台完成,不影响数据库的正常操作。
6. 释放锁
当所有操作完成后,MySQL 会释放元数据锁,允许其他 DDL 或 DML 操作继续进行。
总结:
- 解析语句并检查合法性。
- 对表加元数据锁(防止冲突的结构变更)。
- 创建临时表,并将数据从旧表复制到临时表。
- 替换旧表,删除旧表的元数据。
- 释放锁。
注意 :这种方法在不使用 Online DDL 的情况下,可能导致大量的数据复制操作,进而对性能有影响,尤其是表数据量较大时。
六、你知道哪些情况下会导致索引失效
在 MySQL 中,索引是提高查询效率的关键工具,但有时可能会遇到索引失效的情况,导致查询性能大幅下降。这种情况通常与查询语句的写法、数据类型的选择以及数据库的优化机制有关。下面是几种常见会导致索引失效的场景:
1. 使用 LIKE 时通配符放在前面
如果在 LIKE 语句中,通配符 % 放在字符串的开头,会导致索引失效。因为在这种情况下,MySQL 无法通过索引快速定位到符合条件的记录,而需要扫描所有记录。
示例:
sql
SELECT * FROM users WHERE name LIKE '%abc'; -- 索引失效这种写法会使得 MySQL 扫描全表,而如果写成 LIKE 'abc%',索引仍然有效。
类比:这就像你在一大堆文件中查找名字以"abc"开头的文件名,你可以直接找到相应的部分,但如果是查找名字包含"abc"的文件,你就得看每个文件名。
2. 数据类型不一致
当查询条件中的字段类型与索引字段的类型不一致时,MySQL 可能不会使用索引。它会先对数据进行类型转换,而类型转换会导致无法高效利用索引。
示例:
假设 id 是一个整型字段:
sql
SELECT * FROM users WHERE id = '123'; -- 索引失效这里的 '123' 是字符串,MySQL 会进行隐式转换,因此索引失效。
3. 对索引字段使用函数
如果在查询中对索引字段使用了函数或运算操作,MySQL 不能通过索引来查询,导致索引失效。
示例:
sql
SELECT * FROM users WHERE YEAR(created_at) = 2023; -- 索引失效这里 YEAR(created_at) 是对 created_at 字段进行了函数操作,因此 MySQL 无法直接使用索引进行查找。
类比:这就像你想按某种规律排列的列表中查找内容,但你需要先改变它的形式才能找到,导致效率下降。
4. 使用 OR 关键字
当 OR 条件中的某一列没有索引时,整个查询的索引都会失效。
示例:
sql
SELECT * FROM users WHERE id = 1 OR name = 'Alice'; -- 索引失效假设 id 列有索引,而 name 列没有索引,那么这个查询就不能利用索引,MySQL 需要进行全表扫描。
优化方式 :为
name字段单独建立索引,或者改写查询逻辑,避免OR导致的索引失效。
5. 不等条件 (!= 或 <>)
使用不等于操作符(!= 或 <>)时,MySQL 不能有效使用索引,会导致全表扫描。
示例:
sql
SELECT * FROM users WHERE age != 30; -- 索引失效这类查询通常会导致索引失效,因为 MySQL 无法通过索引定位所有满足 != 的记录。
6. 范围查询 (>, <, BETWEEN) 后的列
在复合索引(即多列索引)中,当第一个字段使用了范围查询时,后续的字段的索引可能会失效。
示例:
假设我们有一个复合索引 (age, name),如下查询:
sql
SELECT * FROM users WHERE age > 30 AND name = 'Alice'; -- `name` 索引失效在这种情况下,由于 age 使用了范围查询,name 列的索引将失效,MySQL 无法通过复合索引直接查找。
7. 索引列前加上 IS NULL 或 IS NOT NULL
对于索引列使用 IS NULL 或 IS NOT NULL,有时 MySQL 可能不会利用索引,尤其是在大量数据存在 NULL 值的情况下,MySQL 会认为索引的使用不划算。
示例:
sql
SELECT * FROM users WHERE name IS NOT NULL; -- 可能索引失效8. 查询条件中使用 NOT IN 或 NOT EXISTS
使用 NOT IN 或 NOT EXISTS 也可能会导致 MySQL 不使用索引,从而引发全表扫描。
示例:
sql
SELECT * FROM users WHERE id NOT IN (1, 2, 3); -- 索引失效9. 表中的数据量很小
当表中的数据量很小,MySQL 可能认为全表扫描比使用索引更高效。在这种情况下,MySQL 会选择直接扫描而不是通过索引查找。
类比:如果你只有几个文件需要查找,花时间先创建目录索引反而不划算,直接扫描全部文件更快。
10. MySQL 优化器选择不使用索引
有时,即便索引可用,MySQL 的查询优化器可能会根据表的统计信息和成本估算,认为全表扫描比使用索引更快,从而放弃索引。
总结:
索引失效通常与查询语句的写法、数据类型、函数使用、以及 MySQL 查询优化器的决策有关。为了避免索引失效,需要尽量避免上述常见的情况,如:
- 在
LIKE查询中避免通配符%开头 - 保持数据类型一致
- 尽量不对索引列使用函数或运算操作
- 合理规划复合索引中的查询顺序
七、你是如何理解MySQL的filesort的?
