文章目录
0.架构图
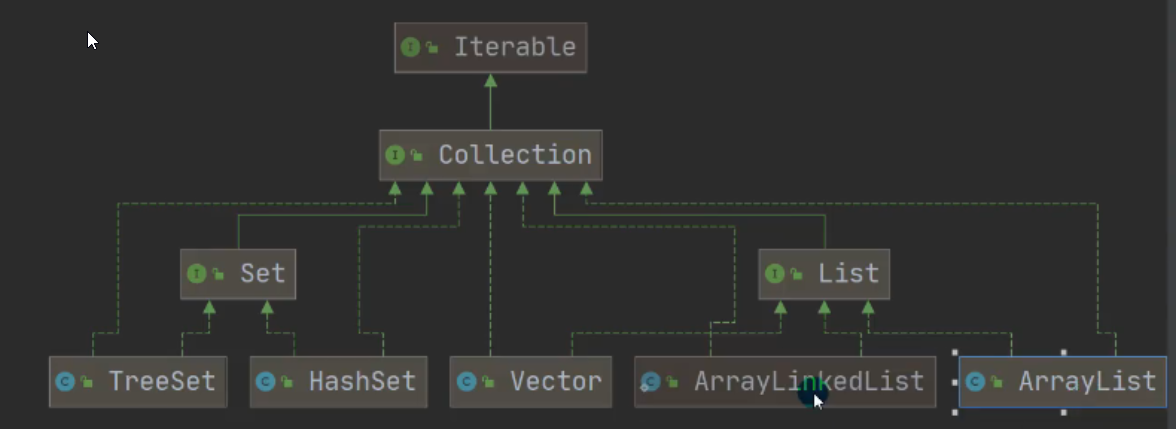
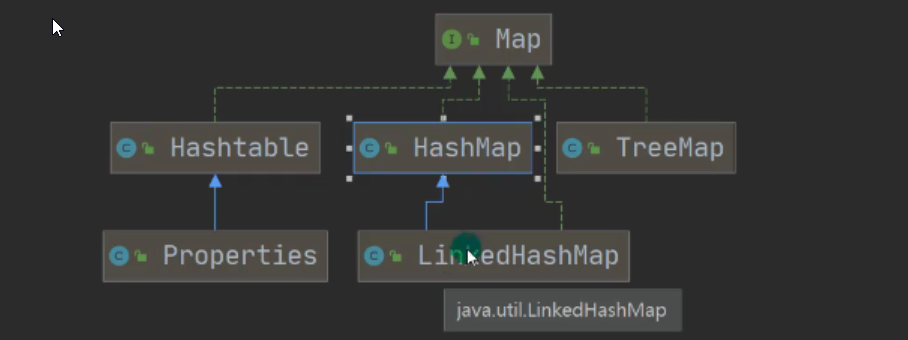
1.vector解析
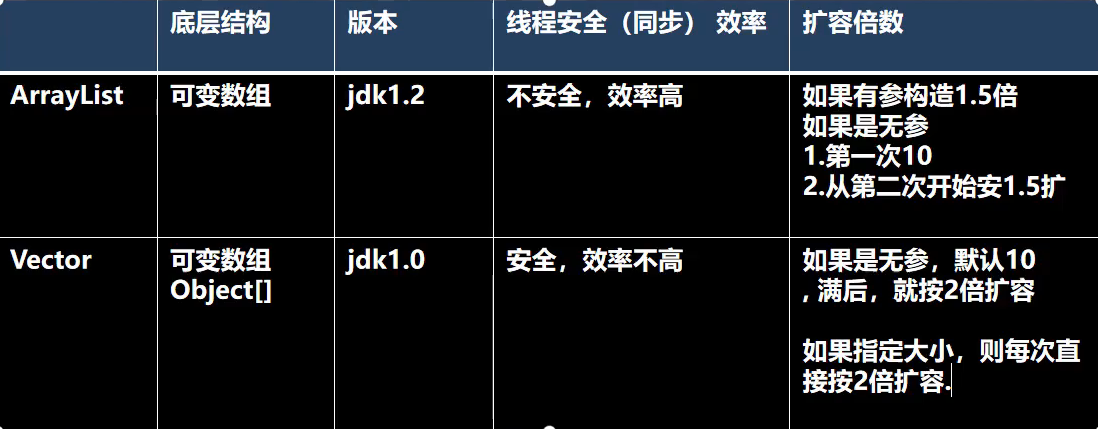
和之前介绍的这个ArrayList相比,这个vector属于线程安全操作,他的这个基本的使用和我们的这个Arraylist没有太大的区别,但是这个扩容机制和我们的这个Arraylist不太一样;
在默认的情况下,我们的这个空间容量的大小就是10,然后会按照2倍扩容,这个就是和Arraylist的一个区别,因此下面的这个add,前面的10个数据是不会进行扩容的,只有后面的add(10)才会进行这个扩容的操作;
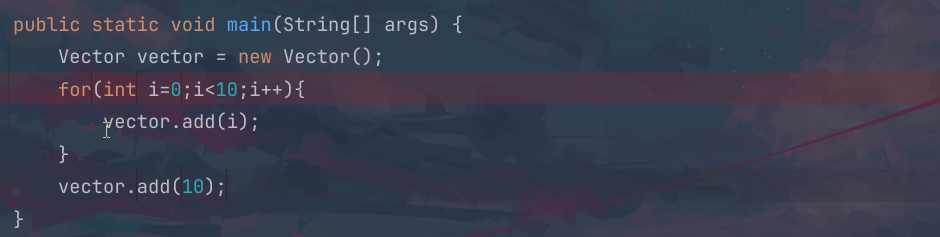
我们可以自己去进行debug调试,这个方法就是我们的s是一个默认的参数,当我们的数据长度小于这个数据的时候根本就不会进行grow里面去进行扩容,当我们的这个循环结束的时候,已经是插入10个数据,这个时候两个是相等的,才会调用这个grow方法;

在我们的这个grow方法里面,这个capacityIncrement小于0,对于这个三木而言,就是后面的这个oldcapacity作为结果操作,所以会进行这个二倍扩容,newcapacity就是10*2==20;
