简述
Apache Dolphinscheduler Master和Worker都是支持多节点部署,无中心化的设计。
- Master主要负责是流程DAG的切分,最终通过RPC将任务分发到Worker节点上以及Worker上任务状态的处理
- Worker主要负责是真正任务的执行,最后将任务状态汇报给Master,Master进行状态处理
那问题来了:
- Master掉了怎么办?它是负责流程实例的管理的。这样Worker就没有办法给它汇报任务状态,当然它也不能做状态处理了?
- Worker掉了又怎么办?要知道Worker是真正任务执行的载体,它如果掉了。Master要怎么处理?
来来来,一张图说清楚它们。
容错
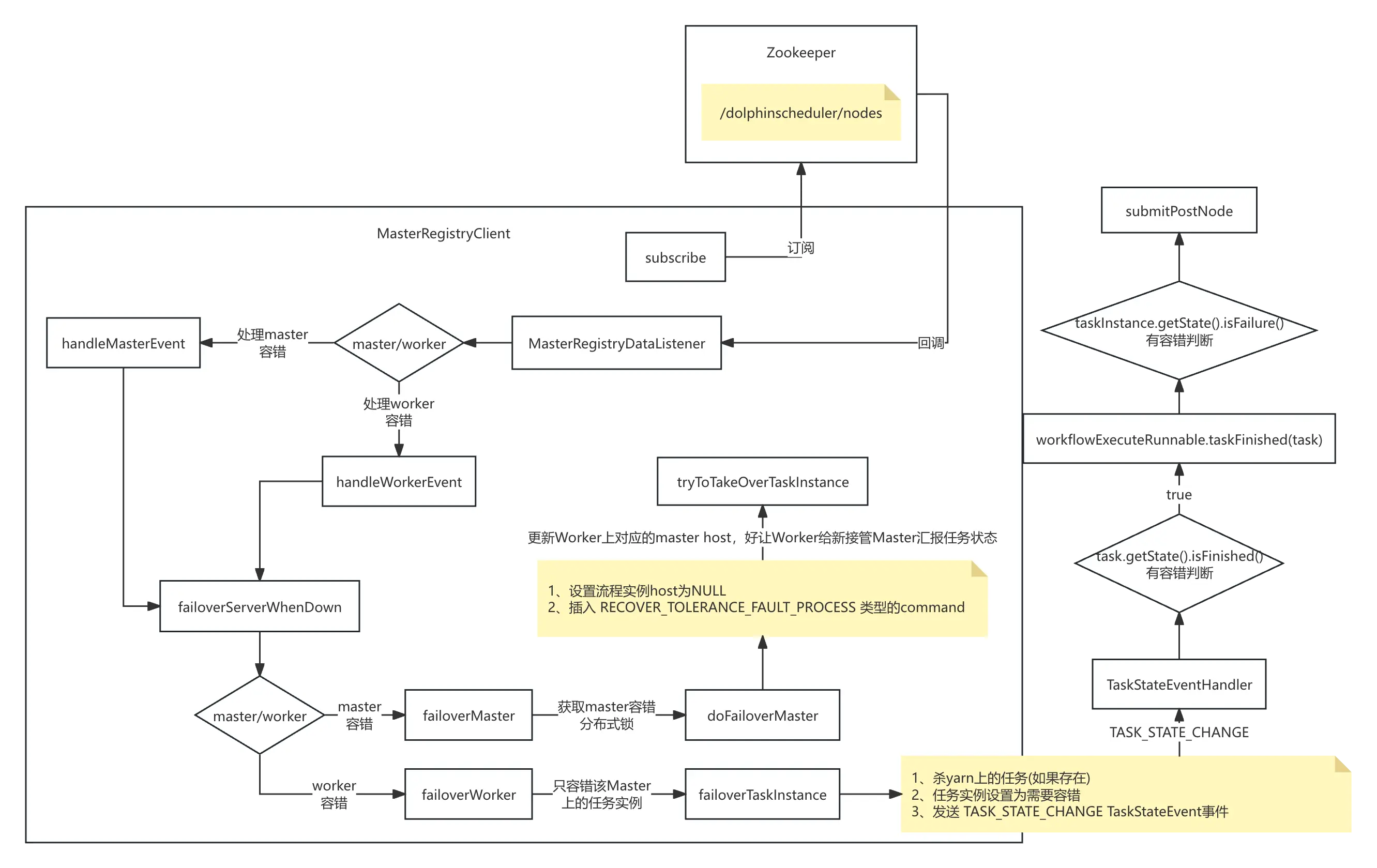
总结
其实说白了就是如果Master掉了,其他Master分布式锁来对Master进行容错。也就是流程实例由之前的down掉的Master切换到要接管的Master上,这个时候是需要给Worker下发新Master的host的,让Worker可以重新给新Master上报信息。
而Worker掉了就是任务的重试,但是任务重试之前是有前提的,那就是要kill掉正在运行YARN上的任务,当前DS做不到。为什么?因为对于在非客户端分离模式下,是需要ProcessBuilder的waitFor一直等待客户端进程退出的。而applicationId的解析是在客户端进程退出(也就是waitFor退出)之后做的。
那意思就是说只能等待程序运行完毕,我才能获取到applicationId。
org.apache.dolphinscheduler.server.master.service.WorkerFailoverService#killYarnTask
private void killYarnTask(TaskInstance taskInstance, ProcessInstance processInstance) {
try {
if (!masterConfig.isKillApplicationWhenTaskFailover()) {
return;
}
if (StringUtils.isEmpty(taskInstance.getHost()) || StringUtils.isEmpty(taskInstance.getLogPath())) {
return;
}
TaskExecutionContext taskExecutionContext = TaskExecutionContextBuilder.get()
.buildWorkflowInstanceHost(masterConfig.getMasterAddress())
.buildTaskInstanceRelatedInfo(taskInstance)
.buildProcessInstanceRelatedInfo(processInstance)
