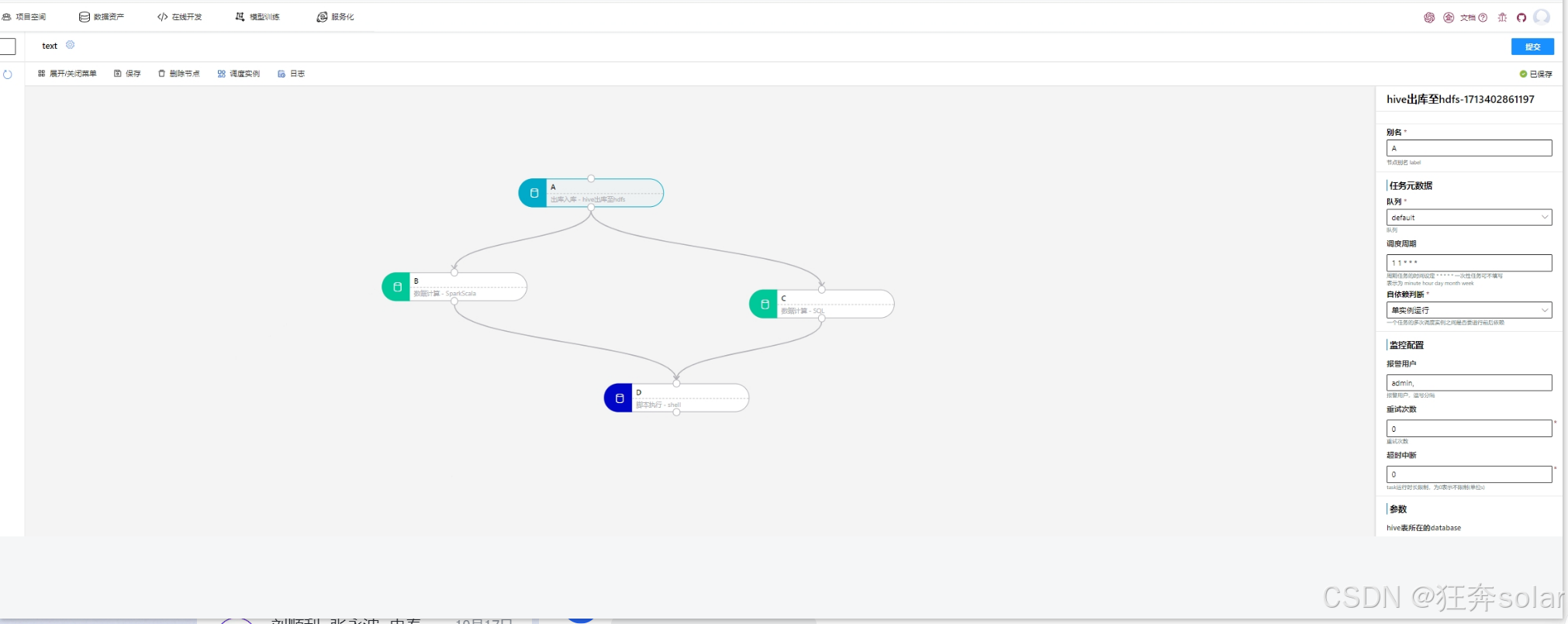
前端使用一个可以拖拽的编排工具,每个节点会有镜像和启动命令参数的配置
定义一个dag模板
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
name: ml-{{randomNumber}}
generateName: dag-diamond-{{randomNumber}}
spec:
entrypoint: main
templates:
- name: main
dag:
tasks:
{% for item in task_arr %}
- name: {{item.name}}
template: {{item.template}}
dependencies: {{item.dependencies}}
arguments:
parameters: {{item.parameters}}
{% endfor %}
{% for item in task_templates %}
- name: {{item.name}}
inputs:
parameters:
{% for parameter in item.parameters %}
- name: {{parameter}}
{% endfor %}
container:
name: {{item.name}}
image: {{item.image}}
command: {{item.command}}
{% endfor %}编写代码把前端接收到的图信息写入到dag-xxx.yml
def uploadArgoYml(etl_pipeline_id, dag_json):
s3Host = conf.get('MINIO_HOST', '')
s3AccessKey = conf.get('MINIO_ACCESS_KEY', '')
s3SecretKey = conf.get('MINIO_SECRET_KEY', '')
if "http://" in s3Host or "https://" in s3Host:
s3Host = s3Host.split("//", 1)[-1]
client = Minio(
s3Host,
access_key=s3AccessKey,
secret_key=s3SecretKey,
secure=False
)
S3_file_path = None
# 使用 task_templates + 参数作为启动
task_arr = []
# 增加启动镜像+command作为模板
task_templates = []
try:
from jinja2 import Template
from pinyin import pinyin
import yaml
print(f'current_directory:{current_directory}')
script_directory = os.path.dirname(os.path.realpath(__file__))
with open(f'{script_directory}/../templates/pipeline_task/dag_template.yml') as rf:
template_content = rf.read()
template = Template(template_content)
# 第一次遍历先添加template
for key, value in dag_json.items():
templateKey = pinyin.get(key, format="strip", delimiter='')
notebok_image_name = value.get('task-config').get('image_id')
if notebok_image_name is not None:
notebook = db.session.query(Notebook).filter_by(name=notebok_image_name).first()
image = eval(notebook.image_save_path)[0]
else:
image = 'ray:test'
command = value.get('task-config').get('command', '')
parameters = value.get('task-config').get('parameters', '')
task_templates.append({
'name': templateKey,
'image': image,
'command': command.split(" "),
'parameters': ['params']
})
task_config = value['task-config'] # 获取字典对象
dependencies = []
for item in value['upstream']:
label = pinyin.get(item, format="strip")
for k, v in dag_json.items():
if pinyin.get(k, format="strip", delimiter='') == label:
dependencies.append(f'task{v.get("task_id")}')
parameters = [{'name': key, 'value': value} for key, value in task_config.items()]