通俗的理解,可以把 filesort 理解为数据库的"备用排序方式"。当查询中的 ORDER BY 语句无法利用索引中的排序顺序时,MySQL 就会启用 filesort 来手动排序结果。
什么时候会触发 filesort?
MySQL 会在某些情况下使用 filesort,比如:
-
没有合适的索引 :
当查询中的
ORDER BY字段没有索引,MySQL 无法利用索引顺序,只能借助filesort来进行排序。示例:
sqlSELECT * FROM users ORDER BY age;假设
users表中没有age字段的索引,这时候 MySQL 会进行filesort。 -
多列排序,但索引不匹配 :
当我们对多个列进行排序,而这些列没有被索引覆盖或索引顺序与排序要求不符时,
filesort也会被触发。示例:
sqlSELECT * FROM users ORDER BY age, name;假设表上只有
age的索引,但没有(age, name)的复合索引,那么 MySQL 会使用filesort。 -
组合查询或函数操作导致索引失效 :
当查询中对字段进行计算或函数操作时,即便这些字段有索引,也无法直接利用索引进行排序。
示例:
sqlSELECT * FROM users ORDER BY LENGTH(name);LENGTH(name)是一个函数操作,MySQL 需要手动排序,因此会使用filesort。
filesort 的工作方式:
filesort 实际上有两种实现方式,取决于 MySQL 的版本和配置:
-
单行数据排序 (Older Versions):MySQL 会把查询结果的所有行都放入一个缓冲区,然后根据
ORDER BY字段逐行比较并排序。这种方式效率相对较低,因为要处理的数据量很大。 -
两次扫描排序 (Optimized Versions):在较新的 MySQL 版本中,
filesort会进行优化,只会在第一次扫描时收集需要排序的字段和ROW_ID,然后通过排序后的ROW_ID再去读取整行数据。这种方式减少了排序的数据量,提高了性能。
filesort 性能的影响:
filesort 并不是说每次都会涉及磁盘操作,它有可能在内存中完成,但当数据量较大时,内存不足以完成排序,就可能将数据写入磁盘进行排序,这样会影响性能。
MySQL 有两个重要的参数控制 filesort 行为:
-
sort_buffer_size:这是 MySQL 用来在内存中排序的缓冲区大小。如果排序的数据能放进这个缓冲区,排序就会在内存中完成;否则,MySQL 会将部分数据写入磁盘,从而影响性能。 -
max_length_for_sort_data:控制 MySQL 采用哪种filesort方法(单行排序或两次扫描排序)。对于较短的数据,MySQL 更可能选择效率较高的两次扫描排序方式。
如何避免或优化 filesort?
-
使用合适的索引 :
最直接的办法就是为查询中的排序字段创建索引。尤其是在有
ORDER BY子句时,确保创建了复合索引可以有效避免filesort。示例:
sqlCREATE INDEX idx_age_name ON users (age, name); -
增加
sort_buffer_size:如果无法避免
filesort,可以通过增加sort_buffer_size的大小,确保更多数据可以在内存中排序,减少磁盘 I/O。 -
减少排序的数据量 :
使用
LIMIT来限制查询结果集的大小,可以减少需要排序的数据量,从而减小filesort的开销。示例:
sqlSELECT * FROM users ORDER BY age LIMIT 100; -
尽量避免对排序字段使用函数 :
在
ORDER BY中,尽量不要对排序字段进行函数运算或表达式操作,这样可以增加 MySQL 使用索引的可能性。
总结:
filesort 是 MySQL 中的一种排序机制,当查询结果无法通过索引顺序排序时,MySQL 就会启用 filesort 进行手动排序。虽然名字中有"file",但排序未必一定涉及磁盘操作,内存中的排序也是常见的。filesort 是 MySQL 的备用排序方式,尽管有时不可避免,但我们可以通过创建索引、调整缓冲区大小等方式来优化它的性能。
八、你知道哪些情况下会锁表吗?