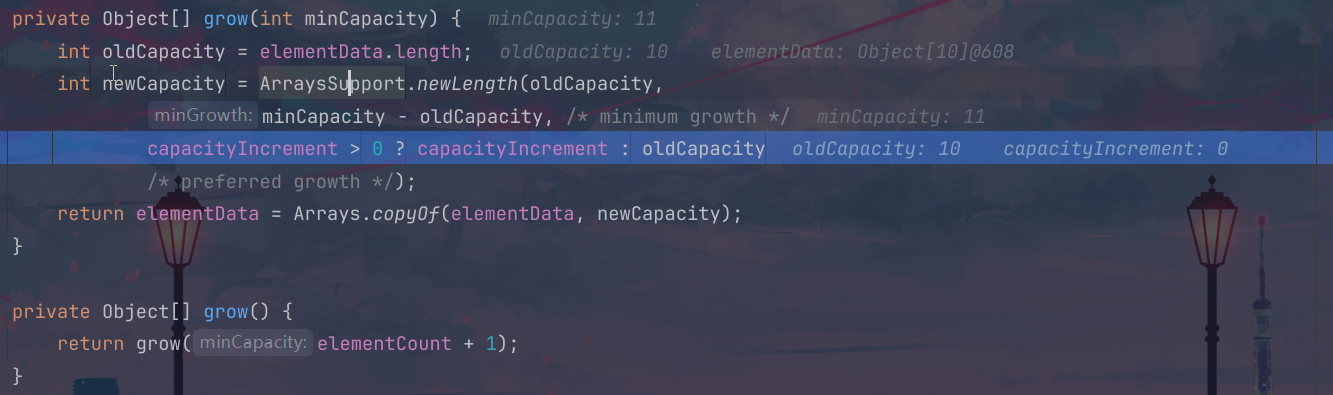
2.LinkedList分析
linkedlist的本质上就是一个双向的链表;
2.1源码分析
我们以添加节点和删除节点为例进行源码的分析:
首先我们创建这个lineedlist的时候就是进行的初始化的工作,这个时候双向链表里面是没有节点的,因此这个时候的size=0,然后去创建第一个节点;
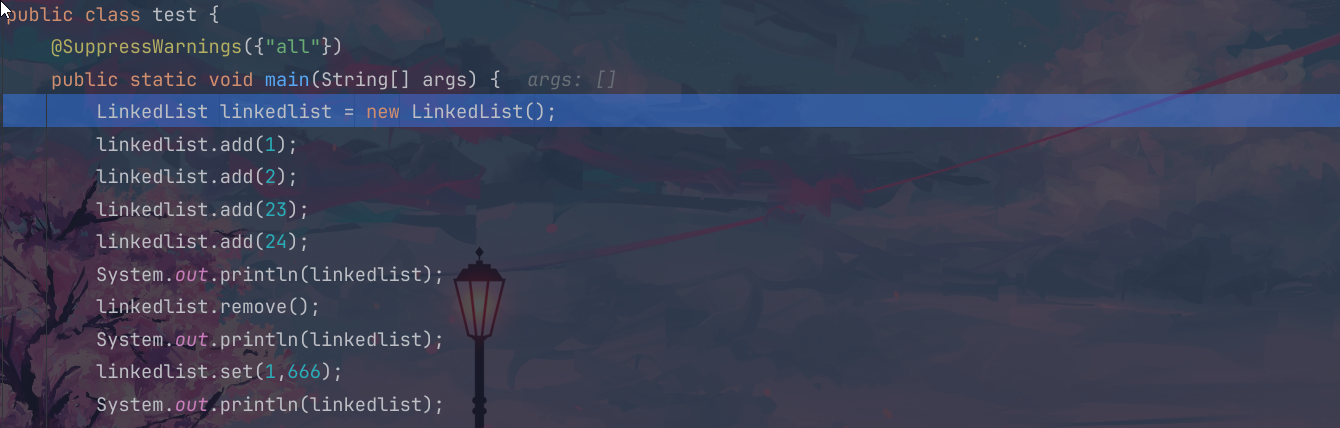
添加第一个节点的时候,可以看到这个首先还是进行的这个装箱的过程,把这个基本的数据类型转换为我们的常用类integer;

下面的这个是进行的第一次数据的插入过程:因为这个时候双向链表就是空的,所以这个时候我们的last,first都是指向的这个604地址空间位置;
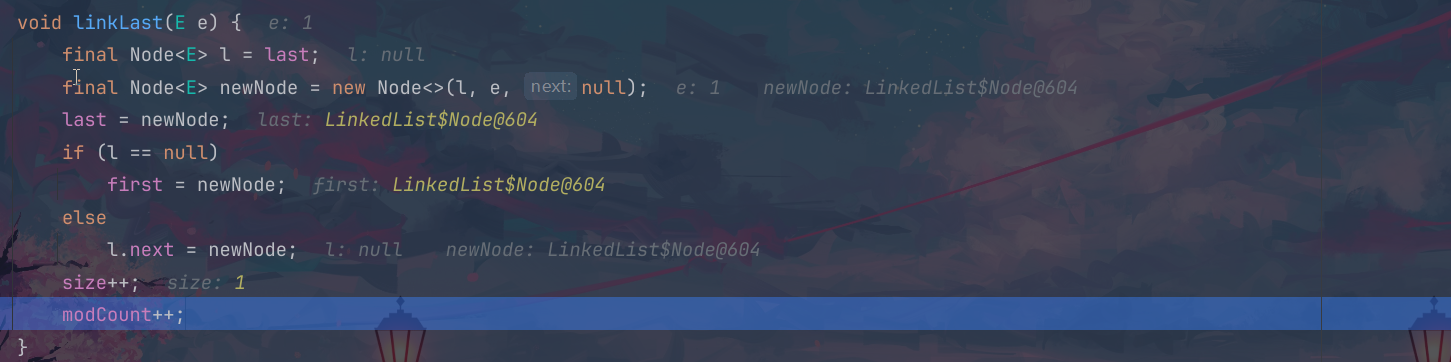
当我们插入第二个数据的时候,这个first指向的还是第一个位置的节点,但是这个last已经指向了新的节点,这个地址也是进行了更新:615;但是我们的这个l还是指向的第一个节点地址位置;
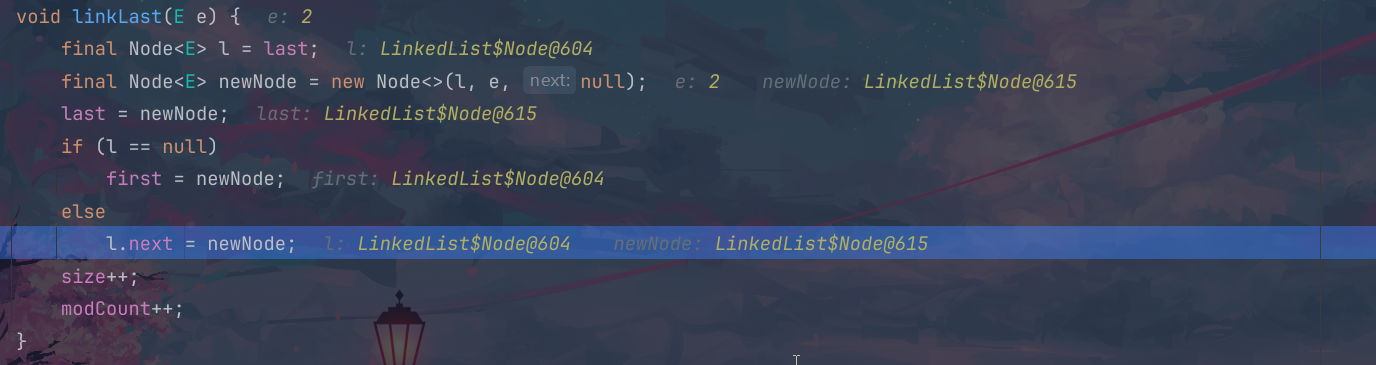
接下来再次进行数据的插入,这个时候我们的lat再次进行更新,这个l指向的还是我们的最后一个节点的前面的一个位置的地址;
