作者: caiyfc 原文来源: https://tidb.net/blog/e0035e5e
一、背景
我最近在研究使用向量数据库搭建RAG应用,并且已经使用 Milvus、Llama 3、Ollama、LangChain 搭建完成。最近通过活动获取了 TiDB Cloud Serverless 使用配额,于是打算把 Milvus 已完成的向量数据给迁移到 TiDB Cloud Serverless 中。
经过查阅相关资料,我发现向量数据迁移的工具还不支持从 Milvus 迁移到 TiDB。那就无法迁移了吗?不,虽然现有的工具不能迁移,但是我可以手动迁移。于是就有了这篇文章。
TiDB Cloud Serverless 活动地址: 【TiDB 社区福利】贡献开源代码的开发者看过来!最高可获得超 14,000 元的 TiDB Cloud Serverless 云资源额度
搭建RAG应用方法: 手把手系列 | 使用Milvus、Llama 3、Ollama、LangChain本地设置RAG应用
二、迁移方案
要做数据迁移,首先需要确定迁移方案。最简单的迁移就两个步骤:数据从源库导出、数据导入到目标库,这样就完成了数据迁移。
但是这次就不同了。RAG应用使用了 LangChain,根据调研,LangChain 在 Milvus 和在 TiDB 中创建的结构是不同的。
在 Milvus 中的 collection 名称是:LangChainCollection,结构是: 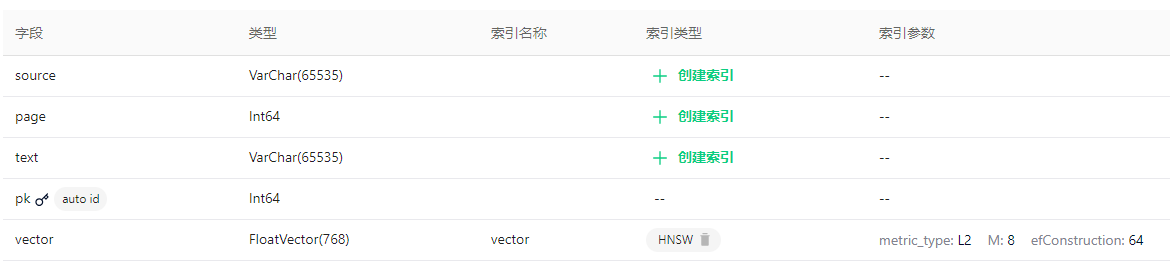
但是在 TiDB 中的table 名称是:langchain_vector,结构是:
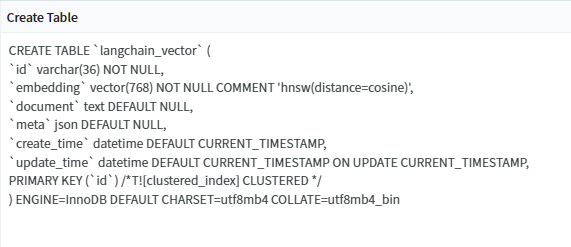
在 LangChain 的文档中也有说明: 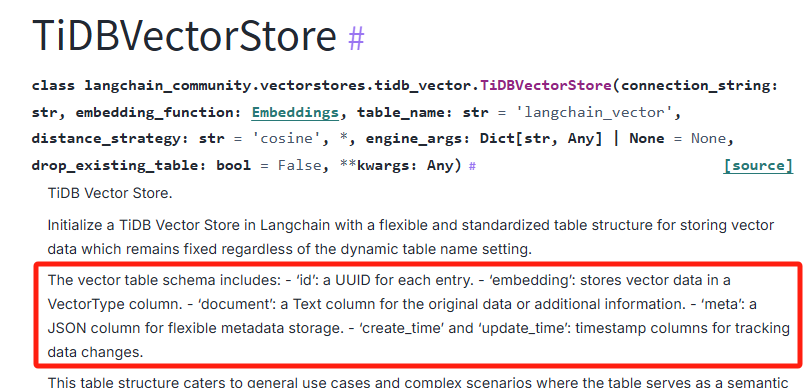
那么这次数据迁移就需要多增加两个步骤了:数据整理、表结构调整。而这两个又是异构数据库,所以导出的数据格式选择较为通用的csv。
整体方案如下:

三、Milvus 数据导出
根据 Milvus 的官方文档,没找到能直接把数据导出成 csv 文件的工具,但是我可以用 python 的 SDK 来把数据读取出来,然后存成 csv 文件。
import csv
from pymilvus import connections, Collection
# 连接到 Milvus
connections.connect("default", host="10.3.xx.xx", port="19530")
# 获取 Collection
collection = Collection("LangChainCollection")
# 分页查询所有数据
limit = 1000
offset = 0
all_results = []
while True:
# 传递 expr 参数,使用一个简单的条件查询所有数据
results = collection.query(expr="", output_fields=["pk", "source", "page", "text", "vector"], limit=limit, offset=offset)
if not results:
break
all_results.extend(results)
offset += limit
# 打开 CSV 文件,准备写入数据
with open("milvus_data.csv", "w", newline="", encoding='utf-8') as csvfile:
# 定义 CSV 列名
fieldnames = ["pk", "source", "page", "text", "vector"]