一、常见的锁表情况
1. DDL 操作(数据定义语言)
当执行一些结构性变更的操作(例如 ALTER TABLE、CREATE TABLE、DROP TABLE)时,MySQL 会锁住整个表,防止其他线程对该表进行操作。这种锁是元数据锁(Metadata Lock),用来保证表结构的变更不会与其他并发操作发生冲突。
示例:
sql
ALTER TABLE users ADD COLUMN age INT;此操作会锁表,其他对 users 表的操作会被阻塞,直到变更完成。
2. 全表扫描的 UPDATE 或 DELETE 操作
当你执行一个 UPDATE 或 DELETE 操作且未使用索引时,MySQL 可能会锁住整个表进行更新或删除,因为它必须扫描所有行。
示例:
sql
UPDATE users SET age = 30 WHERE name LIKE '%John%'; -- 如果没有索引,可能锁表由于 LIKE '%John%' 无法利用索引,MySQL 需要全表扫描,并对整个表加锁。
3. 事务中的写操作(INSERT、UPDATE、DELETE)
在 InnoDB 存储引擎中,写操作会对数据行加上行锁 (Row Lock)。但是在某些情况下(如没有索引的情况下),MySQL 可能会退化为表锁(Table Lock)。即使是行锁,在长事务未提交或回滚的情况下,也可能阻塞其他事务,从而产生间接的锁表现象。
示例:
sql
BEGIN;
UPDATE orders SET status = 'shipped' WHERE order_id = 1234; -- 行锁,但可能锁表
COMMIT;如果该事务运行了很长时间,并且其他操作也需要访问 orders 表中的记录,可能会导致等待。
4. LOCK TABLES 显式加锁
MySQL 支持使用 LOCK TABLES 命令显式地对表加锁,分为读锁(READ LOCK) 和写锁(WRITE LOCK)。在写锁期间,其他线程不能对该表进行任何读或写操作;在读锁期间,其他线程只能读表,而不能写表。
示例:
sql
LOCK TABLES users WRITE; -- 对 `users` 表加写锁此时,其他线程对 users 表的任何读写操作都会被阻塞,直到锁被释放。
5. 大批量插入数据
当你使用某些批量插入语句(如 INSERT INTO ... SELECT ... 或 INSERT IGNORE)插入大量数据时,如果没有恰当的索引,MySQL 可能会锁表,尤其是在 MyISAM 存储引擎中。
示例:
sql
INSERT INTO new_users SELECT * FROM users WHERE created_at > '2023-01-01'; -- 可能锁表如果 created_at 没有索引,MySQL 需要锁表来完成整个插入操作。
6. 外键约束检查
在 InnoDB 中,当插入或删除涉及到外键约束的数据时,MySQL 可能会锁住父表或子表,确保数据的完整性。虽然 InnoDB 大多情况下会使用行锁,但在某些复杂的情况下,比如没有合适的索引,可能会导致表锁。
示例:
sql
DELETE FROM orders WHERE order_id = 100; -- 触发外键约束检查,可能锁住 `customers` 表如果 orders 表有外键关联到 customers 表,且没有合适的索引,可能会锁住 customers 表。
7. MyISAM 存储引擎的读写操作
在 MyISAM 存储引擎中,写操作会锁住整个表,即使只修改了一行。读操作之间不会互相阻塞,但读写操作之间会发生阻塞。因此,MyISAM 表在处理高并发写操作时可能会频繁锁表。
示例:
sql
INSERT INTO myisam_table (name, age) VALUES ('John', 30); -- 写锁锁住整个表如果有大量的写操作,表会频繁被锁住,影响并发性能。
二、如何避免锁表?