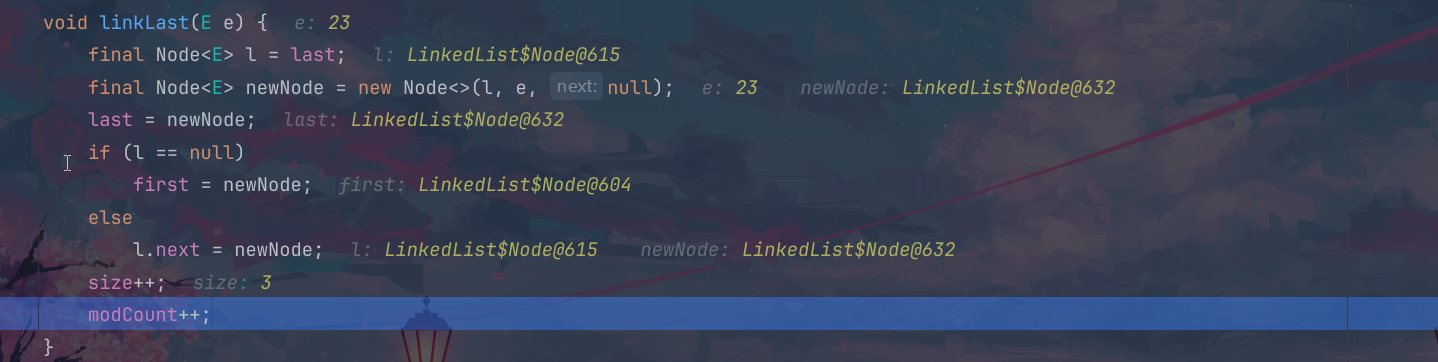
下面的这个是进行的remove方法的调用,这个时候就是删除我们的这个链表里面的第一个节点,使用的是这个unlinkFirst方法实现的;

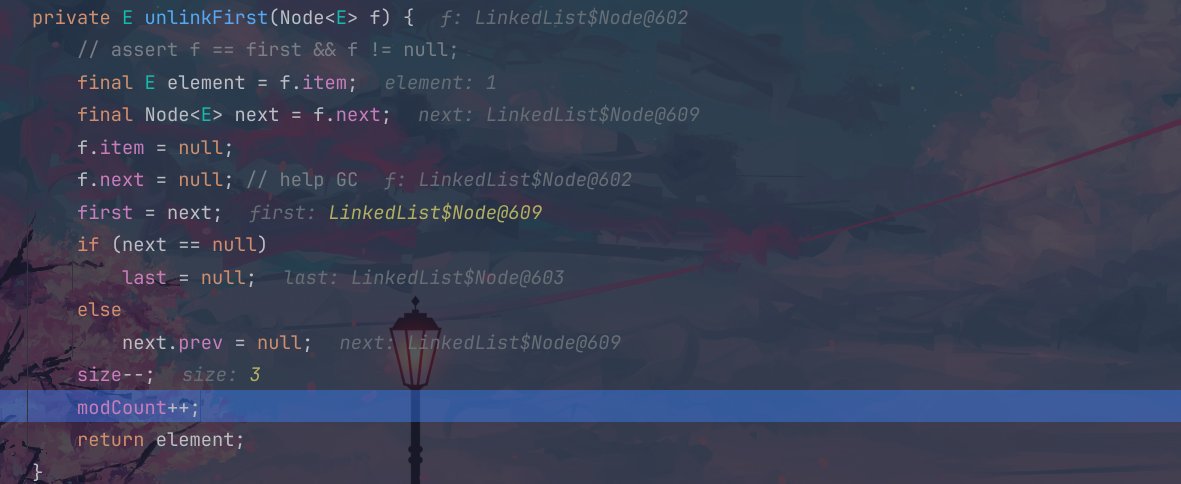
这个方法里面,叫这个f的数值变为null,指向的下一个节点也是空的,这个时候这个节点就会被作为垃圾回收掉,这个时候我们的第二个数据就是头结点,因此这个first指向了原来的609地址位置;
2.2迭代器遍历的三种方式
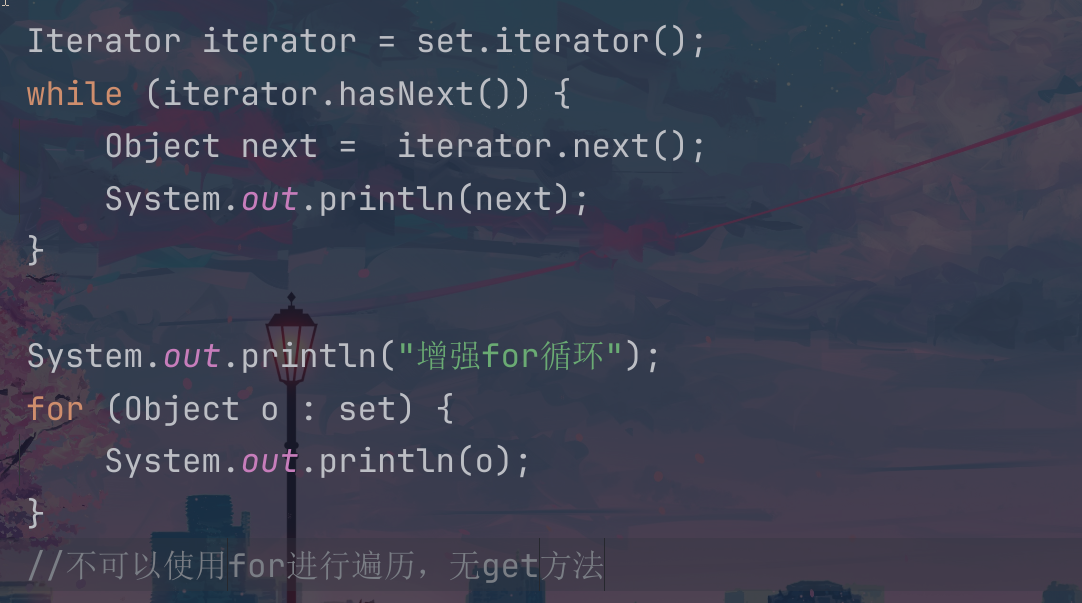
下面的这个就是我们的循环双向链表支持的三个遍历的方式,linkedlist.get(i)表示拿出来这个双向链表里面的第i个下标位置的节点数值;

3.set接口的使用方法
3.1基本使用说明
set接口实现类创建的实例化对象,即这个接口对象(实现这个接口的类的对象):
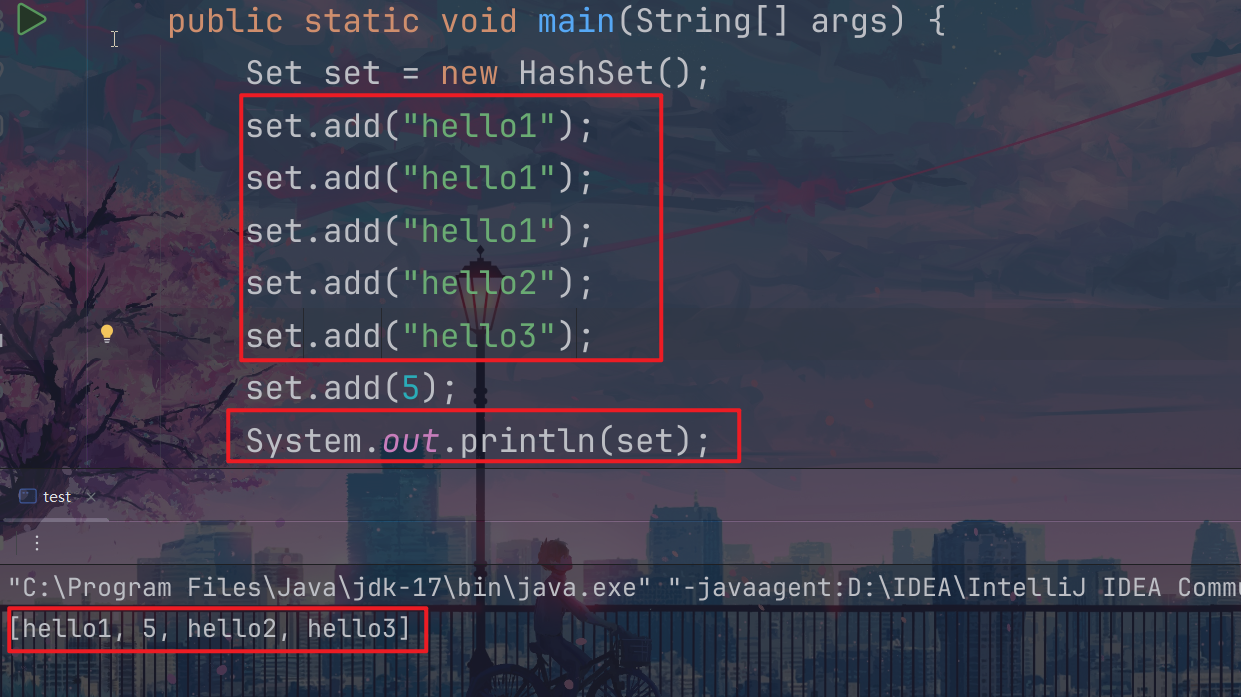
1.添加元素不可以是重复的;
2.没有顺序的:添加顺序和取出来的这个顺序不是一样的;
3.可以添加空值null;
4.取出来这个顺序虽然不是添加时候的这个顺序,但是这个取出来的顺序是固定的,不会每一次都发生变化;