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
# 写入表头
writer.writeheader()
# 写入每一条记录
for result in all_results:
# 解析 JSON 数据,提取字段
vector_str = ','.join(map(str, result.get("vector", []))) # 将向量数组转换为字符串
writer.writerow({
"pk": result.get("pk"), # 获取主键
"source": result.get("source"), # 获取源文件
"page": result.get("page"), # 获取页码
"text": result.get("text"), # 获取文本
"vector": vector_str # 写入向量数据
})
print(f"Total records written to CSV: {len(all_results)}")导出的 csv 文件数据的格式为:

四、数据整理、表结构整理
我用少量测试数据转换成向量,使用 LangChain 加载到 TiDB Cloud 中了。这样就得到了 TiDB Cloud 中的数据结构及数据格式了。
表结构为:
CREATE TABLE `langchain_vector` (
`id` varchar(36) NOT NULL,
`embedding` vector(768) NOT NULL COMMENT 'hnsw(distance=cosine)',
`document` text DEFAULT NULL,
`meta` json DEFAULT NULL,
`create_time` datetime DEFAULT CURRENT_TIMESTAMP,
`update_time` datetime DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`) /*T![clustered_index] CLUSTERED */
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin可以在 TiDB Cloud 中直接创建该表。
导出成 csv 的数据格式为(省略部分内容):
"id","embedding","document","meta","create_time","update_time"
"00a2ad02-eff5-4649-947f-820db0d24afa","[-0.08534411,0.048610855,0.018906716,0.023978366,***********-0.023846595,0.06352842,0.07482053]","--- 22 --- (七)移交利用共用部位、共用设施设备经营的相关资料、\n物业服务费用和公共水电分摊费用交纳记录等资料; (八)法律、法规员会和物业服务企业。","{\"page\": 21, \"source\": \"./湖北省物业服务和管理条例.pdf\"}","2024-10-15 08:18:16","2024-10-15 08:18:16"
已知 Milvus 导出的 csv 的数文件,根据对应关系,其实就是embedding 对应 vector,document 对应 text,meta 对应 page加source。这样逻辑就清晰了。根据对应关系编写数据整理的脚本:
import pandas as pd
import json
from uuid import uuid4
from datetime import datetime