锁表会影响数据库的并发性和性能,因此我们通常需要尽量避免。这里有一些方法可以减少锁表的发生:
1. 使用合适的存储引擎
尽量使用 InnoDB 存储引擎,它支持行级锁 ,可以在绝大多数情况下避免锁表。相比之下,MyISAM 使用的是表级锁,在并发读写场景下性能较差。
2. 创建合适的索引
通过为查询条件中的列创建适当的索引,避免全表扫描。例如,如果你经常根据 name 字段进行查询和更新,应该为 name 字段创建索引:
sql
CREATE INDEX idx_name ON users (name);索引可以有效减少锁表的可能性。
3. 减少长事务
长时间未提交的事务会持有锁,从而阻塞其他查询。因此,尽量缩短事务的执行时间,确保在事务中尽快完成操作并提交。
4. 使用 OPTIMIZE 和 ANALYZE 慎重
这些命令会锁住表的元数据,阻止并发的读写操作。运行这些命令时应避免高并发时间段。
5. 分批次操作
如果需要执行大量的 UPDATE 或 DELETE,可以将操作分批执行,以减少每次操作涉及的数据量,避免长时间锁表。
示例:
sql
DELETE FROM users WHERE created_at < '2022-01-01' LIMIT 1000; -- 分批删除6. 避免显式表锁
尽量避免使用 LOCK TABLES 进行显式加锁操作,尤其是在高并发场景下。InnoDB 的事务机制和行级锁已经足够应对大多数并发问题。
九、你是如何理解MySQL中的死锁机制的?
在 MySQL 中,死锁(Deadlock)是指两个或多个事务互相等待对方持有的锁,导致它们都无法继续执行。这是一种常见的并发问题,尤其是在高并发情况下,事务在访问相同的数据资源时容易产生死锁。
通俗理解:
可以把死锁类比为两个人走在一条窄路上,他们都需要对方让路才能继续前进。A 挡住了 B 的路,B 又挡住了 A 的路,谁也不肯退让,结果两个人都卡住了。这在数据库中表现为事务 A 等待事务 B 释放资源,而事务 B 同时也在等待事务 A 释放资源,最终两个事务都无法继续。
死锁的产生过程:
- 事务 A 获取资源 X 的锁。
- 事务 B 获取资源 Y 的锁。
- 事务 A 尝试获取资源 Y 的锁,但资源 Y 被事务 B 锁住,于是事务 A 进入等待状态。
- 事务 B 尝试获取资源 X 的锁,但资源 X 已经被事务 A 锁住,事务 B 也进入等待状态。
- 结果是:事务 A 等待 B,事务 B 等待 A,形成一个循环等待,产生死锁。
MySQL 中的死锁机制:
MySQL 使用的存储引擎 InnoDB 提供了行级锁,这虽然减少了锁冲突的概率,但也更容易导致死锁。InnoDB 遇到死锁时,会主动检测并解决这个问题,通过回滚其中一个事务来打破僵局。
死锁的处理方式:
在 MySQL 中,当 InnoDB 检测到死锁时,它会选择回滚代价最小的事务,通常是回滚锁定较少资源的事务。然后,它会向客户端返回一个错误消息,类似于:
ERROR 1213 (40001): Deadlock found when trying to get lock; try restarting transaction当一个事务被回滚后,另一个事务可以继续执行,解决了死锁问题。
如何避免死锁?
尽管 MySQL 能自动检测并处理死锁,但频繁出现死锁会影响系统性能,因此尽量避免死锁是很有必要的。以下是一些常见的避免死锁的方法:
1. 固定锁的顺序
确保所有事务在访问多张表或多条记录时,遵循相同的顺序锁定资源。这样可以避免不同事务间出现交叉锁定,减少死锁的可能性。
示例:
所有事务在更新 users 表和 orders 表时,都先锁住 users 表,再锁住 orders 表,避免死锁。
2. 减少锁定范围
尽量减少每个事务锁定的范围和时间,避免长时间占用锁。例如,尽量缩短事务的执行时间,减少不必要的查询。
示例:
sql
BEGIN;
UPDATE users SET age = age + 1 WHERE id = 1;
COMMIT;尽量避免在一个事务内进行过多的操作或等待用户输入。
3. 使用合适的索引
在查询时尽量使用索引来减少锁定的行数,特别是在 UPDATE 和 DELETE 操作时,合适的索引可以减少锁定的行数,从而降低死锁的风险。
示例:
为 user_id 创建索引:
sql
CREATE INDEX idx_user_id ON orders (user_id);4. 减少并发量
控制数据库的并发访问量,如果可能的话,避免在高并发情况下进行大批量数据操作。高并发访问会增加死锁的概率。
5. 合理设置事务隔离级别
使用合适的事务隔离级别可以减少锁定冲突。InnoDB 支持多种事务隔离级别,最常见的是 REPEATABLE READ 和 READ COMMITTED 。其中,READ COMMITTED 隔离级别可以减少锁争用的情况,从而降低死锁发生的概率。
示例:
sql
SET TRANSACTION ISOLATION LEVEL READ COMMITTED;6. 通过批量操作减少锁定的时间
如果需要对大量数据进行更新或删除操作,可以考虑分批处理,减少每次事务锁定的行数,从而降低死锁风险。
示例:
sql
DELETE FROM orders WHERE order_date < '2023-01-01' LIMIT 1000;使用 LIMIT 分批删除旧数据。
如何检测死锁?