set接口是collection的子接口,因此这个迭代器遍历set也是可以使用的:
3.2基本遍历方式
这个就是我们的迭代器遍历和增强for循环两个方式进行遍历;但是不支持这个普通的索引,因为这个里面是没有get方法的,没有办法根据下标进行数据的查找;
3.3HashSet引入
我们创建这个的时候实际上这个底层走的还是我们的hashmap这个东东;
hashset可以存放null值,但是元素不可以重复;
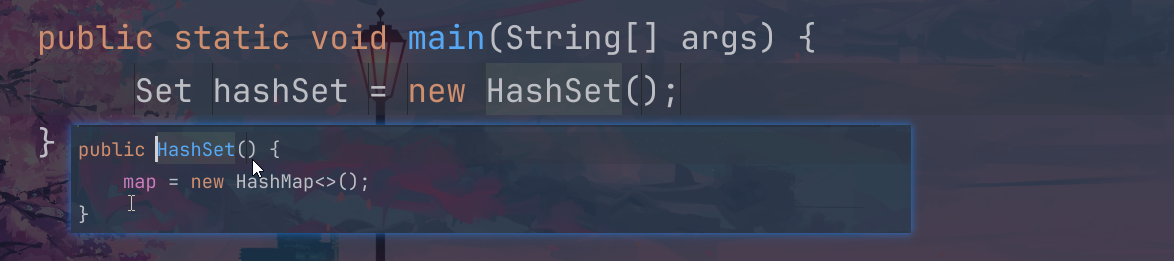
我们下面的算是对于这个hashset入门的一个demo案例,这个案例需要用到下面的这个类:我们在这个类里面实现了这个构造器和toString方法;

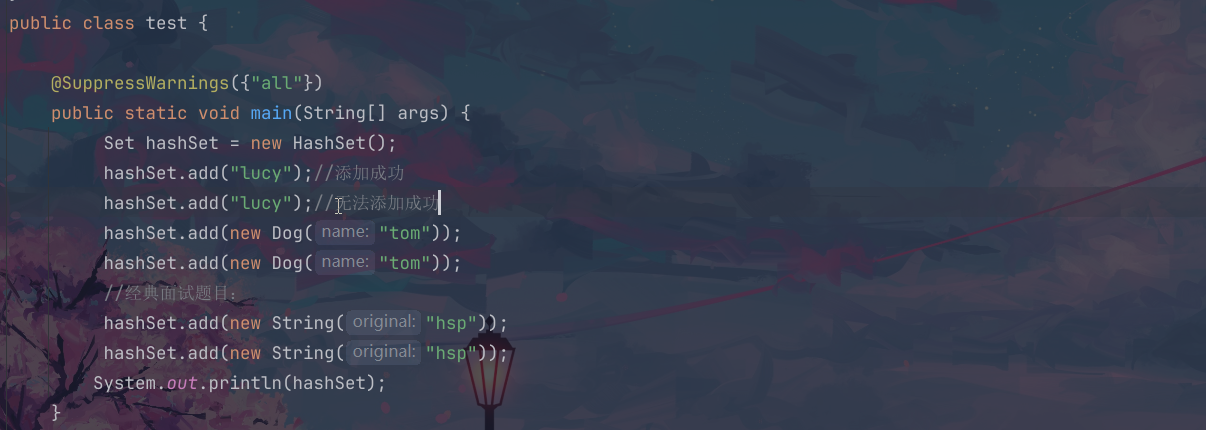
我们创建一个hashset对象,向这个里面去插入数据,因为这个结构式不允许重复的,所以我们第二次插入的这个lucy是不会插入成功的;
但是我们的new Dog两次的这个名字是一样的,可以理解为这个堆上面开辟了不同的空间,但是两个引用指向的是相同的内容,所以两次添加这个new的dog对象是可以成功的;
接下来我们new两个同名的string对象,这个时候的第二个是不会插入成功的,为什么?需要后续学习之后方可解答~~
3.4数组链表模拟
