文章目录
- [RAG 架构](#RAG 架构)
- 向量数据库
- [RAG 工作流程](#RAG 工作流程)
RAG 架构
如今传统LLM大模型有太多的缺点:
- 垂直领域知识不够:基于通用数据进行训练,无法应对垂直领域、特定公司业务的问题解答,这类垂直领域问题没办法在网络中得到答案,例如:i人事app的绩效考核任务如何创建发起?
- 知识时效性滞后:领域知识不足及数据安全问题的局限性,比如说公司需要打造一款公司产品业务的知识库,你公司的产品方面知识没办法使用通用AI大模型来解答,
- 幻觉:有些不懂的问题,他也会胡言乱语,答非所问。
所以才孕育出 RAG(Retrieval-Augmented Generation) 架构,所谓 RAG 指的是将 传统大模型 和 检索系统 (这里指向量数据库 )相结合,提供更精准的数据检索生成,传统 LLM 大模型不知道的问题,可以从数据库中进行检索查询,这样大大提高回答准确度!说白了:RAG是一种架构设计,简单说就是让大模型 LLM 再加了一个数据库,这样就能让大模型通过检索生成更精准的答案。
向量数据库
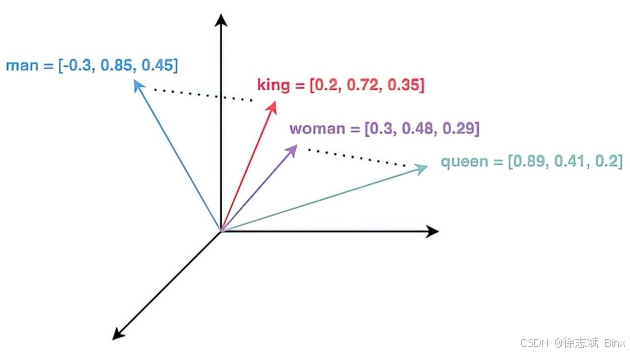
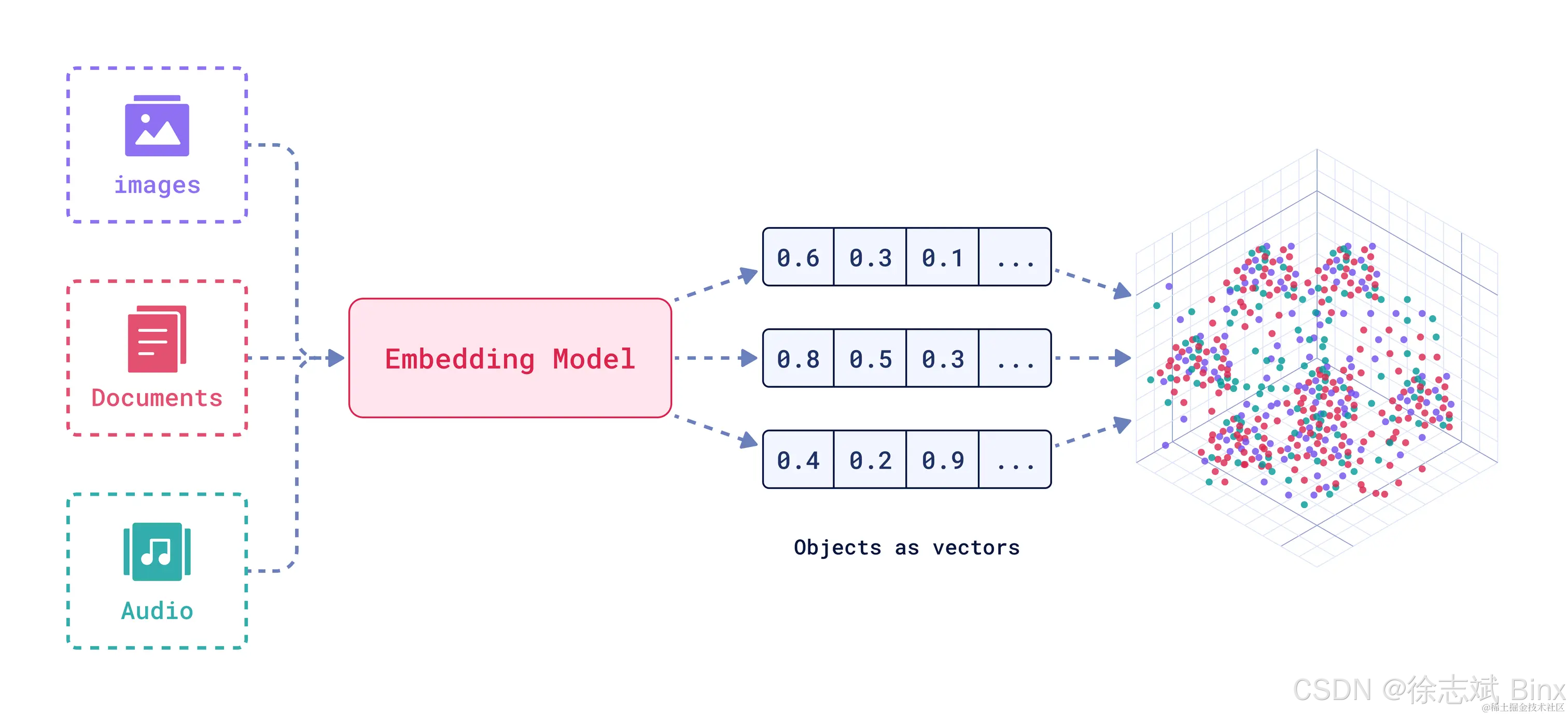
向量数据库中存储向量数据(好像一句废话),向量数据可以来自于文本、图片、音频...例如我想要把公司知识库的文本数据全部存储到向量数据库中,我就需要将文本通过向量模型(Embedding)进行向量化,数据会被清洗、分块(Chunk)后,存入向量数据库(Vector DB),向量数据的格式为浮点数组成的固定长度数组 ,向量之间的距离代表语义相似度。
所以我们需要事先将数据进行向量化处理,然后将检索数据不断存储到向量数据库里面,所以完全就解决上述提到的实时性、垂直性、准确性问题。随着不断收集数据进行词嵌入处理,LLM大模型的回答会越来越精准,专业。
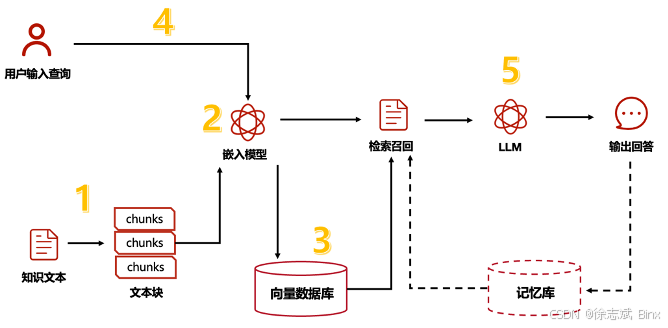