task_arr.append({
"name": f'"task{value.get("task_id")}"',
"template": templateKey,
"dependencies": dependencies,
"parameters": [{'name': 'params', 'value': parameters}]
})
import random
import string
def generate_random_string():
# 包含小写字母和数字的字符串
characters = string.ascii_lowercase + string.digits
random_string = ''.join(random.choice(characters) for _ in range(8)) # 生成8个字符的随机字符串
# 确保名称以字母或数字开头和结尾
random_string = random.choice(string.ascii_lowercase + string.digits) + random_string[1:]
random_string = random_string[:-1] + random.choice(string.ascii_lowercase + string.digits)
return random_string
variables = {
'task_arr': task_arr,
'task_templates': task_templates,
'etl_pipeline_id': etl_pipeline_id,
'randomNumber': generate_random_string()
}
rendered_content = template.render(variables)
local_file_path = f'{script_directory}/../templates/pipeline_task/dag_pipeline-{etl_pipeline_id}.yml'
with open(local_file_path, 'w') as wf:
wf.write('\n'.join(line for line in rendered_content.split('\n') if line.strip()))
bucket_name = "xxxx"
dir_path = 'PIPELINE_TASK'
S3_file_path = f'{dir_path}/{etl_pipeline_id}/task-{etl_pipeline_id}.yml'
print(f'S3_file_path:{S3_file_path}')
file_length = os.stat(local_file_path).st_size
client.put_object(bucket_name, S3_file_path, open(local_file_path, 'rb'), length=file_length)
except Exception as err:
print('Error occurred:', err)
else:
print('No s3Host parameter value provided')
return S3_file_path提交到argo
def submit_pipeline(self, etl_pipeline_id):
# 从minio上下载dag.yml 转为
from pathlib import Path
import os
import yaml
argo_server_url = conf.get('ARGO_SERVER', '')
script_directory = os.path.dirname(os.path.realpath(__file__))
local_file_path = f'{script_directory}/../templates/pipeline_task/dag_pipeline-{etl_pipeline_id}.yml'
#manifest = Path(local_file_path).read_text()
config = Configuration(host=argo_server_url)
client = ApiClient(configuration=config)
service = WorkflowServiceApi(api_client=client)
with open(local_file_path) as f:
manifest: dict = yaml.safe_load(f)
if 'spec' in manifest and 'serviceAccountName' in manifest['spec']:
del manifest['spec']['serviceAccountName']
service.create_workflow('argo', V1alpha1WorkflowCreateRequest(workflow=manifest))
workflow_id = manifest.get('metadata')['name']
return "", f"{argo_server_url}/workflows/argo/{workflow_id}?tab=workflow"查看argo可以看到编排的作业