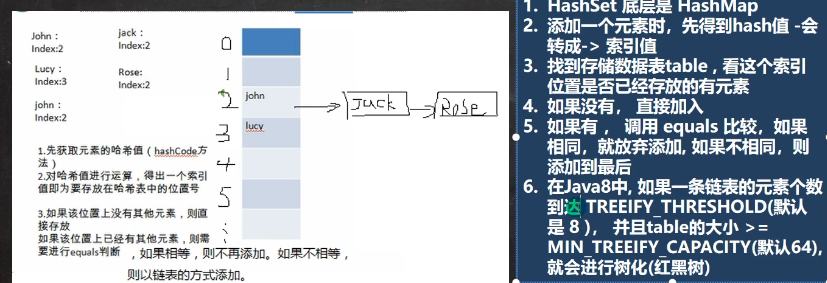
hashset的底层是hashmap,hashmap的底层是数组+链表+红黑树;
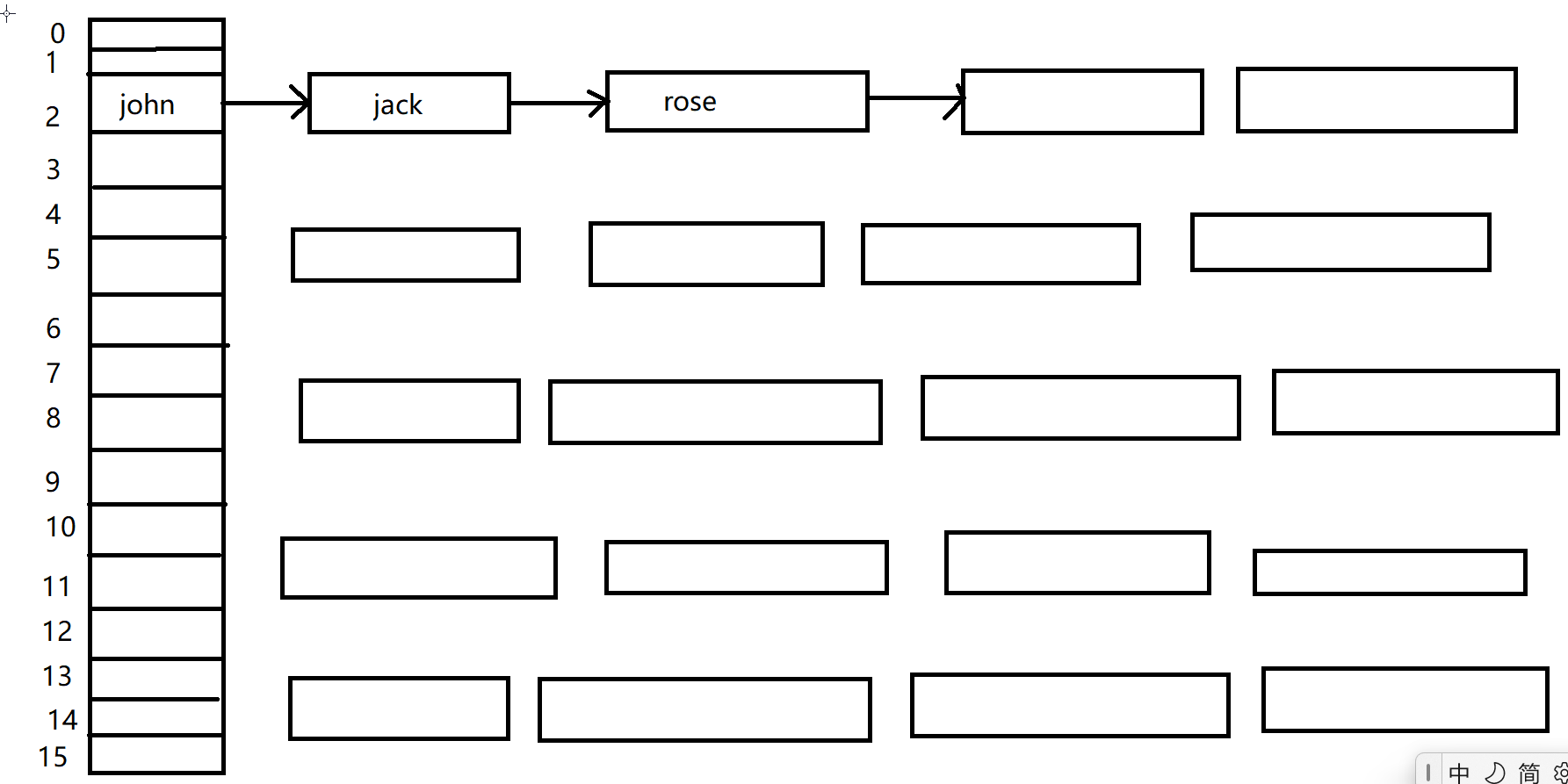
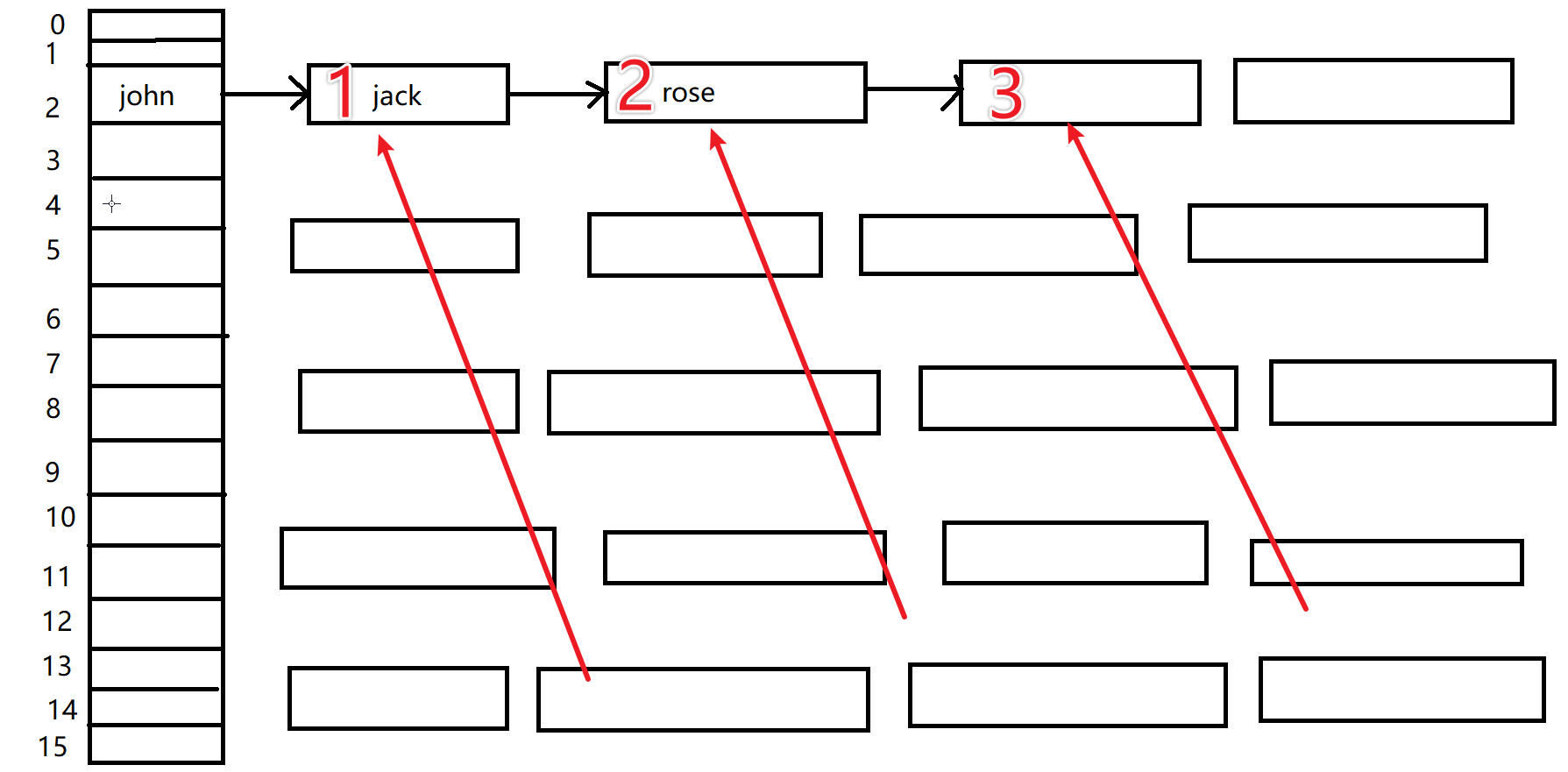
下面的这个就是数组链表的一个模拟情况,就是这个数组里面的每一个元素都是一个链表的头节点(我在这个上面没有完全显示);
下面的先添加这个john对象,然后添加jack对象,继续添加rose对象,每一个数组元素都是有自己的一个链表的,这个就是我们后面分析源码可能会用到的数组链表结构;
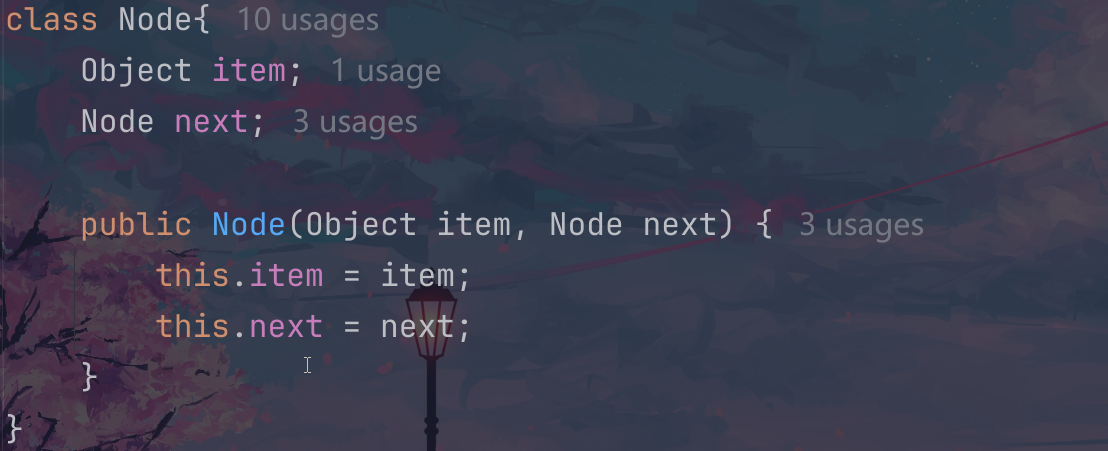
首先需要定义一个node的类,这个里面成员就是我们的结点的数值和下一个节点内容;
然后就是创建对象的过程,我们把这个john放到这个里面的2下标的位置,然后剩下的添加的元素都和这个john组成链表,这个只是为了说明问题,实际上添加的时候是进行这个这个hash的索引分配;
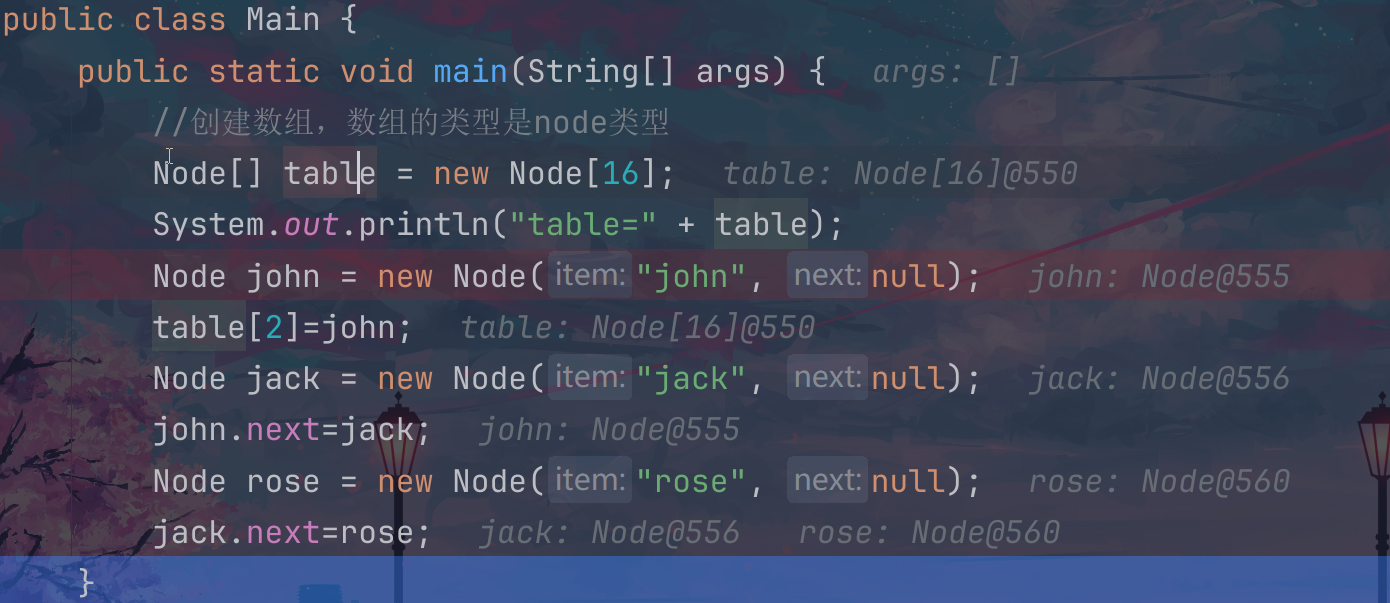
运行结束之后,我们就可以看到这个2位置对应的已经形成了一个链表,这个链表里面已经有了我们插入的三个元素;

3.5hashset扩容机制
1.首先hash值,这个就是一个数字;