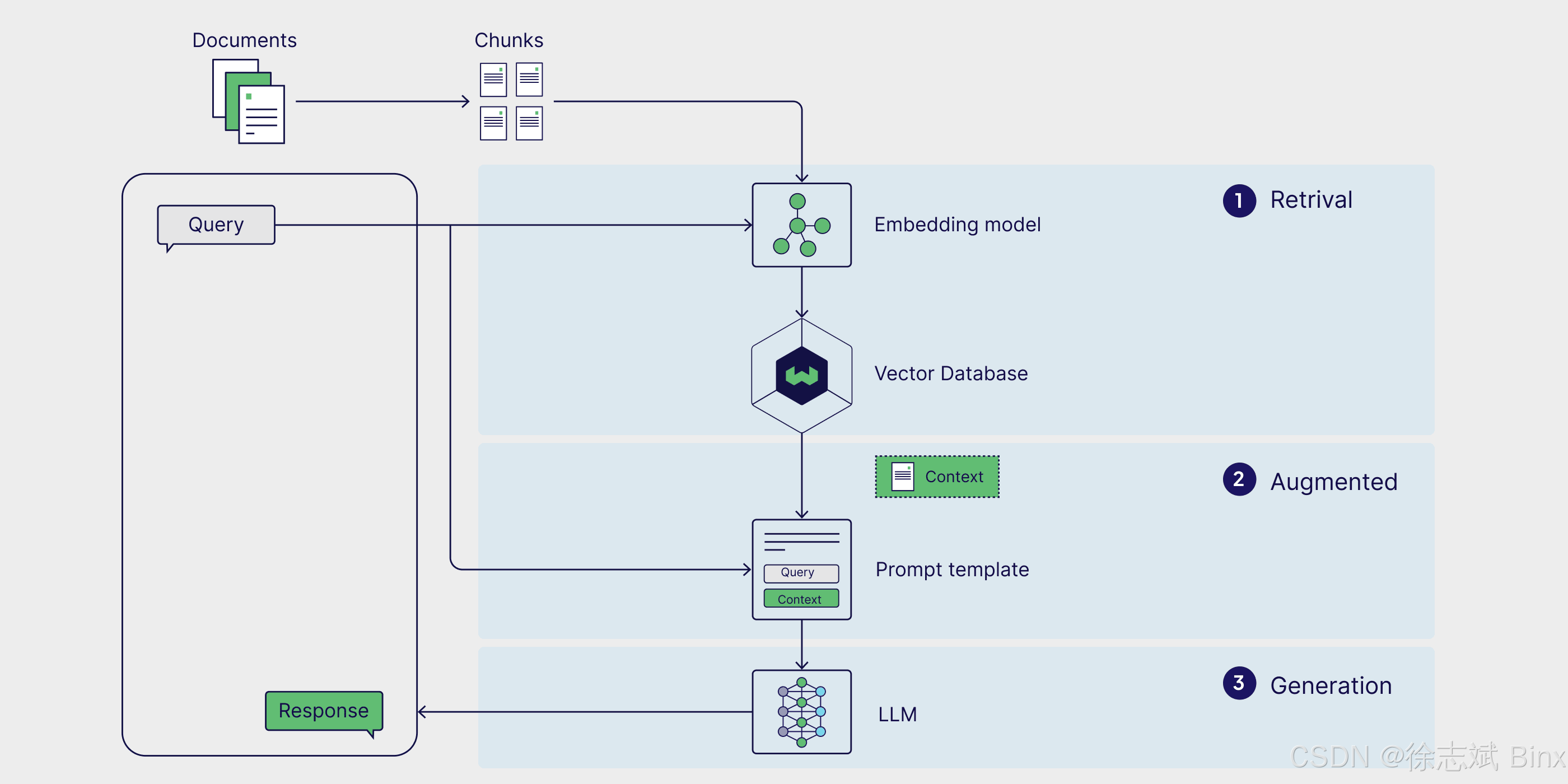
RAG 工作流程
首先,要提前将检索数据进行分块(chunk),然后通过词嵌入模型进行向量化处理(例如将文本转换成浮点数组),然后将数据提前嵌入到向量数据库当中。当客户发起提问,首先也会讲问题进行向量化处理,然后才会在向量数据库中进行相似度检索,此时可能会检索出很多内容,还需要进行筛选、排名TopN,对数据进行召回发送给LLM大模型进行参考,最后大模型组织语言对客户问题进行回答。一个典型的RAG流程组成包含以下部分:
- 文本切片、分块
- Embedding 嵌入模型:例如 OpenAI text-embedding-3, BGE,
- 向量数据库:例如 FAISS(本地),Milvus(分布式)
- LLM大模型:例如 GPT-4 / Claude / Qwen2
- Rerank 重排模型:BERT / cross-encoder / bge-reranker