# 读取CSV文件
input_csv = 'milvus_data.csv' # 替换为你的CSV文件名
df = pd.read_csv(input_csv)
# 创建新的DataFrame
output_data = []
for _, row in df.iterrows():
# 提取需要的字段
id_value = str(uuid4()) # 生成唯一ID
embedding = f"[{','.join(row['vector'].split(','))}]" # 将vector转换为嵌入格式
document = row['text']
# 生成meta信息
meta_dict = {"page": row['page'], "source": row['source']}
meta = json.dumps(meta_dict, ensure_ascii=False) # 首先生成正常的JSON
# meta = meta.replace('"', '\\"') # 转义双引号
create_time = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
update_time = create_time # 更新时同样的时间
# 添加到输出数据
output_data.append({
"id": id_value,
"embedding": embedding,
"document": document,
"meta": meta,
"create_time": create_time,
"update_time": update_time
})
# 转换为DataFrame
output_df = pd.DataFrame(output_data)
# 保存为CSV文件
output_csv = 'output.csv' # 输出文件名
output_df.to_csv(output_csv, index=False, quoting=1) # quoting=1用于确保字符串加引号
print(f"转换完成,已保存为 {output_csv}")
数据整理完成后,就可以导入数据到 TiDB Cloud 中了。
五、导入数据到 TiDB Cloud
TiDB Cloud 提供三种导入方式:

本次使用本地上传的方式。
小于 50MiB 的 csv文件可以使用第一种上传本地文件的方式,如果文件大于 50 MiB,可以使用脚本将文件拆分为多个较小的文件再上传:
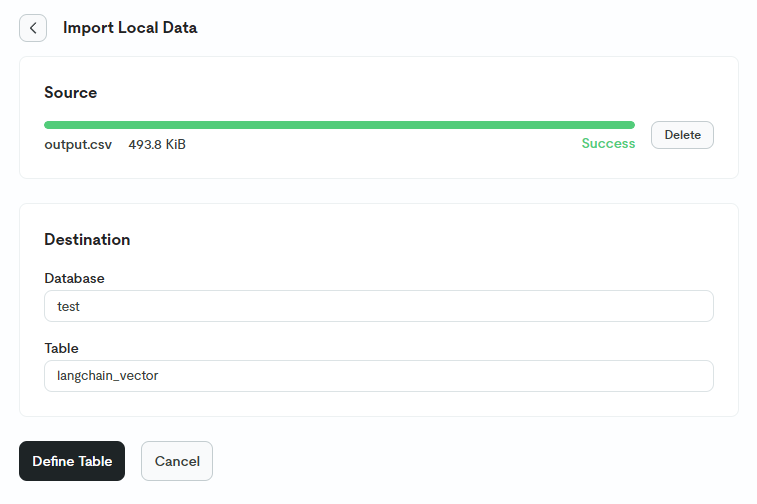
上传文件后,选择已经创建好的库和表,点击 define table :
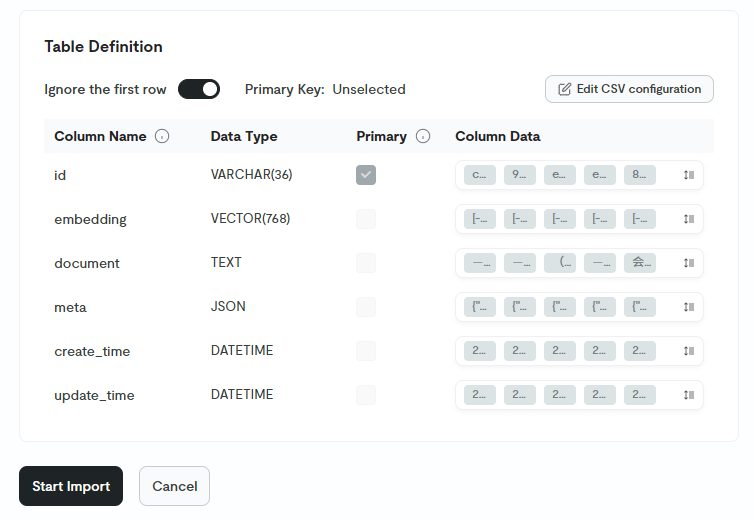
调整好对应关系,点击 start import 即可

更多的导入方式可以查看文档: Migration and Import Overview
六、验证结果
数据成功导入之后,就需要开始验证数据了。于是我修改了 RAG应用的代码,分别从 Milvus 和 TiDB 中读取向量数据,使用同一个问题,来让大模型返回答案,查看答案是否类似。
from langchain_community.llms import Ollama
from langchain.callbacks.manager import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
from langchain import hub
from langchain.chains import RetrievalQA
from langchain.vectorstores.milvus import Milvus