2.通过对于这个哈希值的运算,得到一个下标,这个下标就是我们要添加这个数组元素的链表位置,例如我们运算之后得到的是3,就会在这个数组3下标的链表上进行元素的添加;
3.如果这个位置上面没有其他的元素,就会直接放到这个位置上面去,如果有元素,使用这个equals进行判断,这个equals并不是简单的比较两个数据的内容,因为这个方法我们是可以进行重写的;
4.比较这个equals之后,如果相等,就不会进行添加,否则就会尾插到这个链表的后面;
3.6hashset源码解读
table就是一个属性,刚开始这个table就是null,这个时候会进入这个resize方法里面去,这个就是进行的扩容的操作;
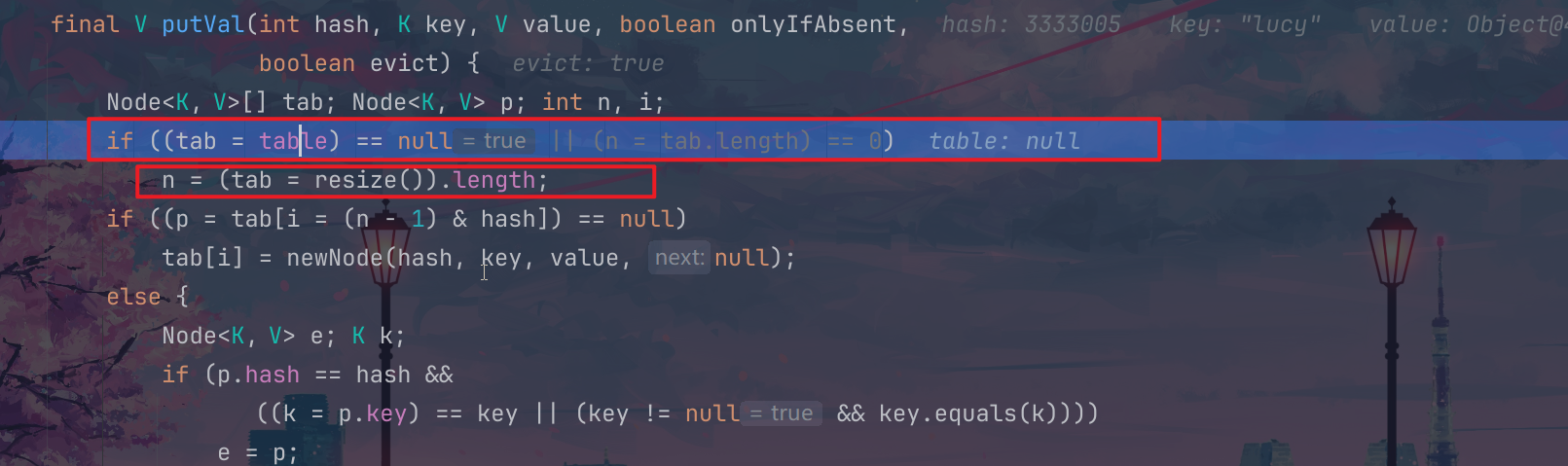
我们扩容的这个大小就是16,但是这个16是我们的数组的大小,每一个数组元素对应的这个链表多少个节点现在是不确定的(后面会说到,默认是8个大小);
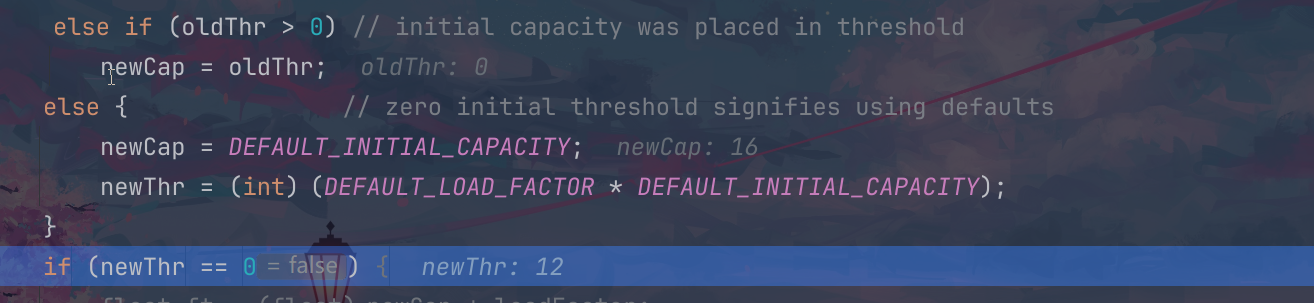
这个时候我们发现这个对象已经插入到了这个13位置,我们上面的是我们自己设置的插入到2下标的位置,这个是自己通过计算匹配之后插入到的这个13位置的;

例如我们想要进行这个数据的插入,匹配到了这个2下标的位置,这个时候通过和这个johu,jack,rose一个一个的进行比对,如果出现了这个equals一样的情况,这个就会进行break操作,否则就会把这个数据添加到我们的这个链表的3位置,这个就是添加的过程;