当死锁发生时,InnoDB 会在错误日志中记录下死锁信息,包含了死锁的相关信息以及导致死锁的事务和查询。可以通过以下 SQL 语句获取死锁信息:
sql
SHOW ENGINE INNODB STATUS;这条命令会显示 InnoDB 的状态信息,其中包含最近一次死锁的详细信息,包括参与死锁的事务和锁的等待情况。
十、你是如何优化慢查询的?
慢查询的优化步骤和方法:
1. 分析慢查询日志
首先,确保慢查询日志(Slow Query Log)已开启,这是 MySQL 用来记录执行时间超过指定阈值的查询。你可以通过分析这些日志,找出系统中耗时最长的查询。
启用慢查询日志:
sql
SET GLOBAL slow_query_log = 'ON';
SET GLOBAL long_query_time = 1; -- 设置慢查询阈值为 1 秒之后,你可以查看慢查询日志来了解哪些查询执行时间过长,并从这些查询中入手进行优化。
2. 使用 EXPLAIN 分析查询执行计划
使用 EXPLAIN 命令可以帮助你了解 MySQL 如何执行查询,它会提供信息如:查询是否使用了索引、扫描了多少行、排序方式等。你可以通过查看执行计划,发现查询中的性能瓶颈。
示例:
sql
EXPLAIN SELECT * FROM users WHERE name = 'John';执行结果会显示查询的类型(如 ALL、INDEX、RANGE 等),表明 MySQL 是否使用了全表扫描(ALL)或者索引(INDEX)。如果看到 ALL 表示全表扫描,这通常是需要优化的信号。
如何解读一些常见的结果:
- type :
ALL表示全表扫描,需要优化;range、ref或const表示使用了索引,性能较好。 - rows: 表示 MySQL 预计扫描的行数,越少越好。扫描的行数越多,查询的开销越大。
- key : 显示 MySQL 使用了哪个索引,如果显示为
NULL,表示没有使用索引。
3. 创建和优化索引
索引是 MySQL 优化慢查询的最常见手段之一。适当的索引可以显著减少查询的扫描行数,提升查询速度。
常见的索引优化策略:
- 单列索引 :对查询中常用的过滤条件或
WHERE子句中的字段创建索引。 - 复合索引 :对涉及多个条件的查询,创建复合索引。例如,
SELECT * FROM users WHERE age = 30 AND status = 'active';,可以为(age, status)创建一个复合索引。
示例:
sql
CREATE INDEX idx_name ON users (name);
CREATE INDEX idx_age_status ON users (age, status);- 覆盖索引:如果索引包含查询所需的所有字段,MySQL 可以直接从索引中读取数据,而无需访问表本身。这样能减少 I/O 操作,大幅提升查询效率。
示例:
sql
SELECT name FROM users WHERE age = 30; -- 如果 name 和 age 都在索引中,MySQL 可以只查索引- 避免索引失效 :确保查询条件能够正确利用索引。例如:
- 避免对索引字段使用函数或表达式,如
WHERE UPPER(name) = 'JOHN'会导致索引失效。 - 使用精确匹配,尽量避免
LIKE '%abc'这种通配符前缀的查询。
- 避免对索引字段使用函数或表达式,如
4. 优化查询语句
改进查询语句的写法可以大幅提升性能。以下是几种常见的优化建议:
- 选择合适的数据类型 :尽量使用合适的数据类型,避免使用过大的字段长度。比如,用
INT存储年龄,而不是用VARCHAR。 - 减少查询的返回结果 :避免
SELECT *,只查询需要的字段。返回的数据越少,查询速度越快。
示例:
sql
SELECT id, name FROM users WHERE age = 30; -- 避免 SELECT *,只取所需的字段-
分解复杂查询 :将复杂的查询拆分为多个小查询,有时能提升性能,尤其是在涉及多个关联表时。例如,把一个包含多个
JOIN的复杂查询,拆分成多次查询缓存中间结果。 -
使用
LIMIT优化分页 :在大表的分页查询中,避免扫描大量数据。可以通过主键或者索引结合LIMIT优化。
示例:
sql