from langchain_community.embeddings.jina import JinaEmbeddings
from langchain_community.vectorstores import TiDBVectorStore
import os
llm = Ollama(
model="llama3",
callback_manager=CallbackManager([StreamingStdOutCallbackHandler()]
),
stop=["<|eot_id|>"],
)
embeddings = JinaEmbeddings(jina_api_key="xxxx", model_name="jina-embeddings-v2-base-zh")
vector_store_milvus = Milvus(
embedding_function=embeddings,
connection_args={"uri": "http://10.3.xx.xx:19530"},
)
TIDB_CONN_STR="mysql+pymysql://xxxx.root:password@host:4000/test?ssl_ca=/Downloads/isrgrootx1.pem&ssl_verify_cert=true&ssl_verify_identity=true"
vector_store_tidb = TiDBVectorStore(
connection_string=TIDB_CONN_STR,
embedding_function=embeddings,
table_name="langchain_vector",
)
os.environ["LANGCHAIN_API_KEY"] = "xxxx"
query = input("\nQuery: ")
prompt = hub.pull("rlm/rag-prompt")
qa_chain = RetrievalQA.from_chain_type(
llm, retriever=vector_store_milvus.as_retriever(), chain_type_kwargs={"prompt": prompt}
)
print("milvus")
result = qa_chain({"query": query})
print("\n--------------------------------------")
print("tidb")
qa_chain = RetrievalQA.from_chain_type(
llm, retriever=vector_store_tidb.as_retriever(), chain_type_kwargs={"prompt": prompt}
)
result = qa_chain({"query": query})其中 TiDB 的连接串可以直接从 TiDB Cloud 中获取:
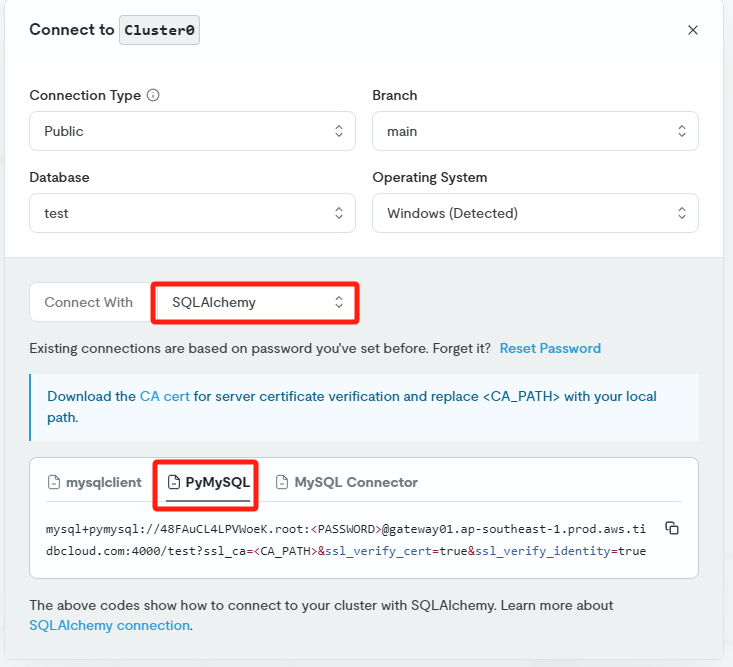
向 RAG 应用提问之后,查看回答,发现 Milvus 和 TiDB 的回答基本一致,说明向量迁移是成功的。还可以更进一步,比对数据条数,如果一致,那么迁移应该已经成功,没有丢失数据。
RAG 应用的执行结果如下图:

七、总结
不同数据库之间的数据迁移,本质上是将数据转换为所有数据库都能识别的通用格式,向量数据也不例外。本次迁移与传统的关系型数据库迁移有所不同,尽管 RAG 应用使用了 LangChain,但 LangChain 针对不同的数据库,创建的表结构和数据格式是不同的,因此需要对数据和表结构进行额外的整理,才能顺利将数据迁移至目标数据库。值得庆幸的是,TiDB Cloud 提供了多种便捷的数据导入方式,使迁移过程相对简单。