3.7扩容*转成红黑树机制**我的理解
1.上面介绍到了这个默认开辟的数组大小是16,实际上这个12就是临界(0.75倍的关系,0.75叫做加载因子),就是当我们的这个数组里面的12个位置都被占用的时候,我们就会考虑扩容,因为害怕剩下的4个大小不够使用,这个是第一点;
2.接下来就会进行2倍扩容,例如从16扩到32,这个时候的临界还是0.75倍,即32*0.75=24,也就是说这个达到24之后又会考虑进行扩容操作;
3.链表达到8个之后,这个就会考虑进行树化操作,即把这个数组链表转换为这个红黑树的结构,但是这个前提条件是我们的这个数组已经大于64,因为可能是因为这个数组不够长,我们首先会对于这个数组进行扩容;
4.如果这个数组元素足够多,数组足够长,而且这个链表的节点已经大于8个,这个时候才会进行这个红黑树的转换(通过调用这个红黑树的相关的算法);
5.这个链表也不是达到8一定会树化,这个8不是确定的,可能是大于8才会树化,可能是9,可能是10,这个8是一个默认值,不是确定数值;
6.底层源码里面的这个size++并不仅仅是我们的数组元素增加的时候才会size++,我们的这个数组元素对应的这个链表上面的这个node节点增加的时候我,我们也会进行这个size++的操作;