SELECT * FROM users WHERE id > 1000 LIMIT 10; -- 基于索引的分页5. 优化 JOIN 操作
JOIN 操作在多表查询中常见,但它们容易导致性能问题,特别是当表很大时。优化 JOIN 时的注意事项:
- 确保连接条件字段有索引 :对于
JOIN中使用的字段,确保它们有合适的索引。
示例:
sql
SELECT * FROM orders o JOIN users u ON o.user_id = u.id WHERE u.status = 'active';在这种情况下,user_id 和 id 应该分别在 orders 和 users 表上有索引。
- 尽量减少关联表的数据量 :通过先筛选出需要的数据,再进行
JOIN操作。例如,将筛选条件放在子查询中,减少需要关联的行数。
示例:
sql
SELECT * FROM (SELECT id FROM users WHERE status = 'active') u JOIN orders o ON o.user_id = u.id;6. 调整 MySQL 配置参数
MySQL 的一些配置参数直接影响查询性能,特别是在高并发、大数据量场景下。以下是一些常见的优化参数:
-
innodb_buffer_pool_size:这是 InnoDB 的缓冲池大小,决定了 MySQL 可以用多少内存来缓存数据页。这个值通常设置为系统内存的 70%-80%,以便尽可能减少磁盘 I/O。 -
query_cache_size:如果系统中大量的查询结果是相同的,可以启用查询缓存,以减少重复查询的开销。需要注意的是,MySQL 8.0 中查询缓存被弃用,因为它对高并发场景可能带来性能瓶颈。 -
tmp_table_size和max_heap_table_size:这些参数决定了临时表可以在内存中使用的最大大小,增大这些参数的值,可以避免频繁将临时表写入磁盘,从而提高排序和GROUP BY查询的效率。
7. 使用分区表
如果你的表非常大,可以考虑使用分区表来优化查询性能。分区表将数据分成多个更小的物理子表,MySQL 可以根据查询条件直接定位到某个分区,从而减少扫描的数据量。
示例:
sql
CREATE TABLE orders (
order_id INT,
order_date DATE,
user_id INT,
...
) PARTITION BY RANGE (YEAR(order_date)) (
PARTITION p0 VALUES LESS THAN (2010),
PARTITION p1 VALUES LESS THAN (2015),
PARTITION p2 VALUES LESS THAN (2020),
PARTITION p3 VALUES LESS THAN MAXVALUE
);8. 避免死锁和长事务
如果某个慢查询是由于事务冲突或死锁造成的,应该尽量避免长事务或频繁锁表。通过控制事务范围、使用合适的隔离级别、避免大批量写操作等方式,减少锁等待和死锁的发生,从而加快查询速度。
9. 缓存
除了使用 MySQL 自身的查询缓存,你还可以使用应用层的缓存机制(如 Redis、Memcached),将频繁访问的数据缓存到内存中,减少数据库的访问频率。
示例:
python
# 在应用层缓存 MySQL 查询结果
cache.set('users:active', active_users, timeout=60*5) # 缓存 5 分钟总结:
- 分析慢查询日志 和使用
EXPLAIN了解执行计划是优化慢查询的第一步。 - 创建合适的索引可以显著提高查询速度,尤其是在大表中。
- 优化查询语句和
JOIN操作,尽量减少扫描的行数,并尽量使用索引覆盖查询。 - 通过调整MySQL 配置参数,提升系统对内存和资源的利用率。
- 在大表上使用分区表,并通过缓存减少对数据库的压力
最后说一句(求关注,求赞,别白嫖我)
最近无意间获得一份阿里大佬写的刷题笔记,一下子打通了我的任督二脉,进大厂原来没那么难。
这是大佬写的, 7701页的BAT大佬写的刷题笔记,让我offer拿到手软
本文,已收录于,我的技术网站 cxykk.com:程序员编程资料站,有大厂完整面经,工作技术,架构师成长之路,等经验分享
求一键三连:点赞、分享、收藏
点赞对我真的非常重要!在线求赞,加个关注我会非常感激!