.buildProcessDefinitionRelatedInfo(processInstance.getProcessDefinition())
.create();
// only kill yarn/k8s job if exists , the local thread has exited
log.info("TaskInstance failover begin kill the task related yarn or k8s job");
ILogService iLogService =
SingletonJdkDynamicRpcClientProxyFactory.getProxyClient(taskInstance.getHost(), ILogService.class);
GetAppIdResponse getAppIdResponse =
iLogService.getAppId(new GetAppIdRequest(taskInstance.getId(), taskInstance.getLogPath()));
ProcessUtils.killApplication(getAppIdResponse.getAppIds(), taskExecutionContext);
} catch (Exception ex) {
log.error("Kill yarn task error", ex);
}
}怎么办?回顾 1.3.3 版本,是LoggerServer和Master是分离模式的,所以只要Master节点有yarn客户端,是可以通过master对yarn上的applicationId进行干掉的。而现在怎么办?
两种解决思路 :
-
Master上kill,使用yarn rest api
curl -X PUT -d '{"state":"KILLED"}' \ -H "Content-Type: application/json" \ http://xx.xx.xx.xx:8088/ws/v1/cluster/apps/application_1694766249884_1098/state?user.name=hdfs注意 : 需要加用户。
-
Worker上kill
这个是需要标识该任务是容错任务 ,然后在任务重试运行的时候,调度到指定的Worker上。需要先kill当前运行的applicationId,然后再任务重试。其实这里有一个优化点就是,是Worker掉了,但是任务还在,所以需要判断的是yarn上的状态,如果异常,再kill也不迟,而不是上来就kill。如果是RUNNING,等待就好,可以设置等待超时时间。
转载自journey
原文链接:https://segmentfault.com/a/1190000045084857
本文由 白鲸开源科技 提供发布支持!