7.上面说的这个第六点主要是为了说明什么问题?就是我们的这个这个最开始数组不是16个大小吗,就是达到12的时候就会触发扩容,但是这个12并不是12个数组元素,可能会是说这个数组只有两个元素,但是这个链表上面有10个节点,这个时候就是size=12,我们接下来插入数据(无论是节点还是数组元素),都会触发扩容操作,也就是说,即使我们的数组大量是空的,但是我们的这个链表上面的节点足够多,这个也是会出触发我们的这个数组的扩容;
8.首先,我们进行这个数据的添加的时候首先会比较这个hash值,如果哈希值不一样,说明这个下标索引就不一样,这个时候肯定会放进去,这个时候不会进行这个equals操作,当我们的这个hash值一样的时候,说明我们会插入到一个链表上面去,这个时候才会调用这个equals方法;
9.new对象的时候,hash值很难是一样的,但是我们可以重写这个hasncode方法,让他们的属性相同的时候,就会拥有一样的hash值;
如果哈希值不一样,说明这个下标索引就不一样,这个时候肯定会放进去,这个时候不会进行这个equals操作,当我们的这个hash值一样的时候,说明我们会插入到一个链表上面去,这个时候才会调用这个equals方法;
9.new对象的时候,hash值很难是一样的,但是我们可以重写这个hasncode方法,让他们的属性相同的时候,就会拥有一样的hash值;